MVIT图像分类 学习笔记 (附代码)
论文地址:https://arxiv.org/pdf/2104.11227.pdf
代码地址:https://github.com/facebookresearch/SlowFast
1.是什么?
MViT(Multiscale Vision Transformers)是一种多尺度视觉Transformer模型。它的关键概念是逐步增加通道分辨率(即维度),同时降低整个网络的时空分辨率(即序列长度)。通过这种设计,MViT在早期层具有精细的时空(和粗通道)分辨率,在后期层中上/下采样到粗时空(和精细通道)分辨率。
与在整个网络中保持恒定通道容量和分辨率的传统transformer不同,多尺度transformer具有几个通道分辨率“尺度”阶段。从图像分辨率和小通道维度出发,逐级扩展通道容量,同时降低空间分辨率。这在transformer网络内部创建了一个特征激活的多尺度金字塔,有效地将transformer的原理与多尺度特征层次联系起来。

2.为什么?
- 视觉信号的极度密集性。前期层信道容量较轻,可以在高空间分辨率下运行,模拟简单的低级视觉信息。反过来,深层可以关注复杂的高级特征。
- 多尺度模型充分利用时间信息。在自然视频上训练的ViT在具有混洗帧的视频上测试时,不会出现性能衰减,表明这些模型没有有效地使用时间信息,而是严重依赖于外观。相比之下,当在随机帧上测试MViT模型时,有显著的精度衰减,这表明十分依赖于时间信息。
- MViT在没有任何外部预训练数据的情况下,相较于并发视频转换器有显著的性能提升。
3.怎么样?
通用 Multiscale Vision Transformer 架构建立在 stages 这个核心概念之上。每个 stage 都包含多个具有特定时空分辨率和通道维度的 transformer block。 Multiscale Transformers 的主要思想是逐步扩展通道容量,同时汇集网络从输入到输出的分辨率。
3.1网络结构
3.11.多头池化注意力(Multi Head Pooling Attention)
首先对MHPA作出解释,这是本文的核心,它使得多尺度变换器以逐渐变化的时空分辨率进行操作。与原始的多头注意力(MHA)不同,在原始的多头注意力中,通道维度和时空分辨率保持不变,MHPA将潜在张量序列合并,以减少参与输入的序列长度(分辨率)。如图3所示

具体地说,考虑一个序列长度为L的D维输入张量X, X∈RL×D。在MHA之后,MHPA将输入的X通过线性运算投影到中间查询张量(Q∈RL×D)、键张量(K∈RL×D)和值张量(V∈RL×D)?
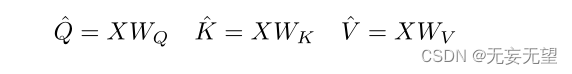
使用维数为D×D的权重WQ、WK、WV?,然后使用池操作符 P将获得的中间张量按序列长度进行合并
Pooling Operator
在参与输入之前,中间张量参与运算符P ( ? ; Θ ) P(·;Θ)P(?;Θ),这是MHPA的基石,也是多尺度变换器架构的基础。运算符P ( ? ; Θ ) P(·;Θ)P(?;Θ)沿每个维度对输入张量执行池化计算。
Θ=(k,s,p),使用大小为的池核k、大小为
的步长s和大小为
填充p,来减少尺寸L=T×H×W的输入张量,经过下面的公式池化之后

?
用坐标方向的方程。池化张量再次被平面化,得到P(Y;Θ)∈R ~ L×D,序列长度减少
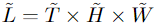
Pooling Attention
P(?;Θ) 分别地应用于所有中间张量,由此产生预注意向量
,
和
通过操作对Q,K,V进行计算

其中是按行对内积矩阵进行规范化。因此,随着P(?;Θ)中查询向量 Q 的缩减,最后的输出结果是输出序列缩减了
。并且我们从图3可以注意到,
必须成立,因为他们缩减的幅度必须一致,否则不能进行计算。
总结,以上公式可以用下面的公式来详细表达
?

Multiple heads
假设有h个头部,计算可以并行化,其中每个头部在D维输入张量X的D/h的非重叠子集上执行池化注意力。
3.1.2多尺度变换器网络(Multiscale Transformer Networks)
基于多头集中注意力(MHPA),本文创造了专门使用MHPA和MLP层进行视觉表征学习的多尺度变换器模型。在此之前,了解一下ViT模型
Vision Transformer (ViT)
- 首先将分辨率为 T × H × W 的输入视频,其中 T 为帧数、 H 为高度、 W 为宽度,分割成尺寸为1 × 16 × 16的非重叠块,然后在平坦图像块上逐点运用线性层,将其投影到潜在尺寸 D 中。就是1 × 16 × 16的核大小和步长的卷积,如表1中patch1阶段所示
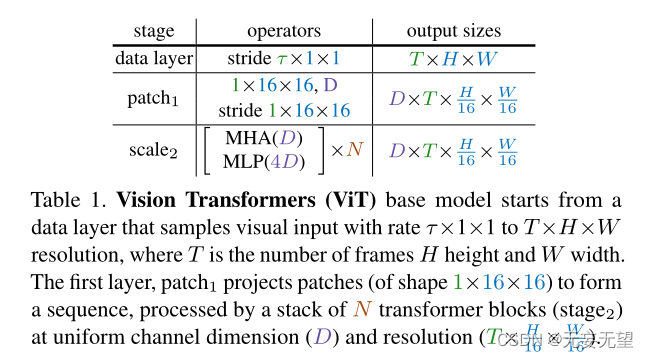
- 位置嵌入
添加到长度为L且维数为D的投影序列的每个元素。
- 通过N个变换器块的顺序处理,产生的长度为L+1的序列,每个变换器块执行注意力(MHA)、多层感知机(MLP)和层规范化(LN)操作。通过以下公式计算:

此处产生长度为L+1的序列是因为spacetime resolution + class token
- N个连续块之后的结果序列被层规范化,通过线性层来预测输出。此处需要注意,默认情况下,MLP的输入是4D。
?Multiscale Vision Transformers (MViT)
逐步增加信道维度,同时降低整个网络的时空分辨率(即序列长度)。MViT在早期层中具有精细的时空分辨率和低信道维度,而在后期层中,变为粗略的时空分辨率和高信道维度。MViT如表2所示。

Scale stages
尺度阶段定义为一组N个变换器块,在相同的尺度上跨信道和时空维度以相同的分辨率运行。在阶段转换时,信道维度上采样,而序列的长度下采样。
Channel expansion
当从一个阶段过渡到下一个阶段时,通过增加前一阶段最终MLP层的输出来扩展通道维数,增加的因素与该阶段引入的分辨率变化相关。举个例子来说,时空分辨率降低4倍,那么通道维数需要增大2倍。
Query pooling
池操作使得查询向量方面有更高的灵活性,从而可以改变输出序列的长度。将查询向量 P(Q;k;p;s)与核函数结合起来,使序列减少了
。这里有个点需要注意,一个阶段的开始降低分辨率,然后在整个阶段保持分辨率,所以只有每个阶段的第一个P在
> 1,其他都是
≡(1,1,1)
Key-Value pooling
与查询池不同,更改键K和值V张量的序列长度不会更改输出序列长度(时空分辨率),所以对于所有的K和V都执行了池化。上面说过,最后为了能够执行计算,K和V池化后的各个维度必须一致,所以本文默认情况下,取
Skip connections
由于通道尺寸和序列长度发生变化,对skip connection 进行pool 以适应其两端的尺寸不匹配。由图3可以看出,MHPA通过使用查询池操作符来处理这种不匹配
3.2代码实现
MultiHeadedAttention
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)?attention_pool
def attention_pool(tensor, pool, thw_shape, has_cls_embed=True, norm=None):
if pool is None:
return tensor, thw_shape
tensor_dim = tensor.ndim
if tensor_dim == 4:
pass
elif tensor_dim == 3:
tensor = tensor.unsqueeze(1)
else:
raise NotImplementedError(f"Unsupported input dimension {tensor.shape}")
if has_cls_embed:
cls_tok, tensor = tensor[:, :, :1, :], tensor[:, :, 1:, :]
B, N, L, C = tensor.shape
T, H, W = thw_shape
tensor = (
tensor.reshape(B * N, T, H, W, C).permute(0, 4, 1, 2, 3).contiguous()
)
tensor = pool(tensor)
thw_shape = [tensor.shape[2], tensor.shape[3], tensor.shape[4]]
L_pooled = tensor.shape[2] * tensor.shape[3] * tensor.shape[4]
tensor = tensor.reshape(B, N, C, L_pooled).transpose(2, 3)
if has_cls_embed:
tensor = torch.cat((cls_tok, tensor), dim=2)
if norm is not None:
tensor = norm(tensor)
# Assert tensor_dim in [3, 4]
if tensor_dim == 4:
pass
else: # tensor_dim == 3:
tensor = tensor.squeeze(1)
return tensor, thw_shapeMlp
class Mlp(nn.Module):
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop_rate=0.0,
):
super().__init__()
self.drop_rate = drop_rate
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
if self.drop_rate > 0.0:
self.drop = nn.Dropout(drop_rate)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
if self.drop_rate > 0.0:
x = self.drop(x)
x = self.fc2(x)
if self.drop_rate > 0.0:
x = self.drop(x)
return xClassificationHead?
class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))MultiScaleAttention?
class MultiScaleAttention(nn.Module):
def __init__(
self,
dim,
dim_out,
input_size,
num_heads=8,
qkv_bias=False,
drop_rate=0.0,
kernel_q=(1, 1, 1),
kernel_kv=(1, 1, 1),
stride_q=(1, 1, 1),
stride_kv=(1, 1, 1),
norm_layer=nn.LayerNorm,
has_cls_embed=True,
# Options include `conv`, `avg`, and `max`.
mode="conv",
# If True, perform pool before projection.
pool_first=False,
rel_pos_spatial=False,
rel_pos_temporal=False,
rel_pos_zero_init=False,
residual_pooling=False,
separate_qkv=False,
):
super().__init__()
self.pool_first = pool_first
self.separate_qkv = separate_qkv
self.drop_rate = drop_rate
self.num_heads = num_heads
self.dim_out = dim_out
head_dim = dim_out // num_heads
self.scale = head_dim**-0.5
self.has_cls_embed = has_cls_embed
self.mode = mode
padding_q = [int(q // 2) for q in kernel_q]
padding_kv = [int(kv // 2) for kv in kernel_kv]
if pool_first or separate_qkv:
self.q = nn.Linear(dim, dim_out, bias=qkv_bias)
self.k = nn.Linear(dim, dim_out, bias=qkv_bias)
self.v = nn.Linear(dim, dim_out, bias=qkv_bias)
else:
self.qkv = nn.Linear(dim, dim_out * 3, bias=qkv_bias)
self.proj = nn.Linear(dim_out, dim_out)
if drop_rate > 0.0:
self.proj_drop = nn.Dropout(drop_rate)
# Skip pooling with kernel and stride size of (1, 1, 1).
if numpy.prod(kernel_q) == 1 and numpy.prod(stride_q) == 1:
kernel_q = ()
if numpy.prod(kernel_kv) == 1 and numpy.prod(stride_kv) == 1:
kernel_kv = ()
if mode in ("avg", "max"):
pool_op = nn.MaxPool3d if mode == "max" else nn.AvgPool3d
self.pool_q = (
pool_op(kernel_q, stride_q, padding_q, ceil_mode=False)
if len(kernel_q) > 0
else None
)
self.pool_k = (
pool_op(kernel_kv, stride_kv, padding_kv, ceil_mode=False)
if len(kernel_kv) > 0
else None
)
self.pool_v = (
pool_op(kernel_kv, stride_kv, padding_kv, ceil_mode=False)
if len(kernel_kv) > 0
else None
)
elif mode == "conv" or mode == "conv_unshared":
if pool_first:
dim_conv = dim // num_heads if mode == "conv" else dim
else:
dim_conv = dim_out // num_heads if mode == "conv" else dim_out
self.pool_q = (
nn.Conv3d(
dim_conv,
dim_conv,
kernel_q,
stride=stride_q,
padding=padding_q,
groups=dim_conv,
bias=False,
)
if len(kernel_q) > 0
else None
)
self.norm_q = norm_layer(dim_conv) if len(kernel_q) > 0 else None
self.pool_k = (
nn.Conv3d(
dim_conv,
dim_conv,
kernel_kv,
stride=stride_kv,
padding=padding_kv,
groups=dim_conv,
bias=False,
)
if len(kernel_kv) > 0
else None
)
self.norm_k = norm_layer(dim_conv) if len(kernel_kv) > 0 else None
self.pool_v = (
nn.Conv3d(
dim_conv,
dim_conv,
kernel_kv,
stride=stride_kv,
padding=padding_kv,
groups=dim_conv,
bias=False,
)
if len(kernel_kv) > 0
else None
)
self.norm_v = norm_layer(dim_conv) if len(kernel_kv) > 0 else None
else:
raise NotImplementedError(f"Unsupported model {mode}")
self.rel_pos_spatial = rel_pos_spatial
self.rel_pos_temporal = rel_pos_temporal
if self.rel_pos_spatial:
assert input_size[1] == input_size[2]
size = input_size[1]
q_size = size // stride_q[1] if len(stride_q) > 0 else size
kv_size = size // stride_kv[1] if len(stride_kv) > 0 else size
rel_sp_dim = 2 * max(q_size, kv_size) - 1
self.rel_pos_h = nn.Parameter(torch.zeros(rel_sp_dim, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(rel_sp_dim, head_dim))
if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_h, std=0.02)
trunc_normal_(self.rel_pos_w, std=0.02)
if self.rel_pos_temporal:
self.rel_pos_t = nn.Parameter(
torch.zeros(2 * input_size[0] - 1, head_dim)
)
if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_t, std=0.02)
self.residual_pooling = residual_pooling
def forward(self, x, thw_shape):
B, N, _ = x.shape
if self.pool_first:
if self.mode == "conv_unshared":
fold_dim = 1
else:
fold_dim = self.num_heads
x = x.reshape(B, N, fold_dim, -1).permute(0, 2, 1, 3)
q = k = v = x
else:
assert self.mode != "conv_unshared"
if not self.separate_qkv:
qkv = (
self.qkv(x)
.reshape(B, N, 3, self.num_heads, -1)
.permute(2, 0, 3, 1, 4)
)
q, k, v = qkv[0], qkv[1], qkv[2]
else:
q = k = v = x
q = (
self.q(q)
.reshape(B, N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
k = (
self.k(k)
.reshape(B, N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
v = (
self.v(v)
.reshape(B, N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
q, q_shape = attention_pool(
q,
self.pool_q,
thw_shape,
has_cls_embed=self.has_cls_embed,
norm=self.norm_q if hasattr(self, "norm_q") else None,
)
k, k_shape = attention_pool(
k,
self.pool_k,
thw_shape,
has_cls_embed=self.has_cls_embed,
norm=self.norm_k if hasattr(self, "norm_k") else None,
)
v, v_shape = attention_pool(
v,
self.pool_v,
thw_shape,
has_cls_embed=self.has_cls_embed,
norm=self.norm_v if hasattr(self, "norm_v") else None,
)
if self.pool_first:
q_N = (
numpy.prod(q_shape) + 1
if self.has_cls_embed
else numpy.prod(q_shape)
)
k_N = (
numpy.prod(k_shape) + 1
if self.has_cls_embed
else numpy.prod(k_shape)
)
v_N = (
numpy.prod(v_shape) + 1
if self.has_cls_embed
else numpy.prod(v_shape)
)
q = q.permute(0, 2, 1, 3).reshape(B, q_N, -1)
q = (
self.q(q)
.reshape(B, q_N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
v = v.permute(0, 2, 1, 3).reshape(B, v_N, -1)
v = (
self.v(v)
.reshape(B, v_N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
k = k.permute(0, 2, 1, 3).reshape(B, k_N, -1)
k = (
self.k(k)
.reshape(B, k_N, self.num_heads, -1)
.permute(0, 2, 1, 3)
)
N = q.shape[2]
attn = (q * self.scale) @ k.transpose(-2, -1)
if self.rel_pos_spatial:
attn = cal_rel_pos_spatial(
attn,
q,
k,
self.has_cls_embed,
q_shape,
k_shape,
self.rel_pos_h,
self.rel_pos_w,
)
if self.rel_pos_temporal:
attn = cal_rel_pos_temporal(
attn,
q,
self.has_cls_embed,
q_shape,
k_shape,
self.rel_pos_t,
)
attn = attn.softmax(dim=-1)
x = attn @ v
if self.residual_pooling:
if self.has_cls_embed:
x[:, :, 1:, :] += q[:, :, 1:, :]
else:
x = x + q
x = x.transpose(1, 2).reshape(B, -1, self.dim_out)
x = self.proj(x)
if self.drop_rate > 0.0:
x = self.proj_drop(x)
return x, q_shape参考:
Multiscale Vision Transformers 论文阅读
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!