10亿数据高效插入MySQL最佳方案
写在文章开头
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。

问题简介
我们直接引入本文要探讨的问题,现在要求用最快的速度把10亿条左右的数据存到数据库中,对应的该实现有着以下几个要求:
- 每条数据转为数据库数据大约
1k。 - 数据都存在
txt文档中,需要进行解析后才能存到数据库中。 - 所有数据对应的文档都存在
Hdfs或S3分布式文件存储里。 - 数据被分到100个文件中,通过文件的后缀确定这些数据的批次。
- 要求保证有序导入,数据尽可能不重复。
- 存储的数据库是
MySQL。
分析问题点
针对需求整理分析,我们对该功能提出以下几个问题点:
- 如何插入?是批量插入还是逐条插入?
- 这种数据量是否需要考虑一下分库分表?
- 插入时是用串行插入数据表还是并行插入数据表?
- MySQL存储引擎如何选择?
- 如何实现快速读取数据?
- 如何保证的写入时有序,即按照100个文件对应的数据顺序进行存储?
- 我们希望将这个插入功能以任务为单位进行,要如何封装?
- 如何实现分布式节点并发工作?
逐个击破
如何插入?批量插入还是单条插入?
考虑到按照主键id顺序自增顺序写入可以达到最快性能,所以我们的数据表的主键id一定是顺序自增的,其次我们都知道MySQL插入操作中最耗时的操作是网络链接,所以我们采用的插入方式是批量插入。为了避免每次进行批量插入时,JDBC需要预编译SQL发起的网络IO,我们使用Mybatis进行插入时,会采用ExecutorType.BATCH的方式进行批处理插入,代码示例大抵如下所示:
@Autowired
private SqlSessionFactory sqlSessionFactory;
/**
* session插入
*/
@Test
void batchInsert() {
//获取一个BATCH的sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
BatchInsertTestMapper sqlSessionMapper = sqlSession.getMapper(BatchInsertTestMapper.class);
long start = System.currentTimeMillis();
for (BatchInsertTest batchInsertTest : testList) {
//生成插入语句
sqlSessionMapper.insert(batchInsertTest);
}
//使用批处理的方式一次性提交这批插入SQL
sqlSession.commit();
long end = System.currentTimeMillis();
log.info("批处理插入{}条数据耗时:{}", BATCH_INSERT_SIZE, end - start);
}
明确了插入方式之后,我们还需要解决每次插入的数据量,根据笔者压测经验,建议选择MySQL配置的全局变量max_allowed_packed大小的一半左右。
举个例子,假设我们的每条数据为1k,而max_allowed_packed为4m,那么每次插入的数据量就是:
max_allowed_packed/2/每条数据的大小=4096/2/1=2048
也就是说我们进行批量插入时,建议一次插入2000条左右的数据最合适,具体还需要结合压测进行明确定位。
是否需要分表?一张表多大合适?如何分表?
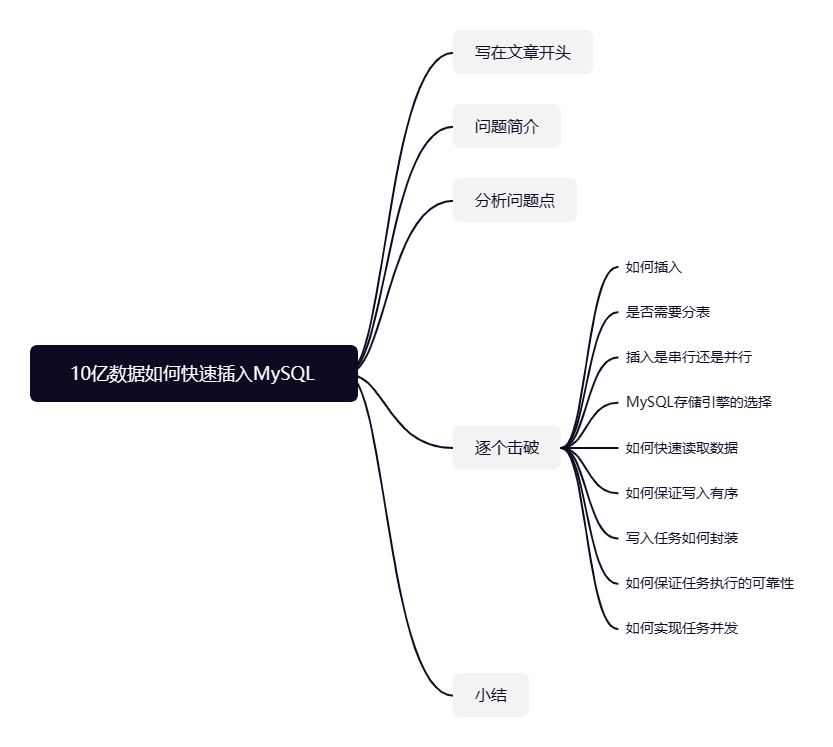
答案是不能,MySQL单库并发写入是存在性能瓶颈的,假设10亿条数据都存储到一张数据表中,无论是插入还是插入操作都会占用大量计算资源,操作相当耗时。所以我们这里需要进行分库分表,一张表建议存2000w左右的数据。
而这个值是怎么得来的呢?我们都直到MySQL底层索引结构采用的是B+树,我们插入的数据都是存储在聚簇索引的叶子节点下。而我们本次插入的数据差不多1k左右的大小,而MySQL数据的页大小为16k,这也就意味者一个叶子节点最多可以存储16条数据。
而非叶子节点存储的数据主键和指向叶子的指针,假设我们主键类型为bigint,即8字节,而指针在innoDB中是为6字节,那么一个非叶子节点可以记录的数据计算公式为:
页大小*1024/(主键大小+指针大小)=16*1024/(8+6)≈1170
也就是说一个非叶子节点大约可以表示1170条数据,而MySQL一张数据表存储数据建议的层级为3层左右,所以一张表最大存储的数据量为2000w:
1170 * 1170 * 16 =21902400≈2000w
明确一张表存储2000w条数据之后。接下来则需要确定如何进行分库分表,在此之前我们必须明确一下使用的存储方案,如果采用HDD的方式,由于写入是需要磁头进行寻道,所以在并发写的情况下会非常耗时,所以并发数和分库数都需要尽可能的少。反之SSD存储并发写入性能更好,但不同厂商的写入能力也大有不同,有的支持500M/s,有的支持1G/s读写,有的支持8个并发,有的支持4个并发。在线上实验之前,我们并不知道实际的性能表现如何。简言之,我们的分库分表要支持可配置,以便在存储方案修改可以切换。
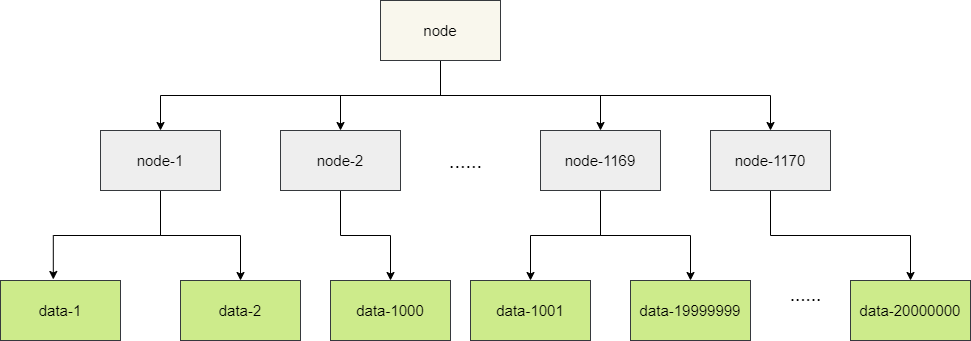
这里我们就假设采用SSD的方式存储数据,考虑的写操作是性能最大瓶颈,所以我们的分库分表要以写操作为主,考虑到10亿左右的数据大约1T大小,我们将其切分为100个文件,所以一个文件大约是10G左右,所以一个文件对应一个写入任务进行批量插入处理比较合适,所以我们建议分为100张表。
插入是是否需要并发写入
首先根据需求说明,要求顺序写入,所以不建议并发写入。而且我们提高了批量插入的阈值,在一定程度上也增加了插入的并发度,所以不需要在进行并发写入单表了。
MySQL存储引擎的选择
参考网上的解决方案:Mysql数据库Innodb与MyISAM的性能对比测试
,可以看出innoDB在关闭即时刷盘之后(可通过innodb_flush_log_at_trx_commit调整),其性能与MyiSam相差不大,而考虑到前者支持事务,为适配其他业务功能,我们建议选择使用Innodb,然后根据业务情况决定是否调整刷盘策略。
如何快速读取数据?
我们有10亿条数据,分到100个文件中,也就是每个文件大约10G,这也就意味我们不能一次性将文件读取到内存中进行操作,需要分批次进行读取,而Java常见的IO读取方式大概有以下几种技术:
- Files.readAllBytes一次性将数据加载到内存中。
- FileReader结合BufferedReader进行逐行读取。
- InputStreamReader 结合BufferedReader进行读取。
- Scanner读取。
- Java Nio FileChannel缓冲区方式读取。
为了验证上述读取技术的性能,笔者基于下述代码生成了230w左右的的数据:
public static void readFileByFiles(String pathname) {
Path path = Paths.get(pathname);
try {
/*
* 使用readAllLines的时候,小文件可以很快读取.
* 那么更大的文件,读取的肯定会爆了。
*/
//List<String> lines = Files.readAllLines(path);
byte[] bytes = Files.readAllBytes(path);
String str = new String(bytes);
System.out.println(str);
} catch (IOException e) {
e.printStackTrace();
}
}
先来看看Files.readAllBytes的读取代码段,输出结果为2723ms:
public static void main(String[] args) {
String filePath = "F:\\user.txt";
long start = System.currentTimeMillis();
try {
byte[] fileContent = Files.readAllBytes(Paths.get(filePath));
String contentString = new String(fileContent);
System.out.println(contentString);
long end = System.currentTimeMillis();
log.info("总耗时:{}ms", end - start);
} catch (IOException e) {
e.printStackTrace();
}
}
再来看看FileReader结合BufferedReader逐行读取的代码段,对应的输出结果为249ms,相较于前者会好一些:
public static void readFileByFileReader(String pathname) {
File file = new File(pathname);
FileReader fileReader;
BufferedReader bufferedReader;
try {
fileReader = new FileReader(file);
bufferedReader = new BufferedReader(fileReader);
String line;
StringBuffer buffer = new StringBuffer();
while((line = bufferedReader.readLine()) != null){
// 一行一行地处理...
//System.out.println(line);
//处理字符串,并不会将字符串保存真正保存到内存中
// 这里简单模拟下处理操作.
buffer.append(line.substring(0,1));
}
System.out.println("buffer.length:"+buffer.length());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
//TODO close处理.
}
}
然后就是InputStreamReader 结合BufferedReader,耗时为273ms,和前者区别不大:
public static void readFileByBufferedReader(String pathname) {
File file = new File(pathname);
BufferedReader reader = null;
FileInputStream fileInputStream = null;
InputStreamReader inputStreamReader = null;
try {
//使用BufferedReader,每次读入1M数据.减少IO.如:
fileInputStream = new FileInputStream(file);
inputStreamReader = new InputStreamReader(fileInputStream, Charset.defaultCharset());
reader = new BufferedReader(inputStreamReader,1*1024*1024);
String tempString = null;
StringBuffer buffer = new StringBuffer();
while( (tempString = reader.readLine()) != null) {
//System.out.println(tempString);
//处理字符串,并不会将字符串保存真正保存到内存中
// 这里简单模拟下处理操作.
buffer.append(tempString.substring(0,1));
}
System.out.println("buffer.length:"+buffer.length());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
//TODO close处理
}
}
同样的我们给出Scanner 的代码示例,输出结果为1397ms,性能一般:
public static void readFileByScanner(String filePath) {
FileInputStream inputStream = null;
Scanner sc = null;
try {
inputStream = new FileInputStream(filePath);
sc = new Scanner(inputStream, "UTF-8");
StringBuffer buffer = new StringBuffer();
while (sc.hasNextLine()) {
String line = sc.nextLine();
//System.out.println(line);
//处理字符串,并不会将字符串保存真正保存到内存中
// 这里简单模拟下处理操作.
buffer.append(line.substring(0,1));
}
System.out.println("buffer.length:"+buffer.length());
} catch (Exception e) {
e.printStackTrace();
} finally {
//TODO close处理
}
}
最后我们给出Java nio的读取,一次读取1M的数据,耗时只需惊人的77ms:
public static void readFileFileChannel(String pathname) {
File file = new File(pathname);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(file);
FileChannel fileChannel = fileInputStream.getChannel();
int capacity = 1 * 1024 * 1024;//1M
ByteBuffer byteBuffer = ByteBuffer.allocate(capacity);
StringBuffer buffer = new StringBuffer();
while (fileChannel.read(byteBuffer) != -1) {
//读取后,将位置置为0,将limit置为容量, 以备下次读入到字节缓冲中,从0开始存储
byteBuffer.clear();
byte[] bytes = byteBuffer.array();
String str = new String(bytes);
//System.out.println(str);
//处理字符串,并不会将字符串保存真正保存到内存中
// 这里简单模拟下处理操作.
buffer.append(str.substring(0, 1));
}
System.out.println("buffer.length:" + buffer.length());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//TODO close处理.
}
}
详细的评测内容请参考:读取文件性能比较 :https://zhuanlan.zhihu.com/p/142029812
因为Java Nio FileChannel无法精确的截取每一行数据,所以笔者建议,若读取的数据能够精确解析成数据行可优先考虑Java Nio FileChannel,反之考虑使用FileReader结合BufferedReader,毕竟后者支持逐行读取。
写入时,如何保证有序写入数据库
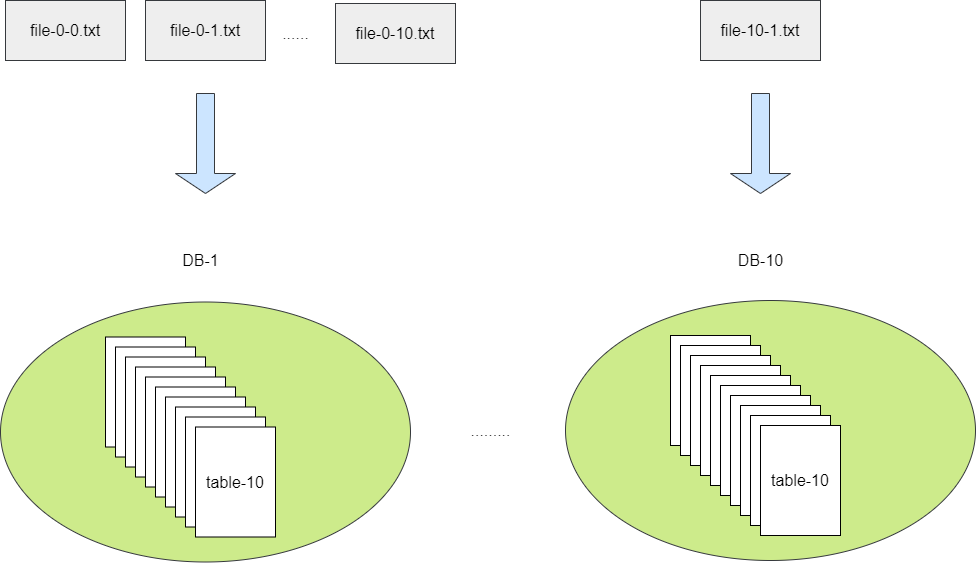
需求明确100个文件,而我们也明确使用100张表,为保证插入并发均摊,我们建议采用10*10即10个库每个库10张表的方式存储数据,如此一来,每个文件即可按照库、表序号进行命名:
1. file-0-0.txt:存储到第1个库的第一张表
2. file-1-1.txt:存储到第2个库的第2张表。
写入任务如何封装
考虑到批量插入的数据庞大,为了保证可靠性,我们专门设计一张数据表用于记录当前批量插入的进度,该数据库字段如下:
- bizId:考虑到后续可能也有别的业务会用到这张表,所以专门用此字段区分不同业务。
- dbIdx:记录当前任务的使用的数据库后缀。
- tbIdx:记录当前任务使用的数据表后缀。
- taskId:记录当前任务的id,每个文件对应一个任务id。
- fileName:记录当前导入操作的文件名。
- offset:记录当前文件进度读取进度,例如文件读取到1000行,那么这个字段存储的值就是1000。
- status:记录当前任务执行状态,状态可分为初始化、处理中、成功、失败、取消。
- retry_count:记录任务失败后重试次数,我们希望重试3次后,彻底将这个任务标记为失败,不再进行重试。
通过将100个文件批量插入操作以100个任务的形式存储到MySQL数据表中,保证数据导入的可靠性,以及后续并发控制、有序执行、失败可断点重试做好铺垫。
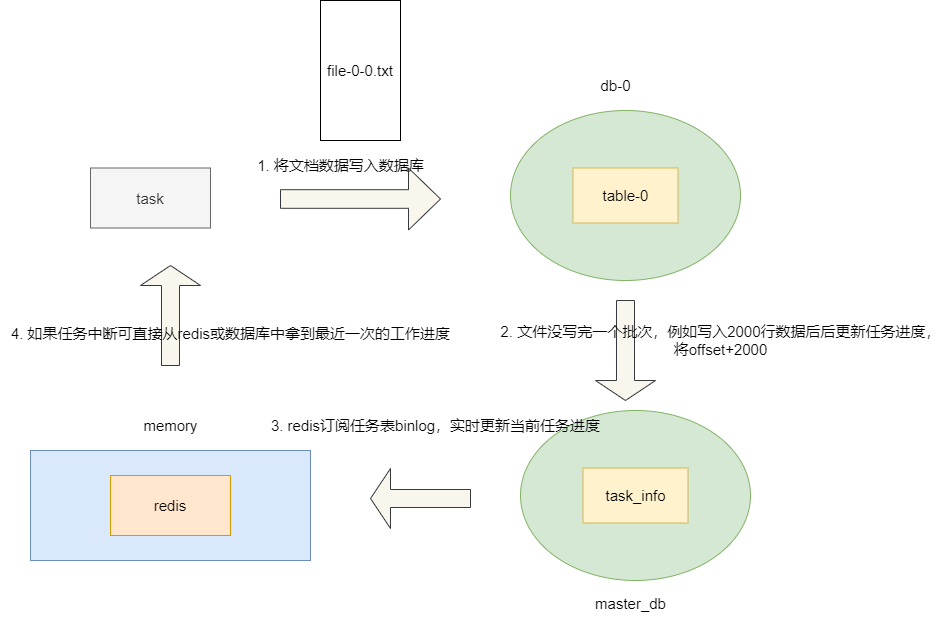
如何保证任务可靠性
为防止各种意外,例如服务发布、服务宕机、数据库故障等情况导致数据导入到数据库失败,导致任务中断我们又该怎么办呢?所以为了保证尽可能的断点续导,所以我们必须保证有一个介质可以存储读写进度,我们建议每次完成一批数据写入之后,先将进度更新到任务表中,让redis订阅binlog实时记录任务进度更新。
如此一来,一旦意味故障导致谋一份进度丢失,我们也可以通过先查询redis,若redis没数据再去查询任务进度表尽可能定位到当前的导入进度,进行断点续传。
如何保证写入有序性
现在的情况是100个文档对应100个任务,读写调度需要如何设计呢?如果根据任务读取一部分文档数据,然后丢到消息队列等中间件中,那么有序性就无法保证,即使可以保证,实现也是非常复杂且不好维护。最简单的办法就是将读写操作都交由每一个工作的线程进行处理。让并发线程根据任务信息读取一批文档的数据后直接着手插入工作,从而保证数据有序。
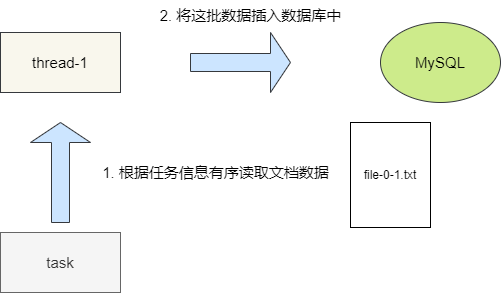
如何实现任务并发
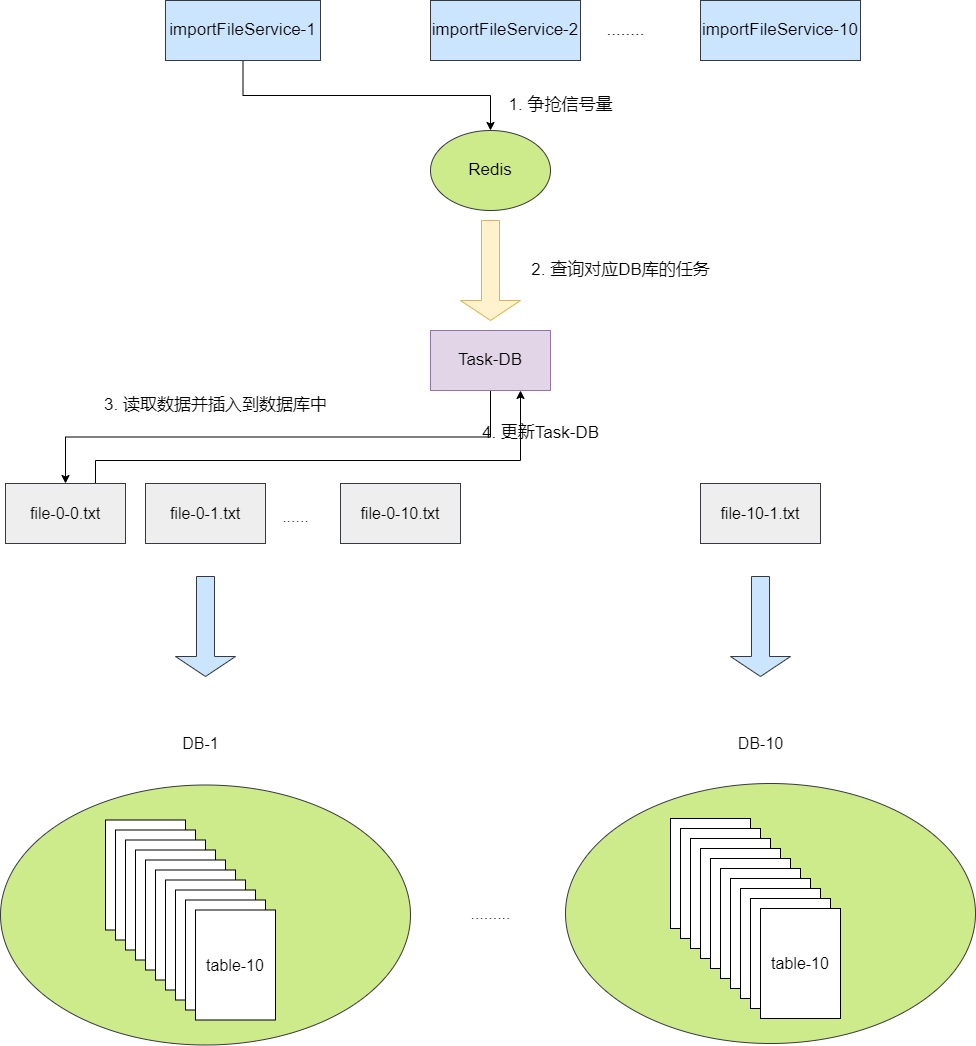
为了避免微服务架构下多节点大量的批量批次导入的线程大并发的执行插入而影响数据库性能,我们必须做到并发控制,所以我们需要限制每个节点的线程数,然后让这些线程通过任务争抢的方式获取任务在进行数据读写,为保证100个任务执行的数据一致性,对于任务争抢确保任务执行的互斥就很重要了,对此笔者建议的方案是通过Redission实现信号量,用每个库id作为key,线程得到这个信号量之后就去任务表获取指定数量的任务执行,考虑到服务crash或其他原因导致信号量未能及时释放,我们需要对信号量设置时限,例如30s,这意味着我们的线程如果还在执行任务需要每25s进行一次续命,直至任务完成释放信号量。
小结
来简单的总结一下,针对10亿数据入库的方案步骤:
- 文件拆分,这里按照需求规定为100个。
- 采用批处理批量插入提高插入性能。
- 针对文件进行恒等分库分表,即10*10搭配。
- 使用串行插入保证有序。
- 考虑到事务建议使用InnoDB。
- 基于库表id设计任务。
- 采用binlog结合redis保证写入可靠性以及断点续存。
- 采用redission信号量实现分布式并发任务争抢避免并发插入导致单库宕机。
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:
写代码的SharkChili,同时我的公众号也有我精心整理的并发编程、JVM、MySQL数据库个人专栏导航。

参考资料
阿里终面:10亿数据如何快速插入MySQL?:https://mp.weixin.qq.com/s/gEDdRDkHK-PQw2DENxiZaw
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!