【分布式】分布式链路跟踪技术
为什么需要分布式链路追踪
提到分布式链路追踪,我们要先提到微服务。相信很多人都接触过微服务。微服务是一种开发软件的架构和组织方法,它侧重将服务解耦,服务之间通过API通信。使应用程序更易于扩展和更快地开发,从而加速新功能上线。
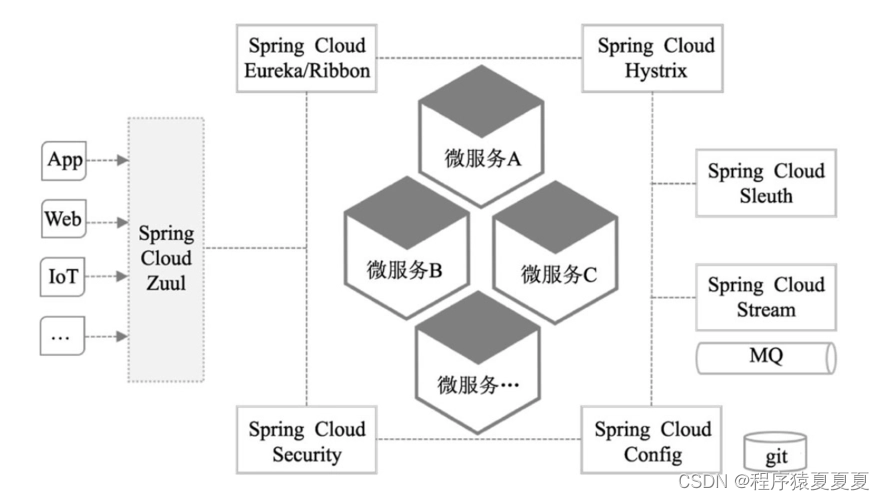
加速研发快速迭代,让微服务在业务驱动的互联网领域全面普及,独领风骚。但是,随之而来也产生了新问题:当生产系统面对高并发,或者解耦成大量微服务时,以前很容易就能实现的监控、预警、定位故障就变困难了。
接下来我们拿一笔支付的例子来举例
比如支付付款这样一个行为,其实是对多个服务器发起了一个请求,这个请求会被发送到多个微服务系统,通俗的讲,这些微服务系统分别用来查询用户信息,查询余额,请求支付等等。每个子系统的做完这一套操作后,会把对应结果展示给用户。
用户一次操作,做了这么一个“全局操作”。任何一个子系统变慢,都会导致最终的操作变得慢,那用户体验就会很差了。
看到这里,你可能会想,体验差我们做优化不就好了么?确实如此,但一般情况,一个前端或者后端工程师虽然知道系统查询耗时,但是他无从知晓这个问题到底是由哪个服务调用造成的,或者为什么这个调用性能差强人意。
这个工程师可能无法准确定位到这次全局搜索是调用了哪些服务,因为新的服务、乃至服务上的某个功能,都有可能在任何时间上过线或修改过。其次,你不能苛求这个工程师对所有参与这次全局搜索的服务都了如指掌,每一个服务都有可能是由不同的团队开发或维护的。再次,搜索服务还同时还被其他客户端使用,比如手机端,这次全局搜索的性能问题甚至有可能是由其他应用造成的。
什么是分布式链路追踪
对于上面的情况,我们迫切需要一些新工具,帮我们精准分析性能问题。于是,分布式系统下链路追踪技术(Distributed Tracing)出现了。
它的核心思想是:在用户一次请求服务的调?过程中,无论请求被分发到多少个子系统中,子系统又调用了更多的子系统,我们把系统信息和系统间调用关系都追踪记录下来。最终把数据集中起来可视化展示。它会形成一个有向图的链路,看起来像下面这样
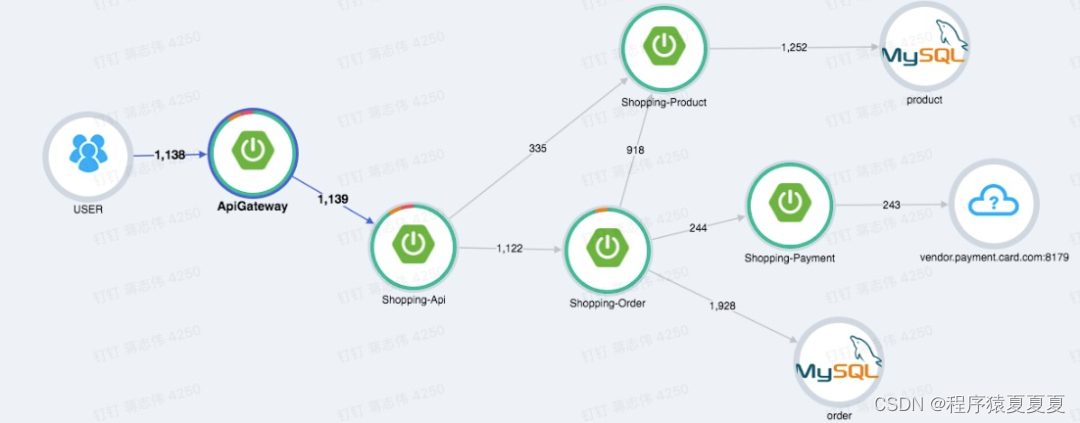
链路Trace的核心结构
应用的稳定性,以及出现问题的时候,怎样的快速定位到真正的原因。主要体现在怎样监控系统,怎样从日志上快速的找到错误,怎样快速的知道调用链是不是出现了问题,以及应用的运行时有没有出问题,应用依赖的数据库,中间件等是不是出现问题了。这也是大家经常听到的观测性的大三要素,监控,日志,链路。
我们如何将这个链路串联起来呢?
有两种方式:span(链式记录依赖)和RPCID(层级计数器)。我们在记录日志带上UUID的同时,也带上RPCID这个信息,帮我们把日志关联关系串联起来。
我们先看看span实现:
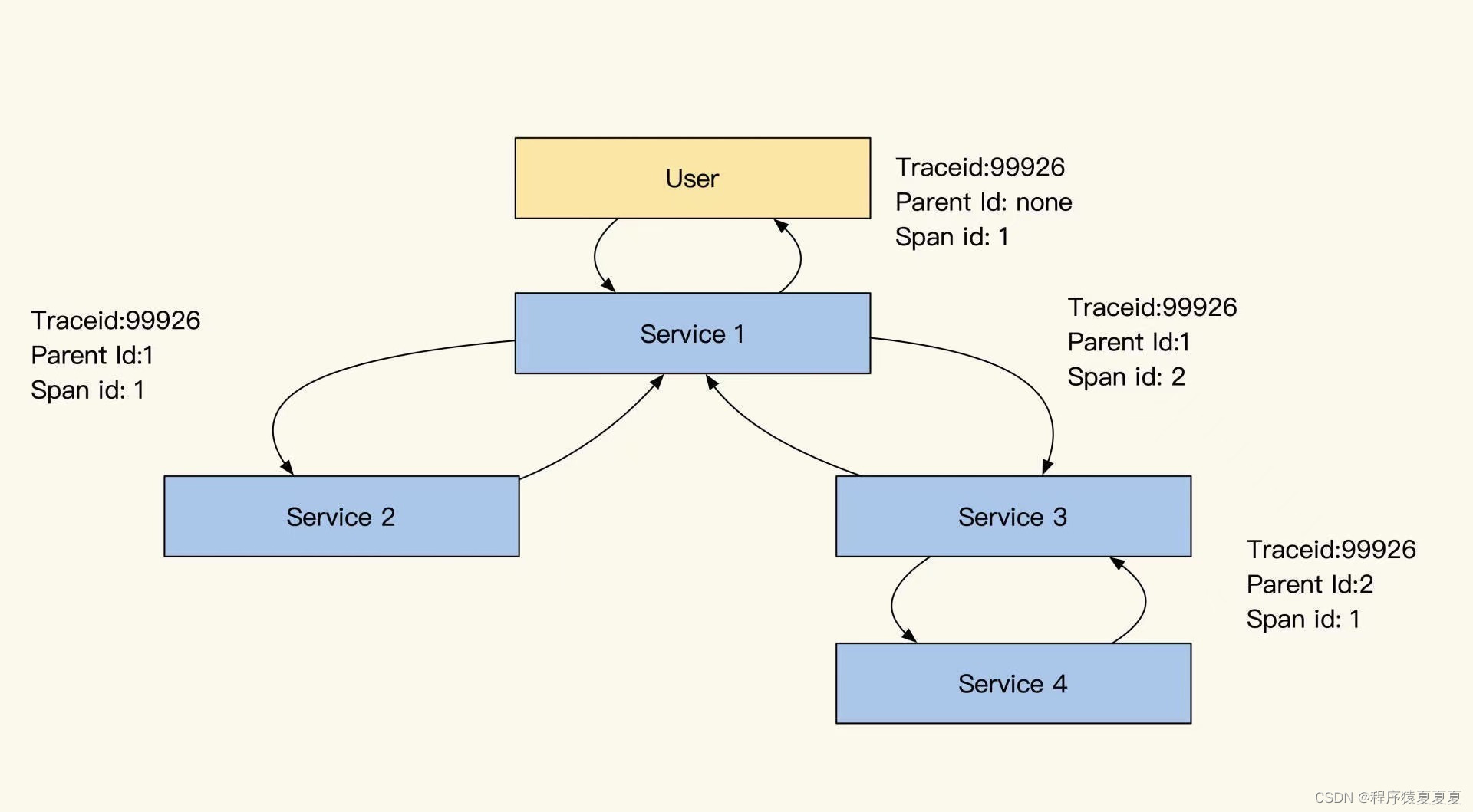
结合上图,我们分析一下span的链式依赖记录方式。对于代码来说,写的很多功能会被封装成功能模块(Service、Model),我们通过组合不同的模块实现业务功能,并且记录这两个模块、两个服务间或是资源的调用依赖关系。
span这个设计会通过记录自己上游依赖服务的SpanID实现上下游关系关联(放在Parent ID中),通过整理span之间的依赖关系就能组合成一个调用链路树。
那RPCID方式是什么样的呢?RPCID也叫层级计数器,为了方便理解,我们来看下面这张图:
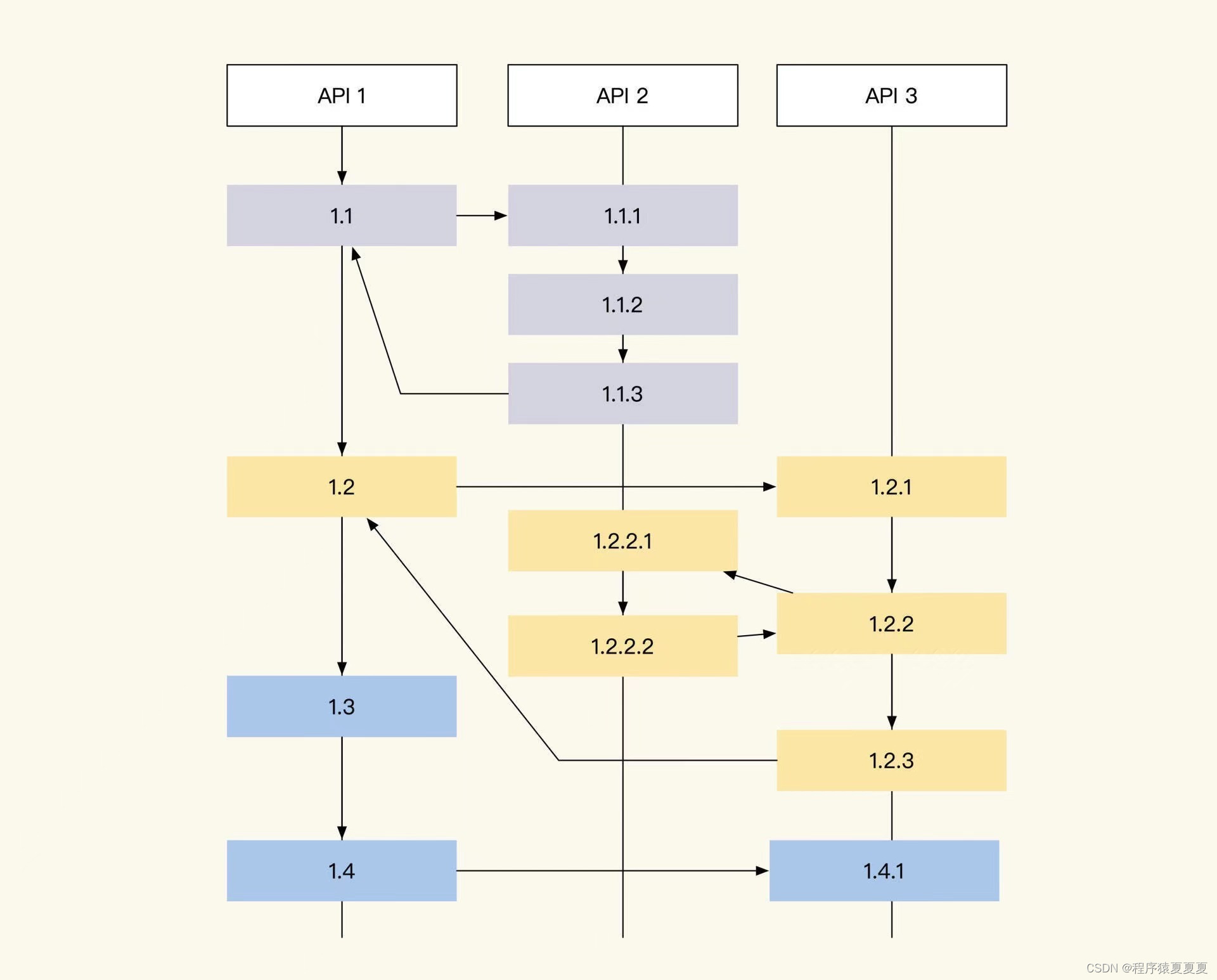
RPCID的层级计数器实现很简单,第一个接口生成RPCID为 1.1 ,RPCID的 前缀 是1, 计数器 是1(日志记录为 1.1)。
当所在接口请求其他接口或数据服务(MySQL、Redis、API、Kafka)时, 计数器 +1,并在请求当中带上1.2这个数值(因为当前的 前缀 + “.” + 计数器值 = 1.2),等到返回结果后,继续请求下一个资源时继续+1,期间产生的任何日志都会记录当前 前缀 +“.”+ 计数器值。
每一层收到了前缀后,都在后面加了一个累加的计数器,实际效果如下图所示:

而被请求的接口收到请求时,如果请求传递了TraceID,那么被请求的服务会继续使用传递过来的TraceID,如果请求没有TraceID则自己生成一个。同样地,如果传递了RPCID,那么被请求的服务会将传递来的RPCID当作前缀,计数器从1开始计数。
相对于span,通过这个层级计数器做出来的RPCID有两个优点。
1、第一个优点是我们可以记录请求方日志,如果被请求方没有记录日志,那么还可以通过请求方日志观测分析被调用方性能(MySQL、Redis)。
3、另一个优点是哪怕日志收集得不全,丢失了一些,我们还可以通过前缀有几个分隔符,判断出日志所在层级进行渲染。举个例子,假设我们不知道上图的1.5.1是谁调用的,但是根据它的UUID和层级1.5.1这些信息,渲染的时候,我们仍旧可以渲染它大概的链路位置。
我们前面提到,请求和被请求方通过传递TraceID和RPCID(或SpanID)来实现链路的跟踪,下面列举几个常见的方式:
1、HTTP协议放在Header;
2、RPC协议放在meta中传递;
3、队列可以放在消息体的Header中,或直接在消息体中传递;
4、其他特殊情况下可以通过网址请求参数传递
那么应用内多线程和多协程之间如何传递TraceID呢?一般来说,我们会通过复制一份Context传递进入线程或协程,并且如果它们之前是并行关系,我们复制之后需要对下发之前的RPCID计数器加1,并把前缀和计数器合并成新的前缀,以此区分并行的链路。
日志样式的定义
日志建议使用JSON格式,所有字段除了标注为string的都建议保存为字符串类型,每个字段必须是固定数据类型,选填内容如果没有内容就直接不输出。
这样设计其实是为了适配Elasticsearch+Kibana,Kibana提供了日志的聚合、检索、条件检索和数值聚合,但是对字段格式很敏感,不是数值类型就无法聚合对比。
日志实现方式
“侵入式埋点SDK”VS“AOP方式埋点”?
那么如果底层代码不能更新,如何简单暴力地实现链路跟踪呢?
这时候我们可以改造分级日志,让它每次在落地的时候都把TraceId和RPCID(或SpanID)带上,就会有很好的效果。如果数据底层做了良好的封装,我们可以在发起请求部分中写一些符合标准性能的日志,在框架的统一异常处理中也注入我们的标准跟踪,即可实现关键点的监控。
当然如果条件允许,我们最好提供一个标准的SDK,让业务研发伙伴按需调用,这能帮助我们统一日志结构。毕竟手写很容易格式错乱,需要人工梳理,不过即使混乱,也仍旧有规律可言,这是ELK架构的强大之处,它的全文检索功能其实不在乎你的输入格式,但是数据统计类却需要我们确保各个字段用途固定。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!