域适应(Domain Adaptation)综述
根据李宏毅老师的视频所归纳的笔记
视频链接:https://www.bilibili.com/video/BV1TL411p7Us?spm_id_from=333.999.0.0
假设我们在训练集上训练黑底白字的手写数字集后(如下图),再把它用在同样是黑底白字的测试集上所得到的效果非常好(99.5%),但是如果把它用在有颜色的数字上的时候,它的效果就没之前那么好了(57.5%)。

?
若训练集和测试集的标签不同我们称之为Domain shift,它分为以下几种情况:第一种是在训练资料上是黑白的数字图片,而测试资料上是彩色的数字图片;第二种是在训练过程中的输出分布非常平均,而测试过程中的输出分布的概率差别很大;第三种是一张图片在训练资料中可能是“0”,而在测试资料中可能是“1”。
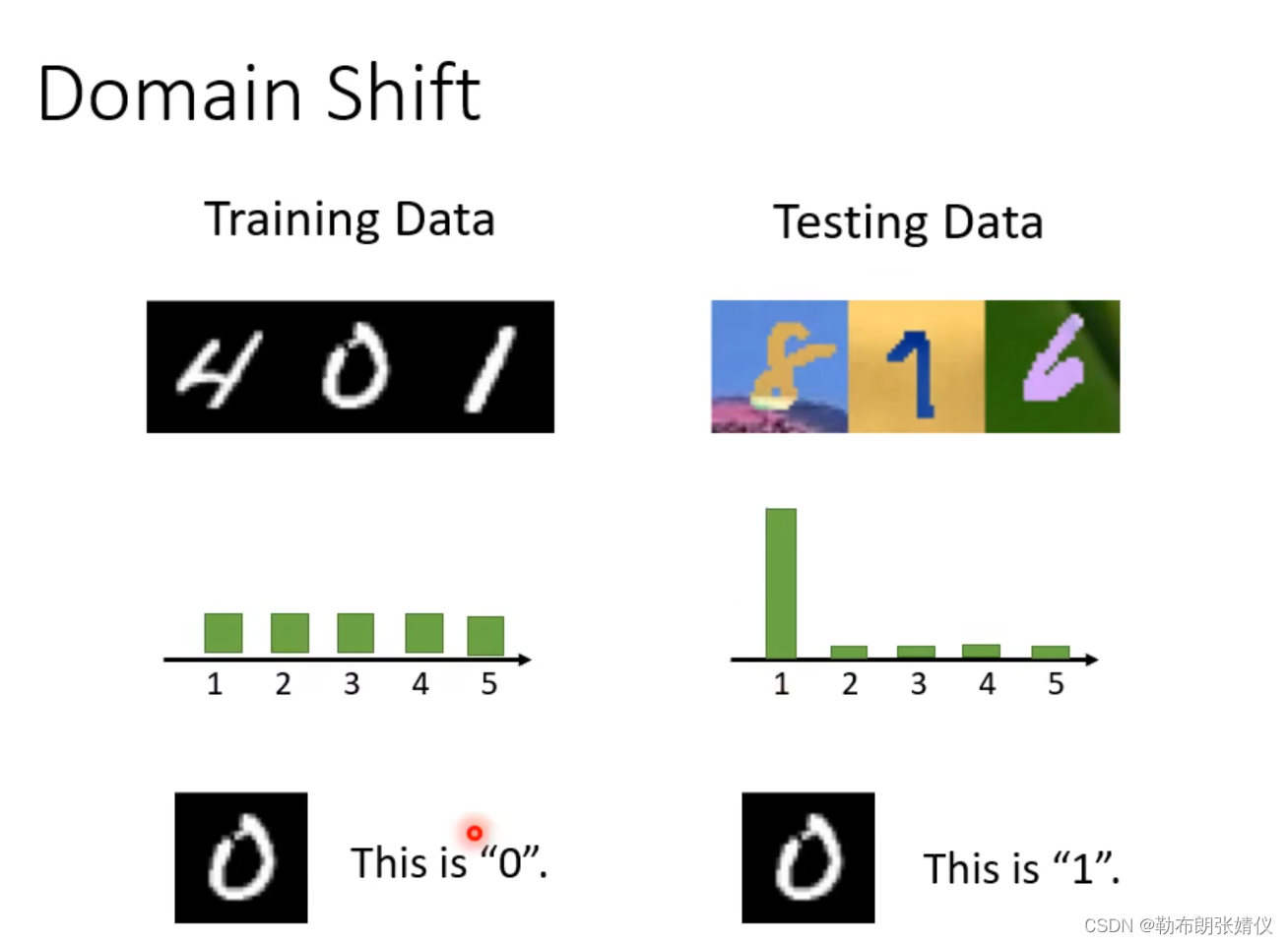
?需要域适应的场景:
第一种是目标域有一些有标签的数据但是很少,解决方法是在目标域上微调你在源域上训练出来的模型。要注意防止过拟合的情况出现。
第二种场景是目标域有大量数据,但是都是没有标注的。那么我们如何用这些未标注的数据在源域上训练并目标域上取得很好的效果呢?
如下图所示,我们要把通过特征提取把源域和目标域的不同特征拿掉(比如忽视掉颜色特征),只留下相同的特征(数字)。
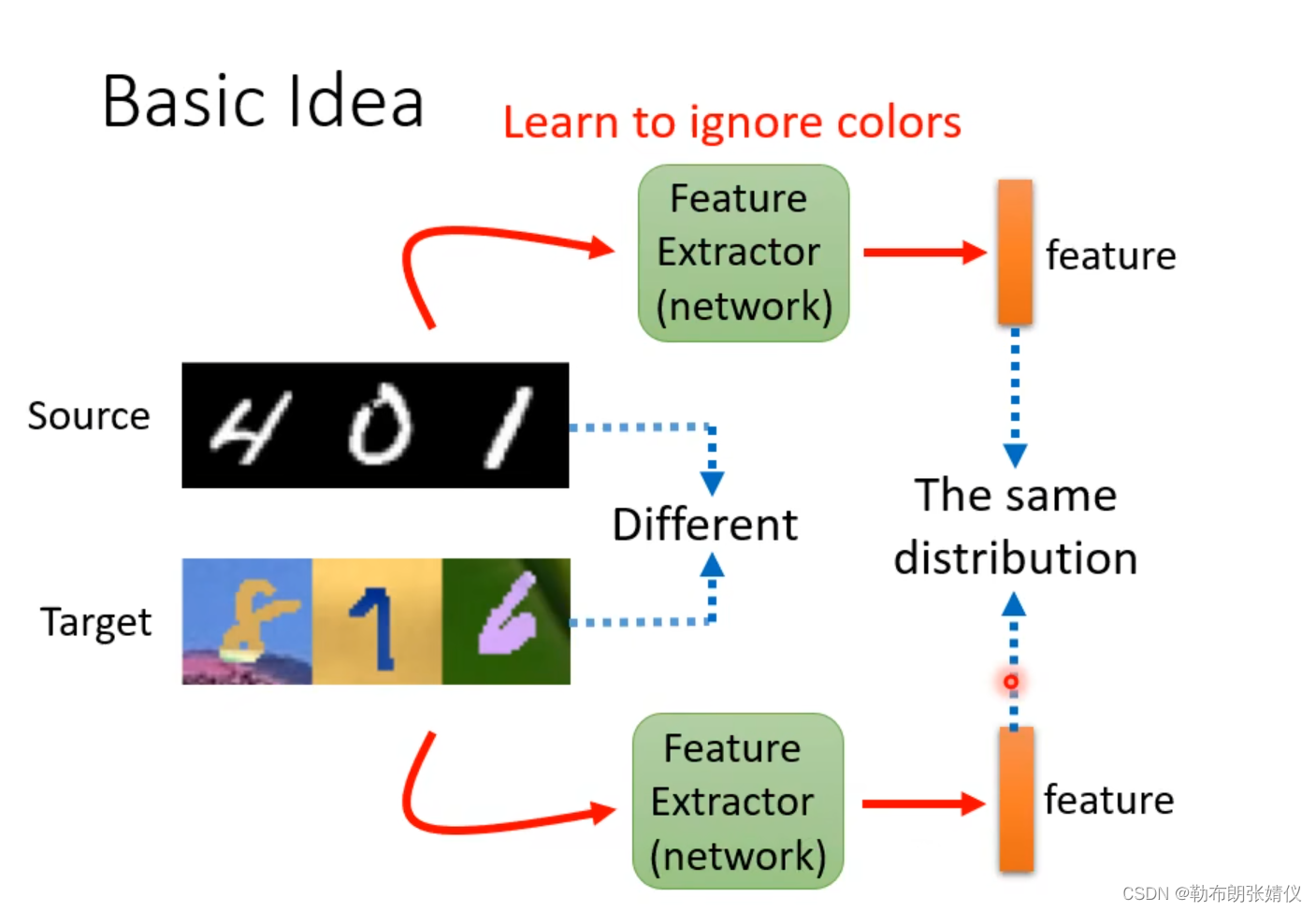
?接下来的问题就是如果找出Feature Extractor?最有用的方法就是领域对抗训练(Domain Adversarial Training)
如下图所示,最原始的做法是:我们想要的结果就是让源域的特征(蓝色的点)和目标域的特征(红色的点)分不出差异。
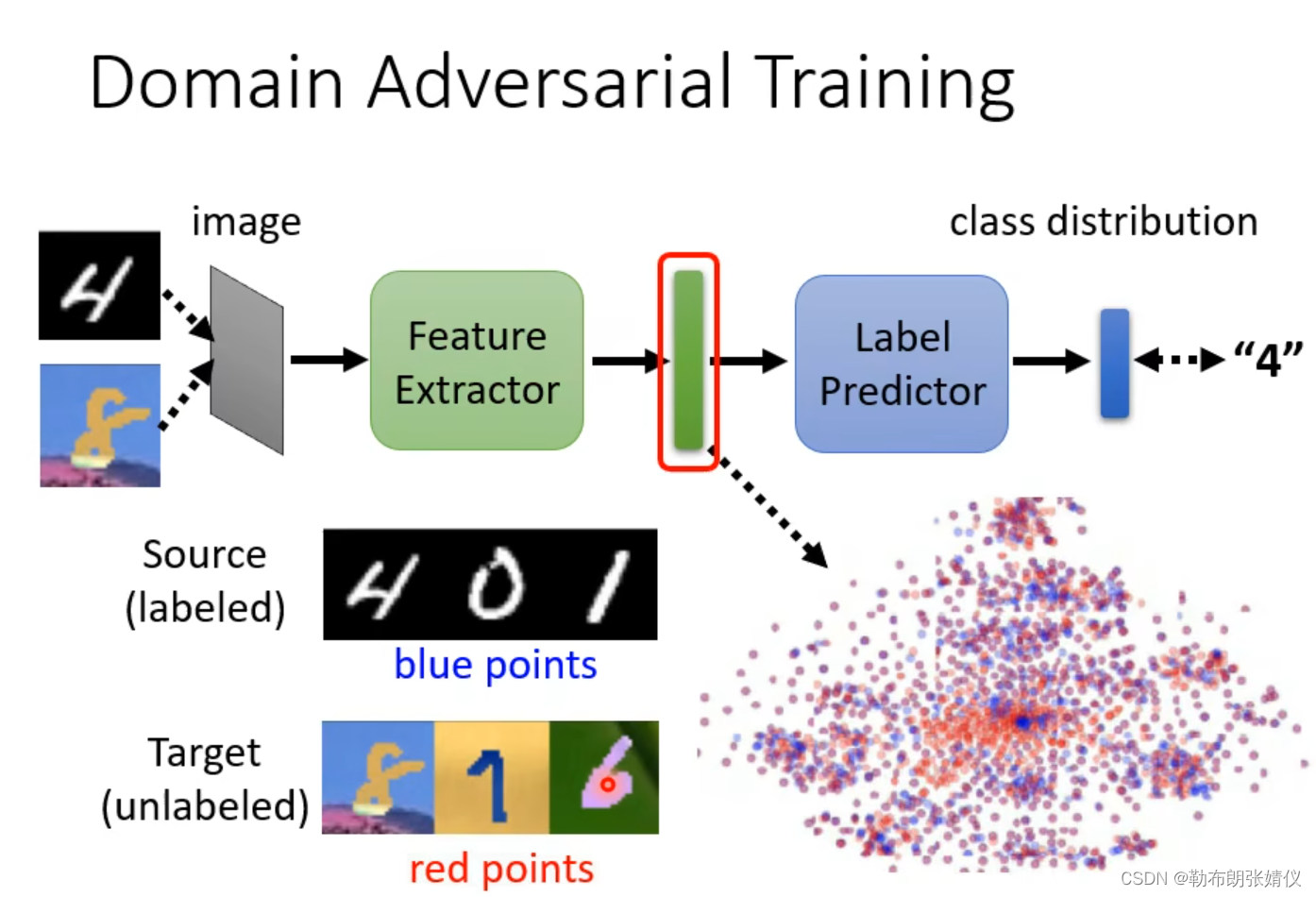
如下图所示,?Domain classifier是一个二元分类器,它的作用是区别你的factor是源域的还是目标域,而Feature Extractor的作用就是骗过Domain classifier(这个过程比较像GAN)。
?Label Predictor要做的事情是让源域上的照片分类越正确越好,Domain Classifier要做的事情就是让Domain的分类越正确越好,Feature Extractor要做的事情帮助是Label Predictor而且骗过Domain classifier
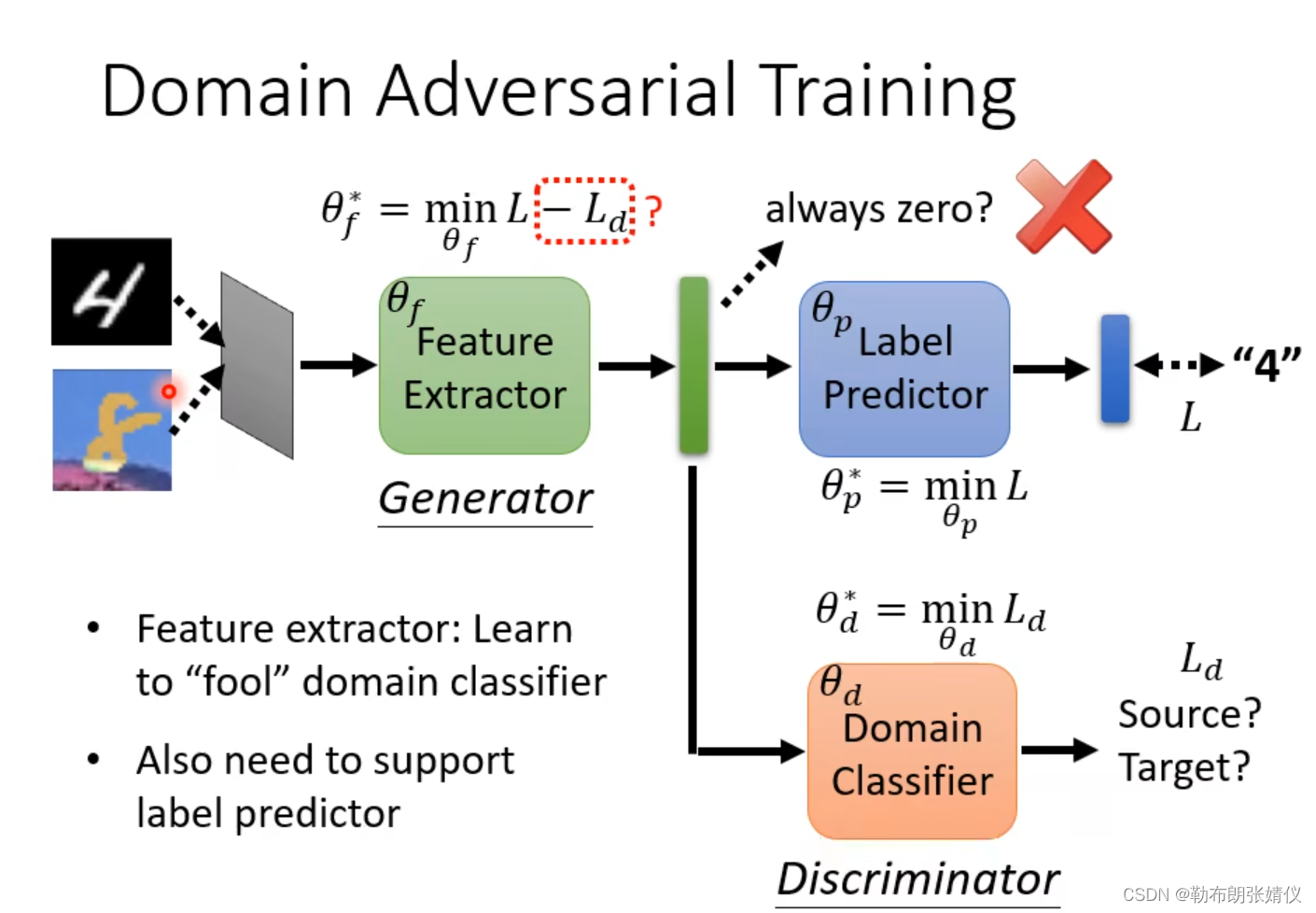
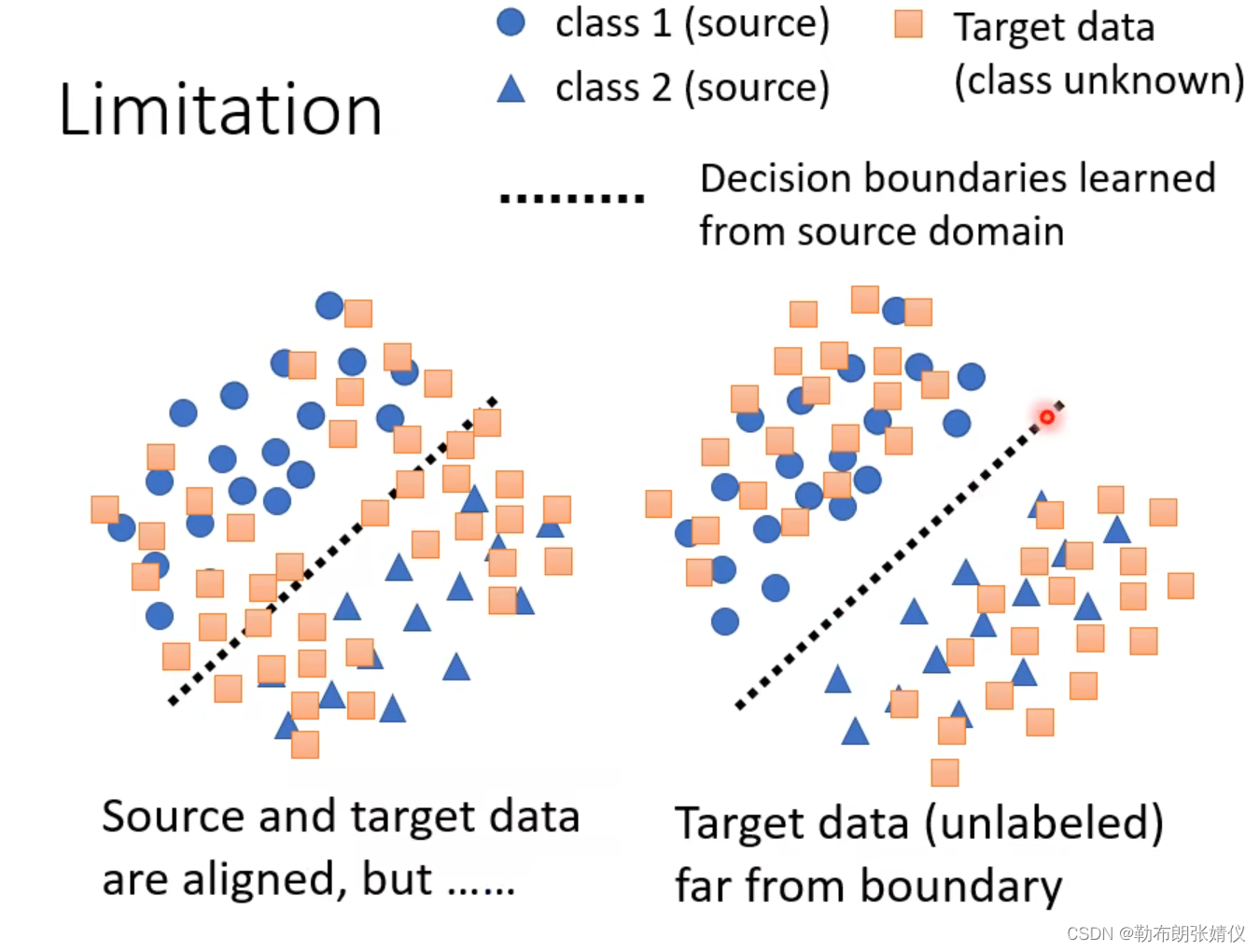
我们现在要做的是在源域和目标域的特征靠的越近的情况下远离分界点(如下图右边所示),那我们该怎么做呢?
?
有一种方法如下图所示,我们有许多无标签的数据,它们经过Feature Extractor和Label Predictor后,不知道属于哪个类别,但希望离边界越远越好,离边界远的意思就是输出的结果非常集中,集中在某一个类别上,离边界近的意思是输出的结果的每一个类别都非常接近,不知道属于哪类。
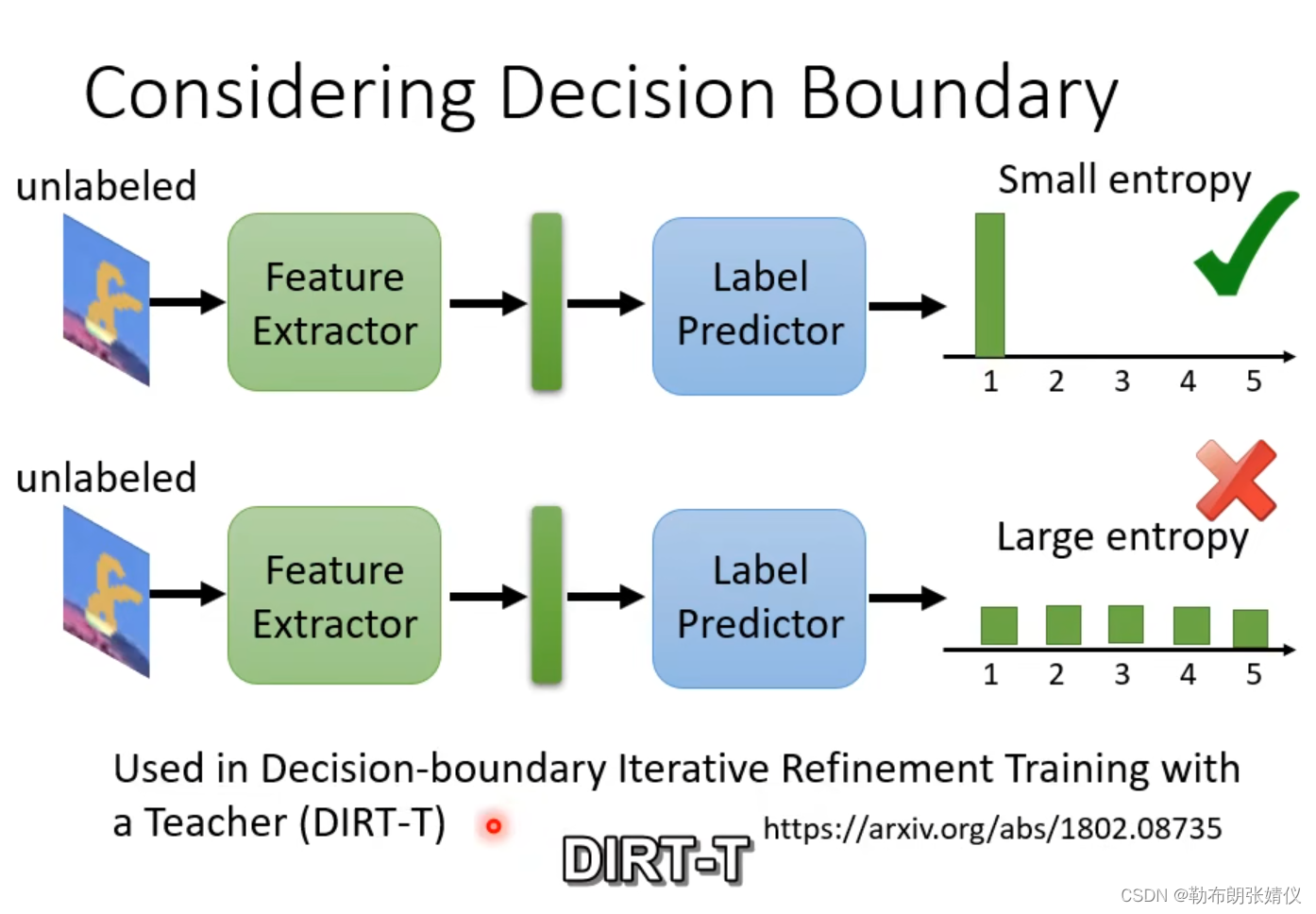
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!