Crowd Counting近期研究(附代码资源)
1.Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes
paper:https://arxiv.org/abs/2310.10352
code:https://github.com/cha15yq/MRC-Crowd
摘要:
为了减轻训练可靠的人群计数模型所需的繁重标注负担,从而使该模型能够受益于更多数据,更加实用和准确,本文提出了一种基于Mean Teachers框架的新型半监督方法。当可用的标注数据稀缺时,模型容易出现局部图像块过拟合的情况。在这种情况下,仅通过非标记数据来提高局部图像块预测准确度的传统方法被证明是不够的。因此,我们提出了一种更细致的方法:培养模型内在的 "subitizing "能力。这种能力使模型能够利用其对人群场景的理解来准确估计区域内的计数,这与人类的认知过程如出一辙。为了实现这一目标,我们对未标记的数据进行了掩膜处理,引导模型根据整体线索对这些被掩膜的图像块进行预测。此外,为了帮助进行特征学习,我们在这里加入了细粒度密度分类任务。我们的方法具有通用性,适用于大多数现有的人群统计方法,因为它没有严格的结构或损失约束。此外,我们还观察到,用我们的框架训练出来的模型表现出类似于 "subitizing "的行为。它只需 "glance "就能准确预测低密度区域,同时结合局部细节预测高密度区域。我们的方法达到了最先进的性能,在 ShanghaiTech A 和 UCF-QNRF 等具有挑战性的基准测试中大大超过了以前的方法。
笔者备注:
Mean Teachers:
Mean Teachers是2018年提出的一种半监督学习算法,该算法是针对Temporal Ensembling计算成本大(在一个epoch上更新一次目标标签)提出的改进算法,不同之处是Temporal Ensembling基于时间记忆的Exponential Moving Average(EMA)是在预测结果上,而Mean Teachers是在模型的权重上。且该算法的核心思想是将模型分为教师和学生,老师用来生成学生学习的目标,学生用老师提供的目标来进行学习,而老师模型的权重是通过学生模型时间记忆的加权平均得到,同时该算法也是基于一致性正则化,认为输入数据添加一个微小的扰动噪声时,模型的预测结果不会发生变化。
subitizing:
通常我们对少于5个的物体进行计数时,不用犹豫就可以一口说出准确的数目。这种能力叫做Subitizing。中文没有固定的翻译,一般叫“数觉”或“数感”,因此摘要中使用了glance这个词,看一眼就准确知道。
主要贡献:
?受整体模式(分类的认知现象)重要性的启发,我们建议利用未标记的图像来增强对计数模型场景的整体理解,这有效地缓解了半监督问题中模型过度拟合局部细节的问题。
?我们提出了一个简单的半监督人群计数框架,称为MRC人群。它通过重建未标记图像中掩蔽块的密度信息来更好地理解人群场景。我们的框架用途广泛,只需要两层分类头作为插件来促进特征学习,使其能够轻松应用于各种计数模型。
?我们在几个基准上建立了新的最先进的结果,这进一步证明了上下文建模能力在计数模型中的重要性。特别是在具有挑战性的UCF-QNRF 数据集上,我们的方法实现了13.2%的平均减少
框架:

(a)MRC群组中采用的基本网络结构。它包含一个骨干网络、一个自上而下的多级特征融合模块、一个回归头和一个分类头。我们采用VGG-19作为骨干网络。(b) 拟议的MRC群组的总体框架图。标记的数据用于通过优化和
来训练学生模型。使用学生模型的权重的指数移动平均值来更新教师模型。具有强扰动的未标记数据被馈送到学生模型,而监督信号由教师模型对没有强扰动的相同数据的预测提供。回归任务和分类任务都是有监督的。使用
对无监督学习过程进行了优化。
消融实验:
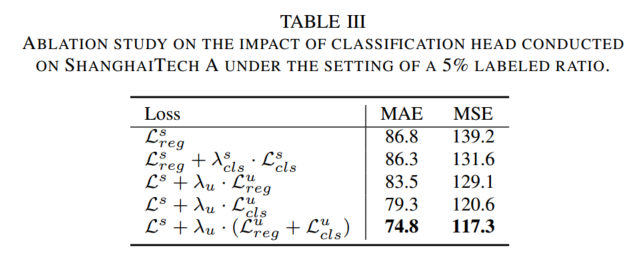
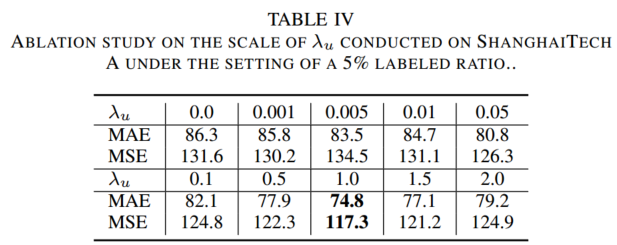


?
2.Point-Query Quadtree for Crowd Counting, Localization, and More
paper:https://arxiv.org/pdf/2308.13814.pdf
code:https://github.com/cxliu0/PET
摘要:
我们证明,人群计数可被视为一个可分解的点查询过程。这种表述方式可以将任意点作为输入,并共同判断这些点是否属于人群以及它们的位置。然而,查询处理在必要的查询点数量上存在潜在问题。数量太少意味着估计不足,数量太多又会增加计算开销。为了解决这一难题,我们引入了一种可分解结构,即点查询四叉树(point-query quadtree),并提出了一种新的计数模型,称为点查询转换器(Point query Transformer,PET)。PET 通过依赖数据的四叉树拆分实现可分解的点查询,其中每个查询点在必要时可拆分为四个新点,从而实现对稀疏和密集区域的动态处理。由于输入和输出都是可解释和可引导的,因此这种查询过程能产生直观、通用的人群建模。我们展示了 PET 在许多人群相关任务中的应用,包括完全监督的人群计数和定位、部分注释学习和点注释完善,并报告了其最新性能。我们首次证明,一个计数模型可以解决不同学习范式中的多个人群相关任务。
主要贡献:
?我们表明,可分解点查询可以成为一种通用的群组建模思想,有可能统一与群组相关的任务。
?我们介绍了PET,一种用于人群计数的点查询转换器,其特点是点查询四叉树和渐进矩形窗口关注。
框架:

现有技术与我们的点查询计数范式之间的比较。与(a)现有技术相反,我们将任意点视为输入,并推理每个点是否是人以及该人位于何处。我们设计了(b)一个点查询四叉树来处理具有自适应树分裂的密集人群。查询设计使PET成为一种直观而通用的方法,支持(c)各种应用程序,如完全监督的人群计数和定位、部分注释学习和点注释细化。

PET的总体架构。我们首先使用CNN主干来提取图像表示。然后将具有渐进矩形窗口注意力的变换编码器应用于
来编码上下文。随后,四叉树分离器接收稀疏查询点和编码特征作为输入,输出点查询四叉树。变换器解码器然后并行解码点查询,其中在局部窗口内计算注意力。这些点查询最终通过预测头来获得人群预测,即“没有人”或“一个人”及其概率和定位。
对比实验
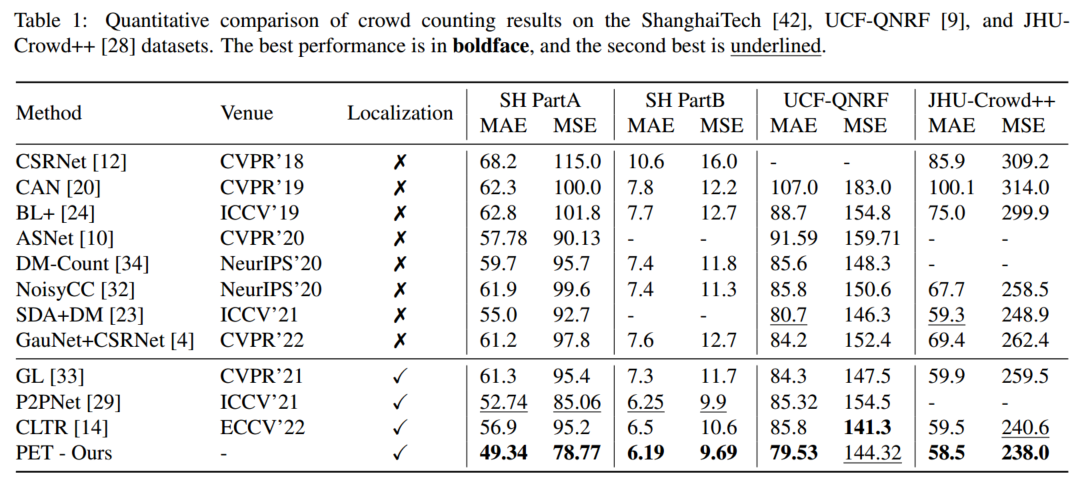
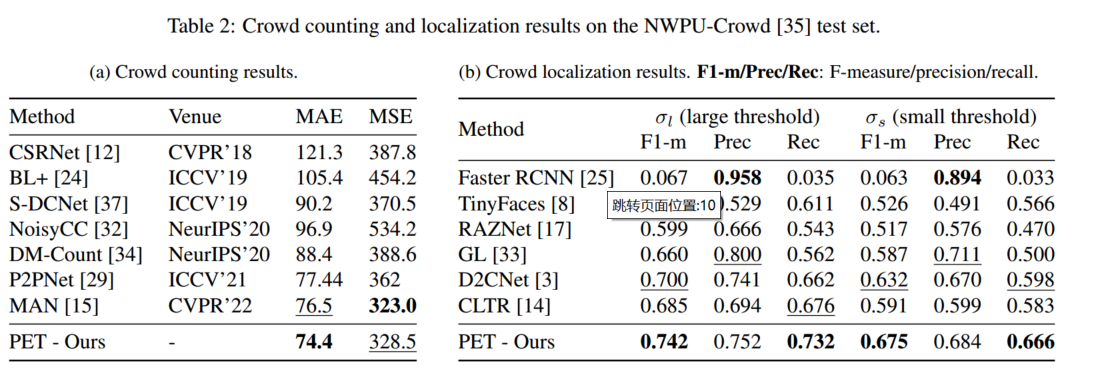
消融实验

?
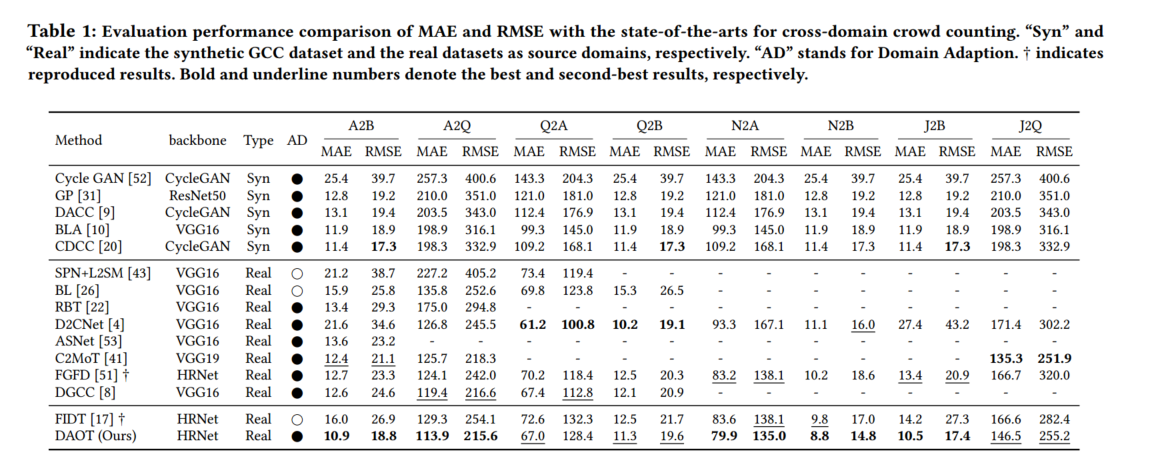
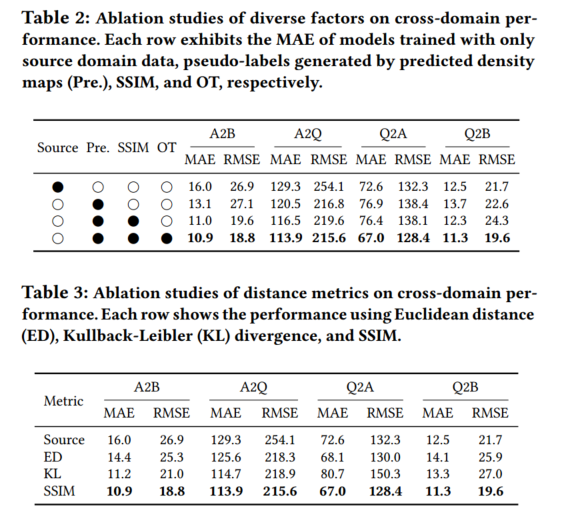
3.DAOT: Domain-Agnostically Aligned Optimal Transport for Domain-Adaptive Crowd Counting
paper:https://arxiv.org/pdf/2308.05311.pdf
code:https://github.com/HopooLinZ/DAOT/
摘要:
在人群统计中,通常采用领域适应技术来弥合不同数据集之间的领域差距。然而,现有的领域适应方法往往只关注数据集之间的差异,而忽略了同一数据集内部的差异,从而导致额外的学习模糊性。这些与领域无关的因素,如密度、监控视角和规模等,会造成显著的领域内差异,而这些因素在不同领域间的错位会导致跨领域人群计数的性能下降。为解决这一问题,我们提出了一种域无关对齐最优传输(Domain-agnostically Aligned Optimal Transport,DAOT)策略,可对域之间的域无关因素进行对齐。DAOT 包括三个步骤。首先,使用结构相似性(structural similarity, SSIM)测量个体层面的领域无关因素差异。其次,采用最佳转移(optimal transfer, OT)策略来平滑这些差异,并找到最佳的领域间错位,通过虚拟 "dustbin "列去除离群个体。第三,根据对齐的领域无关因素进行知识转移,并对模型进行领域适应性再训练,以弥合跨领域差距。我们在五个标准人群计数基准上进行了广泛的实验,证明所提出的方法在不同的数据集上具有很强的通用性
笔者备注:
Optimal Transport
最优传输(Optimal Transport)是多个学科交叉的研究领域,包括概率、分析以及优化等。最优传输研究的主要目标是建立有效比较概率分布的几何工具。
dustbin
非特征点dustbin,不是垃圾箱,参考论文“SuperPoint: Self-Supervised Interest Point Detection and Description”
主要贡献:
?我们对领域不可知因素在人群计数中的影响提出了一个新的视角,强调了它们对领域内变化的重大影响,以及由于领域层面的错位而导致的较差的跨领域性能。这一发现使我们更好地了解了域差距以及域对齐对提高跨域性能的重要性。
?我们设计了一种新的域自适应方法,称为域不可知对齐最优传输(DAOT),通过对齐源域和目标域之间的域不可知因素错位来弥合域差距。
?我们通过在五个人群计数数据集上的广泛实验,证明了所提出的DAOT的有效性和强可推广性。实验结果表明,DAOT的性能优于最先进的方法。
框架:

评估实验/消融实验
4.Accurate Gigapixel Crowd Counting by Iterative Zooming and Refinement
paper:https://arxiv.org/pdf/2305.09271.pdf
code:MaLeCi / GigaZoom · GitLab
摘要:
千兆像素分辨率的日益普及为人群计数带来了新的挑战。这种分辨率远远超出了当前 GPU 的内存和计算极限,而且现有的深度神经网络架构和训练程序也不是为这种大规模输入而设计的。虽然已经提出了几种方法来应对这些挑战,但这些方法要么仅限于将输入图像降采样到较小尺寸,要么借用其他千兆像素任务的方法,而这些方法并不适合人群计数。在本文中,我们提出了一种名为 GigaZoom 的新方法,它可以迭代放大图像中密度最高的区域,并用更精细的细节完善更粗糙的密度图。通过实验,我们发现 GigaZoom 在千兆像素人群计数方面达到了最先进的水平,并将次好方法的精确度提高了42%。
原理图
由于本文只是一个方法,并没有深度学习框架图

(左)PANDA数据集的示例千兆像素图像,分辨率为26908×15024,下采样至2688×1412;(右)放大到原始图像中矩形指定的区域,分辨率为2880×1410像素。

迭代缩放和替换中的正向过程概述

?
迭代缩放和替换中的反向过程概述。

(a) 平滑的密度图以及检测到的、滤波的和聚类的峰值;以及(b)平滑的密度图的三维可视化。
实验



结论:
我们证明,我们提出的方法在千兆像素图像上的人群计数方面显著优于现有方法。通过消融研究,我们发现指数缩放比线性缩放性能更好,适度数量的缩放级别可以实现最佳精度,并且使用多个缩放区域可以为具有多个密集人群的输入提供鲁棒性。
尽管GigaZoom比Gigapixel CSRNet高效得多,但它仍然执行多个CSRNet推断,这可能导致整体推断时间较长。
目前,PANDA是该任务唯一公开可用的数据集,仅包含从三个场景拍摄的45张图像。为了进一步比较和验证方法,至关重要的是创建和发布更多的千兆像素人群计数数据集,这些数据集具有更多来自不同场景的示例。
5.Diffuse-Denoise-Count: Accurate Crowd-Counting with Diffusion Models
paper:https://arxiv.org/pdf/2303.12790.pdf
code:GitHub - dylran/DiffuseDenoiseCount
摘要:
人群计数是人群分析的一个重要方面,通常通过估算人群密度图并对密度值求和来实现。然而,由于使用广义高斯核来创建地面实况密度图,这种方法存在背景噪声累积和密度损失的问题。这个问题可以通过缩小高斯核来解决。然而,现有方法在使用此类地面实况密度图进行训练时表现不佳。为了克服这一局限性,我们建议使用条件扩散模型(diffusion models)来预测密度图,因为众所周知,扩散模型能很好地模拟复杂分布,并在人群密度图生成过程中对训练数据表现出很高的保真度。此外,由于扩散过程的中间时间步骤是有噪声的,因此我们只在训练过程中加入一个回归分支来直接进行人群估计,以改进特征学习。此外,由于扩散模型的随机性,我们引入了生成多个密度图的方法,以提高计数性能,这与现有的人群计数管道截然不同。此外,我们还与密度求和不同,引入了轮廓检测,然后求和作为计数操作,这对背景噪声更有免疫力。我们在公共数据集上进行了大量实验,以验证我们方法的有效性。具体来说,我们新颖的人群计数管道在 JHU-CROWD++ 和 UCF-QNRF 上分别改善了 6% 和 7% 的人群计数误差。
笔者备注:
diffusion models
扩散模型综述:Diffusion Models: A Comprehensive Survey of Methods and Applications
扩散模型代码资源汇总:https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
扩散模型简介:扩散模型(diffusion models)是深度生成模型中新的SOTA(state-of-the-art,防止小白,大佬忽略)。扩散模型在图片生成任务中超越了原SOTA:GAN,并且在诸多应用领域都有出色的表现,如计算机视觉,NLP、波形信号处理、多模态建模、分子图建模、时间序列建模、对抗性净化等。此外,扩散模型与其他研究领域有着密切的联系,如稳健学习、表示学习、强化学习。

主要贡献:
?我们将人群密度图的生成公式化为去噪扩散过程。据我们所知,这是第一项使用扩散模型进行人群计数的研究。
?我们提倡使用窄高斯核来简化学习过程,并促进高质量密度图的生成,使其更接近真实高斯核。
?我们引入了通过轮廓检测进行计数,这是通过使用窄核而不是像素求和实现的。
?我们提出了一种机制,将多个人群密度实现合并为一个结果,以利用扩散模型的随机性来提高计数性能。
?我们表明,所提出的方法在公共人群计数数据集上的性能超过了SOTA。
框架:

?
人群密度图是从人群图像的去噪扩散过程中生成的。接下来,对所得到的人群密度实现执行轮廓检测,以创建人群地图。然后将群组地图融合为单个群组地图。计数分支使用去噪U-Net的编码器-解码器特征并行训练,并在推理过程中丢弃。

人群图融合准则。拒绝半径是根据邻居半径内的邻居(黑色)来计算的。位于拒绝半径内的新点(彩色)将被移除(红色),其余点(绿色)将合并到复合贴图中。
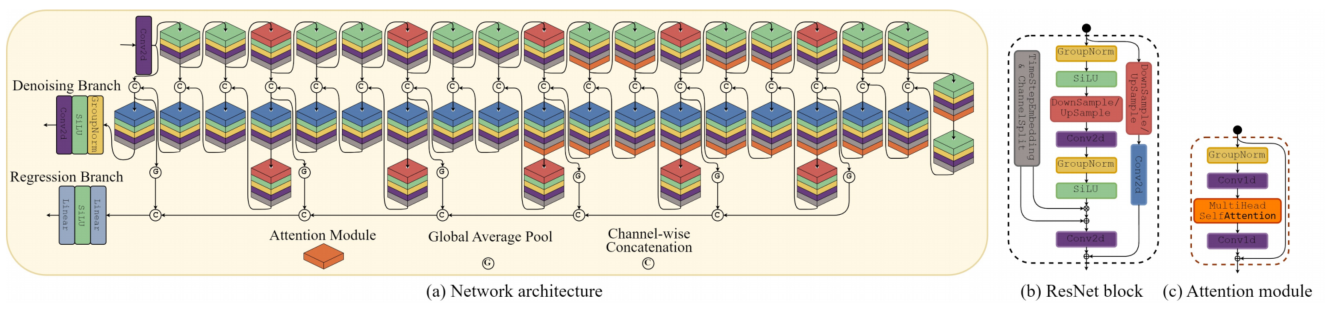
(a) 结合计数回归分支和基本模块的用于去噪U-Net网络架构(b)ResNet块和(c)注意力模块,用于构建网络。堆栈中的每个立方体表示ResNet块中的功能模块以及是否应用了注意力模块。顶部堆栈在编码器中。底部堆栈在解码器中
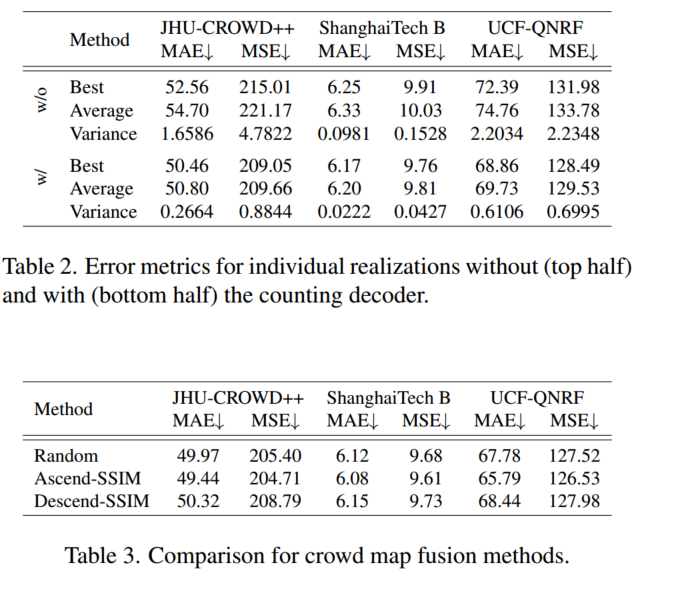
实验/消融:

6.CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model
paper:https://arxiv.org/abs/2304.04231
摘要:
有监督的人群计数在很大程度上依赖于昂贵的人工标注,这既困难又昂贵,尤其是在密集场景中。为了缓解这一问题,我们提出了一种新颖的无监督人群计数框架,名为 CrowdCLIP。其核心思想建立在两个观察基础之上:
1) 最近的对比性预训练视觉语言模型(CLIP)在各种下游任务中表现出色;
2) 在人群图像块和计数文本之间存在自然映射。据我们所知,CrowdCLIP 是第一个研究视觉语言知识来解决计数问题的模型。具体来说,在训练阶段,我们利用多模态排序损失,通过构建排序文本提示来匹配按大小排序的人群图像块,从而指导图像编码器的学习。在测试阶段,为了应对图像块的多样性,我们提出了一种简单而有效的渐进式过滤策略,首先选择极具潜力的人群块,然后将其映射到具有不同计数间隔的语言空间中。在五个具有挑战性的数据集上进行的广泛实验表明,与以前的无监督先进计数方法相比,所提出的 CrowdCLIP 实现了更优越的性能。值得注意的是,在跨数据集设置下,CrowdCLIP 甚至超过了一些流行的全监督方法。
主要贡献:
1)在本文中,我们提出了一种新的无监督人群计数方法CrowdCLIP,该方法创新地将人群计数视为一个图像-文本匹配问题。据我们所知,这是第一个将视觉语言知识转移到人群计数中的工作。2) 我们引入了一种基于排名的对比微调策略,使图像编码器更好地挖掘潜在的人群语义。此外,提出了一种渐进滤波策略,以选择高相关性的群组补丁,用于在测试阶段映射到适当的计数间隔。
框架:

(a) 在训练阶段,我们通过引入排名提示来微调图像编码器,同时冻结文本编码器的参数。(b) 在测试阶段,我们提出了一种渐进式过滤策略,该策略逐步查询最可能的群组补丁,并将过滤后的补丁映射到特定的定量计数中。
实验/消融

7.An end-to-end transformer model for crowd localization
paper:https://arxiv.org/pdf/2202.13065.pdf
code:https://github.com/dk-liang/CLTR
摘要:
人群定位,即预测头部位置,是一项比简单计数更实用、更高级的任务。现有方法采用伪包围盒或预先设计的定位图,依靠复杂的后处理来获取头部位置。在本文中,我们提出了一种名为 CLTR 的优雅端到端人群定位转换器,它可以在基于回归的范例中解决这项任务。所提出的方法将人群定位视为直接集预测问题,将提取的特征和可训练的 embedding 作为变换器-解码器的输入。为了减少模糊点并生成更合理的匹配结果,我们引入了基于 KMO 的匈牙利匹配器,它采用附近的上下文作为辅助匹配成本。在不同数据设置下的五个数据集上进行的广泛实验表明了我们方法的有效性。特别是在 NWPU-Crowd、UCF-QNRF 和 ShanghaiTech Part A 数据集上,我们提出的方法取得了最佳的定位性能。
主要贡献:
1)我们提出了一个名为CLTR的端到端人群定位转换器框架,该框架将人群定位公式化为点集预测任务。CLTR通过去除预处理和后处理,显著简化了人群定位pipeline。2) 我们介绍了基于KMO的匈牙利二部分匹配,它将来自附近头部的上下文作为辅助匹配代价。因此,匹配器可以有效地减少歧义点,并生成更合理的匹配结果。
在五个挑战数据集上进行了广泛的实验,基于KMO的匈牙利匹配器的显著改进表明了其有效性。特别是,仅使用单一比例和低分辨率(输入图像的1/32)特征图,CLTR就可以实现最先进或极具竞争力的定位性能
框架:
?

对比实验:



8.Super-Resolution Information Enhancement For Crowd Counting
paper:https://arxiv.org/pdf/2303.06925.pdf
code:https://github.com/PRIS-CV/MSSRM
摘要:
由于存在严重的遮挡、尺度和密度变化,人群计数是一项具有挑战性的任务。现有方法在有效处理这些挑战的同时,却忽略了低分辨率(low-resolution,LR)情况。低分辨率情况会严重削弱计数性能,主要有两个原因: 1) 细节信息有限;2) 重叠的头部区域在密度图中累积,导致地面实况值极端化。一个直观的解决方案是对输入的 LR 图像进行超分辨率(low-resolution,SR)预处理。然而,这种方法会使推理步骤复杂化,从而限制了需要实时性的应用潜力。我们提出了一种更优雅的方法,称为多尺度超分辨率模块(Multi-Scale Super-Resolution Module, MSSRM)。它能引导网络估计丢失的细节,并增强特征空间中的详细信息。值得注意的是,MSSRM 是插件式的,无需推理成本即可处理 LR 问题。由于提出的方法需要 SR 标签,我们进一步提出了超分辨率人群计数数据集(SR-Crowd)。在三个数据集上的广泛实验证明了我们方法的优越性。
主要贡献:
1.我们提出了一种MSSRM,它可以引导网络估计可靠的细节信息,并在没有推理成本的情况下提高LR情况下的计数性能。
2.介绍了大规模超分辨率人群数据集SR Crowd。据我们所知,这是人群计数领域的第一个超分辨率数据集。
3.在SR Crowd和两个主流人群计数数据集上的大量实验证明了我们方法的有效性。
框架:

拟建MSSRGN。具体地,一个LR图像被馈送到主干中。然后,将输出特征同时馈送到两个分支,即后端CNN和MSSRM。具体而言,后端网络生成密度图以估计人群数量。MSSRM模块预测SR图像并完成SR任务。
对比实验:

9.Cross-head Supervision for Crowd Counting with Noisy Annotations
paper:https://arxiv.org/pdf/2303.09245.pdf
code:https://github.com/RaccoonDML/CHSNet
摘要:
由于多尺度的头部大小、高度遮挡等原因,人群计数数据集中经常存在诸如缺失注释和位置偏移等噪声注释。这些噪声注释严重影响了模型训练,尤其是基于密度图的方法。为了减轻噪声注释带来的负面影响,我们提出了一种新的人群计数模型,该模型包含一个卷积头和一个变换头,在噪声区域,这两个头可以相互监督,我们称之为交叉头监督(Cross-Head Supervision)。由此产生的模型 CHS-Net 可以协同不同类型的归纳偏差,从而获得更好的计数效果。此外,我们还开发了一种渐进式交叉头监督学习策略,以稳定训练过程并提供更可靠的监督。在 ShanghaiTech 和 QNRF 数据集上的大量实验结果表明,CHS-Net 的性能优于最先进的方法。
主要贡献:
1) 我们提出了一种新的模型CHS-Net,该模型具有一个卷积头和一个变换头,以在噪声区域中相互监督;2) 我们设计了一种渐进式跨学科监督学习策略,使训练过程更加稳定;3)我们的CHS-Net在几个基准数据集上实现了卓越的性能。
框架:

CHS-Net的体系结构由一个共享编码器和两个回归头组成——一个卷积头和一个变换头。在每个头的末端,连接一个相同结构的回归块以生成密度图。红框表示遗漏注释的区域,其中精细化监督比地面实况监督更可靠。
对比实验/消融实验:




10.Boosting Detection in Crowd Analysis via Underutilized Output Features
paper:https://arxiv.org/pdf/2308.16187.pdf
code:GitHub - wskingdom/Crowd-Hat
摘要:
由于基于检测的方法在密集人群中表现不佳,因此在人群分析中一直被认为是不利的。然而,我们认为这些方法的潜力被低估了,因为它们为人群分析提供了关键信息,而这些信息往往被忽视。具体来说,输出建议和边界框的面积大小和置信度得分可以让我们深入了解人群的规模和密度。为了充分利用这些未被充分利用的特征,我们提出了 Crowd Hat,这是一个即插即用的模块,可以轻松地与现有的检测模型集成。该模块使用 2D-1D 混合压缩技术来完善输出特征,并获得人群特定信息的空间和数值分布。基于这些特征,我们进一步提出了区域自适应 NMS 阈值和 "解耦-对齐 "范式,从而解决了基于检测方法的主要局限性。我们对各种人群分析任务(包括人群计数、定位和检测)进行了广泛评估,证明了利用输出特性的有效性以及基于检测的方法在人群分析中的潜力。
主要贡献:
?据我们所知,我们是第一个将检测输出视为人群分析中有价值的特征的人,并提出了混合2D-1D压缩来从中细化人群特定特征。
?我们引入了区域自适应NMS阈值和先解耦后对齐的范式,以减轻人群分析中基于检测的方法的主要缺点。
?我们在人群计数、定位和检测任务的公共基准上评估了我们的方法,表明我们的方法可以适应不同的检测方法,同时实现更好的性能。
框架:

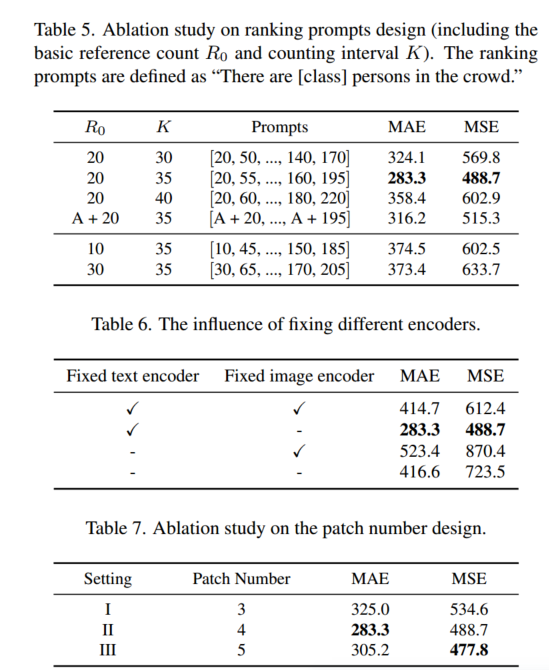
Crowd Hat module概述。我们采用两阶段检测方法PSDNN作为我们的检测pipeline进行说明。
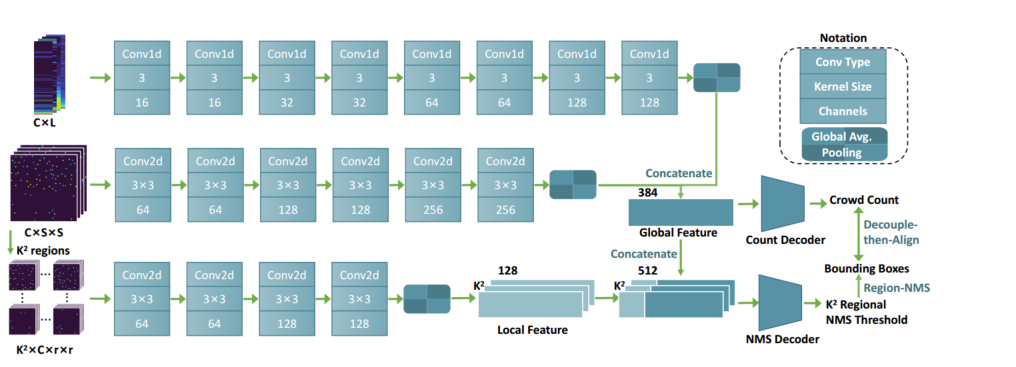
Crowd Hat module的详细神经网络结构。通过卷积神经网络将2D压缩矩阵和1D分布向量进一步转换为全局和局部特征向量。每个卷积层后面都是ReLU激活和最大池化层,除了最后一层我们使用全局平均池化。
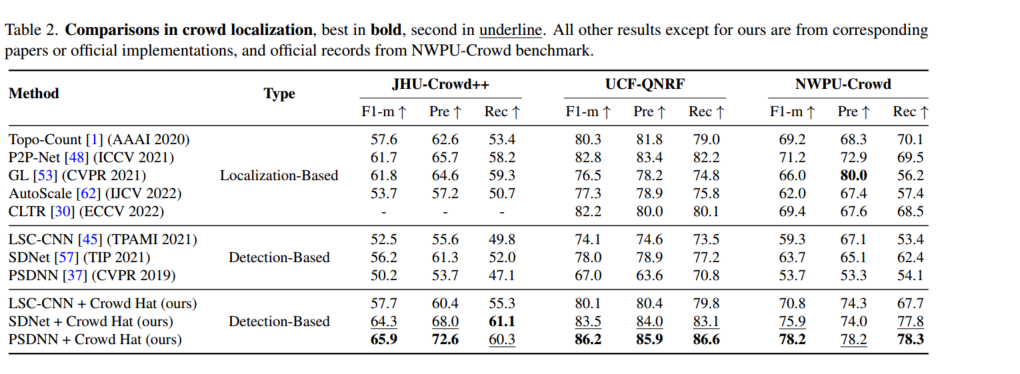
对比实验:

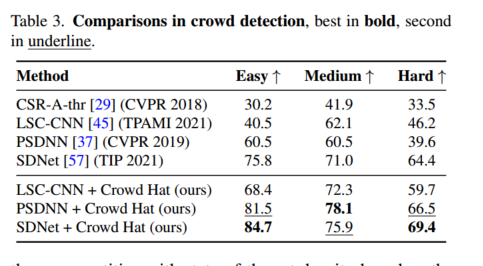
消融实验:

11.Boosting Crowd Counting via Multifaceted Attention
paper:https://arxiv.org/pdf/2203.02636.pdf
摘要:
本文重点关注具有挑战性的人群计数任务。由于人群图像中经常存在大规模的变化,无论是 CNN 的固定大小卷积核还是最新视觉变换器的固定大小注意力都无法很好地处理这种变化。为了解决这个问题,我们提出了多元注意网络(Multifaceted Attention Network,MAN)来改进变换器模型的局部空间关系编码。MAN 将原始变换器的全局注意力、可学习局部注意力和实例注意力整合到一个计数模型中。首先,我们提出了局部可学习区域注意力(Learnable Region Attention,LRA),为每个特征位置动态分配专属注意力。其次,我们设计了局部注意力正则化(Local Attention Regularization),通过最小化不同特征位置注意力之间的偏差来监督 LRA 的训练;最后,我们提供了实例注意力机制,在训练过程中动态地关注最重要的实例。在四个具有挑战性的人群计数数据集(ShanghaiTech, UCFQNRF, JHU++, and NWPU)上进行的大量实验验证了所提出的方法。
主要贡献:
?我们设计了一种局部区域注意力正则化方法来监督 LRA 的训练。
?我们引入了一种有效的实例注意力机制,在训练过程中动态选择最重要的实例。
?我们在包括ShanghaiTech、UCF-QNRF、JHU++和NWPU在内的流行数据集上进行了广泛的实验,并表明所提出的方法在计数性能方面取得了坚实的进步。
框架:

多元注意力网络框架。首先将人群图像输入 CNN。然后,扁平化输出特征图通过可学习区域注意力传输到变换编码器。最后,回归解码器预测密度图。在训练过程中,对局部注意力正则化和实例注意力损失(淡紫色方框内)进行了优化。
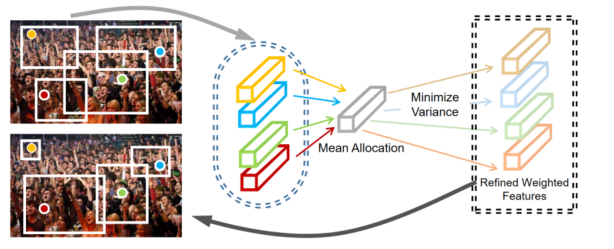
局部注意力正则化概述。它通过保持每个建议区域内分配的注意力资源的一致性来完善 LRA。
对比实验:

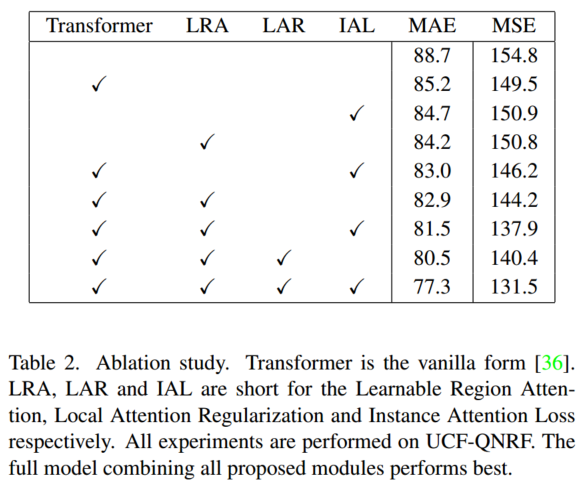
消融实验:
12.Redesigning Multi-Scale Neural Network for Crowd Counting
paper:https://arxiv.org/pdf/2208.02894.pdf
code:GitHub - ZPDu/Redesigning-Multi-Scale-Neural-Network-for-Crowd-Counting
摘要:
视角失真和人群变化使人群计数成为计算机视觉中一项具有挑战性的任务。为了解决这个问题,之前的许多研究都在深度神经网络(DNN)中使用了多尺度架构。多尺度分支既可以直接合并(如通过连接),也可以通过 DNN 中的代理(如注意力)引导进行合并。尽管这些合并方法非常普遍,但它们还不够成熟,无法解决多尺度密度图上每像素性能差异的问题。在这项工作中,我们重新设计了多尺度神经网络,引入了分层密度专家混合系统(hierarchical mixture of density experts),分层合并多尺度密度图进行人群计数。在分层结构中,我们提出了一种专家竞争与合作方案,以鼓励来自所有尺度的贡献;我们还引入了像素级软门控网络,为不同层次中的尺度组合提供像素级软权重。该网络同时使用人群密度图和本地计数图进行优化,后者是通过对前者进行局部整合获得的。由于二者之间可能存在冲突,因此对二者进行优化可能会出现问题。我们根据图像中硬预测的局部区域之间的相对计数差异,引入了一种新的相对局部计数损失,事实证明这种损失与密度图上的传统绝对误差损失是互补的。实验表明,我们的方法在五个公共数据集(即 ShanghaiTech、UCF CC 50、JHU-CROWD++、NWPU-Crowd 和 Trancos)上取得了一流的性能。
主要贡献:
?我们介绍了一种分层混合的密度专家(hierarchical mixture of density experts)结构,该体系结构包括两个关键元素,即专家竞争与协作方案和逐像素软门控网。它为重新设计人群计数中的密度估计网络提供了一种变革性的方法。
?我们介绍了一种从相对局部计数中学习的方案,该方案侧重于优化硬预测局部区域之间的相对局部计数误差。它是对人群密度图上传统优化的补充,适用于许多其他方法。
?我们的方法在标准基准、ShanghaiTech[1]、UCF CC 50[19]、JHU-CROWD++[22]、NWPU CROWD[23]和Trancos[24]上以相当大的优势优于最先进的方法。
笔者备注(有些专有名词翻译真的很扯):
Mixture of Experts
混合专家系统(Mixture of Experts, MoE)是在神经网络 (Neural Network, NN) 领域发展起来的一种集成学习(Ensemble Learning) 技术。传统的深度学习模型在训练时,对于每个输入样本,整个网络都会参与计算。随着模型越来越大,训练使用的样本数据越来越多,训练的开销越来越难以承受。而 MoE 可以动态激活部分神经网络,从而实现在不增加计算量的前提下大幅度增加模型参数量。MoE 技术目前是训练万亿参数量级模型的关键技术。
框架:


对比实验:



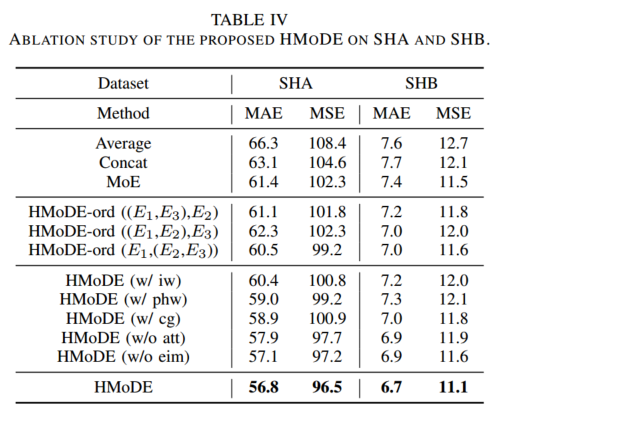
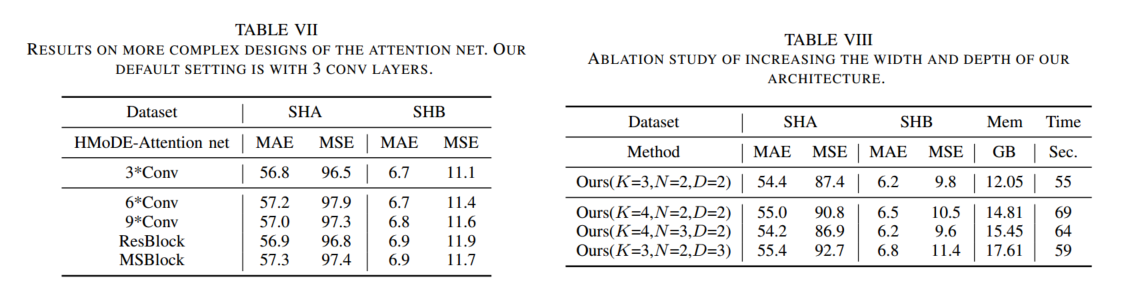
消融实验:

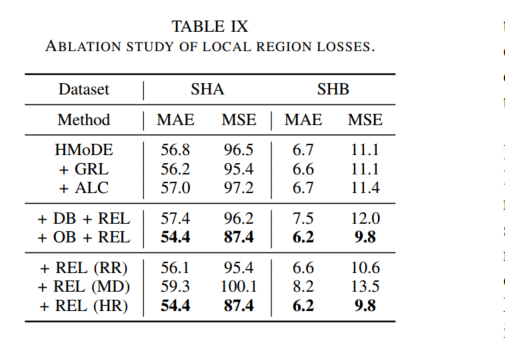
13.Multiscale Crowd Counting and Localization By Multitask Point Supervision
paper:https://arxiv.org/pdf/2202.09942.pdf
code:GitHub - RCVLab-AiimLab/crowd_counting: Crowd Counting
摘要:
我们提出了一种在统一框架内进行人群计数和人员定位的多任务方法。由于检测和定位任务具有很好的相关性,可以联合处理,因此我们的模型通过学习编码人群图像的多尺度表示,然后将其融合,从而受益于多任务解决方案。与相对更流行的基于密度的方法相比,我们的模型使用点监督来准确识别人群位置。我们在两个流行的人群计数数据集 ShanghaiTech A 和 B 上测试了我们的模型,结果表明我们的方法在计数和定位任务上都取得了很好的效果,在 ShanghaiTech A 和 B 上,人群计数的 MSE 值分别为 110.7 和 15.0,定位的 AP 值分别为 0.71 和 0.75。我们的详细消融实验显示了我们的多尺度方法的影响,以及嵌入在我们网络中的融合模块的有效性。
主要贡献:
(1) 我们提出了一种新的基于点监督的多尺度多任务架构,以在每张图像的人数变化很大的情况下有效地估计计数和位置。(2) 我们的方法在两个数据集上实现了强大的结果,并在计数和定位方面接近最先进的水平。详细的消融实验证明了我们网络中每个组件的影响。
框架:

所提出的模型的体系结构。虚线仅用于训练阶段。
实验:
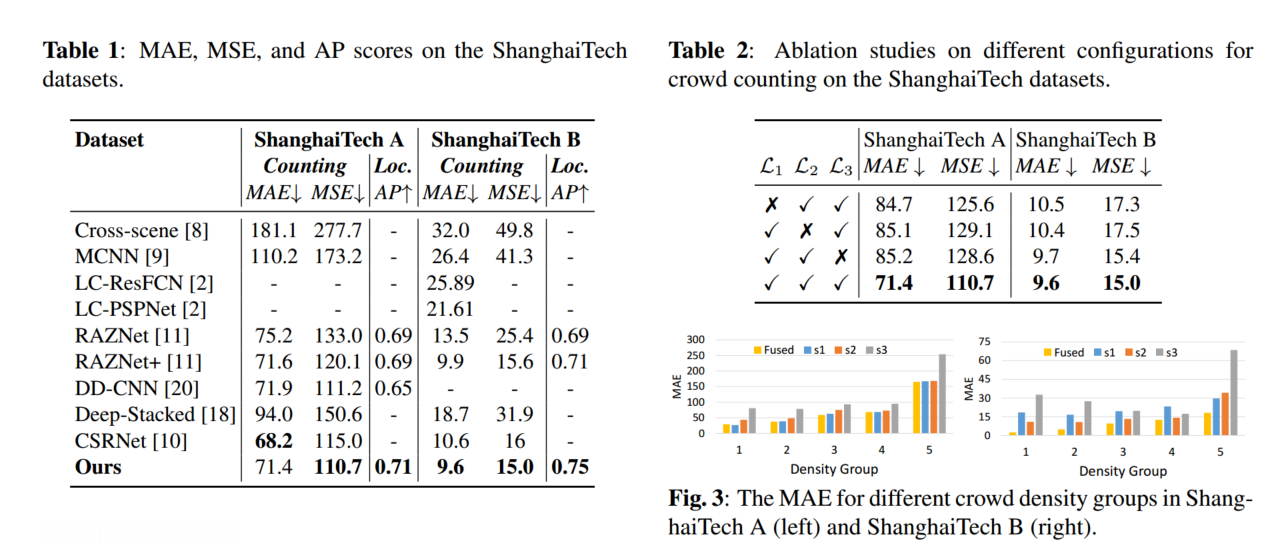
14.Reducing Capacity Gap in Knowledge Distillation with Review Mechanism for Crowd Counting
paper:https://arxiv.org/pdf/2206.05475.pdf
code:GitHub - Dearbreeze/ReviewKD
摘要:
近年来,轻量级人群计数模型,尤其是基于知识蒸馏(KD)的模型,因其在计算效率和硬件要求方面的优势而日益受到关注。然而,现有的基于 KD 的模型通常存在容量差距问题,导致学生网络的性能受到教师网络的限制。本文针对这一问题,以人类在学习过程中的复习机制为灵感,在 KD 模型之后引入了一种新的复习机制。因此,所提出的模型被称为 ReviewKD。我们首先利用训练有素的重型教师网络,在指导阶段将其潜在特征传输给轻型学生网络,然后在审查阶段通过审查机制,根据所学特征对密度图进行精炼估计。在审查机制中,我们首先将解码器得出的密度图估计值作为一定的关注权重,以更多地关注重要的人群区域,然后将纳入关注权重的新特征与从教师处学习到的特征进行聚合,生成增强特征,最后由解码器得出精炼估计值。通过在六个基准数据集上进行实验,并与最先进的模型进行比较,证明了 ReviewKD 的有效性。数值结果表明,在人群计数方面,ReviewKD 优于现有的轻量级模型,并能有效缓解容量差距问题,尤其是其性能超越了教师网络。除了轻量级模型之外,我们还证明了建议的审查机制可以作为即插即用模块,在不修改神经网络架构和不引入任何额外模型参数的情况下,进一步提高一种重型人群计数模型的性能。
主要贡献:
(1)我们介绍了一种新颖的审查机制,以解决现有KD模型所遭受的容量差距问题,主要是由人类的审查机制激励。 通过利用这种审查机制,可以有效缓解容量差距问题,特别是,学生网络的表现通常比相关的教师网络更好。
(2)在建议的评论KD的指令阶段,我们考虑了[27]中最近提出的两个KD模型,以及本文中提出的变体,使用MobilenetV2构建的新的轻量级学生网络。 与人群计数的最先进的模型相比,六个基准数据集的一系列实验证明了所提出的模型的有效性。 数值结果表明,所提出的模型的表现优于人群计数的最新模型,而引入的审查机制可以有效地解决KD模型所遭受的容量差距问题。 此外,SKT遇到的错误传播问题也可以被建议的VSKT有效缓解,如图1(e)所示。
(3)我们还进行了一组数值实验,以表明引入的审核机制可以用作插件模块,以进一步提高一种重型神经网络模型的性能(例如,基于编码器的模型 模型)用于人群计数,而无需修改神经网络体系结构并引入任何其他模型参数。

框架:

一种简化的人类审查机制。这个学生通过几轮复习提高了他的知识


对比实验:

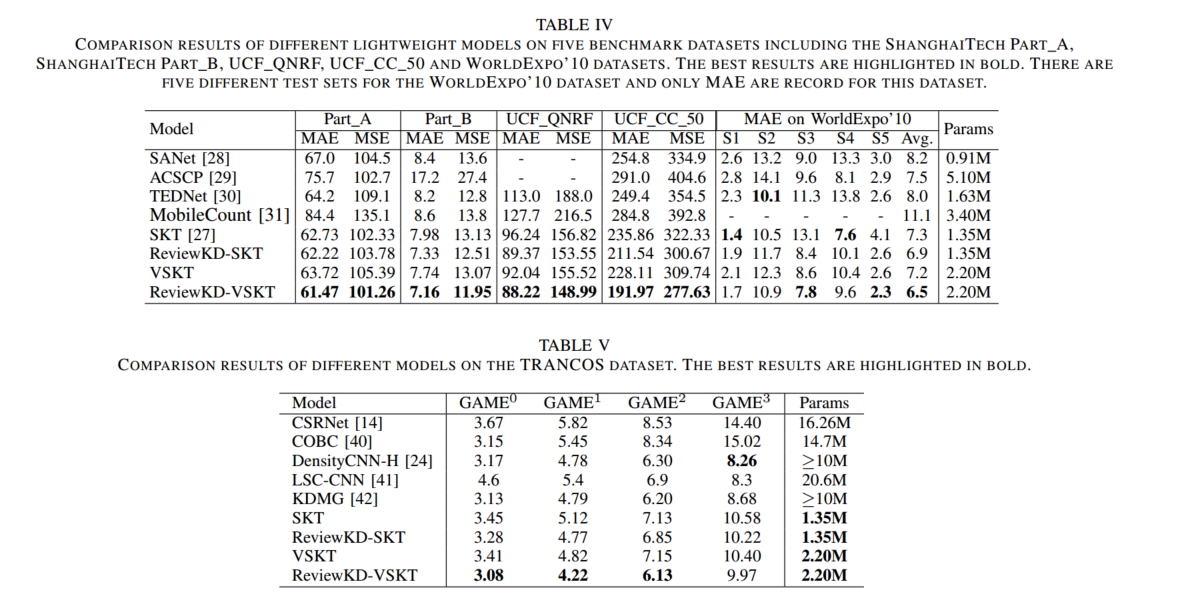

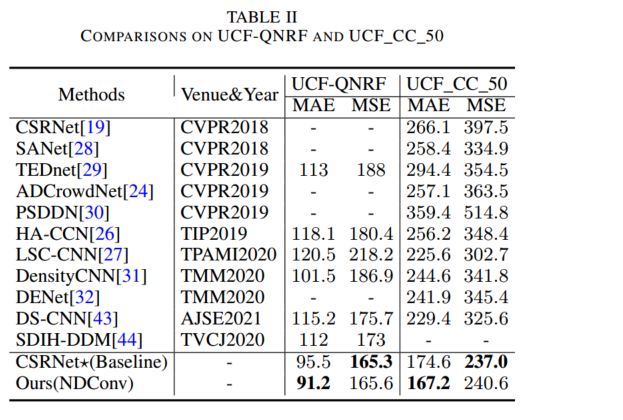
15.An Improved Normed-Deformable Convolution for Crowd Counting
paper:https://arxiv.org/pdf/2206.08084.pdf
code:GitHub - bingshuangzhuzi/NDConv
摘要:
近年来,人群计数已成为计算机视觉领域的一个重要问题。 在大多数方法中,密度图是通过与标记在人头中心周围的地面实况点图的高斯核进行卷积来生成的。 由于CNN的几何结构固定,头部尺度信息不明确,导致头部特征获取不完整。 提出可变形卷积是为了利用头部 CNN 特征的尺度自适应能力。 通过学习采样点的坐标偏移,可以轻松提高感受野的调整能力。 然而,可变形卷积中头部并没有被采样点均匀覆盖,导致头部信息丢失。 为了处理非均匀采样,本文提出了一种通过 Normed-Deformable 损失(即 NDloss)实现的改进的 Normed-Deformable 卷积(即 NDConv)。 受NDloss约束的采样点的偏移往往更加均匀。 然后,更完整地获得头部的特征,从而获得更好的性能。 特别是,所提出的 NDConv 是一个轻量级模块,与 Deformable Convolution 共享类似的计算负担。 在大量实验中,我们的方法在ShanghaiTech A, ShanghaiTech B, UCF QNRF, and UCF CC 50数据集上的表现优于最先进的方法,分别达到 61.4、7.8、91.2 和 167.2 MAE。
主要贡献:
1) 与传统的可变形卷积相比,提出了一种新的归一化可变形卷积(即NDConv),其中采样点倾向于更均匀地分布在头部,从而产生更充分的特征聚合。
2) 我们的NDconv鼓励更多的想法,即应该通过约束采样偏移将形状先验集成到可变形卷积中。
3) 基于所提出的NDConv,在几个人群计数数据集上实现了比最先进的方法更好的性能。
框架:


拟建NDConv网络的架构。我们采用CSRNet* 作为我们的主干,其中最后一层扩展卷积被NDConv取代以约束采样点。
对比实验:

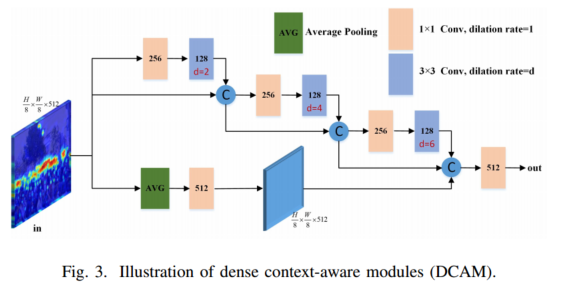
人群计数的目的是预测人数并生成图像中的密度图。 存在许多挑战,包括不同的头部尺寸、图像中人群分布的多样性以及杂乱的背景。 在本文中,我们提出了一种基于单列编码器-解码器架构的多尺度上下文聚合网络(MSCANet),用于人群计数,该网络由基于密集上下文感知模块(DCAM)的编码器和分层注意力引导解码器组成 。 为了处理尺度变化的问题,我们构建了 DCAM,通过将扩张卷积与不同的感受野紧密连接来聚合多尺度上下文信息。 由于其长距离感受野和密集尺度采样,所提出的 DCAM 可以捕获人群区域的丰富上下文信息。 此外,为了抑制背景噪声并生成高质量的密度图,我们在解码器中采用了分层注意力引导机制。 通过引入基于语义注意模块(SAM)的多重监督,这有助于从编码器的浅层特征图中集成更多有用的空间信息。 大量实验表明,所提出的方法在三个具有挑战性的人群计数基准数据集上比其他类似的最先进方法取得了更好的性能。
主要贡献:
?我们提出了一种基于编码器-解码器的多尺度上下文聚合网络用于人群计数,它可以改进多尺度表示并生成高质量的密度图。
?多尺度上下文聚合模块旨在帮助编码器捕获丰富的上下文和广泛的尺度信息。具体而言,该模块由堆叠的多个密集上下文感知模块(DCAM)组成,该模块将多个扩张的核与不同的感受野紧密连接。
?我们提出了一种分层注意力引导解码器,以明确地集成来自编码器的不同特征图的重要信息,从而获得高质量的密度图。在解码器的不同阶段引入多个SAM,以使人群区域的浅层特征图得到更多的关注。
?在三个人群数据集上进行了广泛的实验。结果表明,我们提出的方法比其他类似的最先进的方法获得了更好的性能。
框架:


对比/消融试验:


?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!