python爬虫进阶篇:scrapy爬虫框架 兼职赚钱必备神器
2023-12-18 19:35:42
一、前言
- 前面几篇爬虫入门篇文章我自己设计了个简单的爬虫框架,适用于小型无反爬措施的网站。写这种爬虫框架的目的是理清爬虫的基本流程,方便我们更好理解更高级点的爬虫框架。
- 这篇笔记将介绍爬虫框架中最常用最实用的Scrapy。掌握这门框架技术,我们可以结合自己的日常需求比如:爬取股票信息、天气、新闻信息差等,然后用它去盈利,解放双手,用技术赚钱。
- Scrapy是一个很成熟的框架,此框架是为了爬取网站数据,提取结构性数据而编写的应用框架。 Scrapy通常应用在包括数据挖掘,信息处理或存储历史数据等一系列的项目中。像一些流媒体公司通常会用爬虫来收集电影数据(上座率、票价、好评率)、新闻点击率数据等。这些业务爬取的数据一般是公开的,当爬取的量存到一定数量级时,则可以进行市场分析、打包售卖信息等进行盈利。
- Scrapy框架最初是为了页面抓取 (更确切来说, 网络抓取)而设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫。它用途广泛,可以用于数据挖掘、监测和自动化测试。
二、框架解析
-
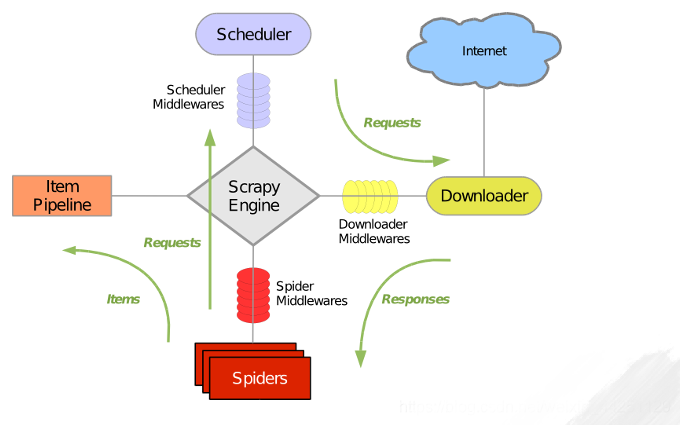
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下:
-
Scrapy运行流程大概如下:
- 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)。
- 然后,爬虫解析Response。
- 若解析出实体(Item),则交给实体管道进行进一步的处理。
- 若解析出的是链接(URL),则把URL交给Scheduler等待抓取
- Scrapy主要包括了以下组件:
- 爬虫引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)。
- URL调度器(Scheduler): 用来接收引擎发过来的请求, 存入队列中, 并在引擎再次请求的时候返回。可以想像成一个URL(爬取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是哪一个, 同时过滤掉重复的网址。
- 网页下载器(Downloader): 用于下载网页内容, 并将网页内容返回给爬虫(Scrapy下载器是建立在twisted这个高效的异步模型上的)。
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取、解析自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出,通常用来处理请求头封装、代理ip封装。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
三、拓展
在掌握好一个技术的理论基础后,接下来要做的就是实践。之后几篇爬虫进阶文章我将把scrapy爬虫的安装、新建、实践应用的过程分篇整理放上来,逐步实现各种日常需要用到的爬虫。
文章来源:https://blog.csdn.net/qq_23730073/article/details/135065388
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!