雅意2.0:打造专为中文优化的300亿参数多语言模型
前言
雅意2.0,作为一款专注于中文语境的开源大型语言模型,其在多语言处理方面的能力尤为突出。该模型不仅具有300亿参数规模的庞大体量,还在多个关键领域取得了显著的技术突破。
-
Huggingface模型下载:https://huggingface.co/wenge-research/
-
AI快站模型免费加速下载:https://aifasthub.com/models/wenge-research
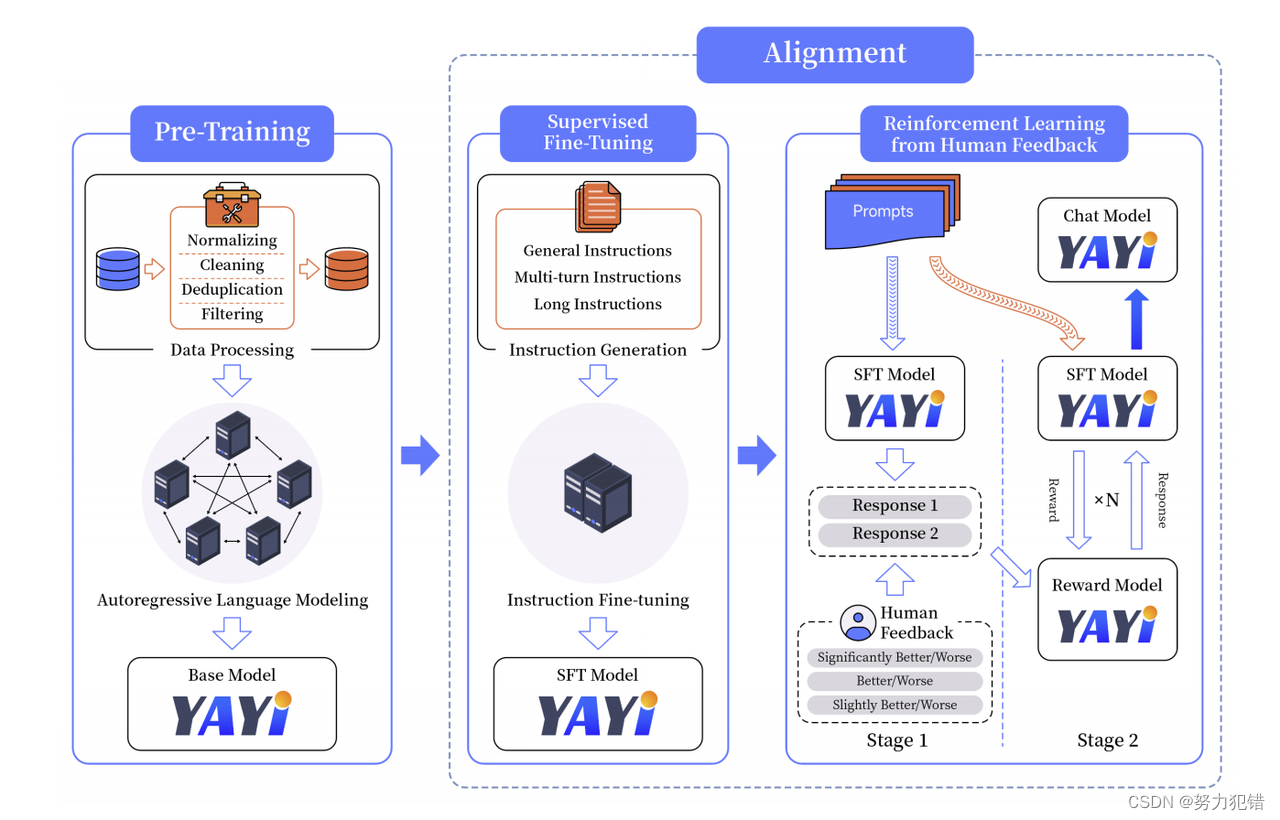
模型训练
-
参数规模的巨大提升,雅意2.0的参数量达到了惊人的300亿,使其成为中文领域中参数量最大的模型之一。这一巨大的参数规模赋予了模型更深层次的理解能力和更广泛的应用范围。
-
Token压缩率国内领先,在Token压缩率方面,雅意2.0在国内领先,尤其在中英双语以及多语种处理方面表现卓越,这一特点使得模型在处理多语种数据时更加高效。
-
从头预训练,数据多层过滤,雅意2.0采用了从头开始的预训练方式,训练数据经过1000余道清洗工序,确保了2.65万亿Tokens的高质量。此外,其预训练涵盖了240TB多源基础数据,覆盖广泛。
特色技能
雅意2.0的特色技能体现在多方面,不仅在多轮对话处理上表现出色,还在多模态处理、内容安全及智能插件应用方面展现了其先进的技术优势。
-
多轮对话角色扮演,雅意2.0能够扮演特定人物或执行专业任务,支持自定义角色及表达风格,实现超长轮历史对话的关联,这在模拟复杂人机互动方面具有重要意义。
-
最长128k输入更长上下文窗口,该模型支持长达128k的输入,这一特性显著提升了对长文本的处理能力,使其在处理离线文档、数据库和API接入时更加高效。
-
1000W+图文数据对齐,雅意2.0在多模态能力方面也取得了显著进步,其图文数据对齐技术支持30+种内容理解、审核和抽取能力,能够将文本描述转化为细节丰富的图像,展现出卓越的创造力。
-
内容安全风控,模型通过人类价值观对齐和流式内容实时审核等方法,提升了内容的安全性和合规性,尤其在处理诱导性内容时表现出良好的抵抗能力。
-
智能插件调用,雅意2.0支持10+种智能插件,能够根据用户输入自动选择最合适的插件,大大提升了用户体验和操作效率。
专业技能
雅意2.0在安全、金融、媒体和舆情等专业领域展现出深度增强的能力,并覆盖了法律、中医等多业务场景。这些专业技能的增强,为行业用户提供了更加丰富和精准的服务。雅意2.0推出了包括YAYI-Chat、YAYI-Bot、YAYI UIE和YAYI File等多个通用产品,这些产品在多种行业场景中均有广泛应用。
测评指标
在多项国内外测评中,雅意2.0展现出了卓越的性能表现。
-
Token压缩率及多语种处理,在中英双语以及多语种处理方面,雅意2.0表现出色,Token压缩率在国内处于领先地位。
-
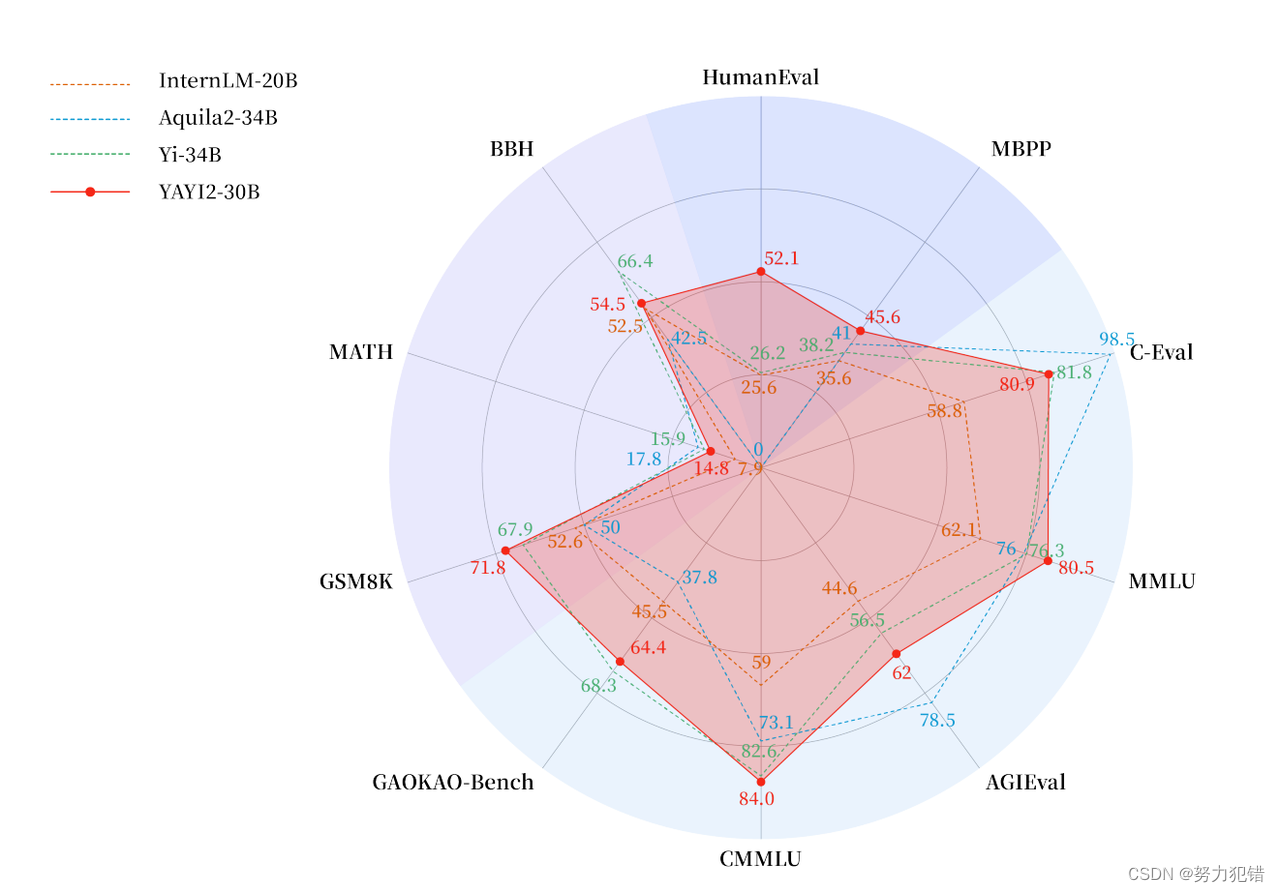
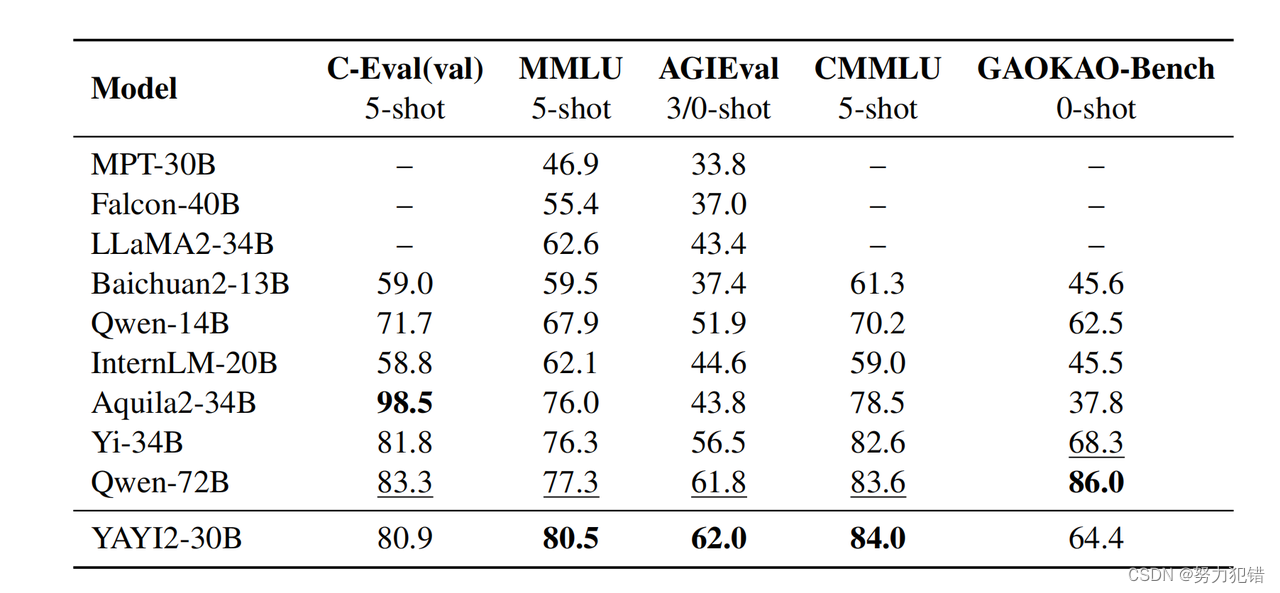
中文知识问答能力,在多个知识问答测评中,如AGIEval和CMMLU,雅意2.0均获得了第一名的成绩,显示了其在中文领域的强大处理能力。
结论
雅意2.0作为一款专注于中文和多语种的大型语言模型,不仅在技术层面取得了显著进步,更在实际应用中展现出了巨大的潜力和广阔的应用前景。随着技术的不断完善和应用的不断深入,预计雅意2.0将在人工智能领域中发挥更加重要的作用。
模型下载
Huggingface模型下载
https://huggingface.co/wenge-research/
AI快站模型免费加速下载
https://aifasthub.com/models/wenge-research
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!