[论文阅读]Multimodal Virtual Point 3D Detection
Multimodal Virtual Point 3D Detection
论文简读
方法MVP方法的核心思想是将RGB图像中的2D检测结果转换为虚拟的3D点,并将这些虚拟点与原始的Lidar点云合并。具体步骤如下:
(1) 使用2D检测器(如CenterNet)在RGB图像中检测物体。
(2) 将检测到的物体掩模投影到Lidar点云中,创建与物体相关的点云子集。
(3) 在与物体相关的点云子集中,随机采样2D点,并找到最近的Lidar点以获得深度值。
(4) 根据采样点的2D位置和对应的深度值生成虚拟3D点。
(5) 将虚拟3D点与原始Lidar点云合并,作为3D检测器(如CenterPoint)的输入。

摘要
基于激光雷达的传感驱动当前的自动驾驶汽车。尽管进步很快,当前的激光雷达传感器在分辨率和成本方面仍落后传统彩色相机二十年。对于自动驾驶来说,这意味着靠近传感器的大物体很容易被看到,但远处或小物体仅包含很少的点。这是一个问题,特别是当这些物体被证明是对驾驶有危险时。另一方面,这些相同的物体在彩色 RGB 传感器中清晰可见。本文提出了一种将 RGB 传感器无缝融合到基于激光雷达的 3D 识别中的方法。本文的方法采用一组 2D 检测来生成密集的 3D 虚拟点,以增强原本稀疏的 3D 点云。这些虚拟点可以自然地集成到任何基于激光雷达的标准 3D 检测器以及常规激光雷达测量中。由此产生的多模态检测器简单而有效。大规模 nuScenes 数据集上的实验结果表明,本文的框架将强大的 CenterPoint 基线提高了 6.6 mAP,并且优于竞争的融合方法。
引言
3D 感知是安全自动驾驶的核心组成部分 。3D 激光雷达传感器可提供周围环境的精确深度测量,但成本昂贵且远距离分辨率较低。顶级 64 线激光雷达传感器的成本很容易高于小型汽车,其输入分辨率比 50 美元的 RGB 传感器低至少两个数量级。该激光雷达传感器接收小型或远处物体很少的测量结果,而相应的 RGB 传感器则可以看到数百个像素。然而,RGB 传感器无法感知深度,无法直接将其测量结果放入场景中。
本文提出了一个简单而有效的框架来融合 3D 激光雷达和高分辨率彩色相机测量数据。将 RGB 测量值映射到使用激光雷达传感器的近距离深度测量场景中,从而将 RGB 测量值提升为 3D 虚拟点(示例见图 1)。本文的多模态虚拟点检测器 MVP 可生成目标物体附近的高分辨率 3D 点云。然后,基于中心的 3D 检测器识别场景中的所有对象。具体来说,MVP 使用 2D 目标检测将原始点云裁剪为实例截锥体。然后,MVP 通过将 2D 像素提升到 3D 空间,在这些前景点附近生成密集的 3D 虚拟点。使用图像空间中的深度补全来推断每个虚拟点的深度。最后,MVP 将虚拟点与原始激光雷达测量结果相结合,作为基于标准中心的 3D 检测器的输入。
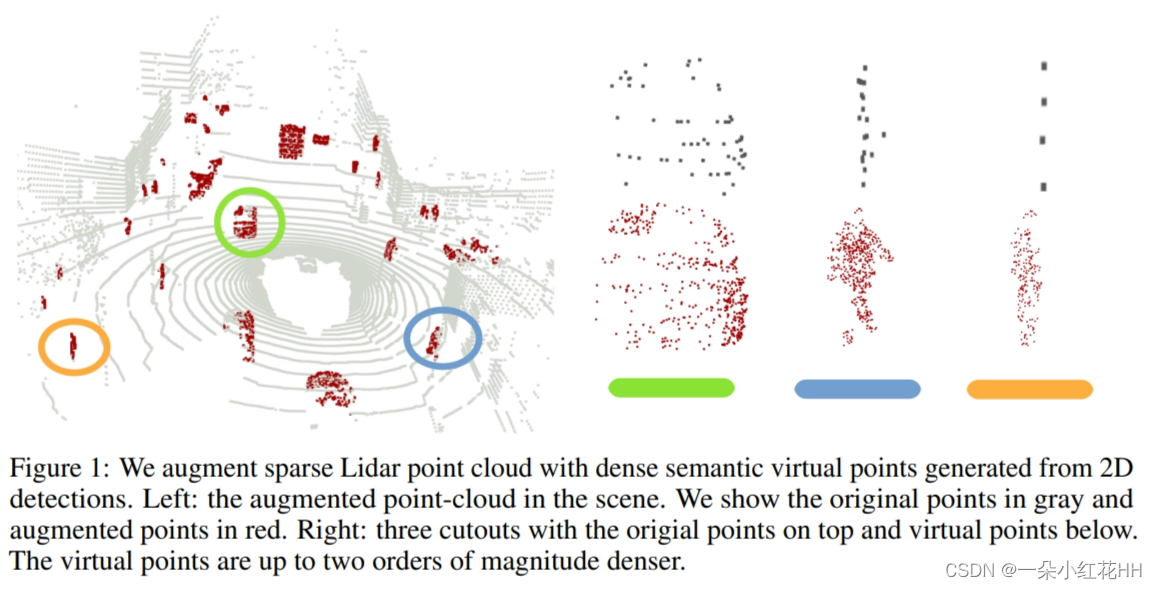
本文的多模态虚拟点方法具有几个关键优势:首先,2D 目标检测得到了很好的优化,即使对于小物体也具有很高的准确度。了解同一场景中两个最先进的 2D 和 3D 检测器的比较。 2D 检测器具有明显更高的 2D 检测精度,但缺乏下游驱动任务中使用的必要 3D 信息。其次,虚拟点减少了近处和远处物体之间的密度不平衡。 MVP用相同数量的虚拟点来增强不同距离的物体,使得这些物体的点云测量更加一致。最后,本文的框架是任何现有或新的 2D 或 3D 探测器的即插即用模块。本文在大规模 nuScenes 数据集上测试模型。与强大的 CenterPoint 基线相比,添加多模态虚拟点可带来 6.6 mAP 改进。在没有任何集成或测试时间增强的情况下,本文的最佳模型在 nuScenes 上实现了 66.4 mAP 和 70.5 NDS,在提交时优于 nuScenes 排行榜上所有竞争的非集成方法。
相关工作
2D Object Detection : 二维目标检测近年来取得了长足的进步。标准方法包括 RCNN 系列,它首先根据预定义的锚框预测与类别无关的边界框,然后使用深度神经网络以两阶段方式对它们进行分类和细化。 YOL、SSD和 RetinaNet一次性预测特定类别的边界框。最近的无锚检测器如 CornerNet和 CenterNe直接通过关键点定位对象,而不需要预定义的锚。在本文的方法中,使用 CenterNet作为2D 检测器,因为它的简单性和检测小物体的卓越性能。
Lidar-based 3D Object Detection : 基于激光雷达的 3D 目标检测从 3D 点云中估计旋转 3D 边界框。 3D 检测器与 2D 检测器共享共同的输出表示和网络结构,但对输入进行不同的编码。 VoxelNet 使用基于 PointNet 的特征提取器来生成体素特征表示,其中由稀疏 3D 卷积和鸟瞰图 2D 卷积组成的主干网产生检测输出。其次[Second]引入了更有效的稀疏卷积运算。 PIXOR 和PointPillars 直接处理鸟瞰点云,进一步提高效率。两阶段 3D 检测器使用基于 PointNet 的集合抽象层来聚合第一阶段提案内的 RoI 特定特征以细化输出。无锚方法消除了对轴对齐鸟瞰视图锚框的需要。 VoteNet 通过霍夫投票和聚类来检测 3D 对象。 CenterPoint 提出了一种基于中心的 3D 目标检测和跟踪表示,并在 nuScenes 和 Waymo 基准测试中实现了最先进的性能。然而,由于深度测量的稀疏性,仅使用激光雷达的探测器仍然会错过小型或远处的物体。在这项工作中,以 CenterPoint 检测器为基础,通过添加多模态虚拟点方法,展示了 6.6 mAP 的显著改进。
Camera-based 3D Object Detection : 基于摄像头的 3D 目标检测可根据摄像头图像预测 3D 边界框。 Mono3D使用地平面假设来生成 3D 候选框,并使用 2D 语义线索对建议进行评分。 CenterNet首先检测图像中的 2D 目标,并使用中心特征预测相应的 3D 深度和边界框属性。尽管进步很快,单目 3D 目标检测器的性能仍然远远落后于基于激光雷达的方法。在最先进的 3D 检测基准上,最先进的单目方法实现的 mAP 检测精度约为基于标准激光雷达的基线的一半。基于 PseudoLidar 的方法从 RGB 图像生成虚拟点云,类似于本文的方法。然而,它们依赖于嘈杂的立体深度估计,而本文使用更准确的激光雷达测量。同样,纯粹基于颜色的方法的性能稍微落后于激光雷达或基于融合的方法。
Multi-modal 3D Object Detection : 多模态 3D 物体检测融合了激光雷达和彩色相机的信息。 Frustum PointNet 和 Frustum ConvNet 首先检测图像空间中的对象,以识别点云中的感兴趣区域以进行进一步处理。它提高了 3D 检测的效率和精度,但从根本上受到 2D 检测质量的限制。相比之下,本文采用标准 3D 主干网来处理增强型激光雷达点云,结合了两种传感器模式的优点。 MV3D 和 AVOD 在两阶段框架中执行以对象为中心的融合。首先在每个传感器中检测对象,并在提议阶段使用 RoIPooling 进行融合。连续融合在其骨干网之间共享图像和激光雷达特征。最接近本文的方法的是 MVX-Net 、PointAugmenting 和 PointPainting ,它们利用逐点对应通过基于图像的分割或 CNN 特征来注释每个激光雷达点。相反,本文使用 3D 测量周围的附加点来增强 3D 激光雷达点云。这些附加点充分利用了更高维的 RGB 测量。
Point Cloud Augmentation : 点云增强从稀疏的激光雷达测量中生成更密集的点云。基于激光雷达的方法,如 PUNet 、PUGAN 和 [Patch-based progressive 3d point set upsampling]从原始激光雷达扫描中学习高级逐点特征。然后,他们从每个高维特征向量重建多个上采样点云。基于图像的方法从稀疏测量中执行??深度补全。本文以这些深度补全方法为基础,并通过点上采样展示最先进的 3D 检测结果。
Preliminary
本文的框架依赖于 2D 检测、现有的 3D 检测器以及 2D 和 3D 之间的映射。本文在下面介绍必要的概念和符号。
2D Detection. : 2D 目标检测器旨在对相机图像中的所有对象进行定位和分类。边界框 bi ∈ R4 描述对象位置。类别分数 si? 预测检测 bi 属于 c 类的可能性。可选的实例掩码 mi ∈ [0, 1]W×H 预测每个对象的像素级分割。在本文中,使用流行的 CenterNet 检测器。 CenterNet 通过关键点估计来检测对象。它采用输入图像并预测每个类 c 的热图。热图的峰值(局部最大值)对应于一个对象。该模型使用具有 L1 或框 IoU 目标的峰值特征回归到其他边界框属性。对于实例分割,使用 CenterNet2 ,它在第一阶段提案网络的顶部添加了级联 RoI 头 。整个网络以 40 FPS 运行,并在 nuScenes 图像数据集上实现 43.3 的实例分割 mAP。
3D Detection. : 令 P = {(x, y, z, r)i} 为具有 3D 位置 (x, y, z) 和反射率 r 的点云。 3D 检测器的目标是从点云 P 预测一组 3D 边界框 {bi}。边界框 b = (u, v, o, w, l, h, θ) 包括 3D 中心位置 ( u、v、o)、物体大小 (w、l、h) 以及沿 z 轴 θ 的偏航旋转。在本文中,以最先进的 CenterPoint 检测器为基础。使用两种流行的 3D 主干网络进行实验:VoxelNet 和 PointPillars 。 VoxelNet 将不规则点云量化为规则体素,然后进行简单的平均池化,以从体素内的所有点中提取特征。之后,由稀疏 3D 卷积组成的主干网处理量化的 3D 特征量,输出是地图视图特征图 M ∈ RW×H×F。 PointPillar 直接将点云处理为鸟瞰图支柱,即每个地图位置的单个拉长体素,并通过快速 2D 卷积提取特征以获得地图视图特征图 M。
借助地图视图特征,受 CenterNet 启发的检测头可以在鸟瞰视图中定位对象,并使用中心特征回归到其他框参数。
2D-3D Correspondence. : 多模态融合方法通常依赖于 3D 点云和 2D 像素之间的逐点对应。在没有校准噪声的情况下,从 3D 激光雷达坐标到 2D 图像坐标的投影涉及从激光雷达测量到相机坐标系的 SE(3) 变换以及从相机坐标系到图像坐标的透视投影。所有变换都可以用同质的、时间相关的变换来描述。令 t1 和 t2 分别为激光雷达测量和 RGB 图像的捕获时间。令 T(car←lidar) 为激光雷达传感器到汽车参考系的变换。令 T(t1←t2) 为汽车在 t2 和 t1 之间的变换。令 T(rgb←car) 为从汽车参考系到 RGB 传感器的变换。最后,令 Prgb 为由相机本征定义的 RGB 相机的投影矩阵。从激光雷达到 RGB 传感器的转换定义为:
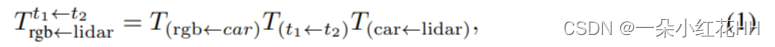
接下来是带有相机矩阵 Prgb 的透视投影和透视除法。透视除法使得从激光雷达到 RGB 的映射是满射且不可逆的。
Multimodal Virtual Point
给定一组 2D 目标检测,希望生成密集的虚拟点 vi = (x, y, z, e),其中 (x, y, z) 是 3D 位置,e 是来自 2D 检测器的语义特征。为了简单起见,使用 2D 检测器类别分数作为语义特征。对于具有关联实例掩码 mj 的每个检测 bj,生成固定数量 τ 的多模态虚拟点。
Virtual Point Generation. : 虚拟点生成。 首先将 3D 激光雷达点云投影到图像平面。具体来说,按照方程(1)将每个激光雷达点 (x, y, z, r)i 转换为 RGB 相机的参考系,然后使用透视投影将其投影到具有相关深度 di 的图像坐标 pi 。令单个检测 j 的所有投影点和深度值的集合为目标点云子集 Fj = {(pi, di)|pi ∈ mj?i}。点云子集仅考虑落在检测掩模 mj 内的投影 3D 点 pi。检测掩模之外的任何激光雷达测量结果都会被丢弃。接下来,从每个点云子集 Fj 生成虚拟点。
首先从每个实例掩码 m 中随机采样 2D 点 s ∈ m。随机均匀地对 τ 点进行采样,不重复。对于每个采样点 sk,从点云子集 Fj 中的最近邻点检索深度估计 dk:dk = arg mindi pi ? sk 。给定深度估计,将该点投影回 3D 并将对象的语义特征 ej 附加到虚拟点。将检测到的类的独热编码和语义特征中的检测目标分数连接起来。

Virtual Point 3D detection. : 基于体素的 3D 检测器首先对 3D 点 (x, y, z)i 进行体素化,并对体素内的所有点特征 (x, y, z, t, r)i 进行平均。这里 ri 是反射率测量,ti 是捕获时间。标准 3D 卷积网络在进一步处理中使用这些体素化特征。对于虚拟点,这会产生一个问题。真实点(x,y,z,t,r)和虚拟点(x,y,z,t,e)的特征维度不同。一个简单的解决方案是将虚拟点和真实点连接成一个更大的特征(x、y、z、t、r、e)并将任何丢失的信息设置为零。然而,这很浪费,因为真实点的维度会增长 3 倍,并且会造成场景不同部分的虚拟点和真实点之间的比例不平衡。此外,真实测量通常比虚拟点更精确,并且两者的简单平均模糊了真实测量中包含的信息。为了解决这个问题,本文修改了平均池方法,分别对虚拟点和真实点的特征进行平均,并将最终平均特征连接在一起作为 3D 卷积的输入。对于架构的其余部分,本文遵循 CenterPoint 。
本文在第二阶段的细化中进一步使用虚拟点。 MVP 模型在目标对象附近生成密集的虚拟点,这有助于两阶段细化。在这里,本文关注从预测的 3D 框的所有外表面提取鸟瞰图特征。本文的输入在物体周围更加密集,因此第二阶段的细化可以获得更丰富的信息。
结论
本文提出了一种用于室外 3D 目标检测的简单多模态虚拟点方法。主要创新是多模态虚拟点生成算法,该算法使用激光雷达传感器的近距离测量将 RGB 测量结果提升为 3D 虚拟点。本文的 MVP 框架可在目标对象附近生成高分辨率 3D 点云,并实现更准确的定位和回归,特别是对于小型和远处的对象。该模型显着改进了强大的仅激光雷达 CenterPoint 探测器,并在 nuScenes 基准上树立了新的最先进水平。本文的框架无缝集成到任何当前或未来的 3D 检测算法中。
当前的方法仍然存在一定的局限性。首先,本文假设虚拟点与附近的激光雷达测量具有相同的深度。这在现实世界中可能不成立。像汽车这样的物体没有垂直于地平面的平面形状。未来,计划应用基于学习的方法从激光雷达测量和图像特征推断详细的 3D 形状和姿势。其次,当前的两阶段细化模块仅使用鸟瞰图的特征,这可能无法充分利用本文的算法生成的高分辨率虚拟点。本文相信基于点或体素的两级 3D 检测器(如 PVRCNN 和 M3Detr )可能会带来更显着的改进。最后,连接 2D 和 3D 检测的基于点的抽象可能会引入太大的瓶颈,无法将信息从 2D 传输到 3D。例如,本文的当前位置+基于类别的 MVP 特征中不包含姿势信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!