风速预测(二)基于Pytorch的EMD-LSTM模型
2023-12-14 09:36:49
目录

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较
前言
本文基于前期介绍的风速数据(文末附数据集),先经过经验模态EMD分解,然后通过数据预处理,制作和加载数据集与标签,最后通过Pytorch实现EMD-LSTM模型对风速数据的预测。风速数据集的详细介绍可以参考下文:
1 风速数据EMD分解与可视化
1.1 导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 读取已处理的 CSV 文件
df = pd.read_csv('wind_speed.csv' )
# 取风速数据
winddata = df['Wind Speed (km/h)'].tolist()
winddata = np.array(winddata) # 转换为numpy
# 可视化
plt.figure(figsize=(15,5), dpi=100)
plt.grid(True)
plt.plot(winddata, color='green')
plt.show()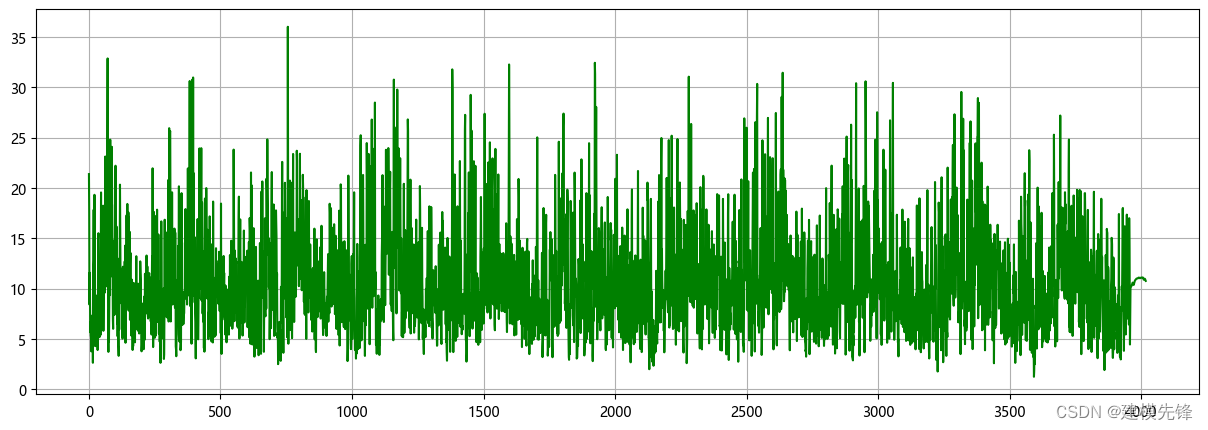
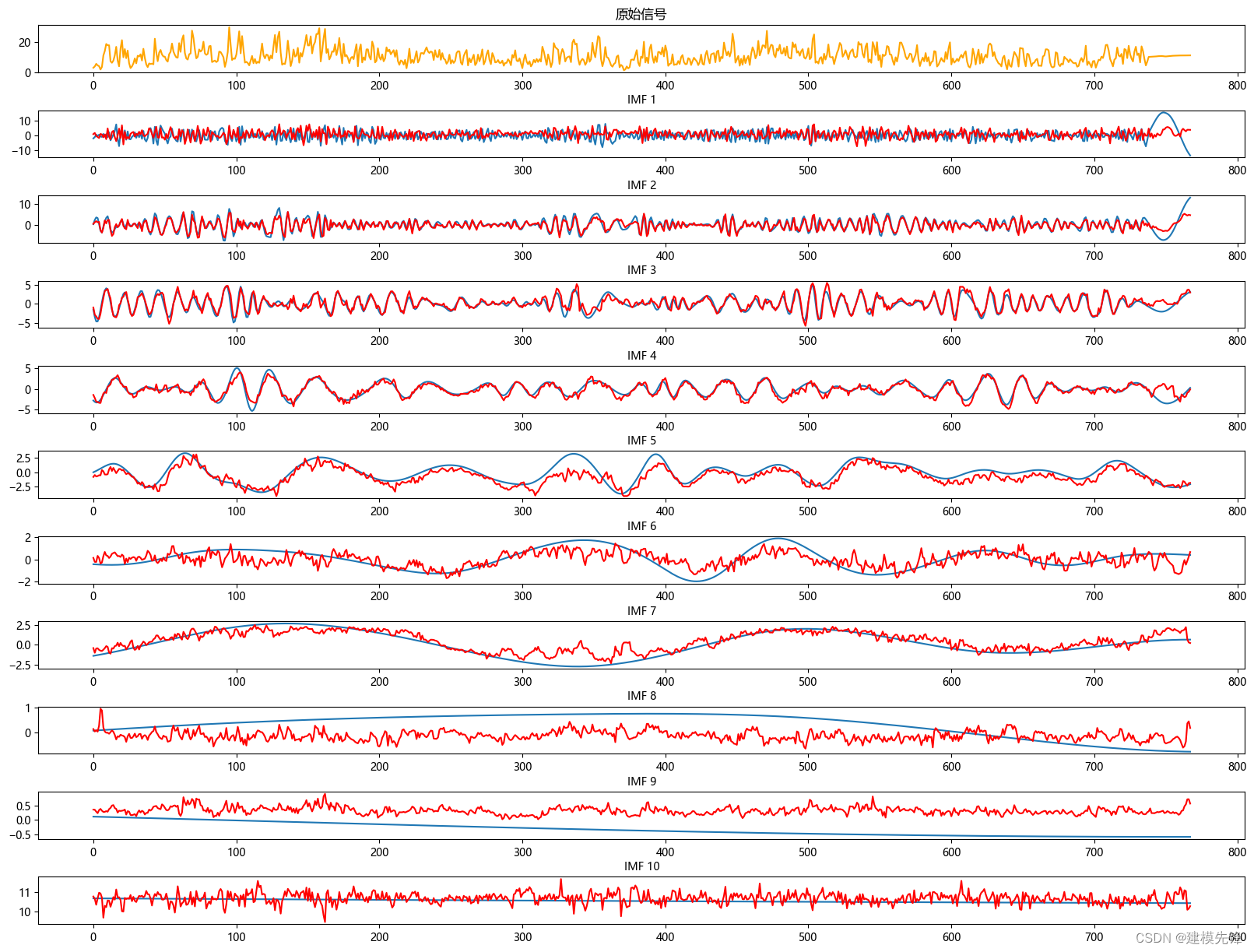
1.2 EMD分解
from PyEMD import EMD
# 创建 EMD 对象
emd = EMD()
# 对信号进行经验模态分解
IMFs = emd(winddata)
# 可视化
plt.figure(figsize=(20,15))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(winddata, 'r')
plt.title("原始信号")
for num, imf in enumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(imf)
plt.title("IMF "+str(num+1), fontsize=10)
# 增加第一排图和第二排图之间的垂直间距
plt.subplots_adjust(hspace=0.8, wspace=0.2)
plt.show()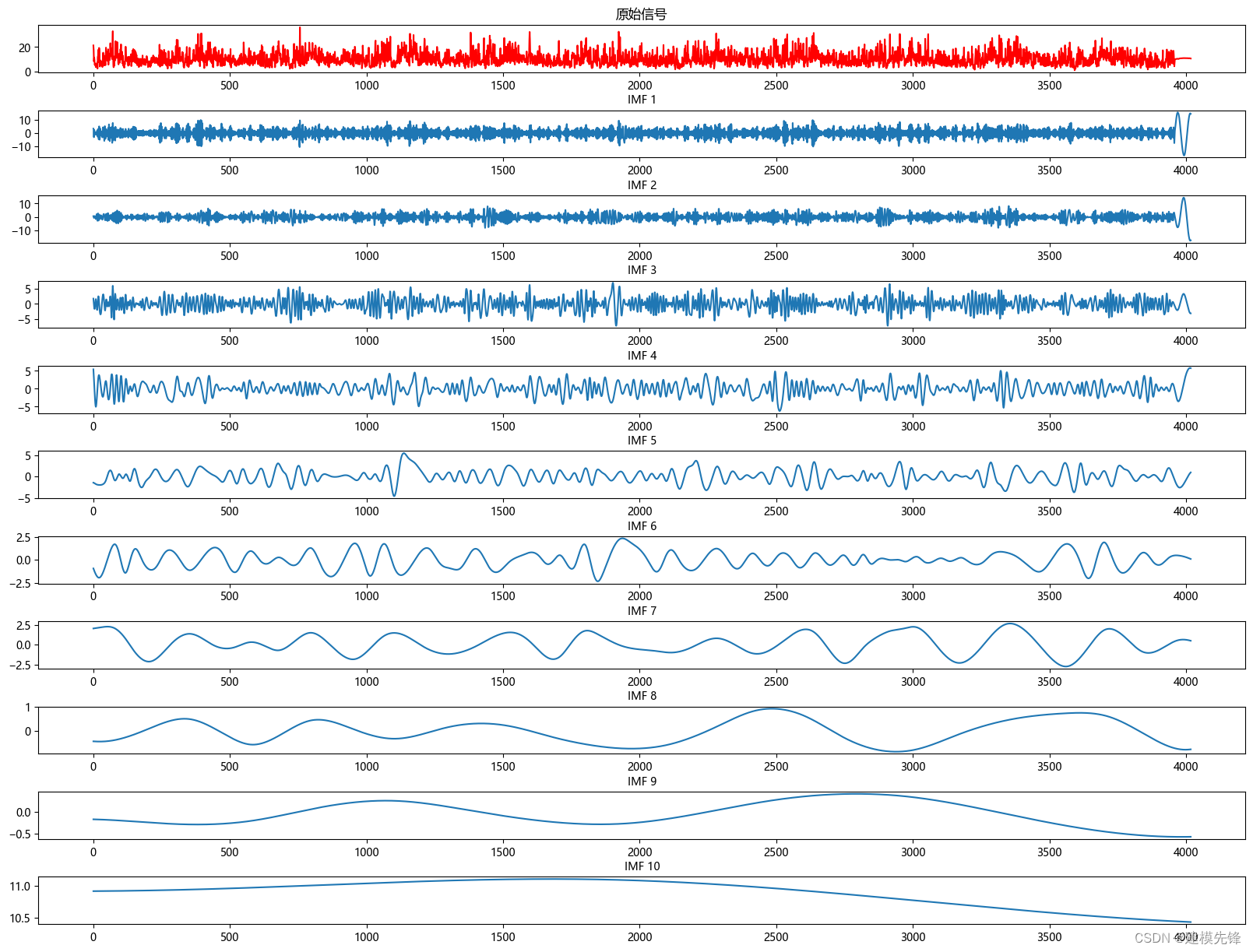
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集
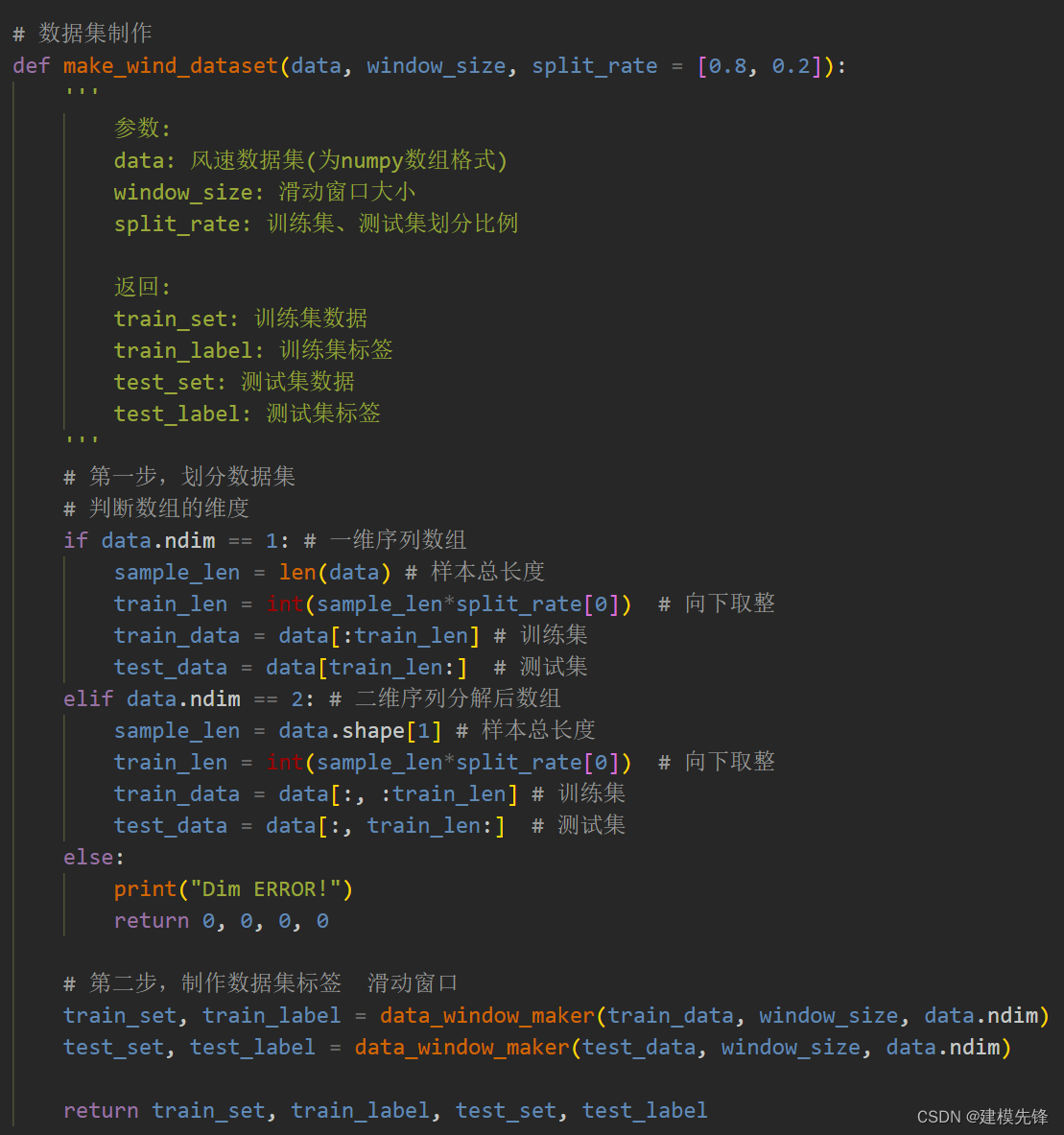
2.2 设置滑动窗口大小为7,制作数据集

3 基于Pytorch的EMD-LSTM模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集
def dataloader(batch_size, workers=2):
# 训练集
train_set = load('train_set')
train_label = load('train_label')
# 测试集
test_set = load('test_set')
test_label = load('test_label')
# 加载数据
train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_set, train_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_set, test_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
return train_loader, test_loader
batch_size = 64
# 加载数据
train_loader, test_loader = dataloader(batch_size)3.2 定义EMD-LSTM预测模型

注意:输入风速数据形状为 [64, 10, 7], batch_size=64,? 维度10维代表10个分量,7代表序列长度。
3.3 定义模型参数
# 定义模型参数
batch_size = 64
input_dim = 10 # 输入维度为10个分量
hidden_layer_sizes = [16, 32, 64, 128] # LSTM隐藏层
output_size = 1 # 单步输出
model = EMDLSTMModel(batch_size, input_dim, hidden_layer_sizes)
# 定义损失函数和优化函数
model = model.to(device)
loss_function = nn.MSELoss() # loss
learn_rate = 0.0003
optimizer = torch.optim.Adam(model.parameters(), learn_rate) # 优化器3.4 模型结构
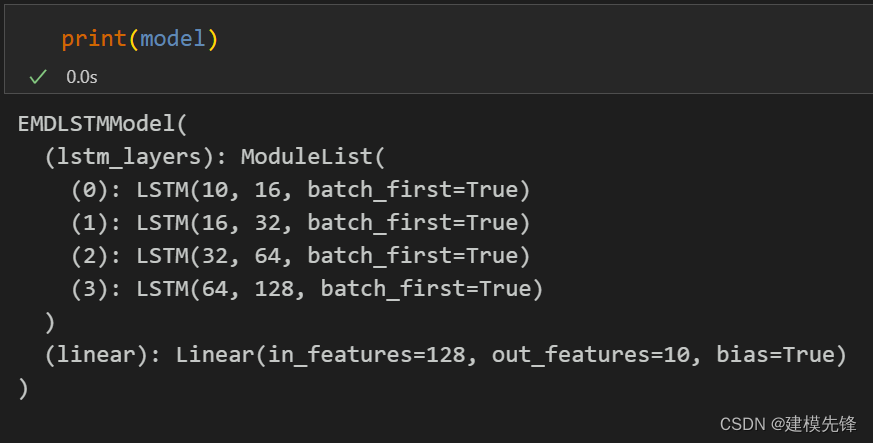
3.5?模型训练
训练结果
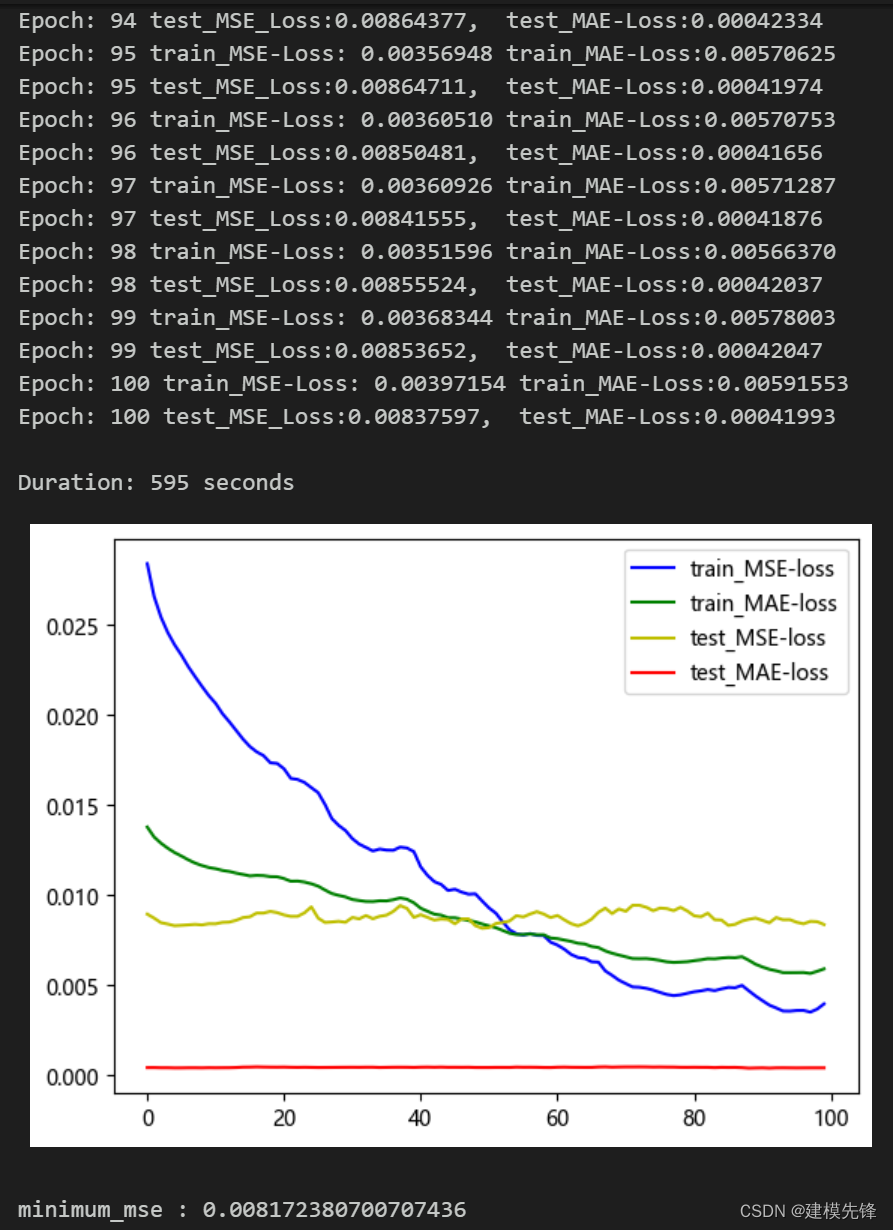
采用两个评价指标:MSE 与 MAE 对模型训练进行评价,100个epoch,MSE 为0.0081,MAE? 为 0.00044,EMD-LSTM预测效果良好,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加 LSTM层数 和隐藏层的维度,微调学习率;
-
增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
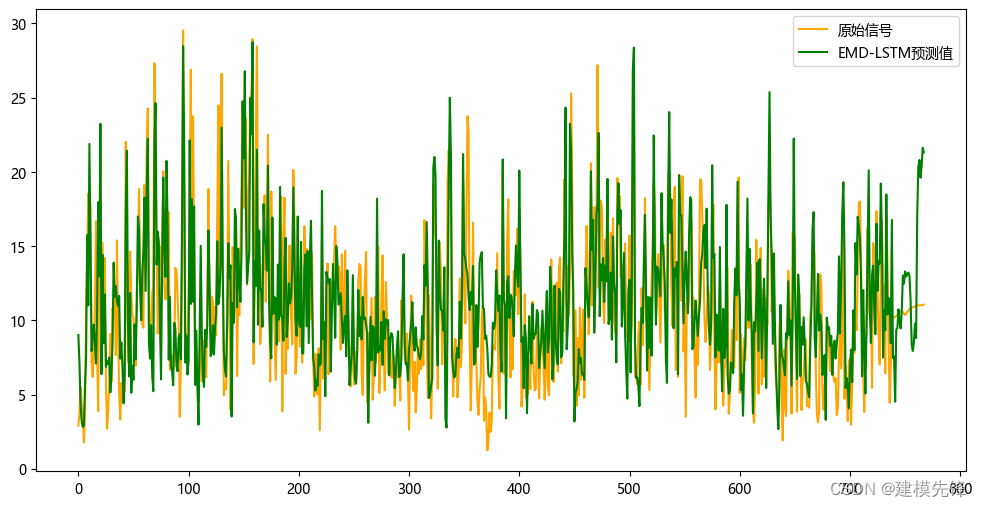
3.6 结果可视化

文章来源:https://blog.csdn.net/qq_40949048/article/details/134950943
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!