通用的AGI 安全风险
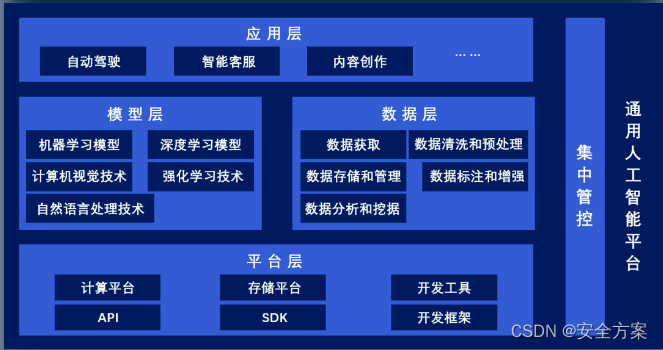
传统安全风险
-
平台基础设施安全风险
-
模型与数据层安全风险
-
应用层安全风险
平台基础设施安全风险
(1)物理攻击:机房管控不到位
(2)网络攻击
(3)计算环境:自身安全漏洞;未进行严格网络隔离
模型与数据层安全风险
(1)供应链攻击
(2)漏洞攻击
(3)API 安全问题:API 的开放增加对外暴露面,导致更多外部威胁。
(4)运维安全问题
应用层安全风险
通用人工智能应用是基于人工智能底层服务提供的 API,以实现在各种实际场景下的落地。
除了一些大企业、研究机构具备人工智能全栈能力外,更多的企业依赖别人提供的底层服务能力来开发人工智能应用,从而面临供应链攻击、自身应用安全架构不合理、应用层漏洞以及各种合规风险。
数据泄露和滥用风险
-
模型和训练数据保护难度提升
-
训练数据泄露隐私、机密信息
-
训练数据滥用,输出不良信息
模型和训练数据保护难度提升
(1)暴露面受攻击风险
基于推广和使用的考虑,往往将大模型部署在云端,并以 API 的方式将相关功能开放给其他用户,以实现模型即服务(MaaS),这些算法模型、训练数据势必面临着来自互联网恶意用户的攻击、窃取的风险。
(2)逆向攻击风险
通过模拟大量输入请求得到大量模型输出,从而逆向还原模型功能,达到窃取模型或者训练数据的目的。
训练数据泄露隐私、机密信息
(1)信息采集范围更广
在传统互联网应用当中,应用方采集用户的手机号、姓名、性别、身份证号码等个人信息以及操作记录、消费记录等行为信息,而通用人工智能应用除上述信息外,还广泛采集其他具有强个人属性的唯一生物特征信息,如声纹、虹膜、指纹等。
(2)AI自学习泄露风险
例如员工在办公环境中使用智能问答平台时,容易将公司的商业机密信息输入平台寻找答案,而平台在获取到该信息后又用于自学习过程,继而导致机密信息在其它场景下泄露。
训练数据滥用,输出不良信息
(1)内容审核不到位
目前全球互联网流量每秒已超 PB 级别,传统内容审核模式捉襟见肘。
(2)训练数据不合规风险
如果为了节省成本,对采集的数据不清洗或清洗不彻底,滥用、误用低质量、不完整的数据,导致输出不良信息,引发监管处罚。
模型可靠性风险
-
数据源污染
-
模型鲁棒性缺乏
-
算法的黑箱性
-
算法的偏见性
数据源污染
(1)训练数据不可控
例如采集数据未清洗、清洗不到位,或者直接使用不可信第三方数据源。
(2)训练数据特殊性,导致模型效率低下
由于大模型神经网络训练和推理需要使用高耗能的GPU和 TPU等加速硬件,如果用于训练数据是一些特殊样本,如海绵样本,可造成大模型性能极低。
(3)数据源中被植入毒化数据、后门数据
攻击者可在污染数据源中植入毒化数据、后门数据,从而导致大模型的决策偏离预期,甚至攻击者可在不破坏模型原来准确率的同时入侵模型,使大模型在后续应用过程中做出符合攻击者预期的决策。
模型鲁棒性缺乏
(1)训练数据无法覆盖所有情况
大模型训练需要完整的数据集,而训练数据往往无法覆盖到真实世界的各种异常场景,导致对于训练中未出现的、真实世界的各种异常输入,大模型无法做出准确的判断与决策。
(2)攻击者添加干扰噪声
攻击者可在输入样本中添加细微到人眼无法识别的干扰噪声,从而在不引起注意的情况下,导致系统做出偏离预期的错误决策。
(3)攻击者输入伪造信息
攻击者伪造具备个体唯一性特征的信息(指纹、虹膜、面容等),并作为智能身份认证系统的输入,实现伪造攻击。
算法的黑箱性
(1)算法结构隐层
AGI 核心基础为深度学习,其算法结构存在多个隐层,导致输入与输出之间存在人类难以理解的因果关系、逻辑关系。
(2)算法模型自适应、自学习性等
具有自适应、自学习等特性,复杂程度超过人类大脑理解范畴,造成不可解释性,给人工智能安全事件的溯源分析带来了严峻挑战。
算法的偏见性
(1)本身无判断能力
人工智能模型算法追求的是统计的最优解,本身并不具备客观公正的判断能力。
(2)价值判断具有地域、文化性
模型对于价值的判断完全依赖于训练数据,而伦理、道德、政治等复杂问题本身具有地域、文化特性。
滥用、误用风险
-
危害社会稳定
-
降低企业创造积极性
-
侵犯个人基本权益
-
危害网络空间安全
危害社会稳定
(1)生成虚假信息、负面信息
混淆视听、左右公众舆论,甚至改变热点事件、政治事件的舆论走向,给社会带来不稳定因素。
(2)深度伪造
制作虚假负面音频、视频等信息,严重扰乱社会正常秩序,并可用于欺诈、诈骗等违法犯罪活动。
降低企业创造积极性
部分大模型的训练数据采集自公开数据,再加上版权保护法律的普遍滞后,新的人工智能创造物未得到法律有力保护,将严重影响企业投入人工智能创造的积极性。
侵犯个人基本权益
(1)个人隐私权益被侵犯
各种人工智能应用使用场景并未得到严格的规范与限制,滥用人工智能技术大量采集用户的隐私信息,如指纹、人脸、虹膜等信息。
(2)个人人格尊严被侵犯
创建虚假人工智能聊天机器人,用于进行网络欺诈或社交工程攻击,获取个人敏感信息或诱导用户进行不恰当的行为。
(3)个人基本权益被侵犯
大模型设计、训练之初误用或滥用包含非客观公正、带歧视性的训练数据,大模型的偏见性输出很有可能给用户带来情感上的伤害。
危害网络空间安全
(1)被广泛应用于网络攻击各个环节
例如,ChatGPT 可用于快速收集目标资产信息,生成并发送大量钓鱼邮件,也能基于目标资产指纹快速发现 NDay 漏洞,甚至可以通过扫描开源代码、泄露的代码自动检测到 0Day 漏。
(2)自动构建漏洞利用代码
基于大规模语言的预训练模型还能根据漏洞原理自动构建漏洞利用代码,从而实现快速入侵目标系统。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!