NeurIPS 2023丨说话人识别:语音解耦与自监督

 ?论文链接:
?论文链接:
https://arxiv.org/abs/2310.01128

该研究由新加坡国家科技局(A?STAR)、新加坡国立大学、香港理工大学和香港中文大学(深圳)的研究人员共同完成。该项工作已被NeurIPS 2023(main track)接收。
对于说话人识别/验证(speaker recognition/verification)任务而言,提取准确的说话人表征(speaker representation)是非常困难的,因为语音信息中同时包含了说话人特征信息和语音内容信息[1]。
为了减少内容信息变化带来的影响,很多现有的工作使用phonetic信息作为特征提取的辅助信息[2-4]。而这种方法往往需要比说话人识别模型大很多的语音识别(ASR)模型[2],或者需要训练数据中包含文本信息的标签[3,4]。以说话人识别广泛使用的VoxCeleb数据集[5]为例,准确地标注超过百万条语音的文本标签是成本极高的。
为了解决上述问题,在这篇论文中,研究人员提出了一个新的解耦框架(disentanglement framework)。该框架可在只使用说话人标签,而文本标签缺失的情况下训练,完成对语音信号中说话人特征和文本信息的解耦。该方法基于之前提出的xi-vector框架[6],并采用了循环(Recurrent)处理的方式,因此命名为RecXi。RecXi使用三层的Gaussian inference来分离语音中动态和静态的信息。这三层如上图蓝、黄、绿三色所示,依次解耦出的表征为:先导说话人特征表征(precursor speaker representation),基于解耦的文本内容表征(disentangled content representation)和基于解耦的说话人特征表征(disentangled speaker representation)。?特别的,为了增强对动态信息的建模能力,研究人员设计了一种根据文本内容可帧级动态调整的transition模型(Frame-wise Content-aware Transition Model,Gt)。另一方面,为了降低文本标签缺失对语音文本信息部分建模的影响,研究者提出了一种特别的自监督(self-supervision)学习方法来辅助解耦动态信息部分,其中使用的损失函数是通过对线性操作所保留的说话人表征的优化而达到的,命名为Self-supervised?Speaker-Preserving loss,Lssp)。更多技术细节欢迎阅读原文。为了简化实现和避免矩阵求逆操作导致的大量计算开销,在附录A中,作者提供了简化的实现方法和公式推导。
该项工作的实验验证在VoxCeleb[5]和SITW[7]数据集上进行。Table 1?中的实验结果验证了提出的解耦框架在说话人验证任务上的有效性,高效性与先进性。

通过可视化实验和消融实验,作者分析了三个Gaussian inference层中携带的信息的变化,并证实了解耦任务的完成。
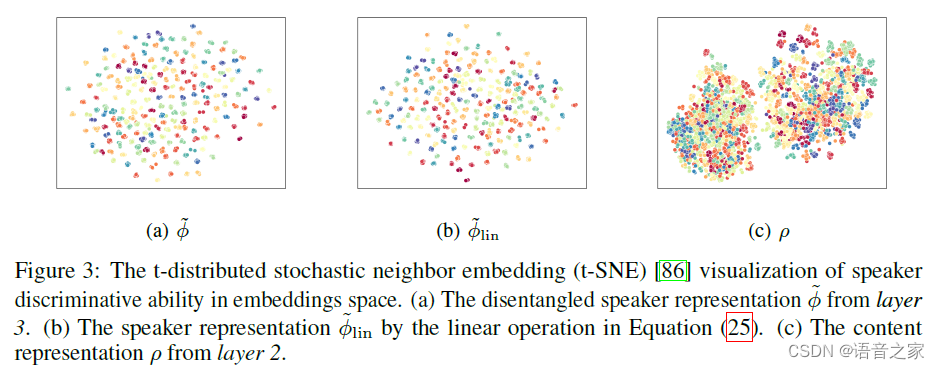

进一步的消融实验验证了提出的自监督方法Lssp对于文本标签缺失情况下训练的明显帮助:

另外,附录中增加的实验验证了该项工作中提出的Gt对于动态信息建模的有效性和必要性。
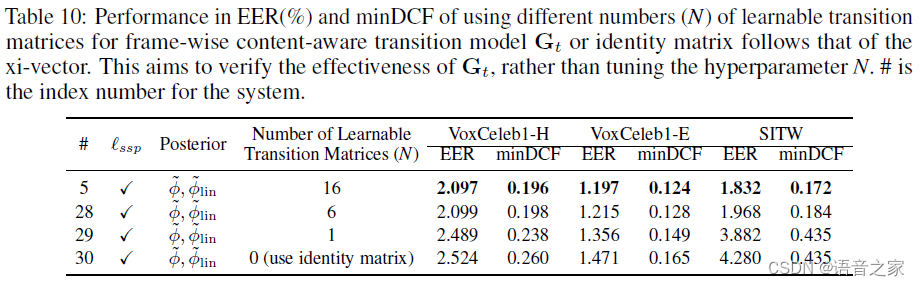
更多实验结果和详细的实验设定欢迎查阅原文。作者团队期待更多的交流,指导和未来的合作机会!
[1] Anthony Larcher, Kong Aik Lee, Bin Ma, and Haizhou Li. Text-dependent speaker verification:
Classifiers, databases and rsr2015. Speech Communication, 60:56–77, 2014.
[2] Tianyan Zhou, Yong Zhao, Jinyu Li, Yifan Gong, and Jian Wu. CNN with phonetic attention
for text-independent speaker verification. In Proc. IEEE ASRU, pages 718–725, 2019.
[3] Tianchi Liu, Rohan Kumar Das, Kong Aik Lee, and Haizhou Li. Neural acoustic-phonetic
approach for speaker verification with phonetic attention mask. IEEE Signal Processing
Letters, 29:782–786, 2022.
[4] Siqi Zheng, Yun Lei, and Hongbin Suo. Phonetically-aware coupled network for short duration
text-independent speaker verification. In Proc. Interspeech, pages 926–930, 2020.
[5] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. VoxCeleb2: Deep speaker recognition. In Proc. Interspeech, pages 1086–1090, 2018.
[6] Kong Aik Lee, Qiongqiong Wang, and Takafumi Koshinaka. Xi-vector embedding for speaker
recognition. IEEE Signal Processing Letters, 28:1385–1389, 2021.
[7] Mitchell McLaren, Luciana Ferrer, Diego Castan, and Aaron Lawson. The speakers in the
wild (SITW) speaker recognition database. In Proc. Interspeech, pages 818–822, 2016.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!