Python武器库开发-武器库篇之子域名扫描器开发(四十一)
2024-01-07 17:42:33
Python武器库开发-武器库篇之子域名扫描器开发(四十一)
在我们做红队攻防或者渗透测试的过程中,信息收集往往都是第一步的,有人说:渗透的本质就是信息收集,前期好的信息收集很大程度上决定了渗透的质量和攻击面,本文将教会大家如何开发一个子域名扫描器进行主动信息收集。
对于一个网站的URL,列如:https://www.baidu.com一般有以下几个部分组成:
- 协议
- 子域
- 域名
- 顶级域名
如果我们要对一个子域名进行爆破,那么我们就需要修改子域这一个部分,然后去观察返回的响应包,我们都知道状态码 200 代表成功,所以我们在子域名进行爆破的过程中去判断返回包的状态码是不是200就能判断出当前爆破的这个域名是否存在。现在我们开发子域名扫描器的核心思想已经非常清楚了。当然说道爆破肯定就离不开字典了,所以大家也请自己去准备一个适合子域名爆破的字典。
首先我们来做一个初版的子域名扫描器,内容代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#引用库
import requests
def domain_scan(domain_name,sub_names):
#循环读取子域名字典
for sub in sub_names:
#添加请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
}
url = f"https://{sub}.{domain_name}"
try:
requests.head = headers
requests.get(url)
#输出爆破成功的子域名
print(f"successful! [*]{url}")
except requests.ConnectionError:
print("error")
pass
if __name__ == '__main__':
#获取要爆破的域名
dom_name = input("enter the domain name:")
with open("subdomain.txt") as file:
#读取字典文件
sub_name = file.read()
#区分换行
sub_dom = sub_name.splitlines()
print("文件中存在的子域名数量:{}".format(len(sub_dom)))
print("文件子域名列表:{}".format(sub_dom))
domain_scan(dom_name,sub_dom)
代码运行的实际效果图如下:
首先我们去输入我们想要爆破的域名,比如baidu.com
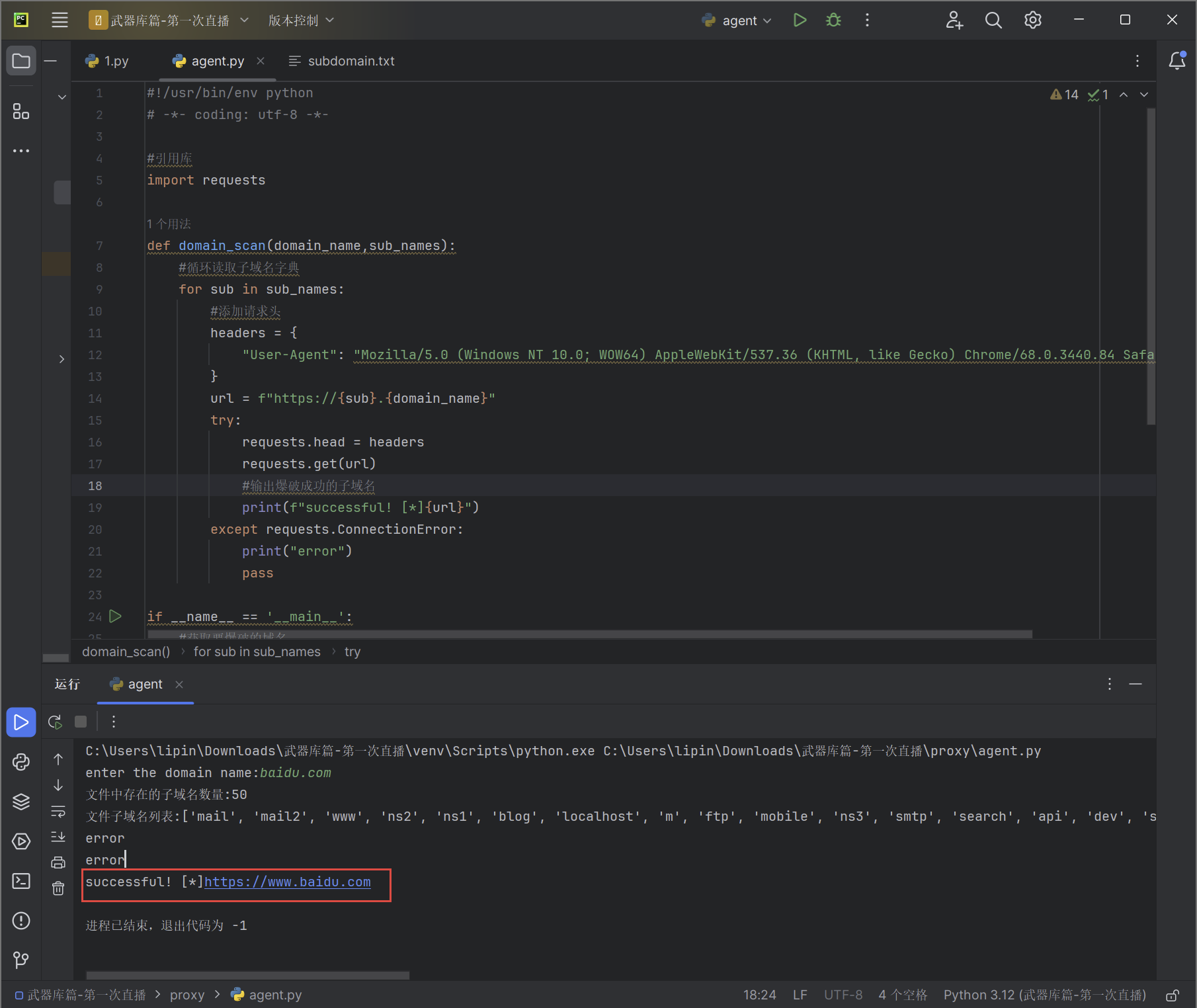
然后他将从字典中选出爆破成功的子域名并打印输出出来,没有的则输出 error
当然在实际的渗透过程中,我们都需要添加代理池去做到隐蔽自己的目的,所以接下来开发一个添加了代理池的子域名扫描器版本,代码内容如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#引用库
import requests
# 添加你的代理池的隧道域名:端口号
tunnel = "xxx.com:xxxx"
# 修改你的用户名和密码
username = "username"
password = "password"
proxies = {
"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel},
"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}
}
def domain_scan(domain_name,sub_names):
#循环读取子域名字典
for sub in sub_names:
#添加请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
}
url = f"https://{sub}.{domain_name}"
try:
requests.head = headers
requests.get(url,proxies=proxies)
#输出爆破成功的子域名
print(f"successful! [*]{url}")
except requests.ConnectionError:
print("error")
pass
if __name__ == '__main__':
#获取要爆破的域名
dom_name = input("enter the domain name:")
with open("subdomain.txt") as file:
#读取字典文件
sub_name = file.read()
#区分换行
sub_dom = sub_name.splitlines()
print("文件中存在的子域名数量:{}".format(len(sub_dom)))
print("文件子域名列表:{}".format(sub_dom))
domain_scan(dom_name,sub_dom)
这串代码中只需要你配置上自己的代理池的IP和端口,还有账户的用户名和密码,就可以启用代理池配置去扫描子域名了。代码效果图如下:
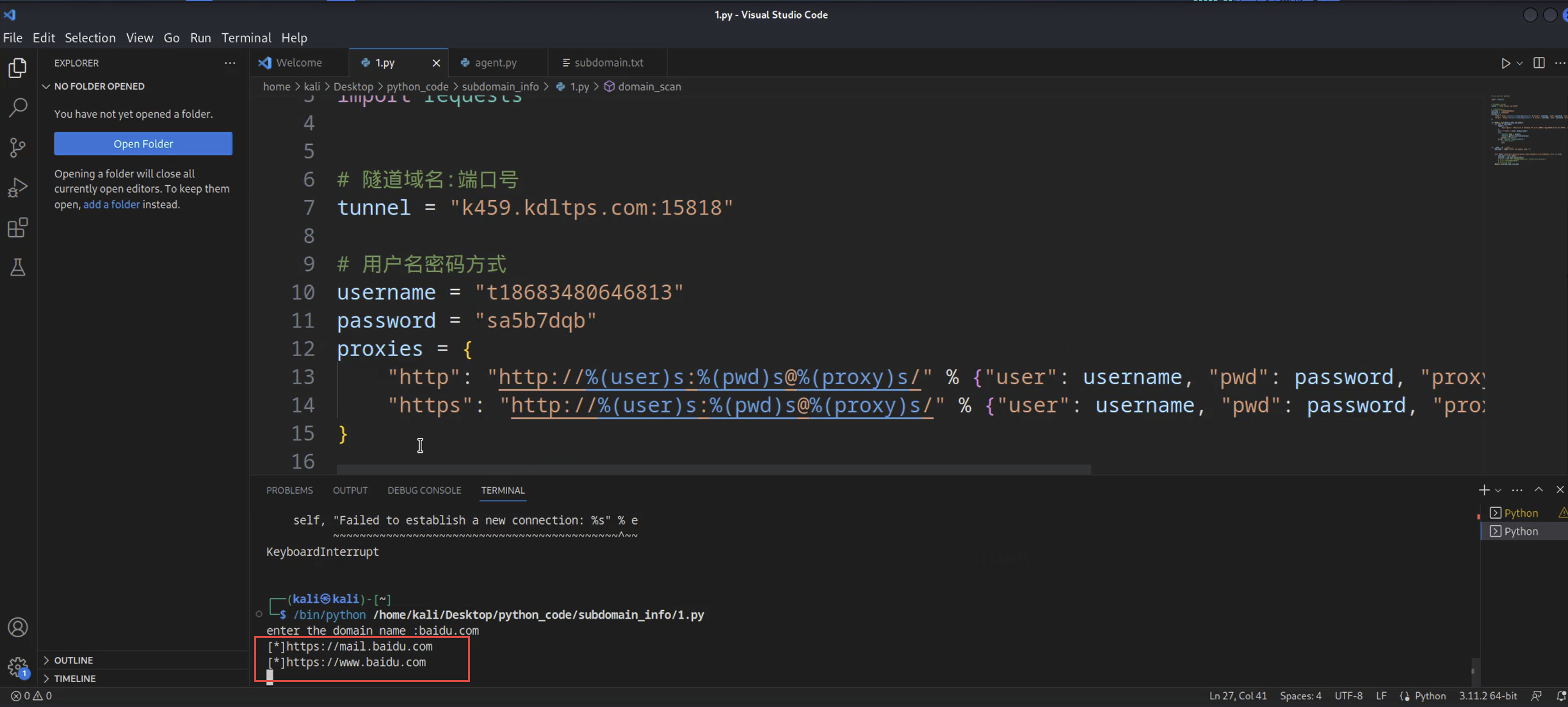
如果想要加快爆破的速度的话,那么也可以添加多线程进行同时爆破,这里就不多演示了。
文章来源:https://blog.csdn.net/qq_64973687/article/details/135421664
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!