C++数据结构-栈
栈
栈是允许在表的一端进行插入和删除的线性表。表中允许插入删除的一端是栈顶,栈顶的当前位置是动态变化的;不允许插入和删除的一端是栈底,栈底的位置是不变的。当表中没有元素时称为空栈,插入数据的运算称为进栈、压栈、入栈,删除数据的运算称为出栈或退栈。
进/出栈示意图:
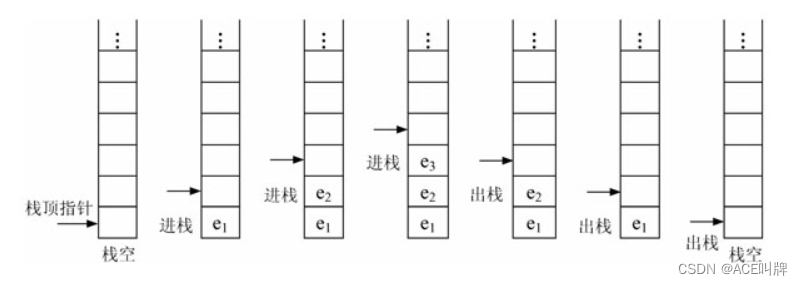 进栈的顺序是e1、e2、e3,出栈的顺序为e3、e2、e1,所以栈又称为后进先出线性表(Last In First Out),简称LIFO表,或称先进后出线性表。其特点是先进后出或者后进先出。
进栈的顺序是e1、e2、e3,出栈的顺序为e3、e2、e1,所以栈又称为后进先出线性表(Last In First Out),简称LIFO表,或称先进后出线性表。其特点是先进后出或者后进先出。
顺序栈
栈的存储与一般的线性表的存储类似,主要有两种存储方式:顺序存储和链式存储。
利用顺序存储方式实现的栈称为顺序栈。类似于顺序表的定义,要分配一块连续的存储空间存放栈中的元素,栈底位置可以固定地设置在数组的任何一端(一般在下标为0的一端),而栈顶是随着插入和删除而变化的,再用一个变量指明当前栈顶的位置(实际上是栈顶元素的下一个位置)。
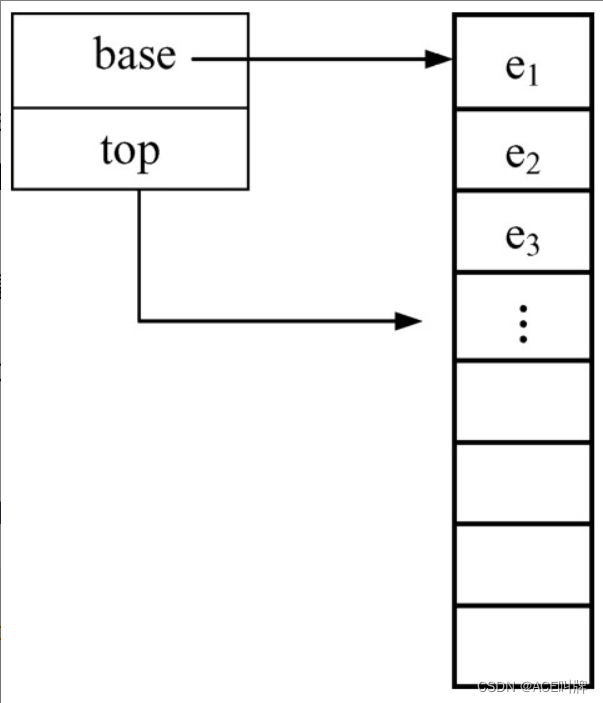 顺序栈的类描述如下:
顺序栈的类描述如下:
// 学生表
struct Student
{
int id_; // 学生id
std::string name_; // 学生姓名
int score_; // 学生成绩
Student(int _id, std::string _name, int _score)
: id_(_id), score_(_score), name_(_name)
{}
Student()
: id_(0), score_(0)
{}
};
class Stack
{
public:
Stack(int _stackSize = 100);
~Stack();
bool IsEmptyStack(); // 判断栈是否为空
bool PushStack(Student &_stu); // 入栈
bool PopStack(Student &_stu); // 出栈
bool GetTop(Student& _stu); // 取栈顶元素
private:
Student* base_; // 栈底指针
Student* top_; // 栈顶指针
int size_; // 栈的大小
};
(1)判断栈是否为空
算法思想:判断top_是否小于等于base_,如果小于等于说明是空栈,返回true,否则返回false。
bool Stack::IsEmptyStack()
{
if (top_ <= base_)
return true;
return false;
}
(2)入栈操作
算法描述:入栈操作是在栈的顶部进行插入操作,相当于在顺序表的表尾进行插入,因而无须移动元素。
算法思想:首先判断栈是否已满,若满则失败,返回0;否则,由于栈的top 指向栈顶元素的后一个位置,将入栈元素赋到top的位置,再将top+1指向新的位置,成功返回1。
bool Stack::PushStack(Student& _stu)
{
if (top_ - base_ < size_)
{
*top_ = _stu;
top_++;
return true;
}
return false;
}
(3)出栈操作
算法描述:出栈操作是在栈的顶部进行,相当于是删除顺序表的最后一个元素,所以也不需要移动元素。
算法思想:首先判断栈是否为空,若空则失败,返回false;否则,由于栈的top 指向栈顶元素的后一位置,要先修改top为top-1,再将其所指向的元素以引用参数_stu返回,成功返回true。
bool Stack::PopStack(Student& _stu)
{
if (top_ > base_)
{
top_--;
_stu = *top_;
return true;
}
return false;
}
(4)取栈顶元素
算法描述:取栈顶元素是获取出栈顶元素的值,而不改变栈。
算法思想:首先判断栈是否为空,若空则失败,返回0;否则,由于栈的top 指向栈顶元素的后一位置,返回top-1所指单元的值,栈不发生变化。
bool Stack::GetTop(Student& _stu)
{
if (top_ <= base_)
return false;
_stu = *(top_ - 1);
return true;
}
链栈
栈也可以用链式存储方式实现。一般链栈用单链表表示,其结点结构与单链表的结构相同,即结点为:
// 学生表
struct Student
{
int id_; // 学生id
std::string name_; // 学生姓名
int score_; // 学生成绩
Student(int _id, std::string _name, int _score)
: id_(_id), score_(_score), name_(_name)
{}
Student()
: id_(0), score_(0)
{}
};
//定义链栈的结点
class StackNode
{
public:
Student data;
StackNode* next;
StackNode()
{
next = NULL;
};
};
因为栈中的主要运算是在栈顶进行插入和删除操作,显然在单链表的表头插入和删除都比较方便,因此以其作为栈顶,而且没有必要像单链表那样为了运算方便而附加一个头结点,存储结构如图:
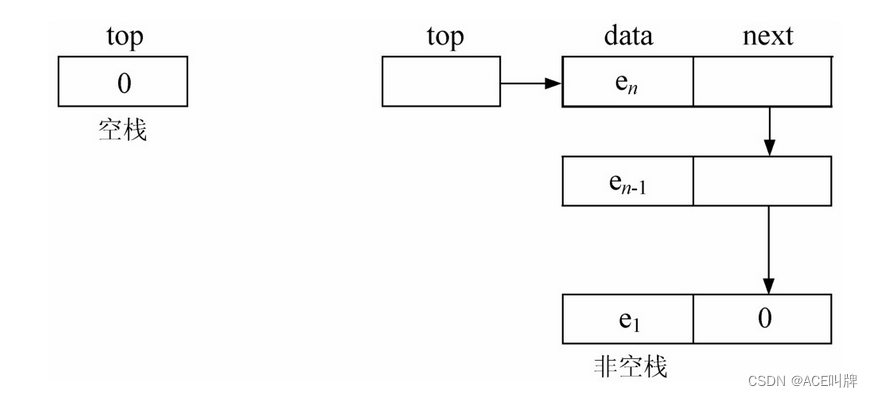 思考:为什么不用单链表的表尾作为栈顶?
思考:为什么不用单链表的表尾作为栈顶?
因为用表尾作为栈顶,那么每次进行入栈、出栈、取栈顶元素的操作都需要遍历一遍单链表找到表尾,或者声明尾指针指向表尾,但是这样做太复杂,没有必要。
// 链栈
class LinkStack
{
public:
LinkStack();
~LinkStack();
bool Empty_Stack(); //判断栈是否为空
bool Push_Stack(Student e); //将元素e插入栈顶
bool Pop_Stack(Student& e); //从栈顶删除一个元素到e中返回
bool GetTop_Stack(Student& e); //从栈顶取出一个元素到e中返回
private:
StackNode* top_;
};
(1)判断链栈是否为空
bool LinkStack::Empty_Stack()
{
return (top_ == nullptr);
}
(2)入栈操作
入栈操作相当于是在表头插入一个元素
bool LinkStack::Push_Stack(Student e)
{
StackNode* p = new StackNode;
p->data = e;
p->next = top_;
top_ = p;
return true;
}
(3)出栈操作
出栈操作相当于删除表头
bool LinkStack::Pop_Stack(Student& e)
{
if (top_)
{
StackNode* p = top_;
e = p->data;
top_ = p->next;
delete p;
p = nullptr;
return true;
}
return false;
}
(4)取栈顶元素
bool LinkStack::GetTop_Stack(Student& e)
{
if (top_)
{
e = top_->data;
return true;
}
return false;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!