聊聊Java中的常用类String
String、StringBuffer、StringBuilder 的区别
从可变性分析
String不可变。StringBuffer、StringBuilder都继承自AbstractStringBuilder,两者的底层的数组value并没有使用private和final修饰,所以是可变的。
AbstractStringBuilder 源码如下所示
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
//确定数组空间是否充足,若不充足则动态扩容
ensureCapacityInternal(count + len);
//这里会进行数组拷贝将新字符串存到数组中
str.getChars(0, len, value, count);
count += len;
return this;
}
}
从线程安全性考虑
String类是常量线程安全。StringBuilder线程不安全。StringBuffer线程安全。
从性能上分析
String是常量每次添加字符串都会将引用指向新的字符串。StringBuilder非线程安全所以性能上相较于StringBuffer会快10%-15%。
三者使用场景建议
- 操作少量数据,
String即可 - 单线程操作大量字符串,建议使用
StringBuilder。 - 多线程用
StringBuffer。
为什么String 是不可变的?
从源码可以看到String底层是使用字符数组存储值的,之所以不可变是因为:
value私有且final也没有对外提供字符串操作的方法。- 类设置为
final,子类也无法继承该类对其进行修改。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
字符串拼接用“+” 的底层工作机制是什么?
如下所示代码
public class StringTest {
@Test
public void addTest() {
String s1 = "hello";
String s2 = "world";
String s3 = "guy";
String s4 = s1 + s2 + s3;
}
}
查看其字节码可以看到JVM为了避免大量常量创建,会将其进行优化,改用StringBuilder进行拼接后toString。
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
ALOAD 1
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 2
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 3
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ASTORE 4
但是在循环体内使用+=的情况下很可能造成性能灾难。
@Test
public void addTest2() {
String[] arr = {"hello", "world", "guys"};
String string = "";
for (int i = 0; i < arr.length; i++) {
string += arr[i];
}
}
可以看到在循环体内会不断创建StringBuilder进行拼接。
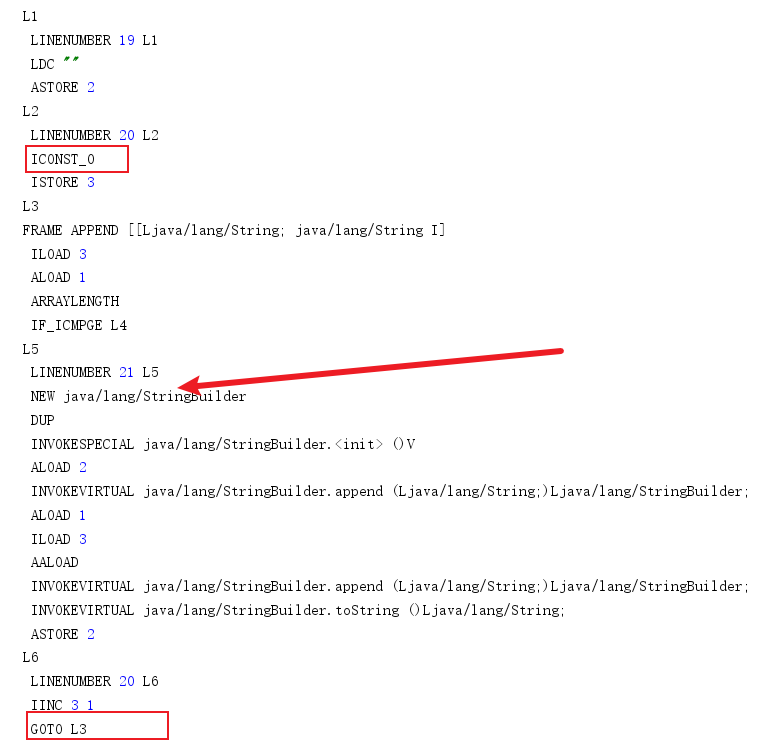
来看看我们手动创建StringBuilder 进行拼接和+=由JVM优化后的性能差距
@Test
public void addTest2() {
String[] arr = new String[1000];
for (int i = 0; i < arr.length; i++) {
arr[i] = String.valueOf(i);
}
long start = System.currentTimeMillis();
String string = "";
for (int i = 0; i < arr.length; i++) {
string += arr[i];
}
long end = System.currentTimeMillis();
System.out.println("使用+=耗时:" + (end - start));
start = System.currentTimeMillis();
StringBuilder builder =new StringBuilder();
for (int i = 0; i < arr.length; i++) {
builder.append(arr[i]);
}
end = System.currentTimeMillis();
System.out.println("使用StringBuilder耗时:" + (end - start));
}
输出结果,可以看到StringBuilder比+=快了将近6倍。
使用+=耗时:6
使用StringBuilder耗时:1
String和Object的equals() 有什么区别
String对equals进行了重写,String比较的是字符串的值是否一致
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
而Object比较的则是两者的引用地址是否一致
public boolean equals(Object obj) {
return (this == obj);
}
字符串常量池是什么,它有什么用?
如下代码所示,Java会将字符串存放在方法区的字符串常量池,后续如有变量需要可以直接复用,关于字符串常量池后文会介绍。
@Test
public void stringConst(){
String s1="s";
String s2="s";
System.out.println(s1==s2);//true
}
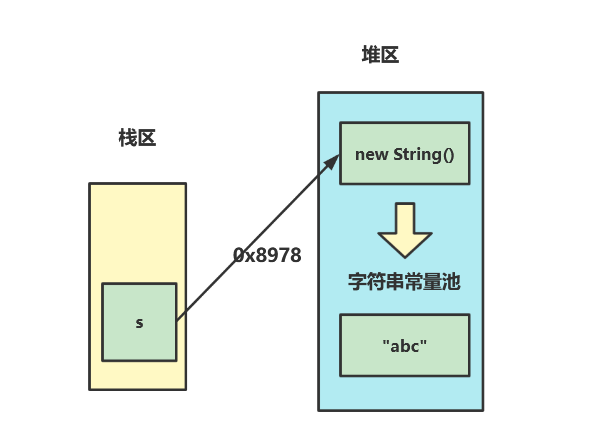
图解String s1 = new String(“abc”);
这段代码实际上会创建两个对象:
- 创建String对象s1指向堆区的String对象
- 在字符串常量池中创建字符串abc
intern 方法是什么?有什么用?
该方法会将字符串值存放到字符串常量池中,并返回该引用。注意如果常量池存在则直接返回引用。若不存在才会创建并返回引用。
常量intern
可以看到下面这段代码,调用intern 的字符串和常量池的对象==比较返回的是true
@Test
public void internTest() {
String s1 = "s";
String s2 = s1.intern();
String s3 = new String("s");
String s4 = s3.intern();
System.out.println(s1 == s2);//true
System.out.println(s3 == s4);//false
System.out.println(s1 == s4);//true
}
常量+=intern
再补充一个神奇的现象,常量字符串进行+=时会被JVM在编译自动优化,例如String s1="a"+"b"实际上会被优化为String s1="ab",所以下面这段intern就会出现下面的结果:
原因也很简单:
对于编译期可以确定值的字符串,也就是常量字符串 ,JVM 会将其存入字符串常量池。并且,字符串常量拼接得到的字符串常量在编译阶段就已经被存放字符串常量池,这个得益于编译器的优化。 在编译过程中,Javac 编译器会进行一个叫做 常量折叠(Constant Folding) 的代码优化。
这里说到一个叫常量折叠的概念,常量折叠就是将常量表达式计算求值,并用求得的值来替换表达式,然后放到常量表中的一种机制。
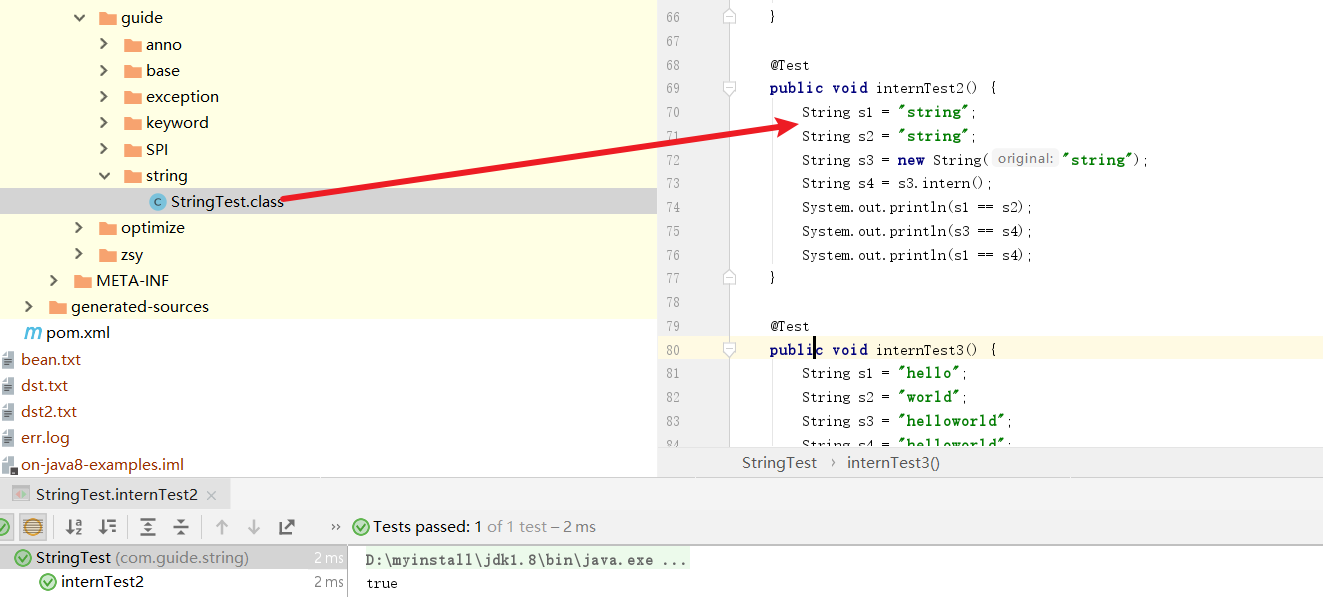
@Test
public void internTest2() {
String s1 = "s"+"tring";
String s2 = "string";
String s3 = new String("string");
String s4 = s3.intern();
System.out.println(s1 == s2);//true
System.out.println(s3 == s4);//false
System.out.println(s1 == s4);//true
}
这一点我们查看字节码文件就得以印证
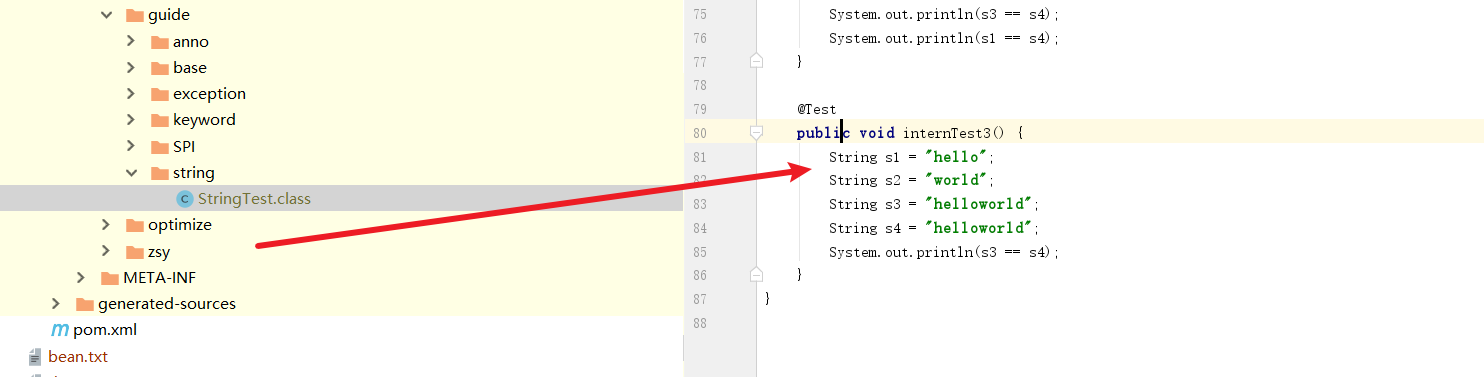
final+=的intern
final字符串会被JVM优化为常量,所以下面这段代码也会返回true
@Test
public void internTest3() {
final String s1 = "hello";
final String s2 = "world";
String s3 = s1 + s2;
String s4 = "helloworld";
System.out.println(s3 == s4);//true
}
查看字节码得以印证。
引用或者函数获取的+=
注意JVM不会对引用和方法这种动态变化的情况进行优化,所以下面这段代码就会返回false。
@Test
public void internTest3() {
final String s1 = "hello";
final String s2 = getStr();
String s3 = s1 + s2;
String s4 = "helloworld";
System.out.println(s3 == s4);//false
}
private String getStr() {
return "world";
}
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!