redis—Hash哈希
目录
前言
几乎所有的主流编程语言都提供了哈希(hash) 类型,它们的叫法可能是哈希、字典、关联数组、映射。在Redis中,哈希类型是指值本身又是一个键值对结构,形如key= "key", value={{
field1, value1 }, ... {fieldN, valueN }}, Redis 键值对和哈希类型二者的关系可以用图2-15来表示。
图2-15字符串和哈希类型对比

哈希类型中的映射关系通常称为field-value, 用于区分Redis整体的键值对(key-value) ,注意这里的value是指field对应的值,不是键(key) 对应的值,请注意value在不同上下文的作用。
1.常见命令
HSET
设置hash中指定的字段(field) 的值(value) 。
语法:
HSET key field value [field value ...] 命令有效版本: 2.0.0之后
时间复杂度:插入一组field为0(1),插入N组field为O(N)
返回值:添加的字段的个数。
示例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"Hello"HGET
获取hash中指定字段的值。
语法:
HGET key field 命令有效版本: 2.0.0之后
时间复杂度: O(1)
返回值:字段对应的值或者nil。
示例:
redis> HSET myhash field1 "foo"
(integer) 1
redis> HGET myhash field1
"foo"
redis> HGET myhash field2
(nil)HEXISTS
判断hash中是否有指定的字段。
语法:
HEXISTS key field 命令有效版本: 2.0.0之后
时间复杂度: O(1)
返回值: 1 表示存在,0表示不存在。
示例:
redis> HSET myhash field1 "foo"
(integer) 1
redis> HEXISTS myhash field1
(integer) 1
redis> HEXISTS myhash field2
(integer) 0HDEL
删除hash中指定的字段。
语法:
HDEL key field [field ...]命令有效版本: 2.0.0之后
时间复杂度:删除一个元素为0(1).删除N个元素为O(N).
返回值:本次操作删除的字段个数。
示例:
redis> HSET myhash field1 "foo"
(integer) 1
redis> HDEL myhash field1
(integer) 1
redis> HDEL myhash field2
(integer) 0HKEYS
获取hash中的所有字段。
语法:
HKEYS key 命令有效版本: 2.0.0之后
时间复杂度: O(N), N为field的个数.
返回值:字段列表。
示例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HKEYS myhash
1) "field1"
2) "field2"HVALS?
获取hash中的所有的值。
语法:
HVALS key 命令有效版本: 2.0.0 之后
时间复杂度: O(N), N为field的个数.
返回值:所有的值。
示例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HVALS myhash
1) "Hello"
2) "World"HGETALL
获取hash中的所有字段以及对应的值。
语法:
HGETALL key 命令有效版本: 2.0.0之后
时间复杂度: O(N), N为field的个数.
返回值:字段和对应的值。
示例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"HMGET
一次获取hash中多个字段的值。
语法:
HMGET key field [field ...] 命令有效版本: 2.0.0之后
时间复杂度:只查询一个元素为0(1),查询多个元素为O(N), N为查询元素个数.
返回值:字段对应的值或者nil.?
示例:
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)在使用HGETALL时,如果哈希元素个数比较多,会存在阻塞Redis的可能。如果开发人员只需要获取部分field,可以使用HMGET,如果一定要获取全部field,可以尝试使用HSCAN命令,该命令采用渐进式遍历哈希类型,HSCAN会在后续章节介绍。
HLEN
获取hash中的所有字段的个数。
语法:
HLEN key redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HLEN myhash
(integer) 2HSETNX
在字段不存在的情况下,设置hash中的字段和值。
语法:
HSETNX key field value 命令有效版本: 2.0.0之后
时间复杂度: 0(1)
返回值: 1表示设置成功,0表示失败。
示例:
redis> HSETNX myhash field "Hello"
(integer) 1
redis> HSETNX myhash field "World"
(integer) 0
redis> HGET myhash field
"Hello"HINCRBY
将hash中字段对应的数值添加指定的值。
语法:
HINCRBY key field increment 命令有效版本: 2.0.0之后
时间复杂度: 0(1)
返回值:该字段变化之后的值。
示例:
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5HINCRBYFLOAT
HINCRBY的浮点数版本。
语法:
HINCRBYFLOAT key field increment 命令有效版本: 2.6.0之后
时间复杂度: 0(1)
返回值:该字段变化之后的值。
示例:
redis> HSET mykey field 10.50
(integer) 1
redis> HINCRBYFLOAT mykey field 0.1
"10.6"
redis> HINCRBYFLOAT mykey field -5
"5.6"
redis> HSET mykey field 5.0e3
(integer) 0
redis> HINCRBYFLOAT mykey field 2.0e2
"5200"1.1命令小结
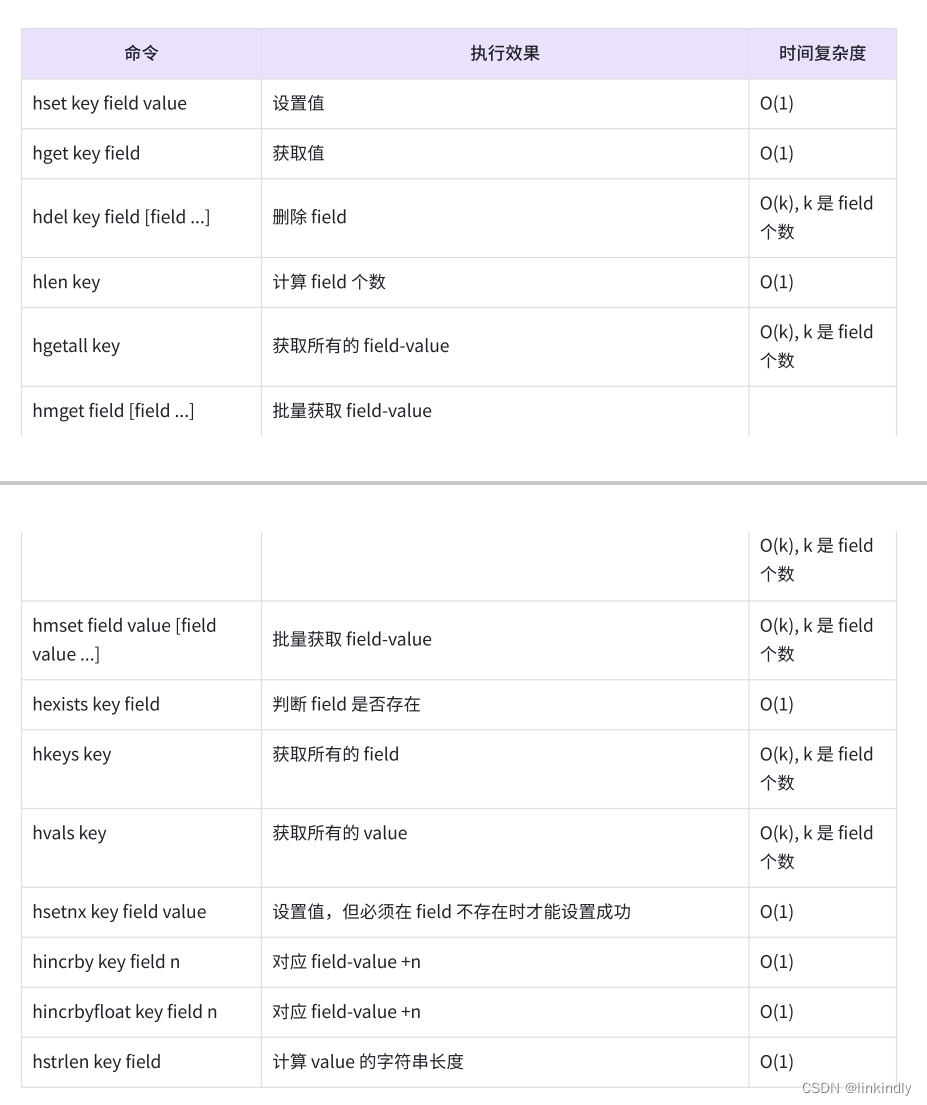
表2-4是哈希类型命令的效果、时间复杂度,开发人员可以参考此表,结合自身业务需求和数据
大小选择合适的命令。
表2-4哈希类型命令小结
1.2内部编码
哈希的内部编码有两种:
ziplist (压缩列表) : 当哈希类型元素个数小于hash-max -ziplist-entries配置(默认512个)、
同时所有值都小于hash-max- ziplist-value配置(默认 64字节)时,Redis 会使用ziplist作为哈
希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比
hashtable更加优秀。
●hashtable (哈希表) :当哈希类型无法满足ziplist的条件时,Redis 会使用hashtable作为哈希
的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为0(1)。
下面的示例演示了哈希类型的内部编码,以及响应的变化。
1)当field个数比较少且没有大的value时,内部编码为ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"2)当有value大于64字节时,内部编码会转换为hashtable:
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 bytes ... 省略 ..." 1
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"3)当field个数超过512时,内部编码也会转换为hashtable:?
127.0.0.1:6379> hmset hashkey f1 v1 h2 v2 f3 v3 ... 省略 ... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"2.使用场景
图2-16为关系型数据表记录的两条用户信息,用户的属性表现为表的列,每条用户信息表现为行。如果映射关系表示这两个用户信息,则如图2-17所示。
图2-16关系型数据表保存用户信息
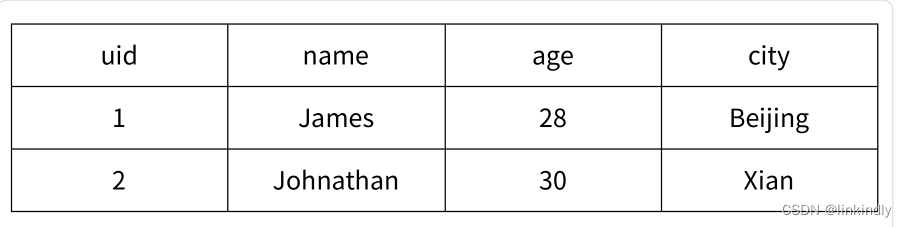
图2-17映射关系表示用户信息
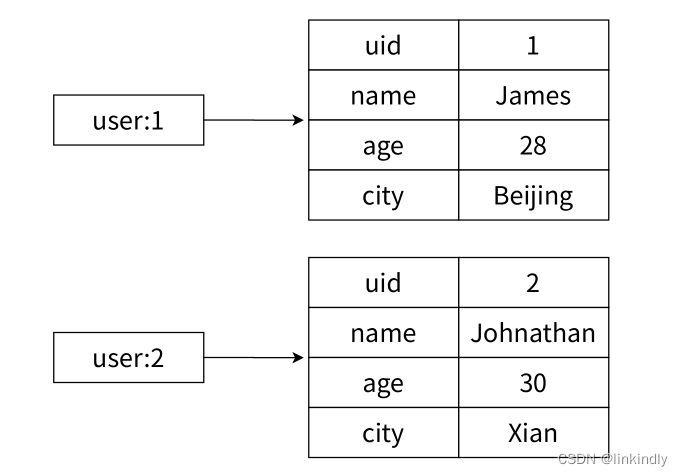
相比于使用JSON格式的字符串缓存用户信息,哈希类型变得更加直观,并且在更新操作.上变得
更灵活。可以将每个用户的id定义为键后缀,多对field-value对应用户的各个属性,类似如下伪代
码:

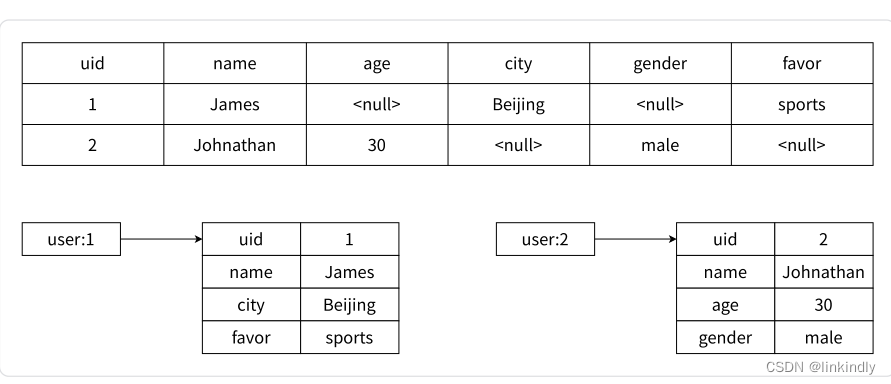
●哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型每个键可以有不同的field, 而
关系型数据库一旦添加新的列,所有行都要为其设置值,即使为null,如图2-18所示。
●关系数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询,例如联表查询、聚合查询等基本不可能,维护成本高。
图2-18关系型数据库稀疏性
缓存方式对比
截至目前为止,我们已经能够用三种方法缓存用户信息,下面给出三种方案的实现方法和优缺点
分析。
1.原生字符串类型一使用字符串类型, 每个属性一个键。
set user:1:name James
set user:1:age 23
set user:1:city Beijing优点:实现简单,针对个别属性变更也很灵活。
缺点:占用过多的键,内存占用量较大,同时用户信息在Redis中比较分散,缺少内聚性,所以这种
方案基本没有实用性。
2.序列化字符串类型,例如JSON格式
set user:1 经过序列化后的??对象字符串 优点:针对总是以整体作为操作的信息比较合适,编程也简单。同时,如果序列化方案选择合适,内存的使用效率很高。
缺点:本身序列化和反序列需要一-定开 销,同时如果总是操作个别属性则非常不灵活。
3.hash类型:
hmset user:1 name James age 23 city Beijing 优点:简单、直观、灵活。尤其是针对信息的局部变更或者获取操作。
缺点:需要控制哈希在ziplist和hashtable两种内部编码的转换,可能会造成内存的较大消耗。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!