一文读懂AI计算平台库
随着人工智能产业的快速发展,用户对算力的需求也与日俱增,再加上CPU在支撑大规模高并发计算任务时的不尽人意,各厂商纷纷自研AI芯片和计算平台库,通过屏蔽底层AI芯片的细节,以及对上层应用提供友好的API和开发工具包,让用户无需关注芯片操作逻辑和内部结构,同时拥有CPU应用程序开发一样的体验。本文就主要讲述一些主流的AI计算平台库。
01 英伟达CUDA
如果说Windows成就了Intel在CPU领域的霸主地位,那Nvidia能够在GPU领域一骑绝尘的第一功臣非CUDA莫属。
从2007年发布CUDA的第一个版本,到2023年7月发布的CUDA Toolkit 12.2.1,全球的CUDA开发者在这十几年间增长了400万,基于CUDA开发的应用程序超过了3000 个,CUDA本身的下载量也达到惊人的 4000 万,再加上近两年人工智能大模型的爆发,Nvidia的市值也突破1万亿美金,成为全球第一个市值破万亿的芯片公司。
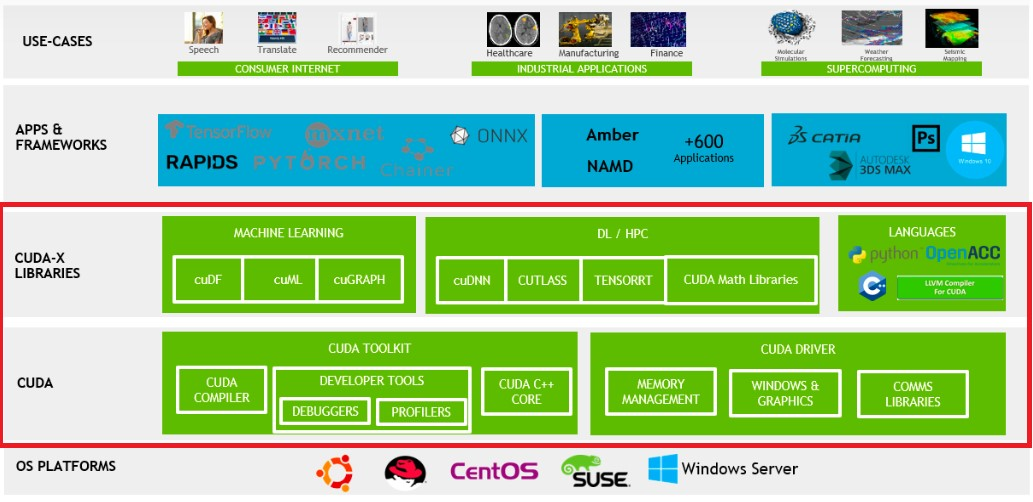
CUDA(Compute Unified Device Architecture)是Nvidia推出的一种通用并行计算架构,包括CUDA指令集架构(ISA)和GPU内部的并行计算引擎,将GPU的应用领域从图形计算拓展到通用计算.
程序员基于CUDA可以使用更高级的编程语言来编写用GPU运行的程序,而不需要去学习特定GPU的指令集系统,最新版本的CUDA是12.2,支持C、C++、Fortran、Python等多种编程语言。
在CUDA出现之前,程序员要开发基于Nvidia的GPU芯片的应用,需要熟悉芯片的操作逻辑和内部结构,再用汇编语言进行程序开发。CUDA发布之后,程序员只需要基于CUDA对外提供的API选择自己熟悉的语言开发程序,无需熟悉芯片的底层逻辑,大大降低了GPU程序员的开发门槛。
同时随着CUDA版本的不断更新,CUDA现在的开发生态已经非常丰富,不仅提供基础的编译、调试、性能分析与监控工具,还提供基础数学库、线性代数、深度学习等函数库,进一步加速了人工智能应用的开发周期。
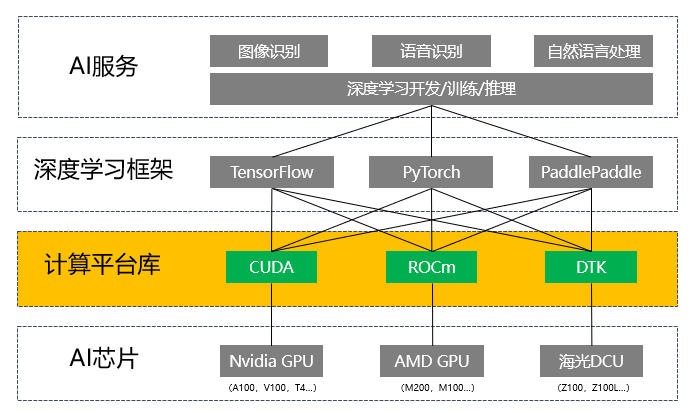
目前CUDA已经成为人工智能领域底层计算平台的事实标准,各种主流的深度学习框架都默认适配CUDA计算平台,包括TensorFlow、PyTorch、Caffe、MxNet、PaddlePaddle等。
当然除了CUDA之外,还有ROCm和基于ROCm的海光DTK,以及国产寒武纪Neuware和华为CANN等,我们统一把这类屏蔽底层AI芯片细节,通过构建一套支持端到端AI应用开发,覆盖编译、调试、性能分析等工具,同时提供各种基础函数库、数学库、深度学习库,以及编程模型和API接口的软件系统称为计算平台库。
02 AMD ROCm
Windows的一家独大使得Linux的出现成为可能,iOS的封闭造就了Android的蓬勃发展,ROCm的横空出世才让CUDA拥有了真正的竞争对手。
ROCm(Radeon Open Compute Platform)是AMD主导的一个开源计算平台库,Radeon是AMD GPU产品的品牌名,除ROCm之外,还有一系列ROCx的简称,如ROCr(ROC Runtime),ROCk(ROC kernel driver),ROCt(ROC Thunk)等。

ROCm之于AMD GPU,基本上相当于CUDA之于NVIDIA GPU,ROCm第一个版本是在2016年发布,目前最新的ROCm已经到了5.6版本。
虽然从发布的时间来看,ROCm比CUDA晚了将近10年,但ROCm生态发展很快,已经能够提供与CUDA类似的API、工具以及各种函数库,因此上层的深度学习框架可以基于ROCm的生态进行构建。
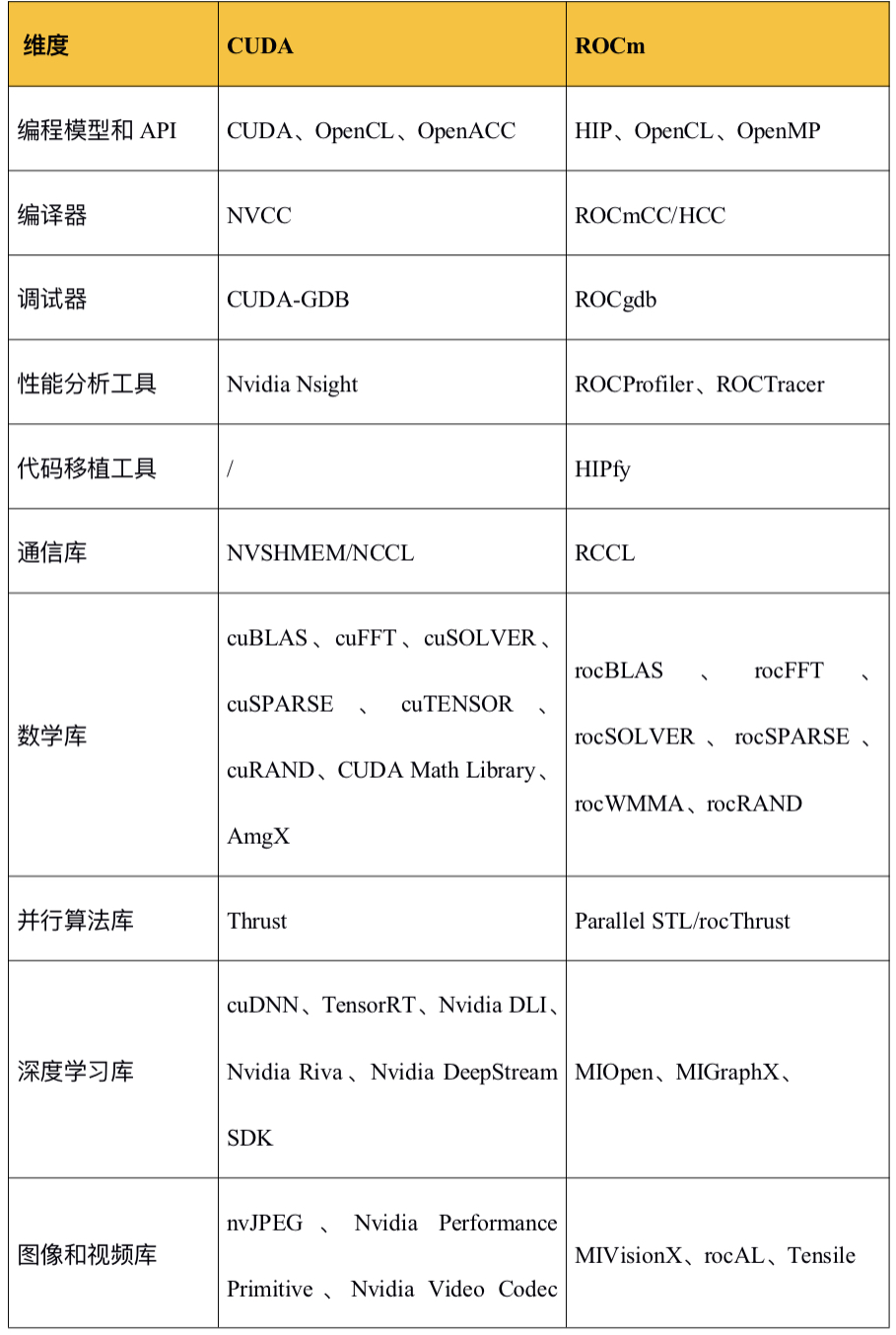
CUDA和ROCm的对比
?
03 国产AI计算平台库的发展
随着国产芯片的崛起以及人工智能浪潮的兴起,中国在AI领域也出现了一些知名企业,他们也在尝试基于国产芯片构建计算平台生态。
目前主流的路线主要有两种,第一种选择从芯片到计算平台库都全自研,比如华为基于自己的Ascend系列ASIC构建的CANN计算平台库以及寒武纪基于自家的MLU系列ASIC构建的Neuware;第二种则是选择自研+开源的路线,比如海光信息基于开源ROCm定制开发了DTK(DCU Toolkit)计算平台库适配自研的DCU系列GPU。
· 海光DTK
DTK(DCU ToolKit)是海光的开放软件平台,封装了ROCm生态相关组件,同时基于DCU的硬件进行优化并提供完整的软件工具链,对标CUDA的软件栈,为开发者提供运行、编译、调试和性能分析等功能。
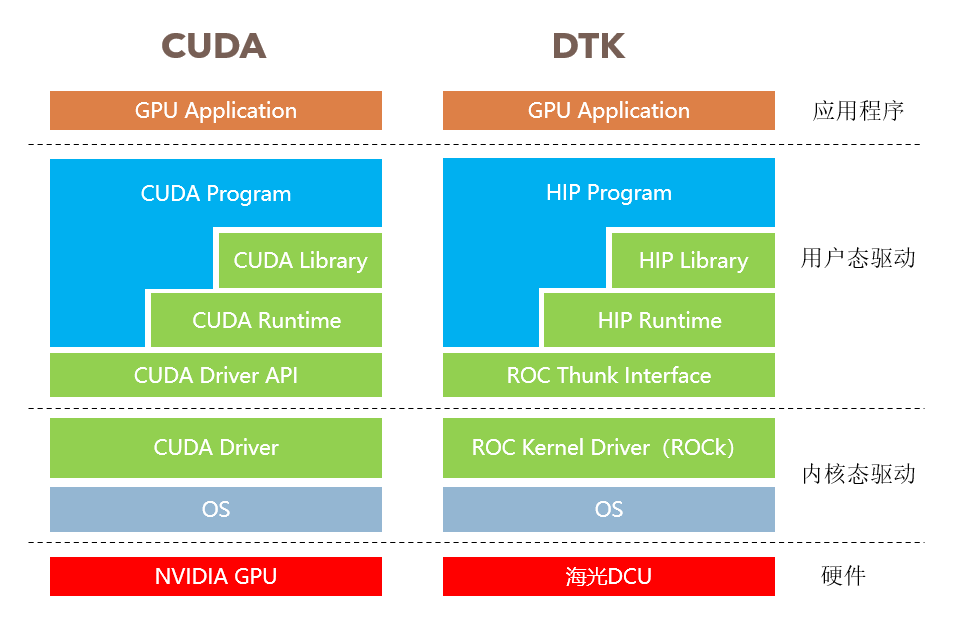
同时提供多种深度优化的计算加速库,原生支持TensorFlow/Pytorch/PaddlePaddle等深度学习框架以及Open-mmlab/Vision/FastMoe等三方组件,提供FP32/FP16/INT8等多精度训练和推理支持,覆盖计算机视觉、智能语音、智能文本、推荐系统和强化学习等多个人工智能领域。
· 寒武纪Neuware
Cambricon Neuware?是寒武纪专门针对其云端和终端的智能处理器产品打造的软件开发平台,其中包括了多种深度学习/机器学习编程库,以及编程语言、编译器、程序调试/调优工具、驱动工具和视频编解码工具等,形成了完善的软件栈,为人工智能应用特别是深度学习推理应用的开发和部署提供了便利。

Neuware软件架构从上往下分别为深度学习应用、主流的深度学习框架、Neuware加速库、Bang编程语言、运行时库CNRT、驱动和虚拟化软件层,此外还包括通用的软件工具。
主流的深度学习框架包括TensorFlow和PyTorch,同时开发者可以结合神经网络加速库和通信库便捷的构造各类深度神经网络模型以及其他机器学习领域的算法,而无须关心寒武纪智能处理器产品的内部硬件资源如何调度。
运行时库CNRT提供了一套针对寒武纪智能处理器产品的上层编程接口,用于与寒武纪智能处理器产品的硬件之间进行交互和调度硬件资源。
Bang语言是专门针对寒武纪智能处理器产品设计的编程语言,它支持最常用的 C99和C++11语言的语法特性,并提供了用于编写高性能程序的内置函数接口。
Neuware的通用软件工具包括编译器、调试器、系统性能分析及监控相关软件。
· 华为昇腾CANN
CANN(Compute Architecture for Neural Networks)是华为针对AI场景推出的异构计算架构。它对上支持业界主流前端框架,向下对用户屏蔽系列化芯片的硬件差异,以丰富的软件栈功能满足用户全场景的人工智能应用诉求。

昇腾计算语言AscendCL开发接口是昇腾计算开放编程框架,对开发者屏蔽底层多种处理器差异,提供算子开发接口TBE、标准图开发接口AIR、应用开发接口,支持用户快速构建基于Ascend平台的AI应用和业务。
昇腾计算服务层主要提供昇腾算子库AOL,通过神经网络库、线性代数计算库等高性能算子加速计算;昇腾调优引擎AOE,通过算子调优OPAT、子图调优SGAT、梯度调优GDAT、模型压缩AMCT提升模型端到端运行速度。同时提供AI框架适配器Framework Adaptor用于兼容Tensorflow、Pytorch等主流AI框架。
昇腾计算编译层通过图编译器将用户输入中间表达的计算图编译成昇腾硬件可执行模型;同时借助张量加速引擎TBE的自动调度机制,高效编译算子。
昇腾计算执行层负责模型和算子的执行,提供运行时库、图执行器、数字视觉预处理DVPP、人工智能预处理AIPP、华为集合通信库HCCL等功能单元。
昇腾计算基础层主要为其上各层提供基础服务,如共享虚拟内存、设备虚拟化、主机-设备通信等。
· 其他厂商
除了前面介绍的国产主流芯片厂商的AI计算平台库,国内还有一些类CUDA厂商,他们也开发了自己的AI计算平台库,如天数智芯,燧原科技等。
天数智芯软件栈包括深度学习编程框架、虚拟化管理工具、函数库加速层、编译器、调试和调优工具、运行库及驱动等,可以满足不同层次的应用开发及调试需求。
燧原科技计算及编程平台TopsPider提供全新的编程模型,开放的编程接口和全新的profiling工具,支持自适应图优化策略及算子泛化和系统级设备虚拟化,同时具备高加速比的分布式训练能力。
04 OrionX异构算力池化解决方案
不论是华为的CANN还是寒武纪的Neuware,亦或是基于ROCm开发的海光DTK,目前与CUDA生态相比还有一定的差距,但随着国家对自主可控的持续投入,越来越多的客户会采购国产卡,同时也会基于相应厂商的AI计算平台库做适配开发。
为了帮助客户解决不同厂商卡的管理运维以及适配开发难题,趋动科技的OrionX异构算力池化解决方案帮助客户构建统一的AI算力资源池,通过软件定义AI算力技术,颠覆了原有的 AI 应用直接调用物理算力的架构,增加软件层,将AI应用与物理硬件解耦合。OrionX架构实现了AI算力资源池化,让用户高效、智能、灵活地使用AI算力资源,达到了降本增效的目的。
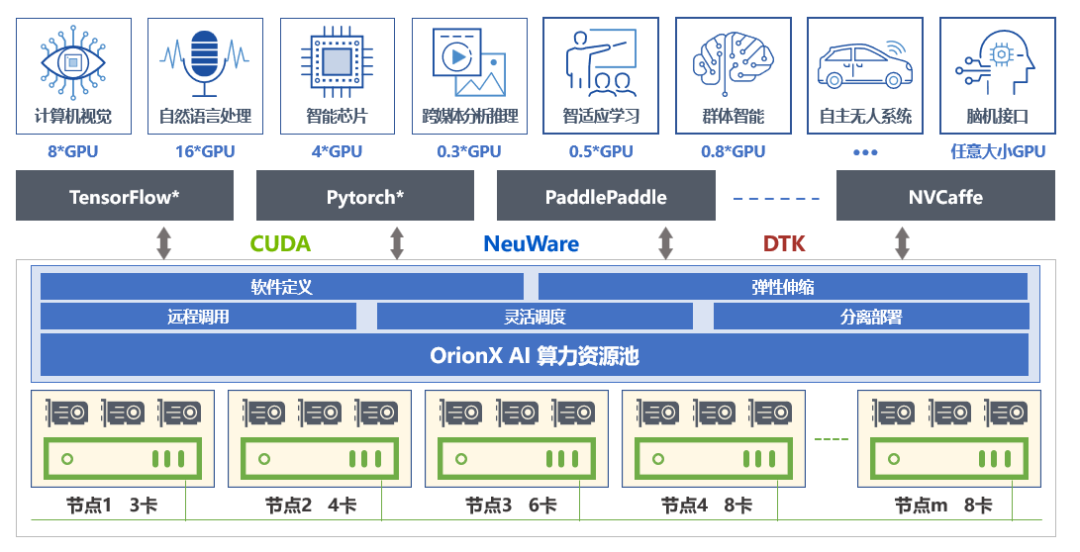
目前OrionX不仅支持英伟达GPU,而且也支持海光DCU,寒武纪MLU,以及华为昇腾。未来OrionX将把更多厂商的AI加速卡纳入统一的AI算力资源池,提升多算力平台管理能力及效率,帮助企业简化管理,提升物效人效。
05 总结
异构算力池化解决方案可在实现多厂商AI算力硬件统一管理、统一调度、统一使用的同时,结合软件定义算力技术实现:
异构算力池化
既支持底层AI算力基础设施全栈国产化,同时也支持国内厂商算力和国外厂商算力的异构池化管理,从而实现国产化的平稳、逐步替代;
按需分配
资源池内各类算力资源按需挂载,用完立即回收,资源高效流转;
资源切分
各类算力硬件资源抽象化,上层应用可以算力1%、显存1MB为基本单位进行异构算力资源的申请和使用,异构算力资源使用更加精细;
资源聚合
资源池内各类算力资源通过网络远程调用方式实现资源整合,形成算力资源池,一方面可突破单服务器硬件配置闲置,另一方面可减少资源池内硬件资源碎片;
远程调用
AI 应用可在资源池任意位置进行部署,无需关注底层物理硬件配置细节;
弹性伸缩
AI 应用可弹性使用资源池内算力资源,无需重启即可改变申请算力资源。
参考文献:
1.https://docs.nvidia.com/cuda/
2.https://rocm.docs.amd.com/en/latest/
3.https://www.iluvatar.com/software?fullCode=cpjs-rj-rjz
4.https://www.enflame-tech.com/software/topsrider
5.https://www.cambricon.com/index.php?m=content&c=index&a=lists&catid=71
6.https://mp.weixin.qq.com/s/21Nf4fMNz8sEXpvd_ZD1FQ
7.https://blog.csdn.net/u014756627/article/details/129100476
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!