Flink系列之:背压下的检查点
Flink系列之:背压下的检查点
一、Checkpointing under backpressure
通常情况下,对齐 Checkpoint 的时长主要受 Checkpointing 过程中的同步和异步两个部分的影响。 然而,当 Flink 作业正运行在严重的背压下时,Checkpoint 端到端延迟的主要影响因子将会是传递 Checkpoint Barrier 到 所有的算子/子任务的时间。这在 checkpointing process) 的概述中有说明原因。并且可以通过高 alignment time and start delay metrics 观察到。 当这种情况发生并成为一个问题时,有三种方法可以解决这个问题:
- 消除背压源头,通过优化 Flink 作业,通过调整 Flink 或 JVM 参数,抑或是通过扩容。
- 减少 Flink 作业中缓冲在 In-flight 数据的数据量。
- 启用非对齐 Checkpoints。 这些选项并不是互斥的,可以组合在一起。本文档重点介绍后两个选项。
二、缓冲区 Debloating
Flink 1.14 引入了一个新的工具,用于自动控制在 Flink 算子/子任务之间缓冲的 In-flight 数据的数据量。缓冲区 Debloating 机 制可以通过将属性taskmanager.network.memory.buffer-debloat.enabled设置为true来启用。
此特性对对齐和非对齐 Checkpoint 都生效,并且在这两种情况下都能缩短 Checkpointing 的时间,不过 Debloating 的效果对于 对齐 Checkpoint 最明显。 当在非对齐 Checkpoint 情况下使用缓冲区 Debloating 时,额外的好处是 Checkpoint 大小会更小,并且恢复时间更快 (需要保存 和恢复的 In-flight 数据更少)。
有关缓冲区 Debloating 功能如何工作以及如何配置的更多信息,可以参考 network memory tuning guide。 请注意,您仍然可以继续使用在前面调优指南中介绍过的方式来手动减少缓冲在 In-flight 数据的数据量。
三、非对齐 Checkpoints
从Flink 1.11开始,Checkpoint 可以是非对齐的。 Unaligned checkpoints 包含 In-flight 数据(例如,存储在缓冲区中的数据)作为 Checkpoint State的一部分,允许 Checkpoint Barrier 跨越这些缓冲区。因此, Checkpoint 时长变得与当前吞吐量无关,因为 Checkpoint Barrier 实际上已经不再嵌入到数据流当中。
如果您的 Checkpointing 由于背压导致周期非常的长,您应该使用非对齐 Checkpoint。这样,Checkpointing 时间基本上就与 端到端延迟无关。请注意,非对齐 Checkpointing 会增加状态存储的 I/O,因此当状态存储的 I/O 是 整个 Checkpointing 过程当中真 正的瓶颈时,您不应当使用非对齐 Checkpointing。
为了启用非对齐 Checkpoint,您可以:
Java代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 启用非对齐 Checkpoint
env.getCheckpointConfig().enableUnalignedCheckpoints();
Scala代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
// 启用非对齐 Checkpoint
env.getCheckpointConfig.enableUnalignedCheckpoints()
Python代码:
env = StreamExecutionEnvironment.get_execution_environment()
# 启用非对齐 Checkpoint
env.get_checkpoint_config().enable_unaligned_checkpoints()
或者在 flink-conf.yml 配置文件中增加配置:
execution.checkpointing.unaligned: true
四、对齐 Checkpoint 的超时
在启用非对齐 Checkpoint 后,你依然可以通过编程的方式指定对齐 Checkpoint 的超时:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getCheckpointConfig().setAlignedCheckpointTimeout(Duration.ofSeconds(30));
或是在 flink-conf.yml 配置文件中配置:
execution.checkpointing.aligned-checkpoint-timeout: 30 s
在启动时,每个 Checkpoint 仍然是 aligned checkpoint,但是当全局 Checkpoint 持续时间超过 aligned-checkpoint-timeout 时, 如果 aligned checkpoint 还没完成,那么 Checkpoint 将会转换为 Unaligned Checkpoint。
五、限制
并发 Checkpoint
Flink 当前并不支持并发的非对齐 Checkpoint。然而,由于更可预测的和更短的 Checkpointing 时长,可能也根本就不需要并发的 Checkpoint。此外,Savepoint 也不能与非对齐 Checkpoint 同时发生,因此它们将会花费稍长的时间。
与 Watermark 的相互影响
非对齐 Checkpoint 在恢复的过程中改变了关于 Watermark 的一个隐式保证。目前,Flink 确保了 Watermark 作为恢复的第一步, 而不是将最近的 Watermark 存放在 Operator 中,以方便扩缩容。在非对齐 Checkpoint 中,这意味着当恢复时,Flink 会在恢复 In-flight 数据后再生成 Watermark。如果您的 Pipeline 中使用了对每条记录都应用最新的 Watermark 的算子将会相对于 使用对齐 Checkpoint产生不同的结果。如果您的 Operator 依赖于最新的 Watermark 始终可用,解决办法是将 Watermark 存放在 OperatorState 中。在这种情况下,Watermark 应该使用单键 group 存放在 UnionState 以方便扩缩容。
与长时间运行的记录处理的相互作用
尽管未对齐的检查点障碍仍然能够超越队列中的所有其他记录。如果当前记录需要花费大量时间来处理,则此屏障的处理仍然可能会被延迟。当同时触发多个计时器时(例如在窗口操作中),可能会发生这种情况。当系统在处理单个输入记录时被阻塞等待多个网络缓冲区可用性时,可能会出现第二种有问题的情况。 Flink 无法中断单个输入记录的处理,未对齐的检查点必须等待当前处理的记录被完全处理。这可能会在两种情况下导致问题。由于不适合单个网络缓冲区的大记录的序列化或在 flatMap 操作中,会为一个输入记录生成许多输出记录。在这种情况下,背压可能会阻止未对齐的检查点,直到处理单个输入记录所需的所有网络缓冲区都可用。当处理单个记录需要一段时间时,它也可能发生在任何其他情况下。因此,检查点的时间可能会比预期的时间长,或者可能会有所不同。
某些数据分布模式没有检查点
有些属性包含的连接无法与 Channel 中的数据一样保存在 Checkpoint 中。为了保留这些功能并确保没有状态冲突或非预期的行为,非同一 Checkpoint 对于这些类型的连接是禁用的。所有其他的交换仍然执行非单色检查点。
点对点连接
我们目前没有任何对于点对点连接中有关数据有序性的强保证。然而,由于数据已经被以前置的 Source 或是 KeyBy 相同的方式隐式 组织,一些用户会依靠这种特性在提供的有序性保证的同时将计算敏感型的任务划分为更小的块。
只要并行度不变,非对齐 Checkpoint(UC) 将会保留这些特性。但是如果加上UC的伸缩容,这些特性将会被改变。
针对如下任务
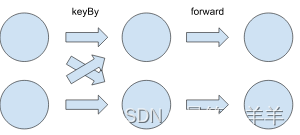
如果我们想将并行度从 p=2 扩容到 p=3,那么需要根据 KeyGroup 将 KeyBy 的 Channel 中的数据突然的划分到3个 Channel 中去。这 很容易做到,通过使用 Operator 的 KeyGroup 范围和确定记录属于某个 Key(group) 的方法(不管实际使用的是什么方法)。对于 Forward 的 Channel,我们根本没有 KeyContext。Forward Channel 里也没有任何记录被分配了任何 KeyGroup;也无法计算它,因为无法保证 Key仍然存在。
广播 Connections
广播 Connection 带来了另一个问题。无法保证所有 Channel 中的记录都以相同的速率被消费。这可能导致某些 Task 已经应用了与 特定广播事件对应的状态变更,而其他任务则没有,如图所示。
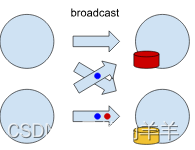
广播分区通常用于实现广播状态,它应该跨所有 Operator 都相同。Flink 实现广播状态,通过仅 Checkpointing 有状态算子的 SubTask 0 中状态的单份副本。在恢复时,我们将该份副本发往所有的 Operator。因此,可能会发生以下情况:某个算子将很快从它的 Checkpointed Channel 消费数据并将修改应有于记录来获得状态。
六、故障排除
Corrupted in-flight data
以下描述的操作是最后采取的手段,因为它们将会导致数据的丢失。
为了防止 In-flight 数据损坏,或者由于其他原因导致作业应该在没有 In-flight 数据的情况下恢复,可以使用 recover-without-channel-state.checkpoint-id 属性。该属性需要指定一个 Checkpoint Id,对它来说 In-flight 中的数据将会被忽略。除非已经持久化的 In-flight 数据内部的损坏导致无 法恢复的情况,否则不要设置该属性。只有在重新部署作业后该属性才会生效,这就意味着只有启用 externalized checkpoint时,此操作才有意义。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!