论文阅读:MonetDB/X100: Hyper-Pipelining Query Execution
目录
Abstract
在决策支持、OLAP和多媒体检索等计算密集型应用领域,数据库系统往往只能在现代cpu上实现较低的IPC(每周期指令)效率。本文首先以TPC-H基准为重点,深入研究了这种情况发生的原因。通过对各种关系系统和MonetDB的分析,我们得出了一套新的查询处理器设计准则。
本文的第二部分介绍了在MonetDB系统中遵循了这些规则的新X100查询引擎架构。表面上来看,它类似于一个经典的Volcano引擎,但关键的区别是,所有的执行都基于向量处理的概念,这使得它有很高的CPU效率。我们在100GB版本的TPC-H上评估了MonetDB/X100的性能,显示其原始执行能力比之前的技术高出一到两个数量级。
1 Introduction
现代CPU可以每秒执行大量的计算,但前提是它们能找到足够的独立处理器来利用它们的并行计算能力。在过去十年里,硬件的发展已经大大增加了CPU在全吞吐量和最小吞吐量下运行的速度差异,可以很容易地达到一个数量级。
人们会期望查询密集型数据库工作负载,如决策支持、OLAP、数据挖掘以及多媒体检索,所有这些都需要许多独立的计算,应该为现代cpu提供接近最佳IPC(每周期指令)效率的机会。
然而,研究表明数据库系统在这些应用领域中倾向于在现代CPU上达到较低的IPC(CPU每一时钟周期内所执行的指令多少)。我们对此结论存疑,在(重要的)缓存敏感查询处理主题之外,我们详细研究了关系数据库系统如何在查询密集型工作负载中与现代超标量CPU交互,特别是TPC-H决策支持benchmark。
我们从这项调查中得出的主要结论是,大多数DBMs所采用的体系结构阻碍了编译器使用对性能最关键的优化技术,从而导致CPU效率低下。特别是,为流水线处理而实现流行的Volcano[10]迭代器模型的常见方法,导致单次元组式执行,这既会导致较高的解释开销,又会对编译器隐藏CPU并行性的机会。
我们还分析了我们团队开发的内存数据库系统MonetDB1的性能及其MIL查询语言[4]。MonetDB/MIL使用单次列执行模型,因此不会受到单次元组解释产生的问题的困扰。但是,它的全列物化策略导致它在查询执行期间生成大量数据流。在我们的决策支持工作负载上,我们发现MonetDB/MIL受到内存带宽的严重限制,导致其CPU效率急剧下降。
因此,我们主张将MonetDB的列式执行和Volcano风格pipeline提供的增量物化相结合。
我们从零开始为MonetDB设计并实现了一个新的查询引擎,名为X100,它使用了一个向量查询处理模型。除了实现高CPU效率之外,MonetDB/X100旨在向非内存(基于磁盘)的数据集提供扩展能力。本文第二部分致力于描述MonetDB/X100的架构,并在大小为100GB的完整TPC-H benchmark上评估性能。
1.1 Outline
本文组织如下。第2节介绍了现代的超标量(或超流水线)cpu,涵盖了与查询求值性能最相关的问题。在第3节中,我们将TPC-H Query 1作为CPU效率的微基准进行研究,首先是针对标准关系数据库系统,然后是MonetDB,最后我们将深入研究该查询的独立手工编码实现,以获得可实现的最大原始性能基线。
第4节描述了用于MonetDB的新X100查询处理器的体系结构,重点是查询执行,但也概述了数据布局、索引和更新等主题。
在第5节中,我们在TPC- H基准上对莫奈系统内的MIL和X100进行了性能比较。在第7节结束之前,我们将在第6节讨论相关工作。
2 How CPU Work
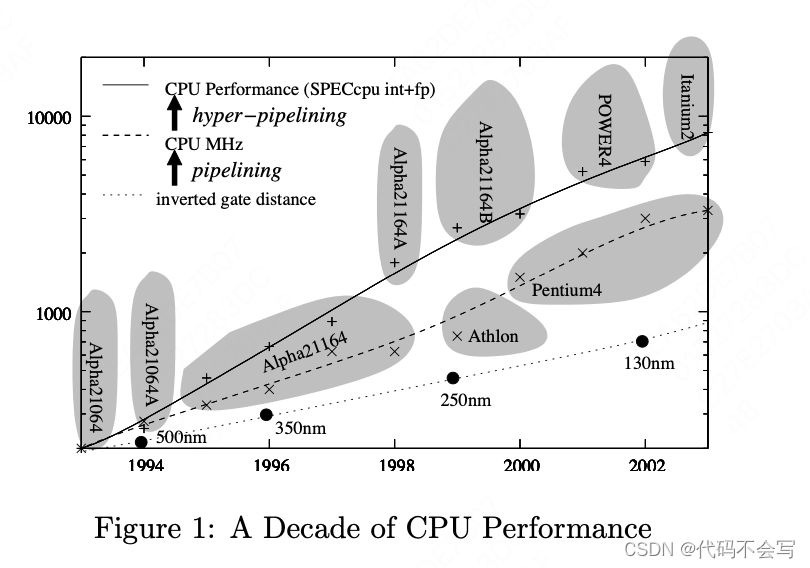
图1展示了过去十年中每一年的最快CPU(以MHz计算),以及最高性能(这两件事并不等价),以及当年生产的最先进芯片制造技术。
CPU MHz提升的主要因素是芯片制造工艺的进步,通常每18个月就缩小1.4倍(摩尔定律)。每缩小一次生产尺寸,晶体管的数量就会增加一倍(1.4的平方),晶体管的数量就会增加一倍(1.4的平方),导线距离和信号延迟也会缩小1.4倍。因此,人们会希望CPU MHz随着信号延迟反向增长,但图1显示时钟速度已经更进一步的增加了,这主要是通过pipeline完成的:将CPU指令的工作划分为多个阶段。每级工作更少以为这可以提高CPU频率。......
Pipeline带来了2个危险:1. 如果一个指令需要前一个指令的结果,那么就不能将其直接推到pipeline中,必须等到前一个指令通过pipeline(或是其中的重要部分)之后再执行。2. 在IF-a-THEN-b-ELSE-c分支场景,CPU必须预测a的结果是true还是false。它可能会猜测结果为后者并将c推到pipeline中,在a之后。再过许多阶段,当a的求值结束时,它可能会确定它猜错了(即错误地预测了分支),然后必须flush pipeline(丢弃其中的所有指令)并重新开始b。显然,pipeline越长,越多的指令会被flush掉,性能损失就越大。转换到数据库系统中,依赖于数据的分支,例如在选择率既不是很高也不是很低的数据上的选择运算符中发现的分支,是无法预测的,并且会显著降低查询执行速度[17]。
此外,如果多个指令是独立的,那么超标量cpu 2提供了并行执行多个指令的可能性。也就是说,CPU有多条pipeline,而不是一条。每一个周期,一个新的指令可以被推入每个pipeline,只要它们是独立于所有已经在执行的指令。一个超标量的CPU可以达到IPC(每周期指令数)>1. 图1显示,这使得实际CPU性能的增长速度超过CPU频率的增长速度。
现代cpu以不同的方式进行平衡。英特尔Itanium2处理器是一个VLIW(超大型结构字)处理器,具有许多并行管道(每个周期可以执行多达6条指令),只有很少(7)个阶段,因此时钟速度相对较低,只有1.5GHz。相比之下,Pentium4拥有非常长的31级流水线,允许3.6GHz时钟速度,但每个周期只能执行3条指令。无论哪种方式,要达到理论最大吞吐量,Itanium2需要7x6 = 42条独立指令,而Pentium4需要31x3 = 93条。这种并行性并不总是存在,因此许多程序使用Itanium2的资源比Pentium4要好得多,这就解释了为什么在基准测试中,尽管两种cpu的时钟速度有很大差异,但性能却很相似。
大多数编程语言不要求程序显示在程序中显式指定那个指令(或表达式)是独立的。因此,编译优化对于达到好的CPU利用率就至关重要了。最重要的技术是循环流水线loop pipelining,其中由多个相关操作F(), G()组成的操作对数组A的所有n个独立元素进行转换,从:
F(A[0]),G(A[0]), F(A[1]),G(A[1]),.. F(A[n]),G(A[n])
到
F(A[0]),F(A[1]),F(A[2]), G(A[0]),G(A[1]),G(A[2]), F(A[3]),..
假设F()的管道依赖延迟为2个周期,当G(A[0])进入执行时,F(A[0])的结果刚刚可用。
在Itanium2处理器的情况下,编译器的重要性甚至更强,因为编译器必须找到可以进入不同管道的指令(其他cpu在运行时使用乱序执行)。由于Itanium2芯片不需要任何复杂的逻辑来查找乱序执行机会,因此它可以包含更多的管道来完成实际工作。Itanium2还有一个称为分支预测的特性,用于消除分支错误预测,允许并行执行THEN和ELSE块,并在条件的结果已知时立即丢弃其中一个结果。编译器的任务还包括检测分支预测的机会。
图2展示了一个选择查询的micro-benchmark,SELECT oid FROM table WHERE col < X,其中X均匀且随机地分布在[0:100],我们在0到100之间改变选择性X。想AthlonMP这样的普通CPU在最坏情况下表现为50%左右,这是由于分支错误预测造成的。通过巧妙地重写代码,我们可以将分支转换为boolean计算(谓词变体)。这种重写的变体的性能与选择性无关,但会产生更高的平均成本。有趣的是,Itanium2上的“分支”变体也是高效且独立于选择性的,因为编译器会将分支转换为硬件预测的代码。

最后,我们应该提到片上缓存对CPU吞吐量的重要性。在CPU执行的所有指令中,约有30%是内存加载和存储指令,它们访问位于主板上距离CPU几英寸远的DRAM芯片上的数据,这对内存延迟造成了大约50ns的延迟物理下限。对于3.6GHz的CPU,这个(理想的)最小延迟50ns已经转化为180个等待周期。因此,只有当程序访问的绝大多数内存可以在片上缓存找到时,现代CPU才有机会以其最大吞吐量运行。最近的数据库研究表明,DMS的性能与内存访问成本(cache miss)密切相关。如果使用缓存敏感的数据结构,如缓存对齐的b树或列式数据布局,如PAX和DSM(如MonetDB),则可以显著提高性能。此外,将其随机内存访问模式限制在CPU缓存区域的查询处理算法,如基数分区哈希连接[18,11](radix-partitioned hash-join),可以极大地提高性能。
总而言之,CPU已经成为高度复杂的设备,处理器的指令吞吐量可以以数量级(!)变化,这取决于内存负载和存储的缓存命中率,分支的数量以及它们是否可以预测,以及编译器和CPU平均可以检测到的独立指令的数量。有研究表明,在商业DBMS系统中执行查询的IPC仅为0.7[6],即每个周期执行的指令少于一条。相比之下,科学计算(例如矩阵乘法)或多媒体处理确实从现代cpu中提取了平均高达2的ipc。我们认为数据库系统不应该表现得如此糟糕,特别是在需要检查数百万元元组并计算表达式的大规模分析任务中。大量的工作包含大量的独立性,应该能够填充CPU所能提供的所有管道。因此,我们的任务是调整数据库体系结构,以便在可能的情况下将其暴露给编译器和CPU,从而显著提高查询处理吞吐量。
3 Microbenchmark: TPC-H Query 1
虽然我们的目标是查询处理的CPU效率,但我们首先关注表达式计算,放弃更复杂的关系操作(如连接)以简化我们的分析。我们选择TPC-H基准的查询1,如图3所示,这个查询是cpu限制的,因为在我们测试的所有rdbms上。而且,这个查询几乎不需要任何优化或花哨的连接实现,因为它的计划非常简单。因此,所有数据库系统都在一个公平的竞争环境中运行,并主要暴露了它们的表达式求值效率。

这个TPC-H benchmark在一个1GB的数据仓库上执行,其大小可以通过缩放因子SF来增加。查询1是一个基于lineitem表的SF*6M的scan,它选择几乎所有的元组(SF*5.9M),并计算许多定点的十进制表达式:2个列对常量的减法,1个列对常量的加法,3个列到列的乘法,以及8个聚合(4个sum,3个avg,一个count)。聚合分组是在两个单字符列上进行的,并且只产生4个唯一的组合,因此它可以用一个小的哈希表高效地完成,不需要额外的I/O,甚至不需要CPU缓存丢失(用于访问哈希表)。
接下来,我们会分析Query1在关系数据库系统上的性能,以及在MonetDB/MIL上的性能,最终在一个手写代码程序上的性能。
3.1 Query 1 on Relational Database Systems
从早期的RDBMS开始,查询执行功能是通过实现物理关系代数来提供的,特别是遵循pipeline处理的Volcano模型。然而,关系代数的参数具有高度自由。例如,即便是一个简单的ScanSelect(R, b, P)也只在查询时接收到输入关系R的格式(列数,数据类型,record offsets)、布尔选择表达式b(可能是任意格式)、以及一个投影表达式P的列表(每个都具有任意复杂度)的全部知识。为了处理所有可能的R,b和P,DBMS实现者实际上必须实现一个表达式解释器,它可以处理任意复杂度的表达式。
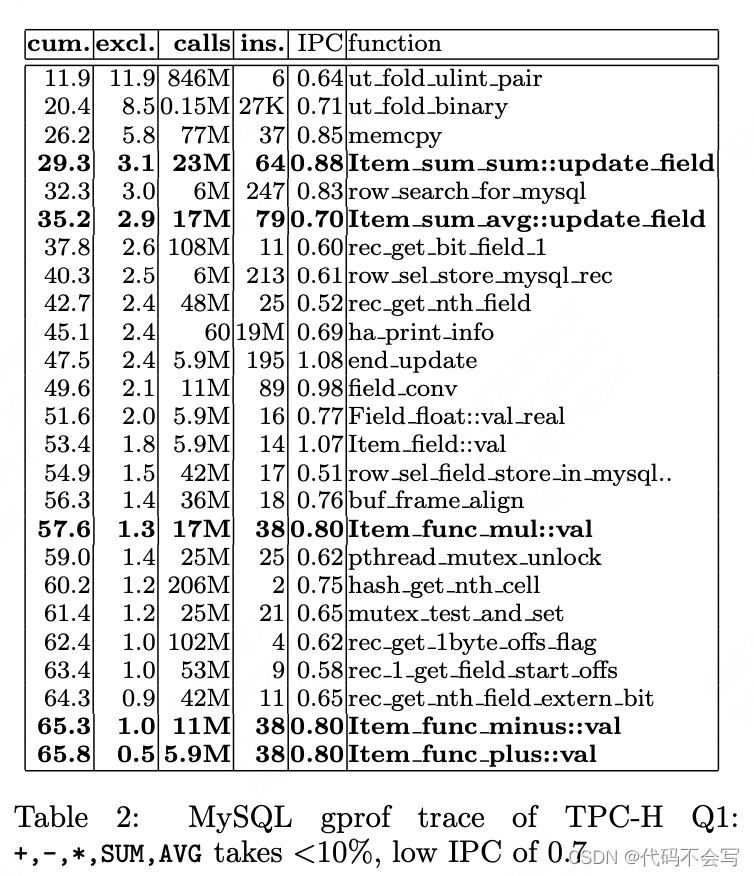
这种解释器的一个危险,特别是当解释的粒度是一个元组时,是“实际工作”的成本(即执行查询中的表达式)只占总查询执行成本的一小部分。我们可以在表2中看到这种情况,表2显示了MySQL 4.1的TPC-H Query 1在SF=1的数据库上的gprof跟踪。第二列显示了在例程中花费的总执行时间的百分比,不包括在它调用的例程(excl .)中花费的时间。第一列是第二列的累加和。第三列列出了调用例程的次数,而第四和第五列显示了每次调用执行的指令的平均数量,以及实现的IPC。
首先要做的观察是,完成所有“工作”的五个操作(以黑体显示)只对应于总执行时间的10%。仔细检查就会发现,28%的执行时间被用于聚合的哈希表的创建和查找所占用。剩下的62%的执行时间分布在像rec get nth field这样的函数上,这些函数通过MySQL的记录表示进行导航,并在其中复制数据。其他因素,如锁定开销(pthread互斥锁解锁、互斥锁测试和设置)或缓冲区页面分配(但帧对齐)似乎在这个决策支持查询中只起很小的作用。
第二个观察结果是Item操作的成本——与查询的计算“工作量”相对应的操作。例如,itemfunc +::val每次添加的代价是38条指令。这个性能跟踪是在一台带有MIPS R12000 CPU3的SGI机器上进行的,该机器每个周期可以执行三个整数或浮点指令和一个加载/存储,平均操作延迟约为5个周期。一个简单的算术运算+(double src1, double src2):在RISC指令中是这样的:
LOAD src1,reg1
LOAD src2,reg2
ADD reg1,reg2,reg3
STOR dst,reg3
这段代码的限制因素是三个加载/存储指令,因此MIPS处理器每3个周期可以执行一次*(double,double)。这与MySQL的成本形成鲜明对比:#ins/Instruction-Per- Cycle (IPC) = 38/0.8 = 49个周期!这种高成本的一个解释是缺乏循环流水线。由于MySQL调用的例程每次调用只计算一个加法,而不是一个加法数组,编译器不能执行循环流水线。因此,加法由四个相互依赖的指令组成,它们必须相互等待。平均指令延迟为5个周期,这解释了大约20个周期的成本。其余的49个循环用于跳转到例程,以及推入和弹出堆栈。
MySQL一次执行多个表达式的策略的后果是双重的:
-
item_func_plus::val只执行一次加法,阻止编译器创建pipeline循环。由于一个操作的指令是高度依赖的,必须产生空的pipeline slots来等待指令延迟,这样循环的成本就变成了20而不是3个周期。
-
例程调用的成本(大约20个周期)必须仅在一个操作上平摊,这实际上使操作成本翻了一番。
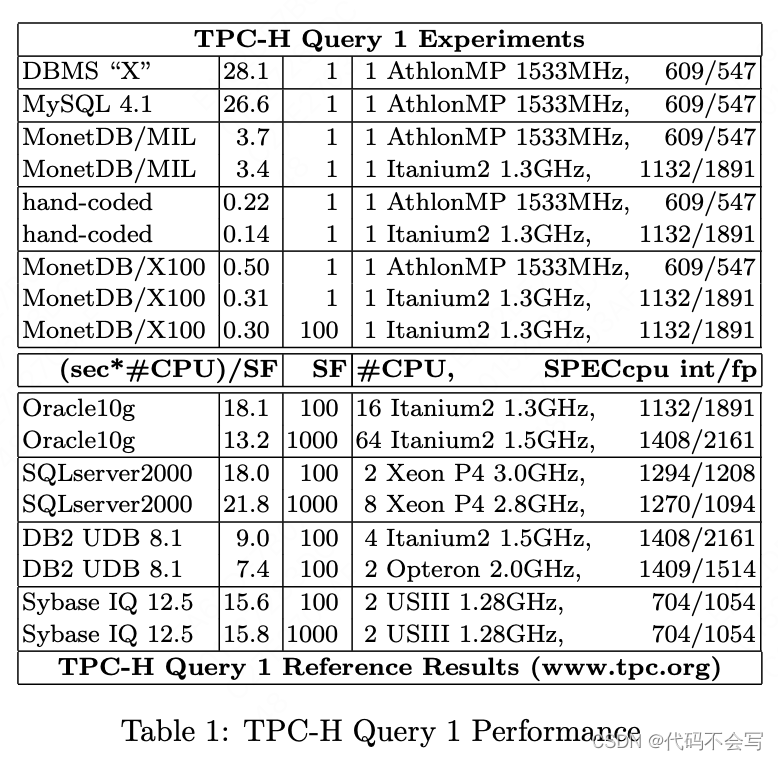
我们也在知名的商业RDBMS(见表1)上测试了同样的查询。由于我们缺少这些产品的源码,我们不能产生gprof trace。然而,在这些DBMS上的查询开销和MySQL非常接近。
表1中的下半部分包括一些从TPC网站获取的官方TPC-H的查询1的结果。
查询1主要是全扫描中的计算,并且随表大小线性扩展。使用水平并行,查询也是“令人尴尬的并行”,因此并行系统上的TPC-H结果很可能实现线性加速。因此,我们可以比较不同系统的吞吐量,方法是将所有时间归一化为SF=1和单个CPU。我们还提供了所使用的各种硬件平台的SPECcpu int/float分数。我们这样做主要是为了检查我们获得的关系DBMS结果与TPC发布的结果大致相同。这使我们相信,我们在MySQL跟踪中看到的情况很可能代表了商业RDBMS实现中发生的情况。
3.2 Query 1 on MonetDB/MIL
由我们团队开发的MonetDB系统,以其对向量分片的使用二闻名,按列存储表,每一列都在一个包含[oid, value]组合的二进制关联表Binary Association Table(BAT)中。一个BAT是一个2列表,其中左边的列被称为head,右边的列被称为tail。MonetDB的代数查询语言是一个列代数,被称为MIL。
对比与关系代数,MIL代数没有任何自由度。它的代数算子具有固定数量的参数以及固定的格式(2列表或是常量)。被一个算子计算的表达式是固定,它的结果样式也是如此。例如,MIL join(BAT[tl,te] A, BAT[te,tr] B) : BAT[tl,tr]是一个tail column A和head column B之间的equi-join,对于每一个匹配的元组组合,它会返回A的head value和B的tail value。MIL中的join A中另一列(例如,join head而不是tail)的机制,是利用MIL reverse(A)算子来返回一个A交换列的视图:BAT[te , tl ]。MonetDB中的reverse是一个领开销的操作,它仅仅只是交换了BAT中的指针。复杂表达式必须用多个MIL中的语句来表达。例如,extprice * (1 - tax) 会变为tmp1 := [-](1,tax);
tmp2 := [*](extprice,tmp1),其中[*]()和[-]()是将一个函数映射到整个BAT(列)的多路操作符。MIL以列方式执行,因为它的操作符总是消耗许多物化的输入BAT,并物化单个输出BAT。
我们使用MonetDB/MIL SQL前端将TPC-H Query 1转换为MIL并运行它。表3显示了所有20个MIL调用,它们总共跨越了超过99%的查询时间。在TPC-H查询1上,MonetDB/MIL显然比同一台机器上的MySQL和商业DBMS要快,并且与已发布的TPC-H分数也有竞争力(见表1)。然而,仔细检查表3会发现,几乎所有MIL操作符都是内存受限的,而不是cpu受限的!这是通过在SF=0.001的TPC-H数据集上运行相同的查询计划来确定的,这样lineitem表的所有使用的列以及所有中间结果都适合CPU缓存,从而消除了任何内存流量。MonetDB/MIL的速度几乎是原来的两倍。第2列和第4列列出了由各个MIL操作实现的带宽(BW),以MB/s为单位,计算了输入BAT和产生的输出BAT的大小。在SF=1时,MonetDB卡在500MB/s,这是该硬件上可承受的最大带宽[1]。当纯在CPU缓存中以SF=0.001运行时,带宽可以超过1.5GB/s。对于多路乘法[*](),只有500MB/s的带宽意味着每秒20M元组(16个字节输入,8个字节输出),因此在我们的1533MHz CPU上每次乘法75个周期,这甚至比MySQL更糟糕。

因此,MIL中的单列处理策略试一把双刃剑。它的优势在于,MonetDB不会像MySQL一样,将90%的查询执行时间用于单个元组的解释开销上。由于执行表达式计算的多路操作再整个BAT上工作(基本上是在编译时就获取其layout的数组上),编译器能够使用loop-pipelining,使这些操作符实现高CPU效率,体现在SF=0.001的结果上。
然而,我们发现完全物化存在一下问题。首先,在许多元组上执行的包含复杂计算表达式的查询会物化表达式中每一个函数的全部结果列。通常,这些函数结果不是查询结果所需要的,仅仅是作为表达式中其他函数的输入。例如,如果一个聚合是查询计划中最顶层的操作符,那么最终结果的大小甚至可以忽略不计(例如在Query 1中)。在这种情况下,MIL物化了比必须数据多得多的数据,从而导致带宽消耗高。
同样,查询1从98%选择率的6M元组表开始,并对剩余的590万元组执行聚合。MonetDB使用6个位置join()实现了select()的相关结果列。在类似于volcano的流水线执行模型中不需要这些join。它可以在一次传递中完成选择、计算和聚合,而不具体化任何数据。代码生成?计算压缩?
在本文中,我们主要关注主存场景下的CPU效率,我们指出,MonetDB/MIL产生的“人为”高带宽使系统难以有效地扩展到基于磁盘的问题,这仅仅是因为内存带宽往往比I/O带宽大得多(而且更便宜)。维持例如1.5GB/s的数据传输需要一个真正高端的RAID系统和非常多的磁盘。
3.3 Query 1: Baseline Performance
为了获取现代硬件在类似Query 1问题上能够达到的基线,我们在MonetDB中将它实现为了一个UDF,如图4所示。这个UDF只在查询所涉及的列中传递。在MonetDB中,这些列以BAT[void, T]的数组存储。也就是说,head列中的oid值密集地从0向上递增。在这种情况下,MonetDB使用不存储的void(“virtual-oid”)。BAT然后采用数组的形式。我们将这些数组作为限制指针传递,这样C编译器就知道它们是不重叠的。只有这样,它才能应用循环流水线。
这个实现利用了这样一个事实,即对两个单字节字符执行GROUP BY永远不会产生超过65536个组合,因此它们的组合位表示可以直接用作具有聚合结果的表的数组索引。像在MonetDB/MIL中一样,我们执行了一些常见的子压缩消除,这样可以省略一个减号和三个AVG聚合。
表1显示了这个UDF实现(所谓的“手工编码”)将查询计算成本降低到惊人的0.22秒。从同一个表中,您将注意到我们的新X100查询处理器(这是本文其余部分的主题)能够达到这个手工编码实现的2倍。
4 X100: A Vectorized Query Processor
X100的目标是:
-
以高CPU效率执行大容量查询
-
对于其他的应用领域具有扩展性,例如数据挖掘、多媒体检索,并基于可扩展的代码达到高效率
-
根据最低存储层次(磁盘)进行缩放
为了达到我们的目标,X100必须与贯穿整个计算机体系结构的瓶颈作斗争;
-
DISK:X100的ColumnBM I/O子系统旨在实现高效的顺序数据访问。为了减少带宽需求,它使用垂直分片的数据布局,在某些情况下还使用轻量级数据压缩进行增强。
-
RAM:像I/O一样,RAM访问是通过显式的内存到缓存和缓存到内存例程(包含特定于平台的优化,有时包括SSE预取和数据移动汇编指令)来执行的。在RAM中使用相同的垂直分区甚至压缩磁盘数据布局来节省空间和带宽。
-
Cache:我们使用基于向量处理模型的类似于volcano的执行管道。小的(例如1000个值)缓存驻留数据项的向量块,称为“向量”,是X100执行原语的操作单元。CPU缓存是唯一一个带宽无关紧要的地方,因此(解)压缩发生在RAM和缓存之间的边界上。X100查询处理操作符应该具有缓存意识,并将庞大的数据集有效地分割成缓存块,并仅在缓存块中执行随机数据访问。
-
CPU:向量化原语向编译器表明,处理元组与前一元组和后一元组无关。投影的向量化原语(表达式计算)很容易做到这一点,但我们也试图在其他查询处理操作符(例如聚合)中实现同样的目标。这允许编译器生成高效的循环管道代码。为了进一步提高CPU吞吐量(主要是通过减少指令组合中的加载/存储数量),X100包含为整个表达式子树而不是单个函数编译向量化原语的功能。目前,此编译是静态引导的,但它最终可能成为优化器强制执行的运行时活动。
为了保持本文的重点,我们只简要地描述磁盘存储问题,这也是因为ColumnBM缓冲区管理器仍在开发中。在我们所有的实验中,X100使用MonetDB作为它的存储管理器(如图5所示),它在内存中的bat上操作。

4.1 Query Language
X100使用相当标准的关系代数作为查询语言。我们抛弃了每次列的MIL语言,以便关系运算符可以同时处理多列(向量),允许使用一个表达式生成的向量作为另一个表达式的输入,而数据在CPU缓存中。
4.1.1 Example
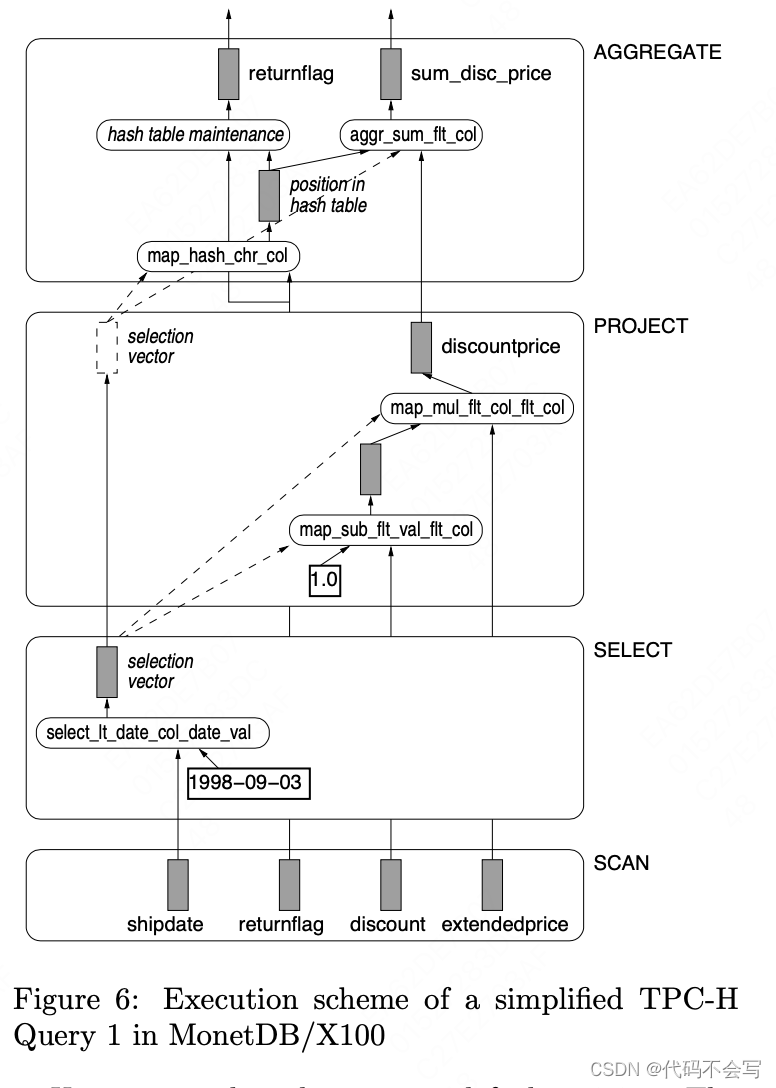
为了演示MonetDB/X100的行为,图6展示了一个简化版本的TPC-H Query 1的执行,使用以下X100关系代数语法:
![]()

执行过程使用类似于volcano的流水线,基于一个向量的粒度(例如1000个值)。扫描操作符每次从Monet BATs中检索数据向量。注意,实际上只扫描与查询相关的属性。
第二步是Selector算子,它创建了一个selection-vector,填充了匹配谓词条件的元组的位置。然后是Project算子,它执行来计算最终aggregation所需的表达式。请注意,在selection期间不会修改“discount”和“extend- edprice”列。相反,map-primitives会考虑selection-vector,只对相关元组执行计算,将结果写入输出向量中与输入向量中相同的位置。这种行为需要将选择向量传播到最终的聚合。在这里,计算每个元组在哈希表中的位置,然后使用这些数据更新聚合结果。此外,对于哈希表中的新元素,将保存分组属性的值。一旦底层运算符耗尽并且不能产生更多的向量,哈希表的内容就可以作为查询结果使用。
4.1.2 X100 Algebra
图7列举了当前支持的X100代数算子。在X100代数中,一个Table是一个物化的关系,而一个Dataflow只是由流经pipeline的元组组成。
Order,TopN和Select返回一个和输入格式相同的Dataflow。其他的算子会定义一个新格式的Dataflow。X100代数的一个特点是Project仅用于表达式计算;且代数不会消除重复(没有Union算子?和distinct关键字?)。重复消除可以通过使用一个Aggr并只对列进行groupby不聚合。Array操作符生成一个数据流,将n维数组表示为包含所有有效数组索引坐标(按列主维顺序)的n元关系。它被用于MonetDB系统的RAM数组操作前端[9]。
Aggregate由3个物理算子支持:1. direct aggregation;2. hash aggregation;3. ordered aggregation。当所有的分组元素在Dataflow中依次到达时,选择后者。Direct aggregation可以用于小的数据类型,其中bit表示限制在已知的(小)域,类似于硬编码解决方案中处理聚合的方式。其他场景则使用hash aggregation。
X100当前仅支持left-deep join。默认的物理实现是有一个Select上游的CartProd算子。如果X100在join condition中检测到外键condition,且join-index是可用的,它会利用Fetch1Join或是FetchNJoin。
在X100中包含这些提取连接并不是巧合。在MIL中,oid与空列的“positional-join”已被证明对存储在密集列中的向量分片数据是有价值的。位置连接允许以一种高效的方式处理向量分片所需的“额外”连接[4]。就像MonetDB中的void类型一样,X100为每个表提供一个虚拟的#rowId列,它只是一个从0开始密集升序的数字。Fetch1Join允许通过#rowId位置获取列值。

4.2 Vectorized Primitives
使用按列矢量布局的主要原因不是为了优化缓存中的内存布局(X100应该对缓存数据进行操作)。相反,向量化的执行原语具有自由度低的优点(如第3.2节所述)。在向量分片的数据模型中,执行原语只知道它们操作的列,而不必知道整个表的布局(例如记录偏移量)。在编译X100时,C编译器看到X100向量化原语对固定形状的受限(独立)数组进行操作。这允许它充分利用循环流水线,这对现代CPU性能至关重要(参见第2节)。作为一个例子,我们展示了(生成的)矢量化浮点加法代码:

sel参数可能是空或是指向一个有n个select position数组的指针。所有的X100向量化原语都允许传递这样的selection vectors。其基本原理是,在selection之后,保留由子操作符传递的向量的完整性通常比将所有选择的数据复制到新的(连续的)向量中更快。
X100有上百个向量化原语,他们不是手动编写和维护的,而是通过primitive patterns生成的。加法的primitive pattern如下:
any::1 +(any::1 x,any::1 y) plus = x + y
这个pattern表明,在C中,两个相同类型的值的相加(但没有任何类型限制)是通过中缀操作符+实现的。它产生相同类型的结果,并且应该加上名称标识符。稍后在规范文件中的特定类型模式可能会覆盖此模式(例如str +(str x,str y) concat = str concat(x,y))。
原语生成的另外一个部分是一个map signature requests文件:
+(double*, double*)
+(double, double*)
+(double*, double)
+(double, double)
这个request会生成单个值和列(带有额外*的)的加法所有可能的组合。其他可扩展rdbms通常只允许使用单值参数的udf[19]。这抑制了循环流水线,降低了性能(参见3.1节)。
我们也可以请求复合原语签名:
/(square(-(double*, double*)), double*)
上述签名是Mahanalobis距离,这是一些多媒体检索任务的性能关键操作[9]。我们发现复合原语的执行速度通常是单函数矢量原语的两倍。注意,这个因子2类似于表1中MonetDB/X100与手工编码的TPC-H Query实现之间的差异。复合原语效率更高的原因是更好的指令组合。就像3.1节在MIPS处理器上的加法示例一样,向量化执行经常成为加载/存储绑定,因为对于简单的2元计算,每条向量化指令需要加载两个参数并存储一个结果(1条工作指令,3条内存指令)。现代cpu通常每个周期只能执行1或2次加载/存储操作。在复合原语中,一次计算的结果通过CPU寄存器传递给下一个计算,加载/存储只发生在表达式图的边缘。
目前,原语生成器只不过是X100系统make序列中的一个宏扩展脚本。然而,我们打算通过一个优化器来实现复合原语的动态编译。
map原语的一个细微变化是select *原语(参见图2)。这些原语只存在于返回布尔值的代码模式中。与生成布尔值的完整结果向量不同(如map所做的那样),select原语填充由所选向量位置(整数)组成的结果数组,并返回所选元组的总数。
类似地,还有aggr *原语用于计算聚合,如count、sum、min和max。对于每种模式,都需要指定初始化、更新和尾声pattern。然后,原语生成器为X100中的各种聚合实现生成相关例程。
X100机制允许数据库扩展开发人员提供(源代码)pattern,而不是编译后的代码,这使得所有adt在查询执行期间都能获得一等公民待遇。这也是MIL(以及大多数可扩展dbms[19])的一个弱点,因为它的主要代数运算符仅针对内置类型进行了优化。
4.3 Data Storage
MonetDB/X100以列式分段的形式存储所有表。不管是使用新的ColumnBM缓冲区管理器,还是使用MonetDB BAT[void,T]存储,存储shema是相同的。而MonetDB将每个BAT存储在独立连续的文件中,ColumnBM将这些文件划分为大(>1MB)块。
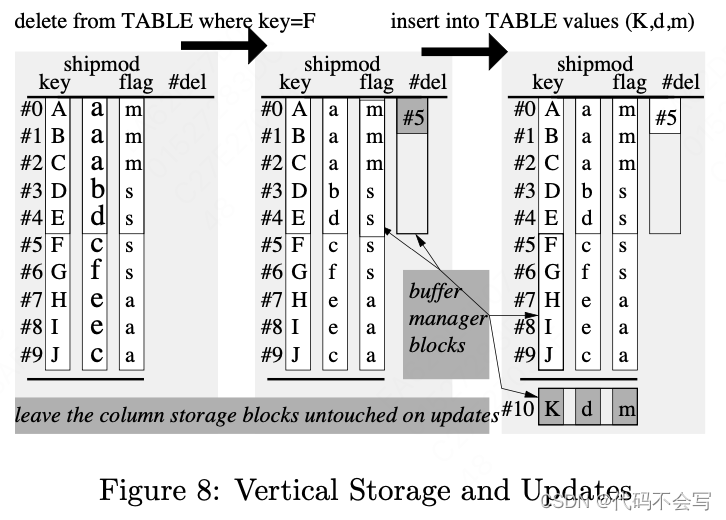
列式存储的缺点是更新成本增加:单行更新或删除必须对每列执行一次I/O。MonetDB/X100通过将列式片段视为不可变对象来解决这个问题。取而代之的是delta结构的更新。图8显示,通过将元组ID添加到删除列表来处理删除,而插入会导致在单独的增量列中添加追加。ColumnBM实际上将所有增量列存储在一个块中,这相当于PAX[2]。因此,这两个操作都只产生一个I/O。更新就是简单的删除,然后插入。更新会使增量列增长,这样,每当它们的大小超过总表大小的一个(很小的)百分位数时,就应该重新组织数据存储,以便垂直存储再次更新,增量列为空。
列式存储的一个优点是,访问许多元组但不是所有列的查询可以节省带宽(这对RAM带宽和I/O带宽都适用)。我们使用轻量级压缩进一步降低了带宽需求。MonetDB/X100支持枚举类型,它有效地将列存储为单字节或双字节整数。该整数表示映射表的#rowId。当在查询中使用此类列时,MonetDB/X100会自动添加Fetch1Join操作来检索使用小整数的未压缩值。请注意,由于列式片段是不可变的,所以更新只会到增量列(它们从未被压缩),并且不会使压缩方案复杂化。
MonetDB/X100还支持简单的“摘要”索引,类似于[12],当列被聚集(几乎排序)时使用。这些摘要索引包含一个#rowId,即列在基表中到该点为止的运行最大值,以及一个以非常粗的粒度反向运行的最小值(默认大小为1000个条目,以固定的间隔从基表中获取#rowId)。这些摘要索引可用于快速派生范围谓词的#rowId边界。再次注意,由于列式片段是不可变的属性,因此它们上的索引实际上不需要维护。增量列应该很小且位于内存中,它们没有索引,必须始终访问。
5 TPC-H Experiments
略
6 Related Work
略
7 Conclusion and Future Work
略
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!