Spring源码之依赖注入(一)
一、简介
1. 概念
前面我们已经分析完了Bean的生命周期,包括BeanDefinition的扫描与注册,Bean的初始化和销毁等。今天就来分析依赖注入(DI)相关的源码。
依赖注入: Dependency Injection,它是 spring 框架核心 IOC 的具体实现,具体点就是依赖关系的维护称之为依赖注入。我们的程序在编写时, 通过控制反转(IOC), 把对象的创建交给了 spring,但是代码中不可能出现没有依赖的情况。
IOC 解耦只是降低他们的依赖关系,但不会消除。 例如:我们的业务层仍会调用持久层的方法。那这种业务层和持久层的依赖关系, 在使用 spring 之后, 就让 spring 来维护了,简单的说,就是坐等框架把持久层对象传入业务层,而不用我们自己去获取。
2. 使用方法
常见的实现依赖注入的方式有两种,第一种是直接使用@Autowired注解
@Component
public class OrderService {
public void test(){
System.out.println("我现在是一个bean了");
}
}
@Component
public class UserService {
@Autowired
private OrderService orderService;
public void test(){
orderService.test();
}
public void close(){
System.out.println("close方法被调用了");
}
}
然后我们再看看测试方法
public class Test {
public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
UserService userService = (UserService) applicationContext.getBean("userService");
userService.test();
}
}

第二种方式是我们再生成的BeanDefinition中自己手动进行依赖注入
public class OrderService {
public void test(){
System.out.println("我现在是一个bean了");
}
}
@Component
public class UserService {
private OrderService orderService;
public void test(){
orderService.test();
}
public void close(){
System.out.println("close方法被调用了");
}
public OrderService getOrderService() {
return orderService;
}
public void setOrderService(OrderService orderService) {
this.orderService = orderService;
}
}
从结果可以看出依赖注入同样是成功的
下面来逐步分析其源码
二、源码分析
1. Byname或Bytype注入方式
我们知道依赖注入是发生在创建Bean过程中,所以要看其源码我们同样要去到核心方法doCreateBean中
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// 实例化bean
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 有可能在本Bean创建之前,就有其他Bean把当前Bean给创建出来了(比如依赖注入过程中)
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 创建Bean实例
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// 后置处理合并后的BeanDefinition
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// 为了解决循环依赖提前缓存单例创建工厂
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 循环依赖-添加到三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 属性填充
populateBean(beanName, mbd, instanceWrapper);
// 初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
// beanName被哪些bean依赖了,现在发现beanName所对应的bean对象发生了改变,那么则会报错
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
前面我们讲到在上面源码中,填充属性所调用的函数为populateBean(beanName, mbd, instanceWrapper);,所以依赖注入相关的内容也应该在这个函数中,所以我们进入这个函数。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
// 实例化之后,属性设置之前
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
if (!bp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
// MutablePropertyValues是PropertyValues具体的实现类
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
// 这里会调用AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法,会直接给对象中的属性赋值
// AutowiredAnnotationBeanPostProcessor内部并不会处理pvs,直接返回了
PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = bp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
// 如果当前Bean中的BeanDefinition中设置了PropertyValues,那么最终将是PropertyValues中的值,覆盖@Autowired
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
首先分析一下面这部分代码,其实下面这部分代码就是在使用Spring已经弃用的Byname和Bytype的注入方法。
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
// MutablePropertyValues是PropertyValues具体的实现类
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
首先我们看看byname和bytype是怎么使用的
@ComponentScan("com.zhouyu")
@EnableScheduling
@PropertySource("classpath:spring.properties")
public class AppConfig {
@Bean(autowire = Autowire.BY_NAME)
public UserService userService(){
return new UserService();
}
}
@Component
public class OrderService {
public void test(){
System.out.println("我现在是一个bean了");
}
}
public class UserService {
private OrderService orderService;
public void test(){
orderService.test();
}
public void close(){
System.out.println("close方法被调用了");
}
public OrderService getOrderService() {
return orderService;
}
public void setOrderService(OrderService orderService) {
this.orderService = orderService;
}
}
上面代码的核心逻辑就是在AppConfig中使用@Bean注解将我们的UserService注入成一个Bean,然后填充来这个注解的属性@Bean(autowire = Autowire.BY_NAME)。同时最关键的是OrderService类中要有注入属性的Set方法(其实底层Spring会执行所有的Set方法,以达到依赖注入的逻辑)。

再回到源码,按照案例我们的注入方法是Byname,所以代码会进入下面代码块:
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
然后执行autowireByName方法
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
// 当前Bean中能进行自动注入的属性名
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
// 遍历每个属性名,并去获取Bean对象,并设置到pvs中
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
Object bean = getBean(propertyName);
pvs.add(propertyName, bean);
// 记录一下propertyName对应的Bean被beanName给依赖了
registerDependentBean(propertyName, beanName);
if (logger.isTraceEnabled()) {
logger.trace("Added autowiring by name from bean name '" + beanName +
"' via property '" + propertyName + "' to bean named '" + propertyName + "'");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
"' by name: no matching bean found");
}
}
}
}
首先它执行String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);拿到当前bean的注入的符合javabean规范的属性名。
protected String[] unsatisfiedNonSimpleProperties(AbstractBeanDefinition mbd, BeanWrapper bw) {
Set<String> result = new TreeSet<>();
PropertyValues pvs = mbd.getPropertyValues();
//获得当前bean的属性描述器
PropertyDescriptor[] pds = bw.getPropertyDescriptors();
// 什么样的属性能进行自动注入?
// 1.该属性有对应的set方法
// 2.没有在ignoredDependencyTypes中
// 3.如果该属性对应的set方法是实现的某个接口中所定义的,那么接口没有在ignoredDependencyInterfaces中
// 4.属性类型不是简单类型,比如int、Integer、int[]
for (PropertyDescriptor pd : pds) {
//getWriteMethod判断是否有set方法
//pvs.contains表示当前BeanDefinition属性值集合中是否已经有当前属性的值了,有了我们就不需要重复注入了
//BeanUtils.isSimpleProperty判断我们要注入的属性类型是否是简单类型,如Number,String等,这种简单类型我们的Byname注入方式是不会管的(注意@Autowired会管)
if (pd.getWriteMethod() != null && !isExcludedFromDependencyCheck(pd) && !pvs.contains(pd.getName()) &&
!BeanUtils.isSimpleProperty(pd.getPropertyType())) {
result.add(pd.getName());
}
}
return StringUtils.toStringArray(result);
}
所谓符合javaBean规范的属性名是指,该属性有相应的get和set方法。上面代码不是拿的属性本身,而是set和get方法,所以我们甚至不需要定义这个orderService属性,只要有get和set方法我们都可以拿到这个属性描述器实现依赖注入。继续回到autowireByName方法,拿到所有要注入的属性后,我们就可以开始实现注入了。
for (String propertyName : propertyNames) {
if (containsBean(propertyName)) {
//获取要注入的属性对应的bean
Object bean = getBean(propertyName);
//将我们得到的bean记录到beanDefinition中的属性值集合中
pvs.add(propertyName, bean);
// 记录一下propertyName对应的Bean被beanName给依赖了
registerDependentBean(propertyName, beanName);
if (logger.isTraceEnabled()) {
logger.trace("Added autowiring by name from bean name '" + beanName +
"' via property '" + propertyName + "' to bean named '" + propertyName + "'");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
"' by name: no matching bean found");
}
}
}
上面代码的逻辑就是,我们前面找到所有的属性描述器后,然后遍历使用getBean方法获得对应的bean,然后将该bean记录到BeanDefinition中的属性值集合中。 上面代码执行完后autowireByName方法就执行完毕了,继续回到populateBean方法,那么现在的疑问就是我们到底是什么实现将属性值实现真正的注入呢?上面的逻辑只是获得了属性值所对应的bean。其实实现这个逻辑的是populateBean方法中的这一句代码:if (pvs != null) {applyPropertyValues(beanName, mbd, bw, pvs);},意识就是如果我们的BeanDefinition对应的属性值几何不为空,我们就执行applyPropertyValues方法。这里就实现了Byname或Bytype注入的逻辑。(Bytype就是根据set方法传入参数的类型来获取对应的bean,和byname相比只是获取bean的逻辑不同,其它基本相同)。
2. @Autowired注入方式
前面分析完第一种Byname和Bytype的注入方式,现在我们来分析@Autowired注入方式。首先我们继续回到populateBean方法。
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware) {
// 这里会调用AutowiredAnnotationBeanPostProcessor的postProcessProperties()方法,会直接给对象中的属性赋值
// AutowiredAnnotationBeanPostProcessor内部并不会处理pvs,直接返回了
PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = bp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
上面代码中处理@AutoWired注解的核心代码是PropertyValues pvsToUse = bp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);,其实这句代码中不仅仅会处理@AutoWired注解,同样会处理@Value和@Resource注解。在这句代码之前有一个for循环如下:
for (InstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().instantiationAware)
这个for循环就是遍历InstantiationAwareBeanPostProcessor,该接口有很多实现类,如下:
其中@Autowired注解就是由AutowiredAnnotationBeanPostProcessor这个类处理的。然后@Resource是由CommonAnnotationBeanPostProcessor这个类处理的,我们这里主要看AutowiredAnnotationBeanPostProcessor这个类。
public class AutowiredAnnotationBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor,
MergedBeanDefinitionPostProcessor, PriorityOrdered, BeanFactoryAware
这个类实现类SmartInstantiationAwareBeanPostProcessor和 MergedBeanDefinitionPostProcessor接口:
- SmartInstantiationAwareBeanPostProcessor(继承了InstantiationAwareBeanPostProcessor接口)
该接口在实例化 bean 之前,允许在 bean 创建过程中进行一些定制化的操作。其中的方法包括 predictBeanType、determineCandidateConstructors 和 getEarlyBeanReference。这些方法允许在实例化 bean 之前对 bean 进行预测、选择构造函数以及获取提前引用(early reference)。SmartInstantiationAwareBeanPostProcessor 的实现可以用于处理一些特殊的构造函数选择逻辑,或者在实例化 bean 之前提供一些代理等增强操作。
- MergedBeanDefinitionPostProcessor
该接口在 bean 的定义信息合并之后,允许对合并后的 RootBeanDefinition 进行进一步的处理。主要方法是 postProcessMergedBeanDefinition,该方法在 bean 定义信息合并后被调用,允许对合并后的 RootBeanDefinition 进行后续的处理。MergedBeanDefinitionPostProcessor 的实现可以用于修改或补充 bean 的定义信息,例如,添加属性、修改属性值、验证合并后的定义等。在 AutowiredAnnotationBeanPostProcessor 中,这个接口的实现通常用于处理 @Autowired 注解的逻辑,确保正确注入依赖。
对于上面两个接口在Bean生命周期中调用的顺序是怎么样的,其实这一部分在Bean的生命周期(二)中已经分析了。具体的逻辑如下图:
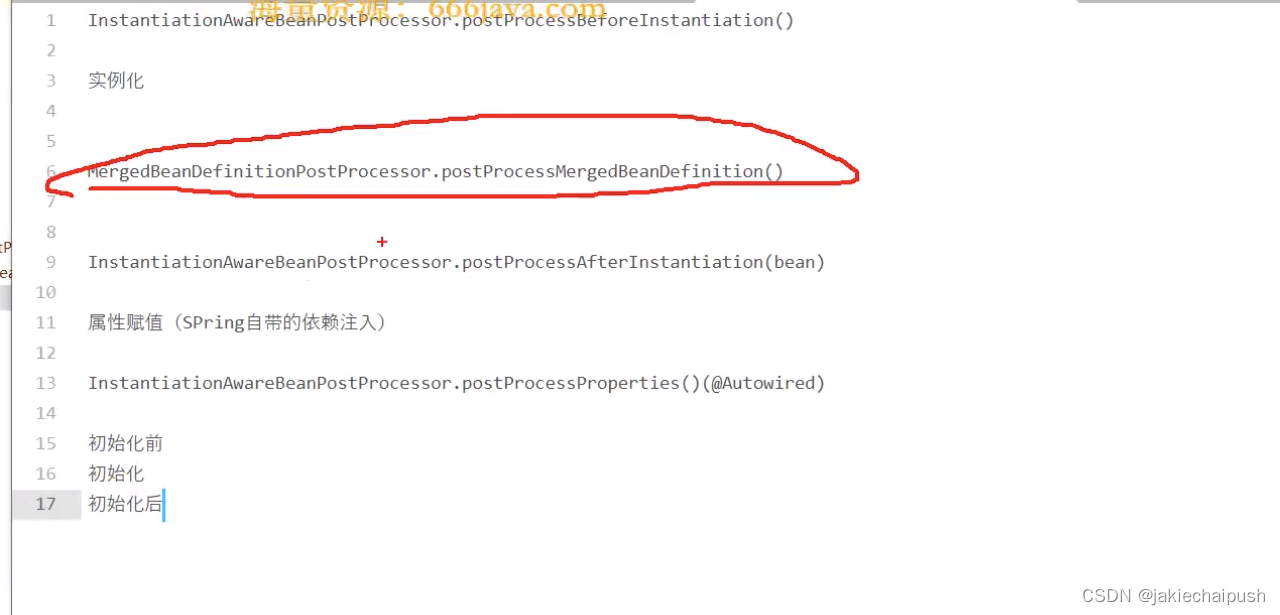
从上图可以看出是MergedBeanDefinitionPostProcessor.postProcessMergeBeanDefinition先执行,然后是InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation后执行,下面我们来分析一下这两个方法。
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
上面方法就是将我们的BeanDefinition和beanType和beanName作为参数传入这个方法,然后调用findAutowiringMetadata,找到我们的注入点,也就是加了@Autowired的地方。
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// Quick check on the concurrent map first, with minimal locking.
//InjectionMetadata可以理解为当前bean所有注入点的一个集合
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
// 解析注入点并缓存
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
}
}
return metadata;
}
上面找注入点的核心代码是metadata = buildAutowiringMetadata(clazz);,下面我们进入这个方法,看看它底层到底是如何找到我们的注入点的。
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
// 如果一个Bean的类型是String...,那么则根本不需要进行依赖注入(底层它会判断注入点类型是否是java.开头,如果是就不需要进行依赖注入。
if (!AnnotationUtils.isCandidateClass(clazz, this.autowiredAnnotationTypes)) {
return InjectionMetadata.EMPTY;
}
List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();
// 遍历targetClass中的所有Field
ReflectionUtils.doWithLocalFields(targetClass, field -> {
// field上是否存在@Autowired、@Value、@Inject中的其中一个
MergedAnnotation<?> ann = findAutowiredAnnotation(field);
if (ann != null) {
// static filed不是注入点,不会进行自动注入
if (Modifier.isStatic(field.getModifiers())) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation is not supported on static fields: " + field);
}
return;
}
// 构造注入点
boolean required = determineRequiredStatus(ann);
//将找到注入点字段构建成一个AutowiredFieldElement对象,加入到currElements这个注入点集合中
currElements.add(new AutowiredFieldElement(field, required));
}
});
// 遍历targetClass中的所有Method
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
//这里是处理bean的桥接方法,。桥接方法是用于解决Java泛型擦除问题的特殊方法。下面代码就是过滤掉桥接方法
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
// method上是否存在@Autowired、@Value、@Inject中的其中一个
MergedAnnotation<?> ann = findAutowiredAnnotation(bridgedMethod);
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
// static method不是注入点,不会进行自动注入
if (Modifier.isStatic(method.getModifiers())) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation is not supported on static methods: " + method);
}
return;
}
// set方法最好有入参
if (method.getParameterCount() == 0) {
if (logger.isInfoEnabled()) {
logger.info("Autowired annotation should only be used on methods with parameters: " +
method);
}
}
//这句代码主要是处理autowired的require属性的
boolean required = determineRequiredStatus(ann);
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);
currElements.add(new AutowiredMethodElement(method, required, pd));
}
});
elements.addAll(0, currElements);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
//将所有的注入点汇集起来,返回一个InjectionMetadata对象
return InjectionMetadata.forElements(elements, clazz);
}
知识点补充:
桥接方法
桥接方法是jvm底层用于解决Java泛型擦除问题的特殊方法。在Java中,泛型类型信息在编译时会被擦除,这就意味着在编译后的字节码中,不再包含有关泛型类型的具体信息。然而,在某些情况下,我们仍然希望在运行时能够获取到泛型类型的信息。为了解决这个问题,Java引入了桥接方法(Bridge Method)。桥接方法的存在是为了在子类继承或实现泛型接口时,保持对泛型类型的正确处理。这个情况通常发生在具有泛型参数的接口或类中,例如:public interface MyGenericInterface<T> { void myMethod(T param); } public class MyClass implements MyGenericInterface<String> { void myMethod(String param) { // 实现 } }在这个例子中,MyClass实现了MyGenericInterface,但在字节码层面,MyClass中的myMethod方法的参数类型是Object而不是String。为了正确处理泛型,编译器会生成一个桥接方法,它会将泛型类型的信息保留下来:
public class MyClass implements MyGenericInterface<String> { void myMethod(String param) { // 实现 } // 自动生成的桥接方法 void myMethod(Object param) { myMethod((String) param); } }
上面代码的逻辑就是找当前bean的所有注入点,首先遍历字段,找到所有的字段注入点,然后判断是否是强制注入(require属性),然后将解析的注入点创建一个AutowiredFieldElement对象,加入到InjectionMetadata这个注入点集合中。同时然后遍历方法,也是上面的逻辑同样封装成一个AutowiredMethodElement对象,加入到InjectionMetadata集合中,执行完上面的方法,当前bean的所有注入点就已经找到了。回到findAutowiringMetadata。
this.injectionMetadataCache.put(cacheKey, metadata);
然后将封装有注入点的对象InjectionMetadata存入到this.injectionMetadataCache这个集合中。到此上面的找注入点的逻辑就执行完了。postProcessMergedBeanDefinition执行完后,然后执行InstantiationAwareBeanPostProcessor接口的方法,对注入点进行赋值。
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
// 找注入点(所有被@Autowired注解了的Field或Method)
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}
postProcessProperties开始同样调用了findAutowiringMetadata方法尝试寻找注入点,但这次是能够直接从缓存中拿出来,我们从this.injectionMetadataCache集合中拿到前面缓存的注入点对象InjectionMetadata。 拿到注入点信息,我们现在就可以开始执行真正的注入逻辑了metadata.inject(bean, beanName, pvs);,参数为当前bean,beanname和beanDefinition对象对应的属性值集合。
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
// 遍历每个注入点进行依赖注入
for (InjectedElement element : elementsToIterate) {
element.inject(target, beanName, pvs);
}
}
}
上面代码最核心的就是遍历InjectionMetadata中的this.checkedElements,也就是注入点集合。然后针对不同的element类型会调用不同的注入方法(在注册注入点时已经说到了这两种类型,分别是AutowiredFieldElement和AutowiredMethodElement)。下面我们看看这两种不同类型对于的inject方法,首先看AutowiredFieldElement的。
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
//获得当前注入点的封装字段
Field field = (Field) this.member;
Object value;
if (this.cached) {
// 对于原型Bean,第一次创建的时候,也找注入点,然后进行注入,此时cached为false,注入完了之后cached为true
// 第二次创建的时候,先找注入点(此时会拿到缓存好的注入点),也就是AutowiredFieldElement对象,此时cache为true,也就进到此处了
// 注入点内并没有缓存被注入的具体Bean对象,而是beanName,这样就能保证注入到不同的原型Bean对象
try {
value = resolvedCachedArgument(beanName, this.cachedFieldValue);
}
catch (NoSuchBeanDefinitionException ex) {
// Unexpected removal of target bean for cached argument -> re-resolve
value = resolveFieldValue(field, bean, beanName);
}
}
else {
// 根据filed从BeanFactory中查到的匹配的Bean对象
value = resolveFieldValue(field, bean, beanName);
}
// 反射给filed赋值
if (value != null) {
ReflectionUtils.makeAccessible(field);
field.set(bean, value);
}
}
上面代码就完成了字段的注入,具体注入的逻辑后面再讲,再看AutowiredMethodElement的inject方法。
@Override
protected void inject(Object bean, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
// 如果pvs中已经有当前注入点的值了,则跳过注入(避免重复注入)
if (checkPropertySkipping(pvs)) {
return;
}
Method method = (Method) this.member;
Object[] arguments;
if (this.cached) {
try {
arguments = resolveCachedArguments(beanName);
}
catch (NoSuchBeanDefinitionException ex) {
// Unexpected removal of target bean for cached argument -> re-resolve
arguments = resolveMethodArguments(method, bean, beanName);
}
}
else {
arguments = resolveMethodArguments(method, bean, beanName);
}
if (arguments != null) {
try {
ReflectionUtils.makeAccessible(method);
method.invoke(bean, arguments);
}
catch (InvocationTargetException ex) {
throw ex.getTargetException();
}
}
}
上面代码就会遍历方法的每一个参数值,然后找参数对应的bean赋值。详细原理后面再讲。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!