模型评估系列:回归模型的评估指标介绍和代码实践
# 导入所需的库
from matplotlib import pyplot as plt # 导入matplotlib库中的pyplot模块,用于绘制图形
import seaborn as sns # 导入seaborn库,用于数据可视化
from IPython.display import Image # 导入IPython库中的display模块中的Image类,用于显示图像
1. 简介
性能指标对于监督式机器学习模型至关重要。为了确保您的模型在预测方面表现良好,您需要评估模型。我们的目标是确定模型在新数据上的表现如何。有一些评估指标可以帮助您确定模型的预测是否准确到一定的性能水平。
2. 回归评估指标
所有这些都是损失函数,因为我们希望将它们最小化。
2.1 平均绝对误差(MAE)
是误差绝对值的均值:
1 n ∑ i = 1 n ∣ y i ? y ^ i ∣ \frac 1n\sum_{i=1}^n|y_i-\hat{y}_i| n1?i=1∑n?∣yi??y^?i?∣
平均绝对误差表示数据集中实际值和预测值之间绝对差异的平均值。它衡量了数据集中残差的平均值。
2.2 均方误差(MSE)
是误差平方的均值:
1 n ∑ i = 1 n ( y i ? y ^ i ) 2 \frac 1n\sum_{i=1}^n(y_i-\hat{y}_i)^2 n1?i=1∑n?(yi??y^?i?)2
均方误差表示数据集中原始值和预测值之间平方差异的平均值。它衡量了残差的方差。
2.3 均方根误差(RMSE)
是误差平方的均值的平方根:
1 n ∑ i = 1 n ( y i ? y ^ i ) 2 \sqrt{\frac 1n\sum_{i=1}^n(y_i-\hat{y}_i)^2} n1?i=1∑n?(yi??y^?i?)2?
RMSE衡量了残差的标准差。
2.4 R平方(决定系数)
R平方是一个用于衡量回归模型拟合程度的统计量。它表示因变量的变异中可以被自变量解释的比例。R平方的取值范围在0到1之间,越接近1表示模型拟合程度越好。
R平方的计算公式为:
R 2 = 1 ? S S r e s S S t o t R^2 = 1 - \frac{SS_{res}}{SS_{tot}} R2=1?SStot?SSres??
其中, S S r e s SS_{res} SSres?表示残差平方和, S S t o t SS_{tot} SStot?表示总平方和。
R平方的值越高,说明模型对数据的解释能力越强。但是,R平方并不能说明模型是否具有预测能力,因为它只是衡量模型对数据的拟合程度,而不是对新数据的预测能力。因此,在使用R平方时,需要结合其他指标来评估模型的预测能力。
任务:请翻译以下markdown为中文,请保留markdown的格式,并输出翻译结果。
语料:
- SST (or TSS)
总平方和(SST或TSS)是观测到的因变量与其均值之间的平方差。
- SSR (or RSS)
回归平方和(SSR或RSS)是预测值与因变量均值之间的差异之和。
- SSE (or ESS)
误差平方和(SSE或ESS)是观测值与预测值之间的差异。
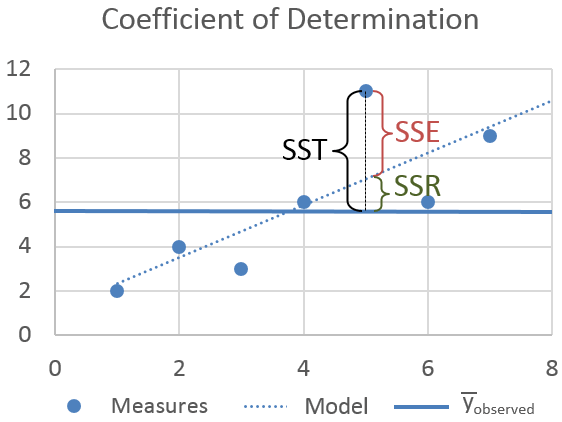
决定系数或R平方表示因变量中由线性回归模型解释的方差比例。当R2较高时,表示回归可以捕捉到观察到的因变量的大部分变异。因此,当R2较高时,我们可以说回归模型表现良好。
R 2 = 1 ? S S R S S T R^2 = 1- \frac {SSR}{SST} R2=1?SSTSSR?
它是一个无量纲的分数,即无论值是小还是大,R平方的值都小于1。关于回归分析的一个误解是,低R平方值总是一件坏事。例如,某些数据集或研究领域本质上具有更多的未解释变异。在这种情况下,R平方值自然会较低。即使R平方值较低,研究人员仍可以对数据做出有用的结论。
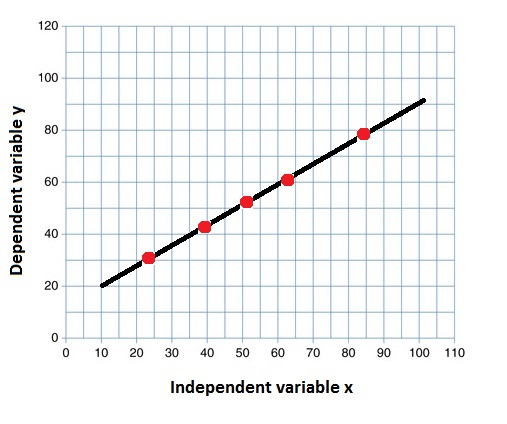
R 2 = 1 R^2=1 R2=1 所有y值的变化都可以由x值解释。
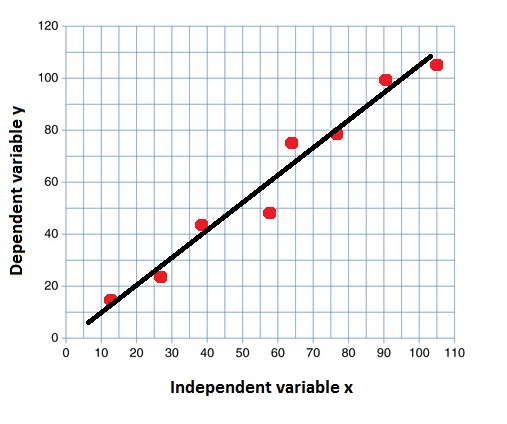
语料:
R
2
=
0.83
R^2=0.83
R2=0.83
83%的y值的变化可以由x值解释。
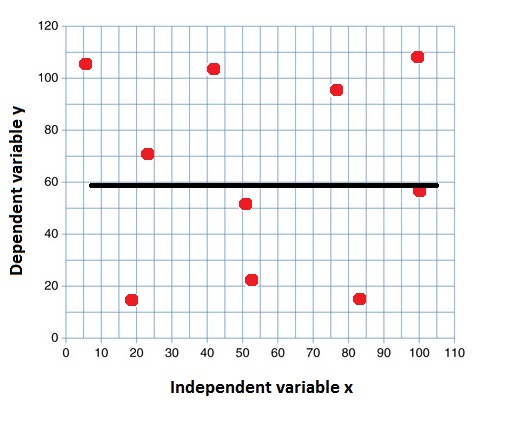
R 2 = 0 R^2=0 R2=0 表示y值的变化没有被x值解释。
2.5 调整后的R平方
R a d j . 2 = 1 ? ( 1 ? R 2 ) ? n ? 1 n ? p ? 1 R^2_{adj.} = 1 - (1-R^2)*\frac{n-1}{n-p-1} Radj.2?=1?(1?R2)?n?p?1n?1?
调整后的R平方是R平方的修改版本,它根据模型中的独立变量的数量进行了调整,并且它始终小于或等于R2。在下面的公式中,n是数据中的观测数量,k是数据中的独立变量数量。
2.6 交叉验证的R2
交叉验证是一种用于在有限数据样本上评估机器学习模型的重采样过程。它是一种流行的方法,因为它简单易懂,并且通常会得出比其他方法(如简单的训练/测试分割)更少偏差或更少乐观的模型技能估计。
该过程有一个称为k的单一参数,它指的是给定数据样本要被分成的组数。因此,该过程通常被称为k折交叉验证。当选择一个特定的k值时,可以将其用于模型的引用中,例如k=10变成10折交叉验证。
交叉验证的R2是从交叉验证过程中取得的中位数值或R2。

2.7 回归评估指标 - 结论
RMSE和R-Squared都用于衡量线性回归模型对数据集的拟合程度。在评估模型对数据集的拟合程度时,计算RMSE和R2值是有用的,因为每个指标都告诉我们不同的信息。
-
RMSE告诉我们回归模型预测值与实际值之间的典型距离。
-
R2告诉我们预测变量能够解释响应变量的变异程度。
向回归模型添加更多的自变量或预测变量往往会增加R2值,这诱使模型的制作者添加更多的变量。调整后的R2用于确定相关性的可靠性以及它受到自变量添加的影响程度。它始终低于R2。
3 设置
3.1 导入库
# 导入必要的库
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from collections import Counter
3.2 定义回归指标的函数
# 定义一个函数,用于评估回归模型的性能指标
def Reg_Models_Evaluation_Metrics(model, X_train, y_train, X_test, y_test, y_pred):
# 使用交叉验证计算模型的得分
cv_score = cross_val_score(estimator=model, X=X_train, y=y_train, cv=10)
# 计算调整后的R-squared
r2 = model.score(X_test, y_test)
# 观测值的数量是沿着轴0的形状
n = X_test.shape[0]
# 特征的数量(预测变量的数量,p)是沿着轴1的形状
p = X_test.shape[1]
# 调整后的R-squared公式
adjusted_r2 = 1 - (1 - r2) * (n - 1) / (n - p - 1)
# 计算均方根误差(RMSE)
RMSE = np.sqrt(metrics.mean_squared_error(y_test, y_pred))
# 计算R-squared
R2 = model.score(X_test, y_test)
# 计算交叉验证的R-squared
CV_R2 = cv_score.mean()
# 返回R-squared、调整后的R-squared、交叉验证的R-squared和均方根误差(RMSE)
return R2, adjusted_r2, CV_R2, RMSE
# 计算并打印均方根误差(RMSE)、R-squared和调整后的R-squared
print('RMSE:', round(RMSE, 4))
print('R2:', round(R2, 4))
print('Adjusted R2:', round(adjusted_r2, 4))
print("Cross Validated R2: ", round(cv_score.mean(), 4))
3.3 数据集特征
鳄梨价格
https://www.kaggle.com/datasets/neuromusic/avocado-prices
数据集中的一些相关列:
-
Date - 观察日期
-
AveragePrice - 单个鳄梨的平均价格
-
type - 常规或有机
-
year - 年份
-
Region - 观察的城市或地区
-
Total Volume - 销售的鳄梨总数
-
4046 - 销售的PLU 4046编号鳄梨总数
-
4225 - 销售的PLU 4225编号鳄梨总数
-
4770 - 销售的PLU 4770编号鳄梨总数
缺失值:无
重复条目:无
波士顿房价
https://www.kaggle.com/datasets/vikrishnan/boston-house-prices
数据库中的每个记录描述了波士顿的一个郊区或城镇。数据来自1970年的波士顿标准都会统计区(SMSA)。属性定义如下(来自UCI机器学习库):CRIM:每个城镇的人均犯罪率
- CRIM 每个城镇的人均犯罪率
- ZN 用于超过25,000平方英尺的住宅用地比例
- INDUS 每个城镇的非零售业务面积比例
- CHAS 查尔斯河虚拟变量(= 1如果地块与河流相邻;否则为0)
- NOX 一氧化氮浓度(每千万分之一)
- RM 每个住宅的平均房间数
- AGE 1940年之前建造的自住单位比例
- DIS 到波士顿五个就业中心的加权距离
- RAD 到径向高速公路的可达性指数
- TAX 每10,000美元的全额财产税率
- PTRATIO 每个城镇的师生比例
- B 1000(Bk - 0.63)^2,其中Bk是每个城镇的黑人比例
- LSTAT 人口的较低地位百分比
- MEDV 自住房屋的中位数价值(以千美元为单位)
缺失值:无
重复条目:无
这是UCI ML房屋数据集的副本。
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
3.4 导入数据
# 读取数据
# 尝试从指定路径读取avocado.csv文件,并将结果赋值给raw_df1变量
# 尝试从指定路径读取housing.csv文件,使用header=None表示文件没有列名,使用delimiter=r"\s+"表示使用空格作为分隔符,使用names=column_names表示指定列名,将结果赋值给raw_df2变量
# 如果尝试失败,则从当前路径读取avocado.csv文件,并将结果赋值给raw_df1变量
# 如果尝试失败,则从当前路径读取housing.csv文件,使用header=None表示文件没有列名,使用delimiter=r"\s+"表示使用空格作为分隔符,使用names=column_names表示指定列名,将结果赋值给raw_df2变量
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
try:
raw_df1 = pd.read_csv('../input/avocado-prices/avocado.csv')
raw_df2 = pd.read_csv('../input/boston-house-prices/housing.csv', header = None, delimiter = r"\s+", names = column_names)
except:
raw_df1 = pd.read_csv('avocado.csv')
raw_df2 = pd.read_csv('housing.csv', header = None, delimiter = r"\s+", names = column_names)
# 删除列
raw_df1 = raw_df1.drop('Unnamed: 0', axis = 1)
# 定义一个列表,包含数值型的列名
numeric_columns = ['AveragePrice', 'Total Volume','4046', '4225', '4770', 'Total Bags', 'Small Bags', 'Large Bags', 'XLarge Bags']
# 定义一个列表,包含分类型的列名
categorical_columns = ['Region', 'Type']
# 定义一个列表,包含时间型的列名
time_columns = ['Data', 'Year']
# 定义一个列表,包含波士顿房价数据集中的数值型的列名
numeric_columns_boston = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
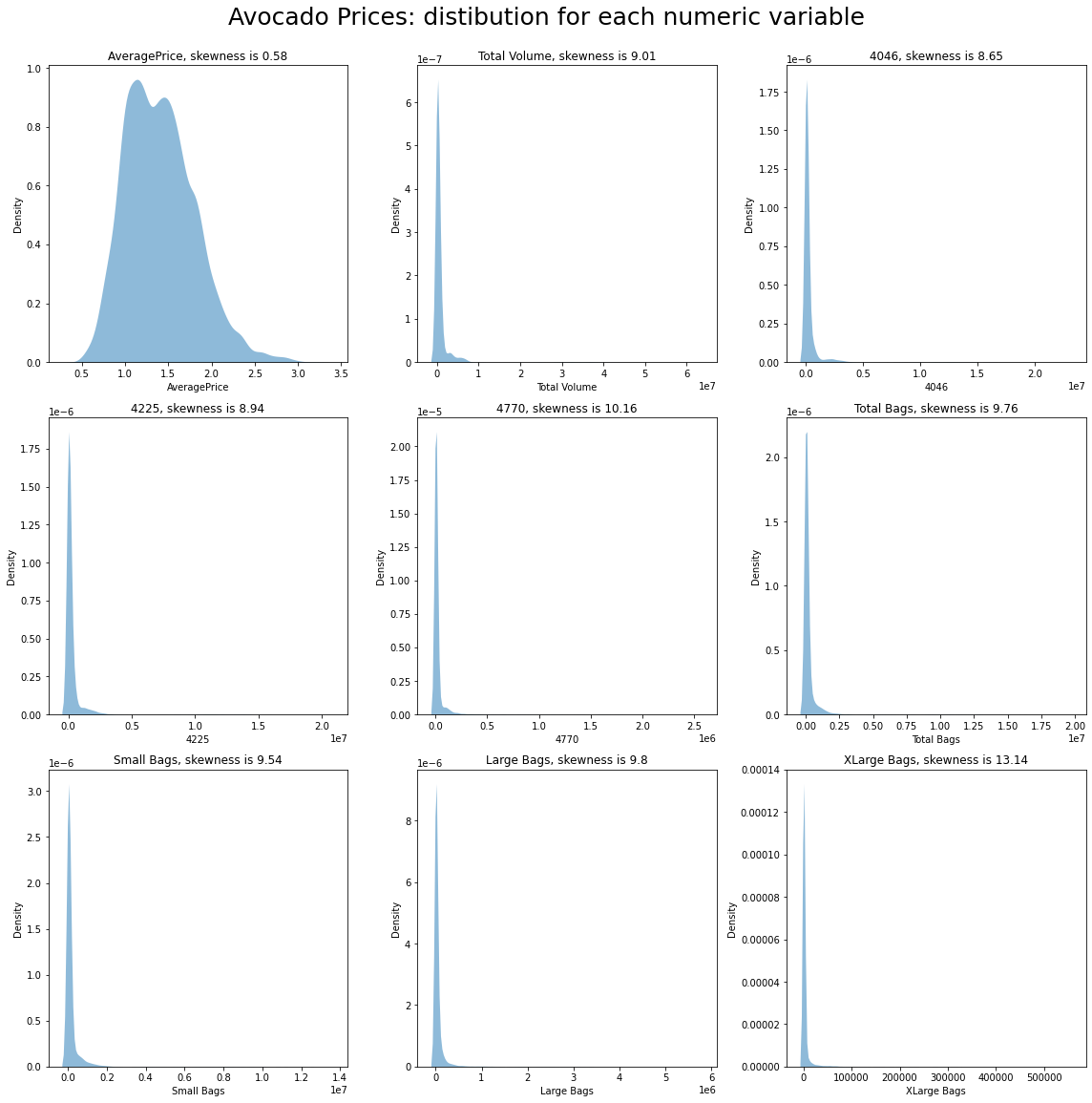
4. 一些可视化
4.1 鳄梨价格
# 定义一个函数用于绘制数据集中各个变量的分布图
def dist_custom(dataset, columns_list, rows, cols, suptitle):
# 创建一个包含多个子图的图像,并设置图像大小为16x16
fig, axs = plt.subplots(rows, cols, figsize=(16, 16))
# 设置图像的总标题和字体大小
fig.suptitle(suptitle, y=1, size=25)
# 将子图展平为一维数组
axs = axs.flatten()
# 遍历列名列表和索引
for i, data in enumerate(columns_list):
# 绘制核密度估计图,并填充颜色,透明度为0.5,线宽为0
sns.kdeplot(dataset[data], ax=axs[i], fill=True, alpha=.5, linewidth=0)
# 设置子图的标题,包括变量名和偏度值
axs[i].set_title(data + ', skewness is ' + str(round(dataset[data].skew(axis=0, skipna=True), 2)))
# 调用函数绘制数据集raw_df1中numeric_columns列表中的变量的分布图
dist_custom(dataset=raw_df1, columns_list=numeric_columns, rows=3, cols=3, suptitle='Avocado Prices: distibution for each numeric variable')
# 调整子图的布局
plt.tight_layout()
4.2 波士顿房价
# 调用dist_custom函数,绘制Boston House Prices数据集中每个数值变量的分布图
dist_custom(dataset=raw_df2, columns_list=numeric_columns_boston, rows=4, cols=3, suptitle='Boston House Prices: distibution for each numeric variable')
# 调整子图之间的间距,使得图形更加紧凑
plt.tight_layout()

5. 数据预处理
5.1 一些转换
在数据处理过程中,我们经常需要对数据进行一些转换。这些转换可以帮助我们清洗数据、提取特征、处理缺失值等。
以下是一些常见的数据转换方法:
- 映射(Mapping):将一个值映射到另一个值。例如,将性别从"male"和"female"映射为0和1。
- 替换(Replacing):用一个值替换另一个值。例如,将缺失值替换为平均值或中位数。
- 过滤(Filtering):根据某些条件过滤数据。例如,只保留年龄大于18岁的数据。
- 排序(Sorting):按照某个特定的顺序对数据进行排序。例如,按照年龄从小到大排序。
- 分组(Grouping):根据某个特征将数据分组。例如,根据地区将数据分组。
- 聚合(Aggregating):将多个值合并为一个值。例如,计算某个特征的平均值或总和。
这些转换方法可以通过使用各种编程语言和工具来实现。在数据处理过程中,选择适当的转换方法非常重要,因为它们可以影响最终的分析结果。
# 对数据类型进行更改
# 遍历raw_df1的每一列
for i in raw_df1.columns:
# 如果列名为'Date'
if i == 'Date':
# 将'Date'列的数据类型更改为datetime64[ns]
raw_df1[i] = raw_df1[i].astype('datetime64[ns]')
# 如果列的数据类型为'object'
elif raw_df1[i].dtype == 'object':
# 将该列的数据类型更改为category
raw_df1[i] = raw_df1[i].astype('category')
# 复制原始数据框df1
df1 = raw_df1.copy()
# 将'Date'列转换为日期格式
df1['Date'] = pd.to_datetime(df1['Date'])
# 提取月份信息并添加为新的列'month'
df1['month'] = df1['Date'].dt.month
# 判断月份是否在3到5之间(包括3和5),并将结果添加为新的列'Spring'
df1['Spring'] = df1['month'].between(3,5,inclusive='both')
# 判断月份是否在6到8之间(包括6和8),并将结果添加为新的列'Summer'
df1['Summer'] = df1['month'].between(6,8,inclusive='both')
# 判断月份是否在9到11之间(包括9和11),并将结果添加为新的列'Fall'
df1['Fall'] = df1['month'].between(9,11,inclusive='both')
# 将'Spring'列中的True替换为1,False替换为0
df1.Spring = df1.Spring.replace({True: 1, False: 0})
# 将'Summer'列中的True替换为1,False替换为0
df1.Summer = df1.Summer.replace({True: 1, False: 0})
# 将'Fall'列中的True替换为1,False替换为0
df1.Fall = df1.Fall.replace({True: 1, False: 0})
# 编码 'type' 标签
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder() # 创建一个LabelEncoder对象
df1['type'] = le.fit_transform(df1['type']) # 使用LabelEncoder对象对'type'列进行编码
# 编码 'region' (独热编码)
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='first', handle_unknown='ignore') # 创建一个OneHotEncoder对象,设置参数drop='first'表示删除第一个编码列,handle_unknown='ignore'表示忽略未知的编码值
ohe = pd.get_dummies(data=df1, columns=['region']) # 使用pd.get_dummies函数对'df1'数据框中的'region'列进行独热编码
df1 = ohe.drop(['Date','4046','4225','4770','Small Bags','Large Bags','XLarge Bags'], axis=1) # 从独热编码后的数据框中删除'Date','4046','4225','4770','Small Bags','Large Bags','XLarge Bags'列,得到最终的数据框df1
5.2 异常值检测和处理
我们在两个数据集中都存在显著的异常值问题:
- 大多数分布不是正态分布;
- 存在极大的异常值;
- 在“鳄梨价格”数据集中,数据呈高度右偏分布;
- 存在许多异常值。
Tukey(1977)的技术用于检测偏斜或非钟形数据中的异常值,因为它不做分布假设。然而,Tukey的方法可能不适用于小样本量。一般规则是,任何不在(Q1-1.5 IQR)和(Q3+1.5 IQR)范围内的值都是异常值,并且可以被删除。
四分位距(IQR)是用于异常值检测和删除的最广泛使用的程序之一。
步骤:
- 找到第一四分位数Q1。
- 找到第三四分位数Q3。
- 计算IQR。IQR = Q3-Q1。
- 以Q1-1.5 IQR为下限,以Q3+1.5 IQR为上限定义正常数据范围。
有关异常值检测方法,请参见此处:https://www.kaggle.com/code/marcinrutecki/outlier-detection-methods
def IQR_method(df, n, features):
"""
使用Tukey IQR方法,接受一个数据框并返回一个索引列表,该列表对应于根据离群值数量超过n的观测值。
"""
outlier_list = [] # 创建一个空列表,用于存储离群值的索引
for column in features: # 遍历features中的每一列
# 计算第一四分位数(25%)
Q1 = np.percentile(df[column], 25)
# 计算第三四分位数(75%)
Q3 = np.percentile(df[column], 75)
# 计算四分位距(IQR)
IQR = Q3 - Q1
# 计算离群值步长
outlier_step = 1.5 * IQR
# 确定离群值索引列表
outlier_list_column = df[(df[column] < Q1 - outlier_step) | (df[column] > Q3 + outlier_step)].index
# 将离群值索引列表添加到总的离群值列表中
outlier_list.extend(outlier_list_column)
# 选择包含超过x个离群值的观测值
outlier_list = Counter(outlier_list) # 使用Counter计算每个索引出现的次数
multiple_outliers = list(k for k, v in outlier_list.items() if v > n) # 找到出现次数大于n的索引
# 计算低于和高于边界值的记录数
df1 = df[df[column] < Q1 - outlier_step]
df2 = df[df[column] > Q3 + outlier_step]
print('删除的离群值总数:', df1.shape[0] + df2.shape[0])
return multiple_outliers # 返回多个离群值的索引列表
# 定义函数IQR_method,用于检测并删除数据集中的异常值
# 使用IQR_method函数检测并删除df1数据集中numeric_columns2列的异常值
Outliers_IQR = IQR_method(df1, 1, numeric_columns2)
# 删除df1数据集中的异常值
df1 = df1.drop(Outliers_IQR, axis=0).reset_index(drop=True)
Total number of deleted outliers: 2533
# 使用IQR方法检测并删除异常值
# 调用IQR_method函数,传入原始数据集raw_df2、异常值阈值1和需要检测的数值型列名列表numeric_columns2
# 将返回的异常值索引列表赋值给变量Outliers_IQR
Outliers_IQR = IQR_method(raw_df2, 1, numeric_columns2)
# 删除异常值
# 调用drop函数,传入异常值索引列表Outliers_IQR和轴参数axis=0,表示按行删除异常值
# 调用reset_index函数,重置索引并丢弃原索引,将删除异常值后的数据集赋值给变量df2
df2 = raw_df2.drop(Outliers_IQR, axis=0).reset_index(drop=True)
Total number of deleted outliers: 7
5.3 训练测试分割
# 从df1中删除'AveragePrice'列,得到特征矩阵X
X = df1.drop('AveragePrice', axis=1)
# 从df1中获取'AveragePrice'列,得到目标变量y
y = df1['AveragePrice']
# 从raw_df2中获取除最后一列外的所有列,得到特征矩阵X2
X2 = raw_df2.iloc[:, :-1]
# 从raw_df2中获取最后一列,得到目标变量y2
y2 = raw_df2.iloc[:, -1]
# 导入train_test_split函数
from sklearn.model_selection import train_test_split
# 使用train_test_split函数将数据集X和标签y划分为训练集和测试集
# test_size参数指定测试集所占比例为30%,random_state参数指定随机种子为42,保证每次划分结果一致
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用train_test_split函数将数据集X2和标签y2划分为训练集和测试集
# test_size参数指定测试集所占比例为30%,random_state参数指定随机种子为42,保证每次划分结果一致
X_train2, X_test2, y_train2, y_test2 = train_test_split(X2, y2, test_size=0.3, random_state=42)
5.4 特征缩放
# 导入StandardScaler类
from sklearn.preprocessing import StandardScaler
# 创建一个函数用于特征缩放
def Standard_Scaler(df, col_names):
# 从数据框中选择需要缩放的特征列
features = df[col_names]
# 创建一个StandardScaler对象,并使用特征列的值进行拟合
scaler = StandardScaler().fit(features.values)
# 使用拟合后的scaler对象对特征列进行缩放
features = scaler.transform(features.values)
# 将缩放后的特征列替换原始数据框中的对应列
df[col_names] = features
# 返回缩放后的数据框
return df
# 定义列名列表col_names
col_names = ['Total Volume', 'Total Bags']
# 对训练集X_train进行标准化处理
X_train = Standard_Scaler(X_train, col_names)
# 对测试集X_test进行标准化处理
X_test = Standard_Scaler(X_test, col_names)
# 定义列名列表col_names
col_names = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
# 对训练集X_train2进行标准化处理
X_train2 = Standard_Scaler(X_train2, col_names)
# 对测试集X_test2进行标准化处理
X_test2 = Standard_Scaler(X_test2, col_names)
6. 比较不同模型
6.1 线性回归
# 导入线性回归模型
from sklearn.linear_model import LinearRegression
# 创建并训练模型
lm = LinearRegression()
lm.fit(X_train, y_train)
# 模型对测试数据进行预测
y_pred = lm.predict(X_test)
鳄梨数据集的线性回归性能
# 调用函数,计算线性回归模型的性能指标
ndf = [Reg_Models_Evaluation_Metrics(lm,X_train,y_train,X_test,y_test,y_pred)]
# 将性能指标转化为DataFrame格式,并添加模型名称
lm_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
lm_score.insert(0, 'Model', 'Linear Regression')
# 返回结果
lm_score
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Linear Regression | 0.598793 | 0.593598 | 0.604281 | 0.255931 |
# 导入必要的库
import matplotlib.pyplot as plt
import seaborn as sns
# 设置图形大小
plt.figure(figsize=(10, 5))
# 绘制回归图
sns.regplot(x=y_test, y=y_pred)
# 设置图形标题和字体大小
plt.title('Avocado数据集的线性回归', fontsize=20)
Text(0.5, 1.0, 'Linear regression for Avocado dataset')

波士顿数据集的线性回归性能
# 使用训练数据拟合线性回归模型
lm.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = lm.predict(X_test2)
# 创建一个名为ndf的列表,其中包含一个名为Reg_Models_Evaluation_Metrics的函数的返回值
ndf = [Reg_Models_Evaluation_Metrics(lm,X_train2,y_train2,X_test2,y_test2,y_pred)]
# 创建一个名为lm_score2的DataFrame,将ndf作为数据,列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
lm_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在lm_score2的第一列插入一个名为'Model'的列,值为'Linear Regression'
lm_score2.insert(0, 'Model', 'Linear Regression')
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Linear Regression | 0.679168 | 0.648945 | 0.687535 | 4.889394 |
6.2 随机森林
# 导入RandomForestRegressor类
from sklearn.ensemble import RandomForestRegressor
# 创建和训练模型
# 实例化RandomForestRegressor类,设置n_estimators参数为10(表示使用10个决策树),设置random_state参数为0(用于控制随机数生成的种子,保证每次运行结果一致)
RandomForest_reg = RandomForestRegressor(n_estimators = 10, random_state = 0)
针对鳄梨数据集的随机森林性能
# 使用随机森林模型对训练数据进行拟合
RandomForest_reg.fit(X_train, y_train)
# 使用训练好的模型对测试数据进行预测
y_pred = RandomForest_reg.predict(X_test)
# 创建一个名为ndf的列表,其中包含一个函数调用
# 函数调用使用RandomForest_reg模型对训练数据X_train和y_train进行拟合,并使用X_test进行预测,将预测结果与y_test进行比较,并计算评估指标
ndf = [Reg_Models_Evaluation_Metrics(RandomForest_reg,X_train,y_train,X_test,y_test,y_pred)]
# 创建一个名为rf_score的DataFrame,其中包含ndf中的数据,并设置列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
rf_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在rf_score中插入一列名为'Model',值为'Random Forest',插入到第一列位置
rf_score.insert(0, 'Model', 'Random Forest')
# 返回rf_score DataFrame
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest | 0.78712 | 0.784363 | 0.876525 | 0.186426 |
波士顿数据集的随机森林性能
# 使用随机森林回归模型进行训练
RandomForest_reg.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = RandomForest_reg.predict(X_test2)
# 创建一个名为ndf的列表,其中包含一个函数调用的结果
# 函数调用的参数包括RandomForest_reg(一个随机森林回归模型)、X_train2(训练集特征)、y_train2(训练集标签)、X_test2(测试集特征)、y_test2(测试集标签)、y_pred(预测结果)
# 函数的作用是使用随机森林回归模型对给定的训练集进行训练,并使用训练好的模型对测试集进行预测,并计算评估指标
# 评估指标包括R2 Score(决定系数)、Adjusted R2 Score(调整后的决定系数)、Cross Validated R2 Score(交叉验证的决定系数)、RMSE(均方根误差)
# 创建一个名为rf_score2的DataFrame,其中的数据来自ndf列表
# DataFrame的列名分别为'Model'、'R2 Score'、'Adjusted R2 Score'、'Cross Validated R2 Score'、'RMSE'
# 'Model'列的值为'Random Forest'
# 在rf_score2中插入一列,列名为'Model',列的值为'Random Forest',插入的位置为第一列
ndf = [Reg_Models_Evaluation_Metrics(RandomForest_reg,X_train2,y_train2,X_test2,y_test2,y_pred)]
rf_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
rf_score2.insert(0, 'Model', 'Random Forest')
rf_score2
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest | 0.838576 | 0.823369 | 0.817514 | 3.468169 |
6.3 岭回归
# 导入Ridge模型类
from sklearn.linear_model import Ridge
# 创建并训练模型
# 使用Ridge模型,设置alpha为3,solver为cholesky
ridge_reg = Ridge(alpha=3, solver="cholesky")
鳄梨数据集的岭回归性能
# 使用岭回归模型对训练数据进行拟合
ridge_reg.fit(X_train, y_train)
# 使用训练好的模型对测试数据进行预测
y_pred = ridge_reg.predict(X_test)
# 创建一个名为ndf的列表,其中包含一个调用Reg_Models_Evaluation_Metrics函数的结果
# 函数参数为ridge_reg、X_train、y_train、X_test、y_test和y_pred
# 创建一个名为rr_score的DataFrame,数据为ndf,列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
# 在DataFrame的第一列插入一个名为'Model'的列,值为'Ridge Regression'
ndf = [Reg_Models_Evaluation_Metrics(ridge_reg,X_train,y_train,X_test,y_test,y_pred)]
rr_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
rr_score.insert(0, 'Model', 'Ridge Regression')
rr_score
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Ridge Regression | 0.598733 | 0.593537 | 0.604317 | 0.25595 |
波士顿数据集的岭回归性能
# 使用岭回归模型对训练数据进行拟合
ridge_reg.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = ridge_reg.predict(X_test2)
# 创建一个名为ndf的列表,其中包含一个名为Reg_Models_Evaluation_Metrics的函数的调用结果
# 函数的参数依次为ridge_reg,X_train2,y_train2,X_test2,y_test2,y_pred
ndf = [Reg_Models_Evaluation_Metrics(ridge_reg,X_train2,y_train2,X_test2,y_test2,y_pred)]
# 创建一个名为rr_score2的DataFrame,数据为ndf,列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
rr_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在rr_score2的第一列插入一个名为'Model'的列,值为'Ridge Regression'
rr_score2.insert(0, 'Model', 'Ridge Regression')
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Ridge Regression | 0.678696 | 0.648428 | 0.689293 | 4.892991 |
6.4 XGBoost
# 导入XGBRegressor类,用于创建xgboost回归模型
from xgboost import XGBRegressor
# 创建一个xgboost回归模型,设置参数:树的数量为1000,树的最大深度为7,学习率为0.1,子样本比例为0.8,列采样比例为0.8
XGBR = XGBRegressor(n_estimators=1000, max_depth=7, eta=0.1, subsample=0.8, colsample_bytree=0.8)
Avocado数据集的XGBoost性能
# 使用XGBR.fit()方法对训练数据进行拟合,训练出XGBoost回归模型
XGBR.fit(X_train, y_train)
# 使用训练好的模型对测试数据进行预测
y_pred = XGBR.predict(X_test)
# 创建一个列表ndf,其中包含一个函数调用Reg_Models_Evaluation_Metrics,并传入参数XGBR,X_train,y_train,X_test,y_test,y_pred
ndf = [Reg_Models_Evaluation_Metrics(XGBR,X_train,y_train,X_test,y_test,y_pred)]
# 创建一个名为XGBR_score的DataFrame,将ndf作为数据传入,并设置列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
XGBR_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在XGBR_score的第一列插入一个名为'Model'的列,并将其值设置为'XGBoost'
XGBR_score.insert(0, 'Model', 'XGBoost')
# 返回XGBR_score DataFrame
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | XGBoost | 0.798641 | 0.796034 | 0.911125 | 0.181311 |
波士顿数据集的XGBoost性能
# 使用XGBR模型拟合训练数据
XGBR.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = XGBR.predict(X_test2)
# 定义一个列表ndf,其中包含一个函数Reg_Models_Evaluation_Metrics的返回值,该函数的参数为XGBR、X_train2、y_train2、X_test2、y_test2、y_pred
ndf = [Reg_Models_Evaluation_Metrics(XGBR,X_train2,y_train2,X_test2,y_test2,y_pred)]
# 将ndf转换为DataFrame格式,列名为'R2 Score'、'Adjusted R2 Score'、'Cross Validated R2 Score'、'RMSE',数据为ndf中的值
XGBR_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在XGBR_score2中插入一列名为'Model',值为'XGBoost',插入位置为第0列
XGBR_score2.insert(0, 'Model', 'XGBoost')
XGBR_score2
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | XGBoost | 0.901889 | 0.892646 | 0.845593 | 2.70381 |
6.5 递归特征消除(RFE)
RFE(递归特征消除)是一种包装型特征选择算法。这意味着在该方法的核心中使用了不同的机器学习算法,并由RFE进行包装,用于帮助选择特征。
随机森林通常与RFE结合使用,具有良好的性能。
from sklearn.feature_selection import RFE
from sklearn.pipeline import Pipeline
# 创建管道
# 使用RandomForestRegressor作为评估器,选择60个特征进行递归特征消除
rfe = RFE(estimator=RandomForestRegressor(), n_features_to_select=60)
# 创建RandomForestRegressor模型
model = RandomForestRegressor()
# 创建管道,将递归特征消除和随机森林回归模型连接起来
rf_pipeline = Pipeline(steps=[('s', rfe), ('m', model)])
针对鳄梨数据集的随机森林RFE性能
# 使用训练数据拟合随机森林模型
rf_pipeline.fit(X_train, y_train)
# 使用训练好的模型对测试数据进行预测
y_pred = rf_pipeline.predict(X_test)
# 创建一个包含随机森林模型评估指标的列表ndf,其中包含训练集X_train、y_train和测试集X_test、y_test以及预测值y_pred
ndf = [Reg_Models_Evaluation_Metrics(rf_pipeline,X_train,y_train,X_test,y_test,y_pred)]
# 将ndf转换为数据框rfe_score,并添加列名
rfe_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在rfe_score数据框中插入一列名为'Model',值为'Random Forest with RFE'的列
rfe_score.insert(0, 'Model', 'Random Forest with RFE')
# 返回rfe_score数据框
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest with RFE | 0.800169 | 0.797581 | 0.889159 | 0.180622 |
Boston数据集的随机森林RFE性能
随机森林RFE是一种特征选择方法,它使用随机森林算法来评估每个特征的重要性,并逐步删除最不重要的特征,直到达到所需数量的特征。在Boston数据集上,使用随机森林RFE可以有效地选择最相关的特征,以提高模型的性能。
# 导入所需模块已在代码中完成
# 创建一个RFE对象,使用随机森林回归器作为评估器,选择8个特征
rfe = RFE(estimator=RandomForestRegressor(), n_features_to_select=8)
# 创建一个随机森林回归器对象
model = RandomForestRegressor()
# 创建一个管道对象,将特征选择器和随机森林回归器组合在一起
rf_pipeline = Pipeline(steps=[('s',rfe),('m',model)])
# 使用训练数据拟合管道模型
rf_pipeline.fit(X_train2, y_train2)
# 使用测试数据进行预测
y_pred = rf_pipeline.predict(X_test2)
# 创建一个名为ndf的列表,其中包含一个Reg_Models_Evaluation_Metrics对象
# Reg_Models_Evaluation_Metrics对象的参数包括rf_pipeline、X_train2、y_train2、X_test2、y_test2和y_pred
ndf = [Reg_Models_Evaluation_Metrics(rf_pipeline,X_train2,y_train2,X_test2,y_test2,y_pred)]
# 创建一个名为rfe_score2的DataFrame,数据为ndf,列名为['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE']
rfe_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
# 在rfe_score2的第一列插入名为'Model'的列,值为'Random Forest with RFE'
rfe_score2.insert(0, 'Model', 'Random Forest with RFE')
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest with RFE | 0.839377 | 0.824246 | 0.82114 | 3.45955 |
7. 最终模型评估
7.1 鳄梨数据集
# 导入pandas库
import pandas as pd
# 将rfe_score、XGBR_score、rr_score、rf_score、lm_score合并为一个DataFrame,并忽略索引,不进行排序
predictions = pd.concat([rfe_score, XGBR_score, rr_score, rf_score, lm_score], ignore_index=True, sort=False)
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest with RFE | 0.800169 | 0.797581 | 0.889159 | 0.180622 |
| 1 | XGBoost | 0.798641 | 0.796034 | 0.911125 | 0.181311 |
| 2 | Ridge Regression | 0.598733 | 0.593537 | 0.604317 | 0.255950 |
| 3 | Random Forest | 0.787120 | 0.784363 | 0.876525 | 0.186426 |
| 4 | Linear Regression | 0.598793 | 0.593598 | 0.604281 | 0.255931 |
7.2 波士顿数据集
# 导入所需的库
import pandas as pd
# 将rfe_score2、XGBR_score2、rr_score2、rf_score2、lm_score2合并为一个DataFrame
predictions2 = pd.concat([rfe_score2, XGBR_score2, rr_score2, rf_score2, lm_score2], ignore_index=True, sort=False)
# 返回合并后的DataFrame predictions2
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Random Forest with RFE | 0.839377 | 0.824246 | 0.821140 | 3.459550 |
| 1 | XGBoost | 0.901889 | 0.892646 | 0.845593 | 2.703810 |
| 2 | Ridge Regression | 0.678696 | 0.648428 | 0.689293 | 4.892991 |
| 3 | Random Forest | 0.838576 | 0.823369 | 0.817514 | 3.468169 |
| 4 | Linear Regression | 0.679168 | 0.648945 | 0.687535 | 4.889394 |
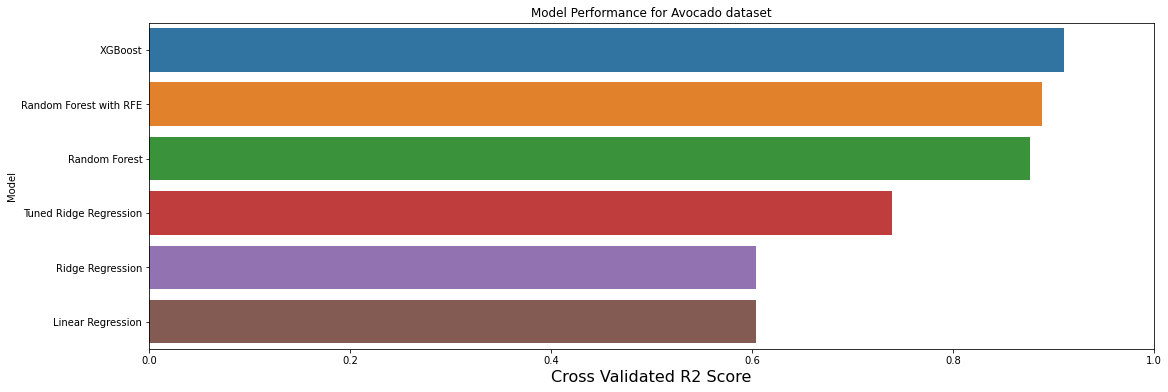
7.3 可视化模型性能
# 创建一个图形对象f和一个坐标轴对象axe
f, axe = plt.subplots(1,1, figsize=(18,6))
# 按照'Cross Validated R2 Score'列的值降序排列预测结果
predictions.sort_values(by=['Cross Validated R2 Score'], ascending=False, inplace=True)
# 使用条形图显示模型的交叉验证R2得分
sns.barplot(x='Cross Validated R2 Score', y='Model', data = predictions, ax = axe)
# 设置x轴标签为'Cross Validated R2 Score',字体大小为16
axe.set_xlabel('Cross Validated R2 Score', size=16)
# 设置y轴标签为'Model'
axe.set_ylabel('Model')
# 设置x轴范围为0到1.0
axe.set_xlim(0,1.0)
# 设置图形标题为'Avocado数据集的模型性能'
axe.set(title='Model Performance for Avocado dataset')
# 显示图形
plt.show()

# 创建一个图形对象f和一个坐标轴对象axe
f, axe = plt.subplots(1,1, figsize=(18,6))
# 按照'Cross Validated R2 Score'列的值进行降序排序
predictions2.sort_values(by=['Cross Validated R2 Score'], ascending=False, inplace=True)
# 使用sns库的barplot函数绘制条形图,x轴为'Cross Validated R2 Score'列的值,y轴为'Model'列的值,图形对象为axe
sns.barplot(x='Cross Validated R2 Score', y='Model', data = predictions2, ax = axe)
# 设置x轴标签为'Cross Validated R2 Score',字体大小为16
axe.set_xlabel('Cross Validated R2 Score', size=16)
# 设置y轴标签为'Model'
axe.set_ylabel('Model')
# 设置x轴范围为0到1.0
axe.set_xlim(0,1.0)
# 设置图形标题为'Model Performance for Boston dataset'
axe.set(title='Model Performance for Boston dataset')
# 显示图形
plt.show()

8. 使用GridSearchCV进行超参数调优
超参数调整是在构建机器学习模型时调整元组中存在的参数的过程。这些参数由我们定义,机器学习算法不会学习这些参数。这些参数可以在不同的步骤中进行调整。
GridSearchCV是一种从网格中给定的参数集中寻找最优超参数值的技术。它本质上是一种交叉验证技术。必须输入模型以及参数。在提取最佳参数值之后,进行预测。
GridSearchCV识别的“最佳”参数在技术上是可以产生的最佳参数,但仅限于您在参数网格中包含的参数。
8.1 调整后的岭回归
# 导入PolynomialFeatures类
from sklearn.preprocessing import PolynomialFeatures
# 多项式特征是通过将现有特征提升到指数来创建的特征。
# 例如,如果一个数据集有一个输入特征X,
# 那么多项式特征将是添加一个新特征(列),其中的值是通过对X的值进行平方计算得到的,例如X^2。
# 定义步骤列表,包括多项式特征和岭回归模型
steps = [
('poly', PolynomialFeatures(degree=2)), # 多项式特征转换器,将输入特征转换为指定次数的多项式特征
('model', Ridge(alpha=3.8, fit_intercept=True)) # 岭回归模型,用于拟合数据并进行预测
]
# 创建Pipeline对象,将多项式特征转换器和岭回归模型组合在一起
ridge_pipe = Pipeline(steps)
# 使用训练数据拟合Pipeline对象
ridge_pipe.fit(X_train, y_train)
# 使用测试数据进行预测
y_pred = ridge_pipe.predict(X_test) # 模型对测试数据进行预测,得到预测结果y_pred
# 导入GridSearchCV类,用于进行网格搜索
from sklearn.model_selection import GridSearchCV
# 定义一个列表alpha_params,其中包含一个字典,字典的键为'model__alpha',值为从1到14的整数列表
alpha_params = [{'model__alpha': list(range(1, 15))}]
# 创建一个GridSearchCV对象clf,使用ridge_pipe作为模型,alpha_params作为参数候选值,cv参数为10,表示进行10折交叉验证
clf = GridSearchCV(ridge_pipe, alpha_params, cv=10)
针对Avocado数据集的调整后的岭回归性能
# 训练和调整模型
clf.fit(X_train, y_train)
# 模型对测试数据进行预测
y_pred = ridge_pipe.predict(X_test)
# 输出最佳超参数组合及其对应的性能表现
print(clf.best_params_)
{'model__alpha': 1}
# 创建一个名为ndf的列表,其中包含一个名为Reg_Models_Evaluation_Metrics的函数的调用结果
# 函数调用时传入了参数clf、X_train、y_train、X_test、y_test和y_pred
# 创建一个名为clf_score的DataFrame,其中的数据来自ndf列表,列名分别为'R2 Score'、'Adjusted R2 Score'、'Cross Validated R2 Score'和'RMSE'
# 在DataFrame中插入一列名为'Model',值为'Tuned Ridge Regression',插入到第0列位置
# 最终得到的clf_score是一个包含评估指标的DataFrame,用于记录模型的性能评估结果
ndf = [Reg_Models_Evaluation_Metrics(clf,X_train,y_train,X_test,y_test,y_pred)]
clf_score = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
clf_score.insert(0, 'Model', 'Tuned Ridge Regression')
clf_score
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Tuned Ridge Regression | 0.736622 | 0.733212 | 0.739008 | 0.210438 |
调整后的岭回归在波士顿数据集上的性能
# 导入所需的模块和函数
# 定义一个步骤列表,其中包含多个步骤,每个步骤都有一个名称和对应的操作
steps = [
('poly', PolynomialFeatures(degree=2)), # 多项式特征转换器,将特征转换为指定次数的多项式特征
('model', Ridge(alpha=3.8, fit_intercept=True)) # 岭回归模型,使用指定的alpha值进行训练
]
# 创建一个管道对象,将多个步骤按顺序连接起来,形成一个完整的机器学习流程
ridge_pipe = Pipeline(steps)
# 使用训练数据对管道进行训练,拟合模型参数
ridge_pipe.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = ridge_pipe.predict(X_test2)
# 定义一个字典,包含一个参数和其对应的取值范围
alpha_params = [{'model__alpha': list(range(1, 15))}]
# 创建一个网格搜索交叉验证对象,用于寻找最佳的模型超参数
clf = GridSearchCV(ridge_pipe, alpha_params, cv=10)
# 使用训练数据对模型进行训练和调参
clf.fit(X_train2, y_train2)
# 使用训练好的模型对测试数据进行预测
y_pred = ridge_pipe.predict(X_test2)
# 打印最佳超参数组合及其对应的性能指标
print(clf.best_params_)
{'model__alpha': 12}
# 创建一个名为ndf的列表,其中包含一个名为Reg_Models_Evaluation_Metrics的函数的调用结果
# 函数调用时传入了参数clf、X_train2、y_train2、X_test2、y_test2和y_pred
# 创建一个名为clf_score2的DataFrame,其中的数据来自ndf列表
# DataFrame的列名分别为'R2 Score'、'Adjusted R2 Score'、'Cross Validated R2 Score'和'RMSE'
# 在clf_score2中插入一列,列名为'Model',列的值为'Tuned Ridge Regression'
ndf = [Reg_Models_Evaluation_Metrics(clf,X_train2,y_train2,X_test2,y_test2,y_pred)]
clf_score2 = pd.DataFrame(data = ndf, columns=['R2 Score','Adjusted R2 Score','Cross Validated R2 Score','RMSE'])
clf_score2.insert(0, 'Model', 'Tuned Ridge Regression')
clf_score2
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Tuned Ridge Regression | 0.793267 | 0.773792 | 0.844628 | 3.965999 |
9. 最终性能比较
9.1 鳄梨数据集
# 将clf_score和predictions两个DataFrame进行合并
result = pd.concat([clf_score, predictions], ignore_index=True, sort=False)
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Tuned Ridge Regression | 0.736622 | 0.733212 | 0.739008 | 0.210438 |
| 1 | XGBoost | 0.798641 | 0.796034 | 0.911125 | 0.181311 |
| 2 | Random Forest with RFE | 0.800169 | 0.797581 | 0.889159 | 0.180622 |
| 3 | Random Forest | 0.787120 | 0.784363 | 0.876525 | 0.186426 |
| 4 | Ridge Regression | 0.598733 | 0.593537 | 0.604317 | 0.255950 |
| 5 | Linear Regression | 0.598793 | 0.593598 | 0.604281 | 0.255931 |
# 创建一个图形对象f和一个坐标轴对象axe
f, axe = plt.subplots(1,1, figsize=(18,6))
# 按照'Cross Validated R2 Score'列的值进行降序排序
result.sort_values(by=['Cross Validated R2 Score'], ascending=False, inplace=True)
# 在坐标轴axe上绘制条形图,x轴为'Cross Validated R2 Score'列的值,y轴为'Model'列的值
sns.barplot(x='Cross Validated R2 Score', y='Model', data = result, ax = axe)
# 设置x轴标签为'Cross Validated R2 Score',字体大小为16
axe.set_xlabel('Cross Validated R2 Score', size=16)
# 设置y轴标签为'Model'
axe.set_ylabel('Model')
# 设置x轴范围为0到1.0
axe.set_xlim(0,1.0)
# 设置图形标题为'Model Performance for Avocado dataset'
axe.set(title='Model Performance for Avocado dataset')
# 显示图形
plt.show()
9.2 波士顿数据集
# 将clf_score2和predictions2两个DataFrame进行合并
result = pd.concat([clf_score2, predictions2], ignore_index=True, sort=False)
| Model | R2 Score | Adjusted R2 Score | Cross Validated R2 Score | RMSE | |
|---|---|---|---|---|---|
| 0 | Tuned Ridge Regression | 0.793267 | 0.773792 | 0.844628 | 3.965999 |
| 1 | XGBoost | 0.901889 | 0.892646 | 0.845593 | 2.703810 |
| 2 | Random Forest with RFE | 0.839377 | 0.824246 | 0.821140 | 3.459550 |
| 3 | Random Forest | 0.838576 | 0.823369 | 0.817514 | 3.468169 |
| 4 | Ridge Regression | 0.678696 | 0.648428 | 0.689293 | 4.892991 |
| 5 | Linear Regression | 0.679168 | 0.648945 | 0.687535 | 4.889394 |
# 创建一个图形对象f和一个子图对象axe,子图对象axe的大小为18x6
f, axe = plt.subplots(1,1, figsize=(18,6))
# 按照'Cross Validated R2 Score'列的值降序排列结果
result.sort_values(by=['Cross Validated R2 Score'], ascending=False, inplace=True)
# 在子图axe上绘制条形图,x轴为'Cross Validated R2 Score'列的值,y轴为'Model'列的值,数据来源为result
sns.barplot(x='Cross Validated R2 Score', y='Model', data = result, ax = axe)
# 设置x轴标签为'Cross Validated R2 Score',字体大小为16
axe.set_xlabel('Cross Validated R2 Score', size=16)
# 设置y轴标签为'Model'
axe.set_ylabel('Model')
# 设置x轴范围为0到1.0
axe.set_xlim(0,1.0)
# 设置图形标题为'Model Performance for Boston dataset'
axe.set(title='Model Performance for Boston dataset')
# 显示图形
plt.show()

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!