(JAVA)-(多线程)-线程池
线程池,顾名思义就是存放线程的池子,当有任务时能够随时取用线程,任务结束后能够放回线程池中。如果把线程比成碗,线程池就像一个碗柜一样。
使用线程池的好处:
1.当有大量线程对象时,减少了线程创建销毁造成的损耗。
2.提高响应速度
3.提高线程的可管理性
线程池的核心逻辑:
1.创建一个池子,池子是空的
2.提交任务的时候池子会创建新的线程对象,任务执行完毕,线程归还给池字,下次再提交任务时,不需要创建新的线程,直接复用已有的线程即可
3.提交任务时,池子中没有空闲的线程,也无法创建新的线程,任务就会排队
代码实现:
1.创建线程池
2.提交任务
3.所有的任务全部执行完毕,关闭线程
一:使用Executors工具类创建线程池对象
Executors是线程池的一个工具类,能调用他的静态方法创建线程池对象
public static ExecutorService newCachedThreadPool();
//创建一个没有上限的线程池
public static ExecutorService newFixedThreadPool(int nThreads);
//创建一个有上限的线程池1.newCachedThreadPool() 方法:
能创建一个没有上限的线程池,如果现有任务没有线程进行处理,就会创建一个新线程并添加到缓存池中。如果有被使用完但是还没销毁的线程,就复用该线程。如果有线程60s未被使用的话就会从缓存中移出并终止(销毁)。因此,长时间保持空闲的线程池不会使用任何资源。
ExecutorService pool1 = Executors.newcachedThreadPool();提交任务:submit方法

可以看到submit方法参数可以传递runnable和Callable的实现类任务
public class test {
public static void main(String[] args) {
ExecutorService pool1 = Executors.newCachedThreadPool();
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
//提交三个任务
pool1.shutdown();
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"---"+i);
}
}
}

我们可以看到线程池创建了三个线程。
2.newFixedThreadPool(int num)方法
这个方法能创建一个固定线程数的线程池,超出线程任务数量的线程会在队列中等待,方法参数为线程池中的线程数
public class test {
public static void main(String[] args) {
ExecutorService pool1 = newFixedThreadPool(1);
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
pool1.submit(new MyRunnable());
//提交三个任务
pool1.shutdown();
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName()+"---"+i);
}
}
}
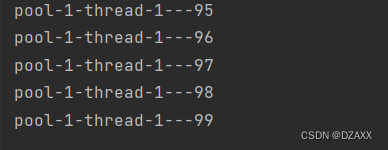
我们可以看到结果中只有线程1在执行任务。
二:自定义线程池
我们首先对Executors工具类进行跟进

我们发现创建这个线程池的方法在底层调用了一个 ThreadPoolExecutor类去创建了对象,并且传递了一些参数进去,ThreadPoolExecutor其实就是线程池的类。
我们先讲解线程池的运行流程
线程池中分为核心线程和临时线程。临时线程倘若经过了一定时间没有处理,就会进行销毁
当任务进行提交时,线程池便会创建线程。
倘若提交的任务数超过了核心线程数,就会在阻塞队列中进行等待,直到核心线程正在进行的任务完成后再执行。倘若提交的任务数超出了阻塞队列的长度,就会进入临时队列中进行执行,若提交的任务在超出了临时队列的范围,就会是使用任务拒绝策略拒绝任务。
通过以上,我们了解了线程池的运行流程。接着我们来看看线程池的参数

跟进发现,线程池这个类最长的构造方法有七个参数,我们逐个讲解
1.corePoolSize:这个参数就是线程池的核心线程数。
2.maximumPoolSize:这个参数是线程池的最大线程数,他肯定是大于核心线程数,从源码中也可以看到,如果这样做在运行时会抛出异常:IllegalArgumentException。
3.keepAliveTime:这个参数是空闲线程的等待时间,当超过这个时间临时线程还没有执行任务,临时线程就会销毁。
4.unit:这个是线程池的空闲时间的单位,需要调用TimeUnit中的枚举常量
- 它在TimeUnit类中有7种静态属性可取。
- 天:TimeUnit.DAYS;
- 小时:TimeUnit.HOURS;
- 分钟:TimeUnit.MINUTES;
- 秒:TimeUnit.SECONDS;
- 毫秒:TimeUnit.MILLISECONDS;
- 微妙:TimeUnit.MICROSECONDS;
- 纳秒:TimeUnit.NANOSECONDS;
5.workQueue:这个参数是线程在等待的阻塞队列,需要传递一个阻塞队列进去。
6.theadFactor:这个参数意思是线程工厂,用于创建新的线程。我们可以传递Executros工具类中的deafaultThread方法进行创建线程工厂,他在底层也是创建了一个线程。
7.rejectedExecutionHandler:这个是一个接口,代表任务的拒绝策略,在ThreadPoolExecutor中以内部类的方式内部类方式存在,他们都实现了rejectedExecutionHandler接口。
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。线程池默认的拒绝策略。如何使用
new ThreadPoolExecutor.AbortPolicy()。 - DiscardPolicy:也是丢弃任务,但是不抛出异常。
- DiscardOldestPolicy:丢弃队列最前面的任务,也就是队列头的元素,然后重新尝试执行任务(重复此过程)。如果此时阻塞队列使用PriorityBlockingQueue优先级队列,将会导致优先级最高的任务被抛弃。
- CallerRunsPolicy:既不抛弃任务也不抛出异常,而是由调用线程的主线程来处理该任务。换言之就是由调用线程池的主线程自己来执行任务(例如:是有main线程启动的线程池,当触发次策略时,多余的任务就会交由main线程来执行),因此在执行任务的这段时间里主线程无法再提交新任务,从而使线程池中工作线程有时间将正在处理的任务处理完成,所以对性能和效率必然是极大的损耗。
那么线程池多大合适呢?

要理解上面的公式,我们得先了解最大并行数是什么
四核八线程:代表着电脑有四个大脑 ,能同时干四件事情,而超线程技术,把一个物理核心模拟成两个逻辑核心,理论上要像八颗物理核心一样在同一时间执行八个线程,所以电脑最大并行数为8.
我们可以用RunTime工具类中的availiableProcessors()静态方法去获取java能够使用的最大线程数。
项目运算比较多,读取本地文件或者数据库比较少,就属于cpu密集型运算,反之则属于IO密集型运算
第一个公式很容易能看懂,那么第二个公式是什么意思呢?
举个例子:从本地文件中读取两个数据,相加。假设java能使用的最大并行数为8,读取数据用了1秒,cpu计算相加用了1秒
从本地文件中读取数据并不是cpu干的事,cpu计算相加用了一秒,因此最合适的线程池大小就是

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!