ChatGLM大模型推理加速之Speculative Decoding
? ? ? ?
目录
????????大模型时代,模型的推理效率尤为重要,推理速度的快慢和模型生成的质量好坏对用户的体验影响很大。大模型生成速度慢,生成效果好;小模型推理速度快,但是推理质量稍差。当前大模型推理速度满不足不了业务实效性需求,小模型不能满足业务质量指标的情况下存不存在一种业务在实际落地的时候最优选择呢?google论文Fast Inference from Transformers via Speculative Decoding和deepmind论文Accelerating Large Language Model Decoding with Speculative Sampling给出了相同思路的解决方案,也就是这篇博客要谈到的东西Speculative Decoding,翻译为推测解码。简单的来说,推测解码一种联合小模型和大模型各自的优势的解码算法,用大模型来对小模型的生成结果进行评估和修正,以实现完美保留大模型的生成质量的同时提升推理速度的目标。
一、推测解码speculative decoding
1、自回归解码

首先看看自回归解码的流程,如图所示
1、把输入序列输入模型,把输出结果logits处理成概率分布,采样得到next token。
2、把新生成的next token和原来的输入序列拼接在一起,作为新的输入序列,然后重复第一步。直到结束——新生成的token是结尾标识符EOS或者达到最大限定长度。
注意其中1中得到next token可以采用greedy search、beam search、topK和topP sample 以及contrastive search等算法。
2、speculative decoding
推测解码本质也也是自回归解码,大体流程上和上述流程相似,只不过在推理过程才使用了一大一小的模型,对效率和质量做了权衡,当然也是以牺牲显存和两次模型训练为代价的。用google论文中的示意图来举例说明:

小模型先生成japan’s benchmark bond n,大模型对这些文本进行评估,发现bond生成不好,拒绝该生成,丢弃掉bond n 这部分生成,修正生成为 nikkei ;然后把japan’s benchmark?nikkei 拼接起来由小模型继续生成,直到结束位置。
具体的流程是什么样的呢?看deepmind论文中的算法伪代码

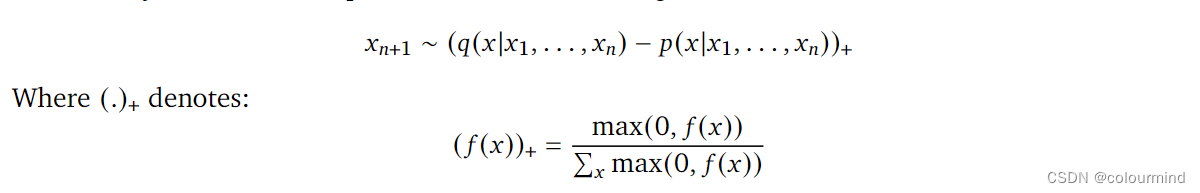
根据上述算法伪代码,可以得出Speculative Sampling的具体流程:
1、设置小模型每次自回归解码的步数K以及最大解码输出长度T。
2、首先用小模型Mq做自回归生成,连续生成采样得到gama个tokens,并同时得到每个token的概率分布q_logits。
3、然后用前缀输入prefix和这个gama个tokens拼接在一起,输入大模型Mp执行forward,得到每个token的概率分布p_logits。
4、使用大小模型的logits做对比,如果大模型发现小模型的某个token不好,拒绝它,使用某种办法重新采样这个token;如果小模型生成的token都很好,大模型直接生成下一个token
5、然后重复2-4步骤,直到结束条件。
3、细节理解
算法中有几个细节需要注意
1、论文中并行的计算得到小模型生成的gama个tokens的大模型对应的logits
其实这里的理解不要太复杂了,就是等待小模型生成完了gama个tokens以后直接用大模型进行forward,这里就利用了矩阵计算,并行的得到了大模型对应的logits。不需要考虑的复杂,小模型生成一个token,1号大模型就计算一次;小模型再生成一个,2号大模型再计算该token的logits。这样极其浪费资源并且并没有一次forward那么快。
2、怎么来评价小模型生成的token好不好?
利用概率分布来评价,这里有个前提,大模型的质量比较好,生成的结果都是正确的。大模型下,该token概率为p,小模型下为q,如果p>q,说明大模型都认为这个位置该生成这个token,那么就接受这个token;反之则以1-p/q的概率拒绝这个token——大模型的概率越小就越要拒绝,越大就约不拒绝。
3、拒绝该token后,怎么生成新的token
![]()
论文中给出了一个方案,使用如上公式用大模型的logtis和小模型的logits进行计算得到一个新的概率分布——最后采样的结果就是大模型和小模型概率差异化越大,就越能被采样到。
以上就是原始论文中的核心思想和重要的地方,但是在代码实现的时候,还是有一些细节的,使用缓存进行加速推理、logits归一化的加速、采样的方案选择等等,对后续算法的效果和效率都有一定的影响。
二、核心逻辑代码
? ? ? ? ? 首先声明该本篇博客中实现的算法代码借鉴了方佳瑞博士大模型推理妙招—投机采样(Speculative Decoding)的实现整体思路,局部细节进行了优化,并使用ChatGLM基座模型进行了效果实测,证实优化后生成质量和推理速度均有提升。
1、算法流程代码
def speculative_decode_generate(self, prompt, gamma, do_sample=False, debug=False, promotion=True):
eos_token = self.tokenizer.eos_token_id
# 小模型生成类初始化
approx_model_kv_cached_genration = KVCachedGenration(self.approx_model, eos_token, self.temperature, self.top_k,
self.top_p, do_sample)
# 大模型生成类初始化
target_model_kv_cached_genration = KVCachedGenration(self.target_model, eos_token, self.temperature, self.top_k,
self.top_p, do_sample)
inputs = self.tokenizer([prompt], return_tensors="pt", padding=True)
prefix = inputs['input_ids'].to(self.device)
seq_len = prefix.shape[1]
T = seq_len + self.max_len
end = T
assert prefix.shape[0] == 1, "input batch size must be 1"
eos_token_index = None
with torch.no_grad():
while prefix.shape[1] < T:
prefix_len = prefix.shape[1]
# 得到小模型的生成结果
x, index = approx_model_kv_cached_genration.generate_promotion(prefix, gamma, debug)
#记录小模型生成的eos_token位置
if index is not None:
eos_token_index = prefix_len + index
# 得到大模型的生成结果
t_x, _ = target_model_kv_cached_genration.generate_promotion(x, 1, debug)
n = prefix_len + gamma - 1
# 大模型评价小模型效果
for i in range(gamma):
if self.random_seed:
torch.manual_seed(self.random_seed)
# r==1的时候表示只要大模型的logits比小模型的小,就拒绝生成
r = torch.rand(1, device=self.device)
else:
r = torch.as_tensor(1.0, dtype=torch.float, device=self.device)
j = x[:, prefix_len + i]
# 拒接 以1-p/q 的概率拒绝 生成
if r > (target_model_kv_cached_genration.prob_history[:, prefix_len + i - 1,
j] / approx_model_kv_cached_genration.prob_history[:, prefix_len + i - 1, j]):
n = prefix_len + i - 1
break
# 根据小模型采纳的token位置来回滚past_key_values缓存
approx_model_kv_cached_genration.kv_rollback(n + 1)
prefix = x[:, :n + 1]
if eos_token_index is not None:
# 如果小模型生成的eos不被接受,则继续生成
if eos_token_index > n:
eos_token_index = None
else:
# 如果小模型生成的eos被接受,则停止
break
# 如果拒绝一些小模型生成的token,从大模型中采样
if n < prefix_len + gamma - 1:
if do_sample:
t = sample(max_fn(target_model_kv_cached_genration.prob_history[:, n,
:] - approx_model_kv_cached_genration.prob_history[:, n, :]))
else:
# t = torch.argmax(max_fn(target_model_kv_cached_genration.prob_history[:, n,
# :] - approx_model_kv_cached_genration.prob_history[:, n, :]),
# dim=-1).unsqueeze(0)
# 直接取大模型logits最大的那个token
t = torch.argmax(target_model_kv_cached_genration.prob_history[:, n, :], dim=-1).unsqueeze(0)
# 根据生成的token位置大模型回滚past_key_values缓存
target_model_kv_cached_genration.kv_rollback(n + 1)
else:
if do_sample:
t = sample(target_model_kv_cached_genration.prob_history[:, -1, :])
else:
t = torch.argmax(target_model_kv_cached_genration.prob_history[:, -1, :], dim=-1).unsqueeze(0)
# 根据生成的token位置大模型回滚past_key_values缓存
target_model_kv_cached_genration.kv_rollback(n + 2)
prefix = torch.cat((prefix, t), dim=1)
# 如果生成eos token 则停止生成
if t == eos_token:
eos_token_index = prefix.shape[1] - 1
break
if eos_token_index:
end = eos_token_index + 1
input_ids = inputs['input_ids'].tolist()[0]
assert len(input_ids) <= end, "eos_token选择位置错误"
output_token_ids = prefix.tolist()[0][len(input_ids):end]
#得到最终输出
response = self.tokenizer.decode(output_token_ids)
代码中实现了上述推测解码的整个流程,并给出了退出解码过程的条件。也实现了不同采样token的方式以及不同拒绝小模型token的策略,对实际结果也是很有影响的。
2、模型自回归代码
这里其实也比较细节的,实现的好不好会影响模型最终生成的效率的,加不加缓存以及向量归一化都会极大影响模型推理速度。
a、带缓存的模型自回归实现代码
@torch.no_grad()
def generate(self, input_ids, gamma):
eos_index = None
x = input_ids
for index, _ in enumerate(range(gamma)):
# past_key_values存在,非首次推理
if self.past_key_values:
kv_cached_len = self.past_key_values[0][0].shape[0]
# 获取位置ids
position_ids = self.get_position_ids(x, x.device)
position_ids = position_ids[..., kv_cached_len:]
# ChatGLM一定要输入位置编码,一般推理的时候模型内部会自己配置位置编码的
outputs = self.model(x[:, kv_cached_len:], position_ids=position_ids,
past_key_values=self.past_key_values, use_cache=True)
logits = outputs.logits
# logits归一化
for i in range(logits.shape[1]):
logits[:, i, :] = norm_logits(logits[:, i, :], self.temperature, self.top_k, self.top_p)
probs = logits[:, -1, :]
self.past_key_values = outputs.past_key_values
self.prob_history = torch.cat([self.prob_history, logits], dim=1)
else:
# past_key_values不存在,首次推理
outputs = self.model(x)
self.prob_history = outputs.logits
# logits归一化
for i in range(self.prob_history.shape[1]):
self.prob_history[:, i, :] = norm_logits(self.prob_history[:, i, :], self.temperature, self.top_k,
self.top_p)
self.past_key_values = outputs.past_key_values
probs = self.prob_history[:, -1, :]
# 采样得到next_tok
if self.do_sample:
next_tok = sample(probs)
else:
next_tok = torch.argmax(probs, dim=-1).unsqueeze(0)
x = torch.cat((x, next_tok), dim=1)
if next_tok == self.eos_token and eos_index is None:
eos_index = index
return x, eos_index
# copy from https://github.com/LeeSinLiang/microGPT/blob/ed40cf9780dbeb180adfe94c227d4aa97e69250e/gpt.py
def top_k_top_p_filter(logits: torch.Tensor, top_k: int = 0, top_p: float = 0.0):
"""
Args:
logits (torch.Tensorpe_): 2D tensor with shape (batch, vocab)
top_k (int, optional): top_k. Defaults to 0.
top_p (float, optional): top_p. Defaults to 0.0.
Returns:
torch.Tensor: a renormalized logits
"""
if top_k > 0:
filter = torch.topk(logits, min(top_k, logits.size(-1)))[0]
logits[logits < filter[:, [-1]]] = float('-inf')
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(
F.softmax(sorted_logits, dim=-1), dim=-1)
filter = cumulative_probs > top_p
filter[..., 1:] = filter[..., :-1].clone()
filter[..., 0] = 0
indices_to_remove = filter.scatter(1, sorted_indices, filter)
logits[indices_to_remove] = float('-inf')
return logits
def norm_logits(logits: torch.Tensor, temperature: float, top_k: float, top_p: float) -> torch.Tensor:
"""
Args:
logits (torch.Tensor): shape (1, vocab)
temperature (float): temperature
top_k (float): top_k
top_p (float): top_p
Returns:
torch.Tensor: next token with shape as (batch, 1)
"""
assert logits.dim() == 2
logits = logits / temperature
logits = top_k_top_p_filter(logits, top_k=top_k, top_p=top_p)
probs = F.softmax(logits, dim=1)
return probs
def sample(probs: torch.Tensor, num_samples: int = 1):
idx_next = torch.multinomial(probs, num_samples=num_samples)
if (idx_next.item() == 0):
raise RuntimeError
return idx_next正常的自回归流程,每次生成的时候都会传入past_key_values(这个时候模型输入就是x[:, kv_cached_len:])进行加速,同时输入position_ids保证结果正确。得到logits后进行归一化(为了后面能够对比大小模型的logits,大模型能够评价小模型,必须scale到同一个值域里面)、topK、topP以及softmax处理,然后采样得到下一个token。以上是没有优化过的版本,在归一化、topK、topP以及softmax处理过程中,大小模型首次推理以及大模型非首次推理都是多个token,代码里采用for循环的方式实现,耗时太多,可以矩阵计算并行化。
b、优化版本带缓存的模型自回归实现代码
并不是优化自回归这个算法本身,是优化自回归过程中大小模型首次推理以及大模型非首次推理logits归一化的实现。这里采用并行计算也就是矩阵计算。
def norm_logits_whole(logits: torch.Tensor, temperature: float, top_k: float, top_p: float) -> torch.Tensor:
# 优化一版提速 矩阵计算代替原来的for循环
assert logits.dim() == 3
"""
Args:
logits (torch.Tensor): shape (1, vocab)
temperature (float): temperature
top_k (float): top_k
top_p (float): top_p
Returns:
torch.Tensor: next token with shape as (batch, 1)
"""
def top(scores: torch.FloatTensor, top_k: int = 0, top_p: float = 0.0):
sorted_logits, sorted_indices = torch.sort(scores, descending=False)
cumulative_probs = sorted_logits.softmax(dim=-1)
cumulative_probs = cumulative_probs.cumsum(dim=-1)
sorted_indices_to_remove = cumulative_probs <= (1 - top_p)
sorted_indices_to_remove[..., -1:] = 0
# 主要是这句代码优化
indices_to_remove = sorted_indices_to_remove.scatter(2, sorted_indices, sorted_indices_to_remove)
scores = scores.masked_fill(indices_to_remove, -float("Inf"))
return scores
if top_k > 0:
filter = torch.topk(logits, min(2, logits.size(-1)))[0]
logits[logits < filter[..., [-1]]] = float('-inf')
logits = logits / temperature
logits = top(logits, top_k, top_p)
probs = F.softmax(logits, dim=2)
return probs
@torch.no_grad()
def generate_promotion(self, input_ids, gamma, debug=False):
eos_index = None
x = input_ids
for index, _ in enumerate(range(gamma)):
if self.past_key_values:
kv_cached_len = self.past_key_values[0][0].shape[0]
position_ids = self.get_position_ids(x, x.device)
position_ids = position_ids[..., kv_cached_len:]
# ChatGLM一定要输入位置编码,一般推理的时候模型内部会自己配置位置编码的
outputs = self.model(x[:, kv_cached_len:], position_ids=position_ids,
past_key_values=self.past_key_values, use_cache=True)
logits = outputs.logits
# 优化提速版本归一化
logits = norm_logits_whole(logits, self.temperature, self.top_k, self.top_p)
probs = logits[:, -1, :]
self.past_key_values = outputs.past_key_values
self.prob_history = torch.cat([self.prob_history, logits], dim=1)
else:
outputs = self.model(x)
self.prob_history = outputs.logits
# 优化提速版本归一化
self.prob_history = norm_logits_whole(self.prob_history, self.temperature, self.top_k, self.top_p)
self.past_key_values = outputs.past_key_values
probs = self.prob_history[:, -1, :]
if self.do_sample:
next_tok = sample(probs)
else:
next_tok = torch.argmax(probs, dim=-1).unsqueeze(0)
x = torch.cat((x, next_tok), dim=1)
if next_tok == self.eos_token and eos_index is None:
eos_index = index
return x, eos_index
def sample(probs: torch.Tensor, num_samples: int = 1):
idx_next = torch.multinomial(probs, num_samples=num_samples)
if (idx_next.item() == 0):
raise RuntimeError
return idx_nextc、ChatGLM的past_key_values的回滚
@torch.no_grad()
def kv_rollback(self, end_index):
past_key_values_keeps = []
for index, kv in enumerate(self.past_key_values):
k, v = kv
k = k[:end_index, :, :, :]
v = v[:end_index, :, :, :]
kv = (k, v)
past_key_values_keeps.append(kv)
self.past_key_values = past_key_values_keeps
self.prob_history = self.prob_history[:, :end_index, :]注意past_key_values不同的模型的维度不一样,llama k, v? (batch, num_head, seq_len, hidden_dim);ChatGLM k, v (seq, batch, head, hidden_dim)而Bloom ?k (batch * head, hidden_dim, seq); v (batch * head, seq, hidden_dim),在实现的时候需要注意。
比较重要的代码笔记都介绍完毕了,没有写文件的依赖和一些不重要的逻辑,放一下我这边的一个python文件speculate_decoding.py的全部代码——实现了不同的采样方式、gama动态输入、是否debug等:
import torch
from torch.nn import functional as F
import time
torch.set_printoptions(precision=10)
# copy from https://github.com/LeeSinLiang/microGPT/blob/ed40cf9780dbeb180adfe94c227d4aa97e69250e/gpt.py
def top_k_top_p_filter(logits: torch.Tensor, top_k: int = 0, top_p: float = 0.0):
"""
Args:
logits (torch.Tensorpe_): 2D tensor with shape (batch, vocab)
top_k (int, optional): top_k. Defaults to 0.
top_p (float, optional): top_p. Defaults to 0.0.
Returns:
torch.Tensor: a renormalized logits
"""
if top_k > 0:
filter = torch.topk(logits, min(top_k, logits.size(-1)))[0]
logits[logits < filter[:, [-1]]] = float('-inf')
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(
F.softmax(sorted_logits, dim=-1), dim=-1)
filter = cumulative_probs > top_p
filter[..., 1:] = filter[..., :-1].clone()
filter[..., 0] = 0
indices_to_remove = filter.scatter(1, sorted_indices, filter)
logits[indices_to_remove] = float('-inf')
return logits
def norm_logits(logits: torch.Tensor, temperature: float, top_k: float, top_p: float) -> torch.Tensor:
"""
Args:
logits (torch.Tensor): shape (1, vocab)
temperature (float): temperature
top_k (float): top_k
top_p (float): top_p
Returns:
torch.Tensor: next token with shape as (batch, 1)
"""
assert logits.dim() == 2
logits = logits / temperature
logits = top_k_top_p_filter(logits, top_k=top_k, top_p=top_p)
probs = F.softmax(logits, dim=1)
return probs
def sample(probs: torch.Tensor, num_samples: int = 1):
idx_next = torch.multinomial(probs, num_samples=num_samples)
if (idx_next.item() == 0):
raise RuntimeError
return idx_next
def norm_logits_whole(logits: torch.Tensor, temperature: float, top_k: float, top_p: float) -> torch.Tensor:
# 优化一版提速 矩阵计算代替原来的for循环
assert logits.dim() == 3
"""
Args:
logits (torch.Tensor): shape (1, vocab)
temperature (float): temperature
top_k (float): top_k
top_p (float): top_p
Returns:
torch.Tensor: next token with shape as (batch, 1)
"""
def top(scores: torch.FloatTensor, top_k: int = 0, top_p: float = 0.0):
sorted_logits, sorted_indices = torch.sort(scores, descending=False)
cumulative_probs = sorted_logits.softmax(dim=-1)
cumulative_probs = cumulative_probs.cumsum(dim=-1)
# Remove tokens with cumulative top_p above the threshold (token with 0 are kept)
sorted_indices_to_remove = cumulative_probs <= (1 - top_p)
# Keep at least min_tokens_to_keep
sorted_indices_to_remove[..., -1:] = 0
# indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
# 这个函数比较难理解、三维矩阵的scatter——就是把sorted_indices_to_remove 用 sorted_indices指定的index来还原
# print('sorted_indices',sorted_indices)
# print("sorted_indices_to_remove", sorted_indices_to_remove)
indices_to_remove = sorted_indices_to_remove.scatter(2, sorted_indices, sorted_indices_to_remove)
# print("indices_to_remove", indices_to_remove)
scores = scores.masked_fill(indices_to_remove, -float("Inf"))
return scores
if top_k > 0:
filter = torch.topk(logits, min(2, logits.size(-1)))[0]
logits[logits < filter[..., [-1]]] = float('-inf')
logits = logits / temperature
logits = top(logits, top_k, top_p)
probs = F.softmax(logits, dim=2)
return probs
def max_fn(x):
"""
norm(max (x, 0))
"""
x_max = torch.where(x > 0, x, torch.zeros_like(x))
x_max_sum = torch.sum(x_max, dim=1, keepdim=True)
return x_max / x_max_sum
class KVCachedGenration(object):
def __init__(self, model, eos_token, temperature: float = 1.0, top_k: int = 0, top_p: float = 0, do_sample=False):
self.model = model
self.eos_token = eos_token
self.past_key_values = None
self.prob_history = None
self.do_sample = do_sample
self.temperature = temperature
self.top_k = top_k
self.top_p = top_p
def get_position_ids(self, input_ids, device):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
@torch.no_grad()
def generate(self, input_ids, gamma, debug=False):
eos_index = None
x = input_ids
for index, _ in enumerate(range(gamma)):
if self.past_key_values:
kv_cached_len = self.past_key_values[0][0].shape[0]
position_ids = self.get_position_ids(x, x.device)
position_ids = position_ids[..., kv_cached_len:]
# ChatGLM一定要输入位置编码,一般推理的时候模型内部会自己配置位置编码的
t1 = time.time()
outputs = self.model(x[:, kv_cached_len:], position_ids=position_ids,
past_key_values=self.past_key_values, use_cache=True)
t2 = time.time()
if debug:
print(
f"post inference time {round((t2 - t1) * 1000, 4)} ms, data shape {x[:, kv_cached_len:].shape}")
logits = outputs.logits
t1 = time.time()
for i in range(logits.shape[1]):
logits[:, i, :] = norm_logits(logits[:, i, :], self.temperature, self.top_k, self.top_p)
t2 = time.time()
if debug:
print(f"norm_logits time {round((t2 - t1) * 1000, 4)} ms, data shape {x[:, kv_cached_len:].shape}")
probs = logits[:, -1, :]
self.past_key_values = outputs.past_key_values
self.prob_history = torch.cat([self.prob_history, logits], dim=1)
else:
t1 = time.time()
outputs = self.model(x)
t2 = time.time()
if debug:
print(f"first inference time {round((t2 - t1) * 1000, 4)} ms, data shape {x.shape}")
self.prob_history = outputs.logits
t1 = time.time()
for i in range(self.prob_history.shape[1]):
self.prob_history[:, i, :] = norm_logits(self.prob_history[:, i, :], self.temperature, self.top_k,
self.top_p)
t2 = time.time()
if debug:
print(f"norm_logits time {round((t2 - t1) * 1000, 4)} ms, data shape {self.prob_history.shape}")
self.past_key_values = outputs.past_key_values
probs = self.prob_history[:, -1, :]
if self.do_sample:
next_tok = sample(probs)
else:
next_tok = torch.argmax(probs, dim=-1).unsqueeze(0)
x = torch.cat((x, next_tok), dim=1)
if next_tok == self.eos_token and eos_index is None:
eos_index = index
return x, eos_index
@torch.no_grad()
def generate_promotion(self, input_ids, gamma, debug=False):
eos_index = None
x = input_ids
for index, _ in enumerate(range(gamma)):
if self.past_key_values:
kv_cached_len = self.past_key_values[0][0].shape[0]
position_ids = self.get_position_ids(x, x.device)
position_ids = position_ids[..., kv_cached_len:]
# ChatGLM一定要输入位置编码,一般推理的时候模型内部会自己配置位置编码的
t1 = time.time()
outputs = self.model(x[:, kv_cached_len:], position_ids=position_ids,
past_key_values=self.past_key_values, use_cache=True)
t2 = time.time()
if debug:
print(
f"post inference time {round((t2 - t1) * 1000, 4)} ms, data shape {x[:, kv_cached_len:].shape}")
logits = outputs.logits
# 优化一版提速
t1 = time.time()
logits = norm_logits_whole(logits, self.temperature, self.top_k, self.top_p)
t2 = time.time()
if debug:
print(
f"norm_logits_whole time {round((t2 - t1) * 1000, 4)} ms, data shape {x[:, kv_cached_len:].shape}")
probs = logits[:, -1, :]
self.past_key_values = outputs.past_key_values
self.prob_history = torch.cat([self.prob_history, logits], dim=1)
else:
t1 = time.time()
outputs = self.model(x)
t2 = time.time()
if debug:
print(f"first inference time {round((t2 - t1) * 1000, 4)} ms, data shape {x.shape}")
self.prob_history = outputs.logits
# 优化一版提速
t1 = time.time()
self.prob_history = norm_logits_whole(self.prob_history, self.temperature, self.top_k, self.top_p)
t2 = time.time()
if debug:
print(
f"norm_logits_whole time {round((t2 - t1) * 1000, 4)} ms, data shape {self.prob_history.shape}")
self.past_key_values = outputs.past_key_values
probs = self.prob_history[:, -1, :]
if self.do_sample:
next_tok = sample(probs)
else:
next_tok = torch.argmax(probs, dim=-1).unsqueeze(0)
x = torch.cat((x, next_tok), dim=1)
if next_tok == self.eos_token and eos_index is None:
eos_index = index
return x, eos_index
@torch.no_grad()
def kv_rollback(self, end_index):
# kv cache 回滚到有效生成位置
# ChatGLM k, v (seq, batch, head, hidden_dim)
# for i in range(len(self.past_key_values)):
# self.past_key_values[i][0] = self.past_key_values[i][0][:, :, :end_index, :]
# self.past_key_values[i][1] = self.past_key_values[i][1][:, :, :end_index, :]
# self.prob_history = self.prob_history[:, :end_index, :]
# kv cache 回滚到有效生成位置
# ChatGLM k, v (seq, batch, head, hidden_dim)
past_key_values_keeps = []
for index, kv in enumerate(self.past_key_values):
k, v = kv
k = k[:end_index, :, :, :]
v = v[:end_index, :, :, :]
kv = (k, v)
past_key_values_keeps.append(kv)
self.past_key_values = past_key_values_keeps
self.prob_history = self.prob_history[:, :end_index, :]
class SpeculateDecoding(object):
def __init__(self, approx_model, target_model, tokenizer, temperature=1.0, top_k=0, top_p=0.85, max_len=100,
random_seed=None):
self.approx_model = approx_model
self.target_model = target_model
self.tokenizer = tokenizer
self.device = approx_model.device
self.random_seed = random_seed
self.temperature = temperature
self.top_k = top_k
self.top_p = top_p
self.max_len = max_len
def speculative_decode_generate(self, prompt, gamma, do_sample=False, debug=False, promotion=True):
eos_token = self.tokenizer.eos_token_id
t1 = time.time()
approx_model_kv_cached_genration = KVCachedGenration(self.approx_model, eos_token, self.temperature, self.top_k,
self.top_p, do_sample)
target_model_kv_cached_genration = KVCachedGenration(self.target_model, eos_token, self.temperature, self.top_k,
self.top_p, do_sample)
t2 = time.time()
if debug:
print(f'cached_genration init {round((t2 - t1) * 1000, 4)} ms')
t1 = time.time()
inputs = self.tokenizer([prompt], return_tensors="pt", padding=True)
t2 = time.time()
if debug:
print(f'token2ids {round((t2 - t1) * 1000, 4)} ms')
t1 = time.time()
prefix = inputs['input_ids'].to(self.device)
t2 = time.time()
if debug:
print(f'tensor to gpu {round((t2 - t1) * 1000, 4)} ms')
seq_len = prefix.shape[1]
reject_count = 0
T = seq_len + self.max_len
end = T
assert prefix.shape[0] == 1, "input batch size must be 1"
eos_token_index = None
start_t = time.time()
with torch.no_grad():
while prefix.shape[1] < T:
prefix_len = prefix.shape[1]
if promotion:
x, index = approx_model_kv_cached_genration.generate_promotion(prefix, gamma, debug)
else:
x, index = approx_model_kv_cached_genration.generate(prefix, gamma, debug)
if debug:
print("小模型生成的token:", [self.tokenizer.decode(x[:, prefix_len:].tolist()[0])], "index: ",
x[:, prefix_len:].tolist()[0], "eos index:", index)
if index is not None:
eos_token_index = prefix_len + index
if promotion:
t_x, _ = target_model_kv_cached_genration.generate_promotion(x, 1, debug)
else:
t_x, _ = target_model_kv_cached_genration.generate(x, 1, debug)
n = prefix_len + gamma - 1
for i in range(gamma):
if self.random_seed:
torch.manual_seed(self.random_seed)
r = torch.rand(1, device=self.device)
else:
r = torch.as_tensor(1.0, dtype=torch.float, device=self.device)
j = x[:, prefix_len + i]
# 拒接 以1-p/q 的概率拒绝 生成
if r > (target_model_kv_cached_genration.prob_history[:, prefix_len + i - 1,
j] / approx_model_kv_cached_genration.prob_history[:, prefix_len + i - 1, j]):
n = prefix_len + i - 1
reject_count += 1
if debug:
print("被拒绝的token:", [self.tokenizer.decode(j)], "index: ", j, "被拒绝的位置:", i)
print("target_model",
target_model_kv_cached_genration.prob_history[:, prefix_len + i - 1, j])
print("approx_model",
approx_model_kv_cached_genration.prob_history[:, prefix_len + i - 1, j])
break
approx_model_kv_cached_genration.kv_rollback(n + 1)
prefix = x[:, :n + 1]
if debug:
print("eos_token_index:", eos_token_index)
print("n:", n)
# # 如果小模型生成的eos不被接受,则继续生成
# if eos_token_index and eos_token_index > n:
# eos_token_index = None
#
# # 如果小模型生成的eos被接受,则停止
# if eos_token_index and eos_token_index <= n:
# break
if eos_token_index is not None:
# 如果小模型生成的eos不被接受,则继续生成
if eos_token_index > n:
eos_token_index = None
else:
# 如果小模型生成的eos被接受,则停止
break
# 如果拒绝一些小模型生成的token,从大模型中采样
if n < prefix_len + gamma - 1:
if do_sample:
t = sample(max_fn(target_model_kv_cached_genration.prob_history[:, n,
:] - approx_model_kv_cached_genration.prob_history[:, n, :]))
else:
# t = torch.argmax(max_fn(target_model_kv_cached_genration.prob_history[:, n,
# :] - approx_model_kv_cached_genration.prob_history[:, n, :]),
# dim=-1).unsqueeze(0)
# 直接取大模型logits最大的那个token
t = torch.argmax(target_model_kv_cached_genration.prob_history[:, n, :], dim=-1).unsqueeze(0)
if debug:
print("拒绝后大模型重新生成的token:", [self.tokenizer.decode(t.tolist()[0])], " index: ", t.tolist()[0])
target_model_kv_cached_genration.kv_rollback(n + 1)
else:
if do_sample:
t = sample(target_model_kv_cached_genration.prob_history[:, -1, :])
else:
t = torch.argmax(target_model_kv_cached_genration.prob_history[:, -1, :], dim=-1).unsqueeze(0)
target_model_kv_cached_genration.kv_rollback(n + 2)
if debug:
print("接受后大模型生成的next token:", [self.tokenizer.decode(t.tolist()[0])], " index: ", t.tolist()[0])
prefix = torch.cat((prefix, t), dim=1)
if t == eos_token:
eos_token_index = prefix.shape[1] - 1
break
end_time = time.time()
if debug:
print(f"while loop time {round((end_time - start_t) * 1000, 4)} ms")
if eos_token_index:
end = eos_token_index + 1
t1 = time.time()
input_ids = inputs['input_ids'].tolist()[0]
assert len(input_ids) <= end, "eos_token选择位置错误"
output_token_ids = prefix.tolist()[0][len(input_ids):end]
response = self.tokenizer.decode(output_token_ids)
response = self.target_model.process_response(response)
t2 = time.time()
if debug:
print(f"post process {round((t2 - t1) * 1000, 4)} ms")
return response, reject_count三、效果实测
这一节我们开始效果实测,看看具体到实际业务落地效率和准确率指标,gama参数(小模型一次生成多少个token)和logits归一化优化的影响等。
测试环境Linux系统、显卡4090显卡、基于ChatGLM6B进行了业务微调得到大模型、花大力气蒸馏了6B得到1.5B小模型。
业务测试数据1088条,样例如下:

从坐席和客户的对话中提取出空调品牌、空调样式、是否5匹、故障类型、姓名、服务时间、联系方式和地址等等几个重要的信息。注意由于我们业务场景需要准确性,不需要模型发散输出多样性,我们解码的时候采用greedy search 解码策略,也就是生成token的时候采用torch.argmax(logits)来获取下一个token。
1、效果对比
tiny模型和big模型耗时以及准确率如下:
小模型
general.chat.tiny: 100%|████████████████████| 1088/1088 [09:03<00:00, 2.00it/s]
tiny cost total time is: 543.863 S, each time is: 499.87412222168024 ms
total 8704
correct 8539
items all acc 0.9810431985294118
{'姓名': 0.9898897058823529, '服务时间': 0.9476102941176471, '联系方式': 0.9908088235294118, '地址': 0.9448529411764706, '空调品牌': 0.9963235294117647, '空调样式': 0.9926470588235294, '是否5匹': 0.9972426470588235, '故障类型': 0.9889705882352942}
glm tiny acc: 0.859375
大模型
general.chat.common: 100%|█████████| 1088/1088 [31:12<00:00, 0.58it/s]
common cost total time is: 1871.7942 S, each time is: 1720.3990845264123 ms
total 8704
correct 8564
items all acc 0.9839154411764706
{'姓名': 0.9880514705882353, '服务时间': 0.9595588235294118, '联系方式': 0.9871323529411765, '地址': 0.9604779411764706, '空调品牌': 0.9926470588235294, '空调样式': 0.9954044117647058, '是否5匹': 0.9954044117647058, '故障类型': 0.9926470588235294}
glm common acc: 0.8759191176470589
可以看到我们蒸馏后的小模型效果也很好,和大模型差距不大,只有1.65个百分点的差距,耗时小模型每次推理500ms左右,大模型每次1720ms,小模型的速度大概是大模型的3.5倍。
看speculate sampling算法
logits归一化未优化? gama==7
r = troch.rand(1) 大模型argmax生成下一个token 以1-p(x)/q(x)的概率拒绝小模型的token gama==7
general.chat.speculatedecode: 100%|█████████| 1088/1088 [15:14<00:00, 1.19it/s]
speculate cost total time is: 914.1663 S, each time is: 840.2263719369383 ms
total 8704
correct 8576
items all acc 0.9852941176470589
{'姓名': 0.9880514705882353, '服务时间': 0.9604779411764706, '联系方式': 0.9898897058823529, '地址': 0.9641544117647058, '空调品牌': 0.9944852941176471, '空调样式': 0.9944852941176471, '是否5匹': 0.9972426470588235, '故障类型': 0.9935661764705882}
glm speculate acc: 0.8869485294117647
logits归一化优化? ?gama==7
r = troch.rand(1) 大模型argmax生成下一个token 以1-p(x)/q(x)的概率拒绝小模型的token gama==7 优化版本
general.chat.speculatedecode: 100%|█████████| 1088/1088 [12:56<00:00, 1.40it/s]
speculate promotion cost total time is: 776.8863 S, each time is: 714.0498757362366 ms
total 8704
correct 8577
items all acc 0.9854090073529411
{'姓名': 0.9880514705882353, '服务时间': 0.9613970588235294, '联系方式': 0.9898897058823529, '地址': 0.9641544117647058, '空调品牌': 0.9944852941176471, '空调样式': 0.9944852941176471, '是否5匹': 0.9972426470588235, '故障类型': 0.9935661764705882}
glm speculate promotion acc: 0.8878676470588235
logits归一化优化? ?gama==14
r = troch.rand(1) 大模型argmax生成下一个token 以1-p(x)/q(x)的概率拒绝小模型的token gama==14 优化版本
general.chat.speculatedecode: 100%|█████████| 1088/1088 [11:41<00:00, 1.55it/s]
speculate promotion cost total time is: 700.5773 S, each time is: 643.9129872357144 ms
total 8704
correct 8574
items all acc 0.9850643382352942
{'姓名': 0.9880514705882353, '服务时间': 0.9604779411764706, '联系方式': 0.9889705882352942, '地址': 0.9632352941176471, '空调品牌': 0.9944852941176471, '空调样式': 0.9954044117647058, '是否5匹': 0.9972426470588235, '故障类型': 0.9926470588235294}
glm speculate promotion gama 14 acc: 0.8851102941176471
speculate sampling算法确实有效,相对大模型而言确实能提升推理速度并完美保持大模型的生成质量。基线效果是提速1.05倍、优化logits归一化后提速1.41倍、gama=14时提速1.67倍,同时算法在测试集上的准确率均超过单一大模型准确率,有偶然性,这个和测试数据以及大模型和小模型的效果强相关,当然不仅仅是准确率,推理速度也是和上述因素强相关的。
另一方面,gama增加的同时只要小模型效果还行,那被拒绝的次数不太多的情况下,一次推理过程,大模型的forward次数就减少了,那么提速是理所当然的了。
2、解码日志展示
最后我们看一下解码过程中debug的日志,同一个输入
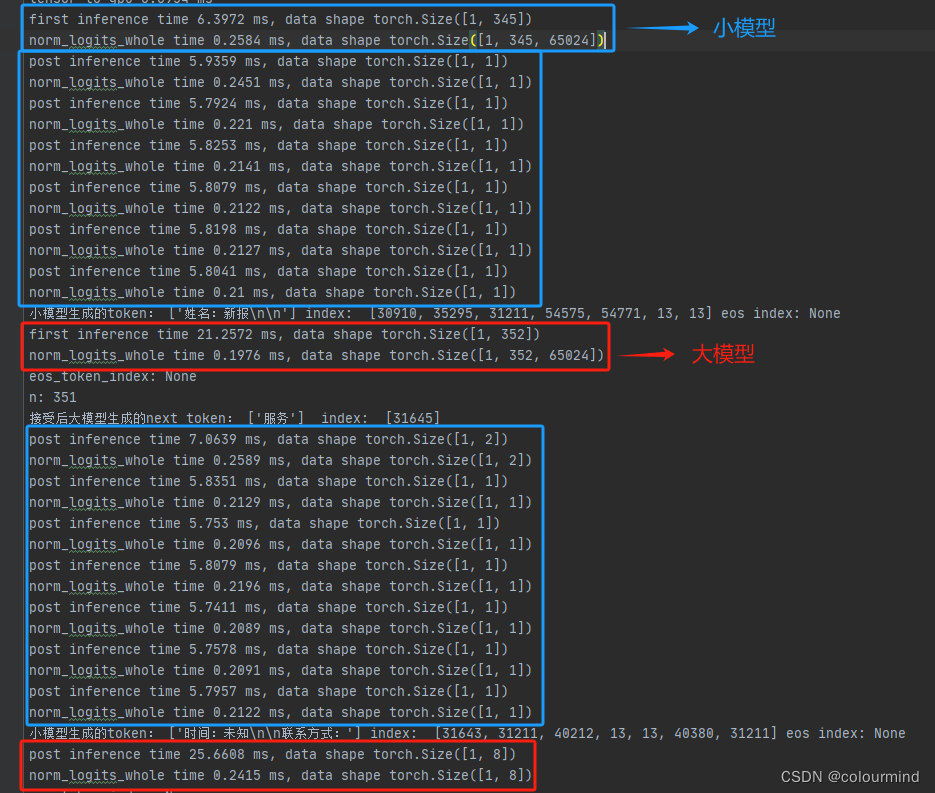
gama=7? logits归一化未优化时

while loop time 795.3556 ms
可以看到大模型forward耗时是小模型forward耗时的3-5倍之间;norm_logits的时间在首次forward后,seq_len为352,耗时80ms左右,小模型和大模型都要执行一次;后面大模型forward每次过8个token,norm_logits为1.75ms左右。
gama=7? logits归一化优化后
while loop time 691.3598 ms
每次inference大小模型forward基本没有变化,变化的是norm_logits为优化后的norm_logits_whole,首次forward后,seq_len为352,耗时0.9ms左右,这块儿优化耗时巨大;后面大模型forward每次过8个token,norm_logits_whole为0.25ms左右也有不小的优化。总体上来看也有100ms左右的优化。
gama=14??logits归一化优化后
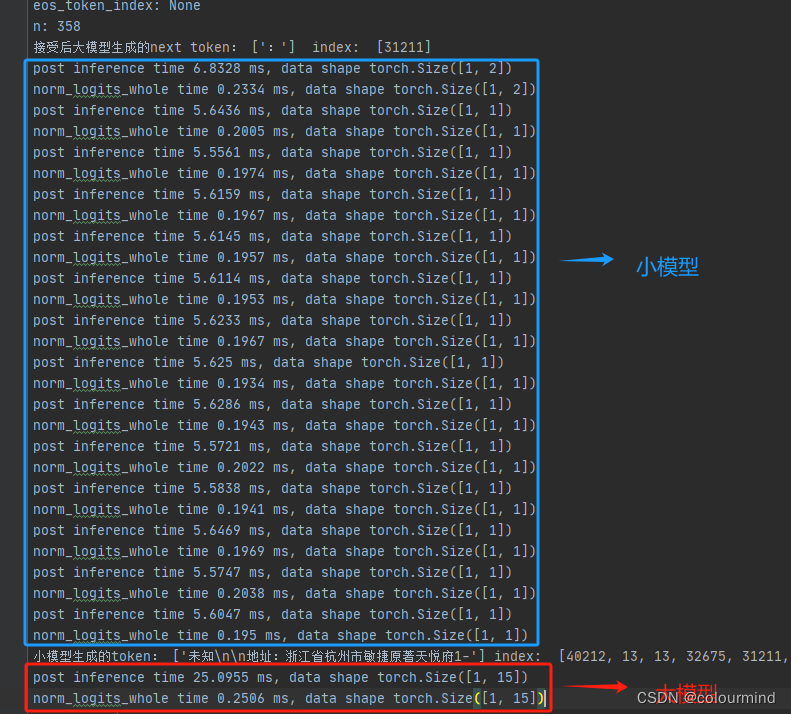
while loop time 542.4328 ms
当gama=14和gama=7对比大模型forward一次15个token为25ms左右,8个token也为25ms左右,耗时差不多,这个和GPU的矩阵并行计算有关;但是整个解码算法过程中大模型forward次数为4,gama=7时大模型forward次数为8,而小模型耗时确实基本不变,因此整体上优化耗时为4*25ms=100ms左右,再加上其他的一些随机耗时差不多能到100-150ms左右。
以上是一个具体测试用例的分析,Speculative Decoding算法的收益和大小两个模型的效果差异有明显关系,相差不是太大,才会有加速的效果;同时小模型的效果又不能比大模型差太小,不然直接使用小模型就好了。相对而言应用场景比较受限,资源消耗也是需要两次训练资源,推理的时候需要大小模型占用的显存。就本次效果测试来说,ChatGLM6B大模型推理占用显存12.8G;小模型4.5G;Speculative Decoding大小模型联合则占用17.5G左右。当然这个Speculative Decoding算法很优秀,实现比较简单,确实比较取巧的实现了大模型推理的加速效果,同时生成质量完美保留。
最后的最后,对推理速度和效果都卡的比较死的业务场景对这个算法有一定的需求。
参考文章
大模型推理妙招—投机采样(Speculative Decoding)
Fast Inference from Transformers via Speculative Decoding
Accelerating Large Language Model Decoding with Speculative Sampling
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!