时间序列预测 — CNN-LSTM实现多变量多步光伏预测(Tensorflow)
目录
?专栏链接:https://blog.csdn.net/qq_41921826/category_12495091.html
1?数据处理
1.1 导入库文件
import scipy
import pandas as pd
import numpy as np
import math
import datetime
from matplotlib import pyplot as plt
# 导入深度学习框架tensorflow
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential, layers, callbacks
from tensorflow.keras.layers import Input, Reshape,Conv2D, MaxPooling2D, LSTM, Dense, Dropout, Flatten, Reshape
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore') plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
plt.rcParams.update({'font.size':18}) #统一字体字号1.2 导入数据集
实验数据集采用数据集6:澳大利亚电力负荷与价格预测数据(下载链接),数据集包括包括数据集包括日期、小时、干球温度、露点温度、湿球温度、湿度、电价、电力负荷特征,时间间隔30min。选取两年的数据进行实验,对数据进行可视化:
# 导入数据
data_raw = pd.read_excel("E:\\课题\\08数据集\\澳大利亚电力负荷与价格预测数据\\澳大利亚电力负荷与价格预测数据.xlsx")
data_raw = data_raw[-365*24*2*2-1:-1]
data_rawfrom itertools import cycle
# 可视化数据
def visualize_data(data, row, col):
cycol = cycle('bgrcmk')
cols = list(data.columns)
fig, axes = plt.subplots(row, col, figsize=(16, 4))
fig.tight_layout()
if row == 1 and col == 1: # 处理只有1行1列的情况
axes = [axes] # 转换为列表,方便统一处理
for i, ax in enumerate(axes.flat):
if i < len(cols):
ax.plot(data.iloc[:,i], c=next(cycol))
ax.set_title(cols[i])
else:
ax.axis('off') # 如果数据列数小于子图数量,关闭多余的子图
plt.subplots_adjust(hspace=0.6)
plt.show()
visualize_data(data_raw.iloc[:,2:], 2, 3)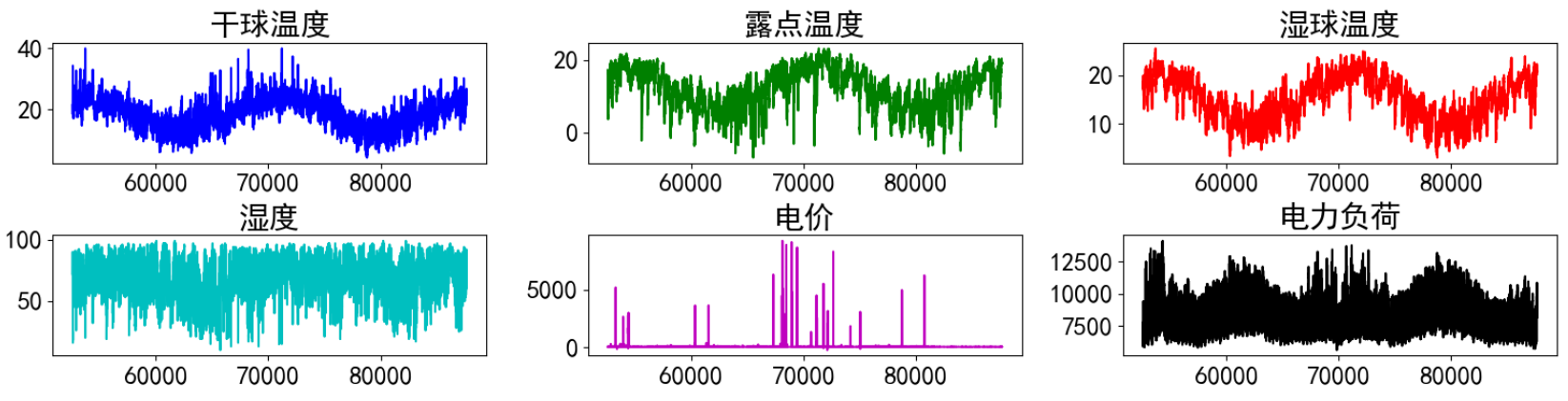 ??
??
?单独查看部分功率数据,发现有较强的规律性。

??
1.3 缺失值分析
首先查看数据的信息,发现并没有缺失值
data_raw.info()
??进一步统计缺失值,通过统计数据可以看到,数据比较完整,不存在缺失值。其他异常值和数据处理可以自行处理。
data_raw.isnull().sum()
2?构造训练数据
选取数据集,去掉时间特征
data = data_raw.iloc[:,2:].values构造训练数据,也是真正预测未来的关键。首先设置预测的timesteps时间步、predict_steps预测的步长(预测的步长应该比总的预测步长小),length总的预测步长,参数可以根据需要更改。
timesteps = 48*7 #构造x,为96*5个数据,表示每次用前96*5个数据作为一段
predict_steps = 48 #构造y,为96个数据,表示用后96个数据作为一段
length = 48 #预测多步,预测96个数据
feature_num = 5 #特征的数量通过前5天的timesteps个数据预测后一天的predict_steps个数据,需要对数据集进行滚动划分(也就是前timesteps行的特征和后predict_steps行的标签训练,后面预测时就可通过timesteps行特征预测未来的predict_steps个标签)。因为是多变量,特征和标签分开划分。
# 构造数据集,用于真正预测未来数据
# 整体的思路也就是,前面通过前timesteps个数据训练后面的predict_steps个未来数据
# 预测时取出前timesteps个数据预测未来的predict_steps个未来数据。
# 单变量划分只需对单个变量划分,多变量划分特征和标签分开划分
def create_dataset(datasetx, datasety=None, timesteps=36, predict_size=6):
datax = [] # 构造x
datay = [] # 构造y
for each in range(len(datasetx) - timesteps - predict_size):
x = datasetx[each:each + timesteps]
# 判断是否是单变量分解还是多变量分解
if datasety is not None:
y = datasety[each + timesteps:each + timesteps + predict_size]
else:
y = datasetx[each + timesteps:each + timesteps + predict_size, 0]
datax.append(x)
datay.append(y)
return datax, datay
??数据处理前,需要对数据进行归一化,按照上面的方法划分数据,这里返回划分的数据和归一化模型,因为是多变量,特征和标签分开归一化,不然后面归一化会有信息泄露的问题。函数的定义如下:
# 数据归一化操作
def data_scaler(datax, datay=None, timesteps=36, predict_steps=6):
# 数据归一化操作
scaler1 = MinMaxScaler(feature_range=(0, 1))
datax = scaler1.fit_transform(datax)
# 用前面的数据进行训练,留最后的数据进行预测
# 判断是否是单变量分解还是多变量分解
if datay is not None:
scaler2 = MinMaxScaler(feature_range=(0, 1))
datay = scaler2.fit_transform(datay)
trainx, trainy = create_dataset(datax, datay, timesteps, predict_steps)
trainx = np.array(trainx)
trainy = np.array(trainy)
return trainx, trainy, scaler1, scaler2
else:
trainx, trainy = create_dataset(datax, timesteps=timesteps, predict_size=predict_steps)
trainx = np.array(trainx)
trainy = np.array(trainy)
return trainx, trainy, scaler1, None然后对数据按照上面的函数进行划分和归一化。通过前5天的96*5数据预测后一天的96个数据,需要对数据集进行滚动划分(也就是前96*5行的特征和后96行的标签训练,后面预测时就可通过96*5行特征预测未来的96个标签)
datax = data[:,:-1]
datay = data[:,-1].reshape(data.shape[0],1)
trainx, trainy, scaler1, scaler2 = data_scaler(datax, datay)?3?模型训练
3.1 CNN-LSTM网络?
CNN-LSTM 是一种结合了 CNN 特征提取能力与 LSTM 对时间序列长期记忆能力的混合神经网络。
CNN 主要由四个层级组成, 分别为输入层、 卷积层、 激活层(Relu 函数)和池化层。 每一层都会将数据处理之后送到下一层, 其中最重要的是卷积层, 这个层级起到的作用是将特征数据进行卷积计算, 将计算好的结果传到激活层, 激活函数对数据进行筛选。最后一层是 LSTM 层, 这一层是根据 CNN 处理后的特征数据,对其模型进行进一步的维度修偏, 权重修正等工作, 为下一步输出精度较高的预测值做好准备, 在 LSTM 训练的过程中, 由于其神经网络内部包括了输入、 遗忘和输出门, 通常的做法是通过增减遗忘门和输入门的个数, 来控制算法的精度。
?

来源:基于改进的 CNN-LSTM 短期风功率预测方法研究
对于输入到 CNN-LSTM 的数据,首先,经过 CNN 的卷积层对局部特征进行提取,将提取后的特征向量传递到池化层进行特征向量的下采样和数据体量的压缩。然后,将经过卷积层和池化层处理后的特征向量经过一个扁平层转化成一维向量输入到 LSTM 中, 每一层 LSTM 后加一个随机失活层以防止模型过拟合。
?
3.2 模型训练
首先搭建模型的常规操作,然后使用训练数据trainx和trainy进行训练,进行50个epochs的训练,每个batch包含64个样本。此时input_shape划分数据集时每个x的形状。(建议使用GPU进行训练,因为本人电脑性能有限,建议增加epochs值)

# CNN_LSTM模型
def CNN_LSTM_model_train(trainx, trainy, timesteps, feature_num, predict_steps):
# 调用GPU加速
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# 定义CNN-LSTM模型
start_time = datetime.datetime.now()
model = Sequential()
model.add(Input((timesteps, feature_num)))
model.add(Reshape((timesteps, feature_num, 1)))
model.add(Conv2D(filters=64,
kernel_size=3,
strides=1,
padding="same",
activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=1, padding="same"))
model.add(Dropout(0.3))
model.add(Reshape((timesteps, -1)))
model.add(LSTM(128, return_sequences=True, dropout=0.2)) # 添加dropout层
model.add(LSTM(64, return_sequences=False, dropout=0.2)) # 添加dropout层
model.add(Dense(64, activation="relu")) # 增加Dense层节点数量
model.add(Dense(predict_steps))
model.compile(loss="mean_squared_error", optimizer="adam", metrics=['mse'])
model.summary()
# 模型训练
model.fit(trainx, trainy, epochs=50, batch_size=128)
end_time = datetime.datetime.now()
running_time = end_time - start_time
# 保存模型
model.save('CNN_LSTM_model.h5')
# 返回构建好的模型
return model
对划分的数据进行训练?
model = CNN_LSTM_model_train(trainx, trainy, timesteps, feature_num, predict_steps)4 模型预测
首先加载训练好后的模型
# 加载模型
from tensorflow.keras.models import load_model
model = load_model('BiLSTM_model.h5')准备好需要预测的数据,训练时保留了6天的数据,将前5天的数据作为输入预测,将预测的结果和最后一天的真实值进行比较。
y_true = datay[-timesteps-predict_steps:-timesteps]
x_pred = datax[-timesteps:]预测并计算误差,并进行可视化,将这些步骤封装为函数。???????
# 预测并计算误差和可视化
def predict_and_plot(x, y_true, model, scaler, timesteps):
# 变换输入x格式,适应LSTM模型
predict_x = np.reshape(x, (1, timesteps, feature_num))
# 预测
predict_y = model.predict(predict_x)
predict_y = scaler.inverse_transform(predict_y)
y_predict = []
y_predict.extend(predict_y[0])
# 计算误差
r2 = r2_score(y_true, y_predict)
rmse = mean_squared_error(y_true, y_predict, squared=False)
mae = mean_absolute_error(y_true, y_predict)
mape = mean_absolute_percentage_error(y_true, y_predict)
print("r2: %.2f\nrmse: %.2f\nmae: %.2f\nmape: %.2f" % (r2, rmse, mae, mape))
# 预测结果可视化
cycol = cycle('bgrcmk')
plt.figure(dpi=100, figsize=(14, 5))
plt.plot(y_true, c=next(cycol), markevery=5)
plt.plot(y_predict, c=next(cycol), markevery=5)
plt.legend(['y_true', 'y_predict'])
plt.xlabel('时间')
plt.ylabel('功率(kW)')
plt.show()
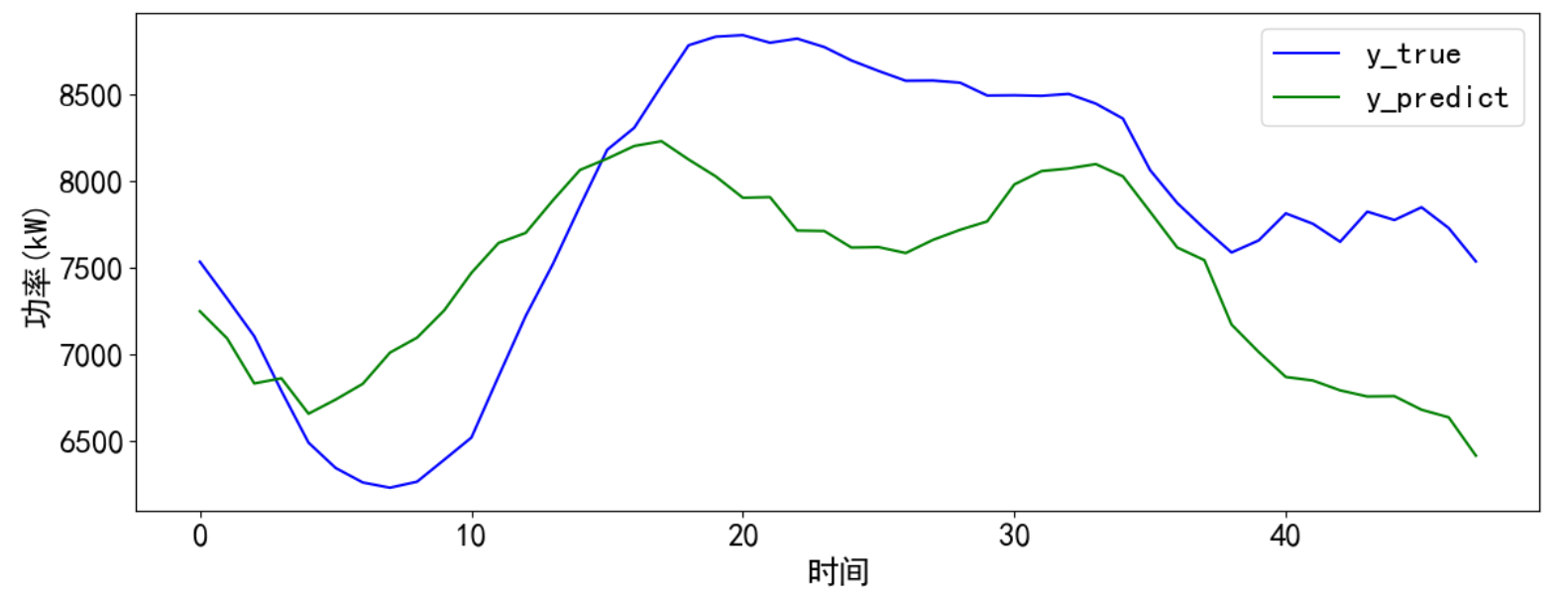
return y_predicty_predict = predict_and_plot(x_pred, y_true, model, scaler2, timesteps)最后得到可视化结果和计算的误差,可以通过调参和数据处理进一步提升模型预测效果。
- r2: 0.19
- ??rmse: 725.34
- mae: 640.73
- mape: 0.08
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!