机器学习中的一些有趣点【Attack 和 Defence】
2023-12-23 21:04:53
什么是机器学习中的攻击
“攻击机器学习模型” 指的是试图危害或操纵机器学习模型的概念。有各种类型的攻击机器学习模型的方法,它们可以广泛分为几类:
- 对抗攻击:
- 定义: 对抗攻击涉及对输入数据进行微小的、通常是难以察觉的更改,目的是使机器学习模型对数据进行错误分类。
- 目标: 了解模型的脆弱性,并探索使其产生不正确预测的方法。
- 模型反演:
- 定义: 模型反演攻击试图通过观察其输出,反向工程或提取机器学习模型中的敏感信息。
- 目标:从模型中获取训练数据或模型结构的洞察,潜在地揭示机密信息。
- 规避攻击:
- 定义: 规避攻击的目的是通过操纵输入数据来规避机器学习模型的检测或分类。
- 目标: 通过精心制作输入样本,愚弄模型以产生不正确的预测。
- 数据污染:
- 定义: 数据污染攻击涉及向训练集注入恶意数据,以影响模型的行为。 目标:
- 在训练期间微妙地改变模型的学习参数,导致在未来真实数据上性能受损。
- 模型提取:
- 定义: 模型提取攻击旨在提取机器学习模型的内部详细信息或参数。 目标:
- 获取训练模型的副本,潜在地允许攻击者以恶意方式使用模型或深入了解专有算法。
攻击相对于防御来说是容易的。
攻击的类型
在训练的时候是调整Network的参数,而在攻击的时候是调整x‘使预测的结果越错越好。且这张图片和原图片(可以被正确分类的图片)十分相似
- 没有目标的攻击类型
- 找到一张图片可以被识别错误,
- 有特定目标的攻击类型
- 找到一张图片可以被识别为指定的类型
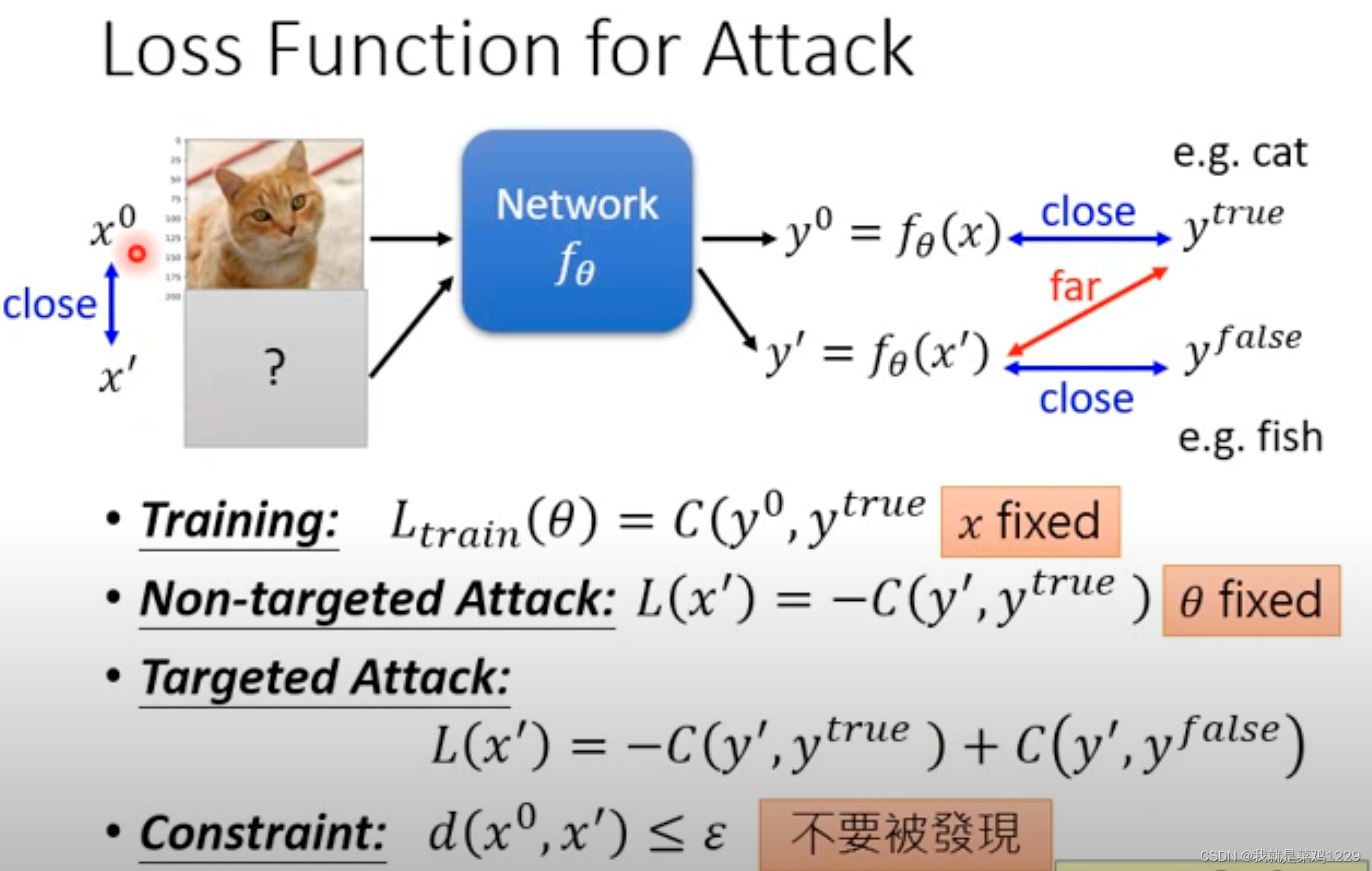
常用的Constraint公式

- 找到一张图片可以被识别为指定的类型
文章来源:https://blog.csdn.net/qq_45467608/article/details/135173177
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!