Flink实时电商数仓(五)
2023-12-23 22:36:36
FlinkSQL的join
- Regular join普通join,两条流的数据都时存放在内存的状态中,如果两条流数据都很大,对内存压力很大。
- Interval Join: 适合两条流到达时间有先后关系的;一条流的存活时间短,一条流的存活时间长。
- Lookup Join:适合主流特别大,从流特别小的情况;主流数据没到达一条,就会去查询从流的每一条数据。主流数据不存储在内存中。
- 语法:主流使用时必须有处理时间,
proctime as PROCTIME() - 在从流表名和别名之间添加
FOR SYSTEM_TIME AS OF c.proc_time - 参数位置,官网->application Development -> Table API & SQL -> Configuration, 在该网页搜索lookup即可查询到相应参数配置,比如:
- table.exec.async-lookup.buffer-capacity: 缓冲队列的大小
- table.exec.async-lookup.output-mode:数据输出的模式,是否有序
- table.exec.async-lookup.timeout:lookup超时时间
- 语法:主流使用时必须有处理时间,
交易域下单事务事实表
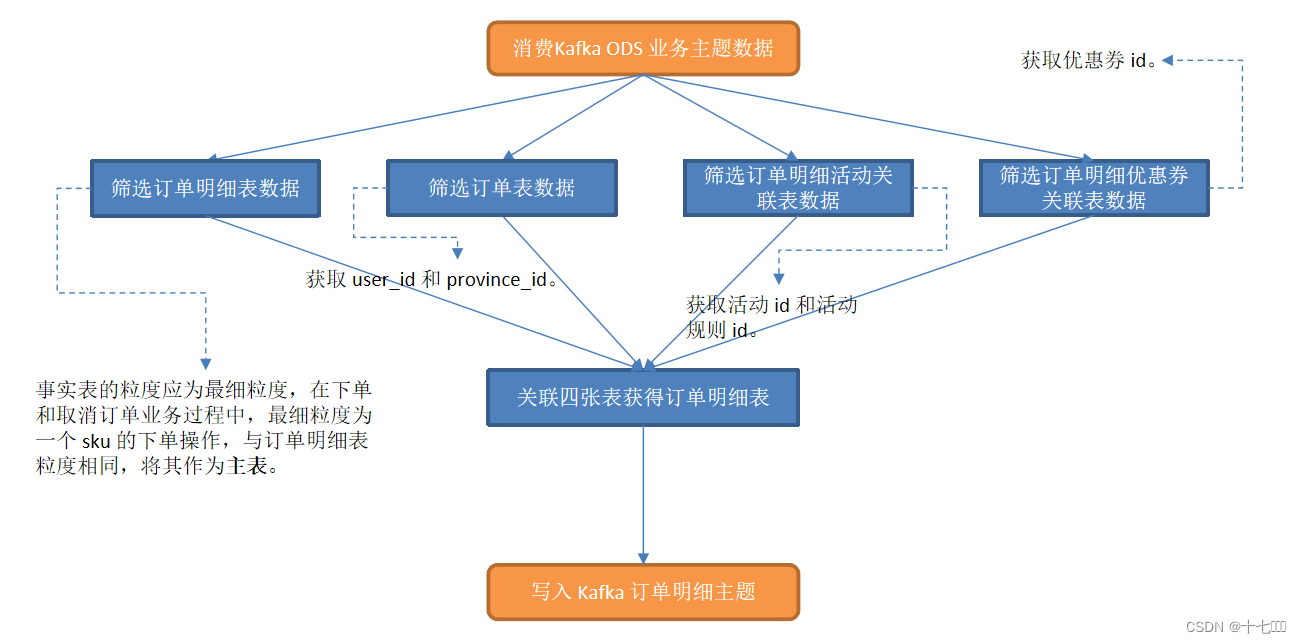
- 交易事务关联的表总共有四个表
- order_detail
- order_info
- order_detail_activity
- order_detail_coupon
- 设置ttl状态生存时间,设置网络波动延迟时间为5s
- 关联四张表获取到订单明细表,order_detail和order_info使用内连接即可,活动和优惠券表使用left join即可。
- 核心业务编写
- 读取topic_db数据
- 筛选订单详情order_detail表数据
- 筛选订单信息表order_info
- 筛选订单详情活动关联表
- 筛选订单详情优惠券关联表
- 将四张表join合并
- 写出到kafka中:一旦使用了left join,会产生撤回流,此时如果需要将数据写出到kafka,不能使用kafka连接器,必须使用upsert kafka连接器。
- upsert kafka必须声明主键
文章来源:https://blog.csdn.net/qq_44273739/article/details/135164650
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!