机器学习笔记(一)从波士顿房价预测开始,梯度下降
从波士顿房价开始
目标
其实这一章节比较简单,主要是概念,首先在波士顿房价这个问题中,我们假设了一组线性关系,也就是如图所示
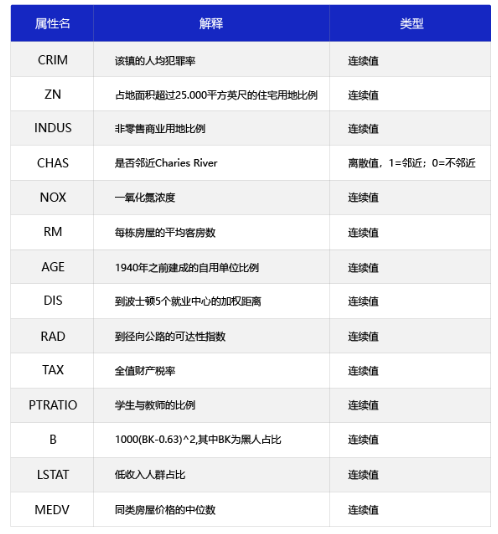
我们假定结果房价和这些参数之间有线性关系,即:
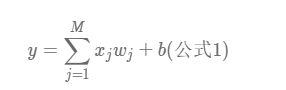
然后我们假定这个函数的损失函数为均方差,即:
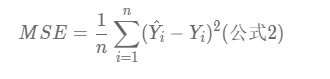
那么就是说,我们现在是已知y和x,来求使得这个损失函数Loss最小化的一个w和b的组合
读取数据
点击查看代码def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值
maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
读取数据这里主要需要注意两点,就是对数据进行归一化。所谓归一化就是将指定变量按照其在整个数据集中的上下限,投影出一个0-1之间的值,并以此来作为计算的标准。这样做的好处是方便计算,而且后面能更好地评估值的影响。
还有一件事就是划分测试集和训练集,这里划分的比例是0.8,不过反正没用这个。
前向计算
什么叫前向计算呢?其实就是一个算出预测值的过程。我们由总的公式
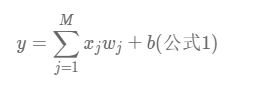
我们取一个数据切片xj向量,然后随便取w和b,然后获得的结果就是预测值z,即:
点击查看代码class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
损失函数
为什么要计算这个预测值呢?因为我们需要前向计算获得这个预测值,然后再进行损失函数的计算,用以评估这个预测值的结果好坏,即:
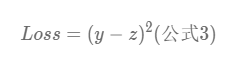
当然了,这里只是算了一组的预测值,我们当然是希望所有数据得到的损失函数的平均数,如图:
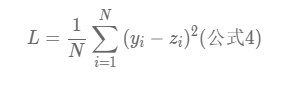
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print('loss:', loss)
计算梯度、梯度下降
什么是梯度?其实也很好理解,某个变量的梯度就是 : 预测值在这个变量上的偏导。之所以这么做是为了能通过梯度下降法寻找到极小值。
一般的做法是每次取w都令w = w -
- step
画一个简单的图示:
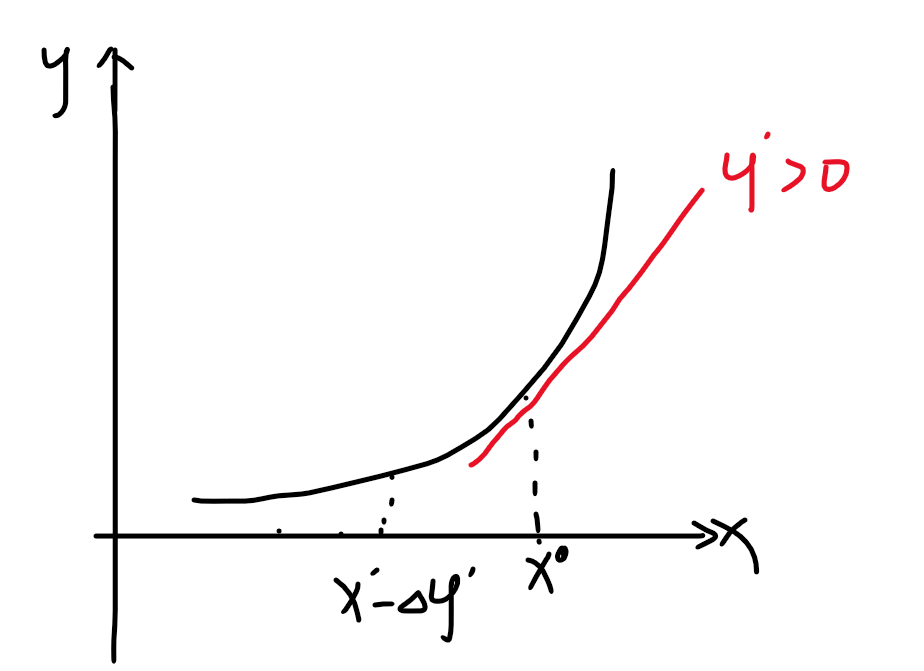
在x’处的偏导大于0时,x-deta * y’会偏向极小值
同理
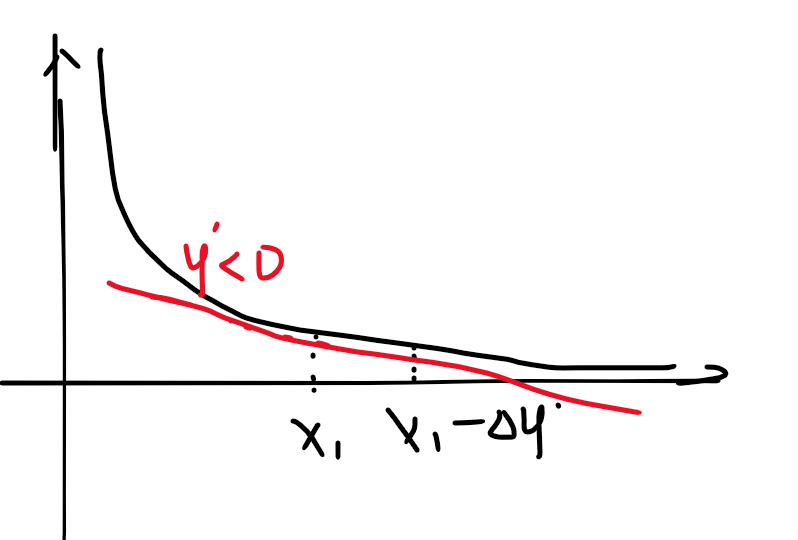
在x’处的偏导小于0时,x-deta * y’会偏向极小值
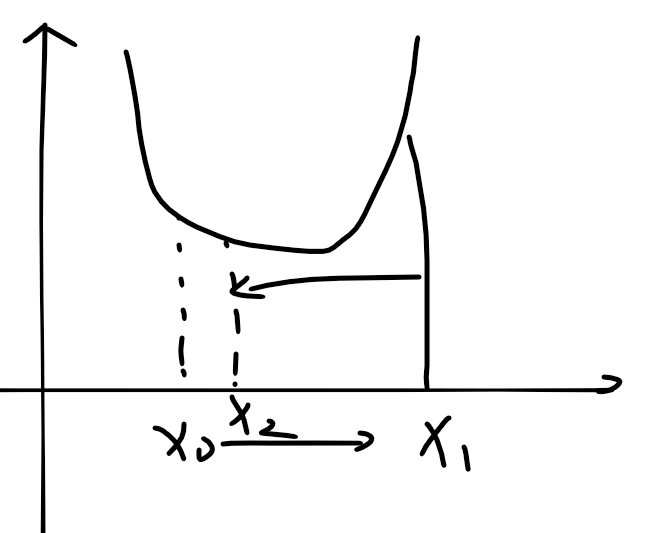
假设有一个极小值,那么这个梯度下降法就会让我们的这个x值逐渐移动到极小值附近停下。
这里需要注意一个问题,就是当我们的步长取得太小的话,那么迭代的次数就会过多,但是如果步长取得太大,就会导致迭代震荡,我们的x越来越往极小值外部偏,当然了会在某一个范围内稳定下来。
我们在计算梯度的时候,也就是在计算偏导,对于此题我们可以尝试计算一下:

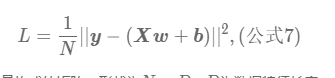
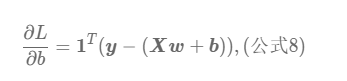
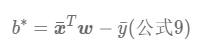
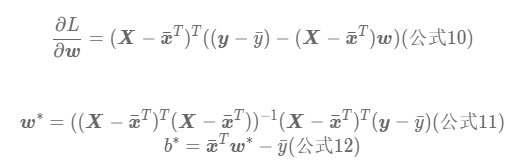
综上我们这里就计算出来L关于b和L关于w 的偏导数,即
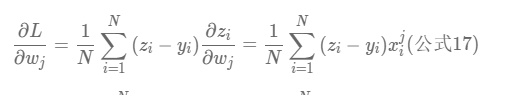
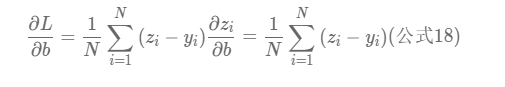
那么我们就可以在运算的过程中逐渐逐行的获得每一个wj组合的偏导,并让wj按照梯度下降的方式朝着L越来越小的方向发展
对此我们对类Network做出修改,如下:
点击查看代码class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
#此处进行对于x值前向计算得到的预测值
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
#此处进行损失损失函数的计算
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
#此处进行对于当前给定的w,x,y处的梯度计算
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
#此处用于进行梯度下降偏移
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
#此处进行实际训练,就是让所有数据按照梯度下降方向偏移直到结果
def train(self, x, y, iterations=100, eta=0.01):
losses = []
for i in range(iterations):
z = self.forward(x)
L = self.loss(z, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(L)
if (i+1) % 10 == 0:
print('iter {}, loss {}'.format(i, L))
return losses
随机梯度下降
在搞懂了什么时梯度下降了之后,我们为了提升效率,就需要寻找一些优化方式,比较简单的方式就是随机梯度下降。
所谓的随机梯度下降也很好理解,就是对于波士顿房价预测这种线性关系比较明显的模型而言,我们往往不需要data那么大的数据量,而是可能几十行就可以解出一个效果比较好的解了,一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD)
最终整理以下代码,就是这样:
点击查看代码import numpy as np
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
#np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z-y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z-y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epochs, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epochs):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epochs=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
小结:
我们在波士顿房价预测方案中,实际上做了三件事:
- 构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
- 随机选择初始点,建立梯度的计算方法和参数更新方式。
- 从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
问题一:样本归一化:预测时的样本数据同样也需要归一化,但使用训练样本的均值和极值计算,这是为什么?
可以从三个角度理解:众所周知,我们的数据集分为训练集和测试集,对于测试集的均值方差归一化,不能用测试集的均值和方差,而要用训练集的均值和方差,因为真实数据中很难得到其均值和方差。另外,网络参数是从训练集学习到的,也就是说,网络的参数尺度是与训练集的特征尺度一致性相关的,所以应该认为测试数据和训练数据的特征分布一致。最后,训练集数据相比测试集数据更多,用于近似表征全体数据的分布情况。
总结就是认为测试数据的分布应该与训练数据的分布一致。
例如样本A、样本B作为一批样本计算均值和方差,与样本A、样本C和样本D作为一批样本计算均值和方差,得到的结果一般来说是不同的。那么样本A的预测结果就会变得不确定,这对预测过程来说是不合理的。解决方法是在训练过程中将大量样本的均值和方差保存下来,预测时直接使用保存好的值而不再重新计算。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!