目前进度记录
2023-12-13 18:45:48
目前已经把之前记录的方法都实现了,目前的主函数可以写的更简单比如
int main(int argc, char* argv[])
{
KernelClass::create_kernel();
MPI_Init(&argc, &argv);
kernel().mpi_manager.init_mpi(argc, argv);
//创建种群
int group1 = kernel().conn_manger.create(2);
int group2 = kernel().conn_manger.create(2);
int group3 = kernel().conn_manger.create(1);
std::cout << "一共创建了" << kernel().conn_manger.get_neuron_size() << std::endl;
//种群之间的连接
SynapseParams s;
s.delay = 1.5;
s.weight = 0.2;
kernel().conn_manger.connect(group1, group2, 1.0);
kernel().conn_manger.connect(group2, group3, 1.0, s);
//进行图分区
kernel().conn_manger.partition_network();
//所有管理类的参数和变量的初始化
kernel().initialize();
//神经元和突触的实例化
kernel().conn_manger.generateSynapseAndNeuron();
//设置仿真的参数
double dt = 0.1; //时间戳
double sim_time = 20; //仿真时间(ms)
int slice = static_cast<int>(sim_time / kernel().conn_manger.get_min_delay());//总共要执行循环数
double current_time = 0;
Time clock; //模拟时钟,每个切片更新一次
int from_step = 0,to_step = kernel().conn_manger.get_min_delay();
//开始仿真
std::cout << "开始仿真" << std::endl;
MPI_Barrier(MPI_COMM_WORLD);
for (int timestep = 0; timestep < slice; timestep++)
{
if (kernel().mpi_manager.get_rank() == 0)
{
std::cout << "---------------------------------------" << std::endl;
}
//更新神经元
const std::vector< Neuron* >& local_nodes = kernel().conn_manger.get_local_nodes();
for (auto node : local_nodes)
{
(*node).update(clock, from_step, to_step);
}
//设置目前的时间
kernel().sim_manager.set_slice_origin(clock);
// 传递脉冲
kernel().event_manager.gather_spike_data();
//管理时间
clock.advance_time(kernel().conn_manger.get_min_delay());
//更新双缓冲
kernel().event_manager.update_moduli();
}
std::cout << "结束仿真" << std::endl;
MPI_Finalize();
kernel().finalize();
KernelClass::delete_kernel();
}运行结果如下
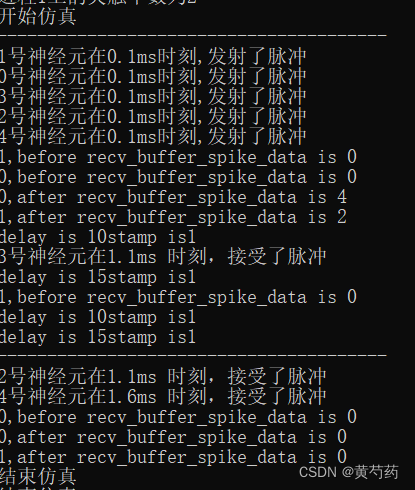
我优化了很多的方面。最大的优化在脉冲传输阶段
我使用了
// key代表神经元的gid,value代表需要通信的进程号
std::unordered_map<int, std::set<int>> comm_proccess;?这样的数据结构,使用set为了避免重复的脉冲发送,使用这个数据结构的好处是,可以不在使用全局的邻接表,减少了内存的占用。而且减少了代码量。目前基本上已经完成了大部分的基础工作,接下来我希望能够在我代码中实现STDP的机制。
文章来源:https://blog.csdn.net/qq_39591612/article/details/134977169
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!