目标检测 详解SSD原理,数据处理与复现
原理详解
前言
今天我们要读的这篇VGGNet(《Very Deep Convolutional Networks For Large-Scale Image Recognition》),就是在AlexNet基础上对深度对网络性能的影响做了进一步的探索。它是ImageNet 2014年亚军,相比于AlexNet,AlexNet只有8层,而VGG有16~19层;AlexNet使用了11x11的卷积核,VGG使用了3x3卷积核和2x2的最大池化层。具体改进效果如何?让我们一起来看一下吧!
论文原文:paper/VGG.pdf at main · shitbro6/paper · GitHub
Abstract-摘要
翻译
在这项工作中,我们研究了卷积网络深度在大规模图像识别环境下对其精度的影响。我们的主要贡献是使用具有非常小(3×3)卷积滤波器的体系结构对增加深度的网络进行了彻底的评估,这表明通过将深度推进到16-19个权重层,可以实现对现有技术配置的显著改进。这些发现是我们2014年ImageNet挑战赛提交的基础,我们的团队在局部化和分类路径上分别获得了第一和第二名。我们还表明,我们的表示法很好地推广到了其他数据集,在这些数据集上,它们获得了最先进的结果。我们已经公开了我们的两个性能最好的ConvNet模型,以促进对计算机视觉中深度视觉表示的使用的进一步研究。
精读
本文研究的问题
本文研究了在大规模图像识别中,卷积网络深度对其识别精度的影响。
本文主要贡献
我们的主要贡献是使用具有非常小(3 ×3)卷积滤波器的架构对于增加了深度的网络的全面评估,这表明将通过将深度推到16-19个权重层可以实现对现有技术配置的显著改进。
一、Introduction—介绍
翻译
卷积网络(ConvNets)最近在大规模图像和视频识别方面取得了巨大成功(Krizhevsky等人,2012年;Zeiler&Fergus,2013;Sermanet等人,2014;Simonyan&Zisserman,2014),这要归功于大型公共图像库,例如ImageNet(邓等人,2009),以及高性能计算系统,如GPU或大规模分布式集群(Dean等人,2012。特别地,ImageNet大规模视觉识别挑战(ILSVRC)(Russakovsky等人,2014)在深度视觉识别体系结构的进步中发挥了重要作用,该挑战已经作为几代大规模图像分类系统的试验台,从高维浅层特征编码(Perronnin等人,2010)(ILSVRC-2011的获胜者)到深度ConvNets(Krizhevsky等人,2012)(ILSVRC-201的获胜者) 随着ConvNets越来越成为计算机视觉领域的必需品,已经进行了许多尝试来改进Krizhevsky等人的原始架构。(2012),以期达到更好的准确性。例如,向ILSVRC2013提交的表现最好的性能(Zeiler&Fergus,2013;Sermanet等人,2014)利用了较小的接受窗口大小和较小的第一卷积层步距。另一项改进涉及在整个图像和多个尺度上密集地训练和测试网络(Sermanet et al.,2014;Howard,2014)。在本文中,我们讨论了ConvNet体系结构设计的另一个重要方面-它的深度。为此,我们固定了结构的其他参数,并通过增加更多卷积层来稳步增加网络的深度,这是可行的,因为在所有层中都使用了非常小的(3×3)卷积滤波器。 因此,我们提出了更精确的ConvNet架构,它不仅在ILSVRC分类和局部化任务上实现了最先进的准确性,而且也适用于其他图像识别数据集,在这些数据集中,即使作为相对简单的管道的一部分使用,它们也可以获得优异的性能(例如,无需微调的线性支持向量机对深度特征进行分类)。我们已经发布了两个性能最好的模型,以方便进一步的研究。 论文的其余部分组织如下。在第2节中,我们描述了我们的ConvNet配置。第三节介绍了图像分类训练和评价的具体内容,并在第四节的ILSVRC分类任务中对两种配置进行了比较。第五节对本文进行了总结。为了完整性,我们还在附录A中描述和评估了我们的ILSVRC-2014对象局部化系统,并在附录B中讨论了非常深入的功能对其他数据集的概括。最后,附录C包含主要论文修订的列表。
精读
介绍卷积网络(ConvNets)的发展和应用
**应用方面:**最近在大规模图像和视频识别方面取得了巨大成功(Overfeat)。
**原因:**这是由于大型公共图像存储库,如ImageNet和高性能计算系统,例如GPU或大规模分布式集群(Tensorflow)。特别是,ImageNet大规模视觉识别挑战赛(ILSVRC)(Russakovsky et al.,2014)在深度视觉识别体系结构的发展中发挥了重要作用,它是几代大型图像分类系统的试验台,从高维浅特征编码(Perronnin等人,2010年)(ILSVRC-2011的获胜者)到深度转换(Krizhevsky等人,2012年)(ILSVRC-2012的获胜者)。
之前对ConvNets精度提高的尝试
1.利用了较小的接受窗口大小和第一卷积层的较小步幅**(处理更小的细节)**
2.改进涉及在整个图像和多个尺度上密集地训练和测试网络**(修改输入网络的数据)**
本文对ConvNets精度提高的改进方法和结果
**方法:**在本文中,我们将讨论ConvNet架构设计的另一个重要方面——深度。为此,我们确定了体系结构的其他参数,并通过添加更多卷积层来稳步增加网络的深度,这是可行的,因为在所有层中使用了非常小的(3×3)卷积核。
**结果:**我们提出了更精确的ConvNet体系结构,不仅在ILSVRC分类和定位任务上达到了最先进的精度,而且还适用于其他图像识别数据集,即使仅作为特征提取器,它们也能获得优异的性能(例如,由线性支持向量机分类的深度特征,无需微调)。为了便于进一步研究,我们发布了两个性能最好的模型(VGG16和VGG19)。
二、ConvNet Configurations—ConvNet配置
翻译
为了在公平的环境下衡量ConvNet深度增加带来的改善,我们所有的ConvNet层配置都是根据相同的原则设计的,灵感来自Ciresan等人。(2011);Krizhevsky等人。(2012年)。在本节中,我们首先描述我们的ConvNet配置的一般布局(第2.1节),然后详细说明评估中使用的具体配置(第2.2节)。然后讨论我们的设计选择,并与第2.3节中的现有技术进行比较。
精读

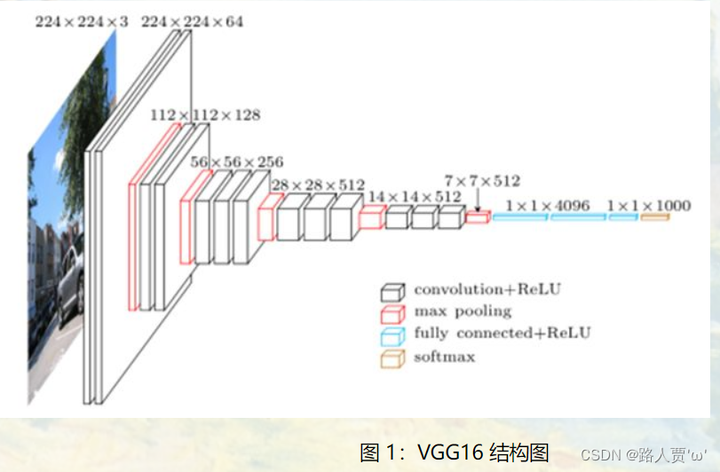
img
2.1Architecture—结构
翻译
在训练过程中,我们的ConvNet的输入是一幅固定大小的224×224 RGB图像。我们所做的唯一预处理是从每个像素减去在训练集上计算的平均RGB值。图像通过一堆卷积(卷积)。层,其中我们使用带有非常小的接收字段的过滤器:3×3(这是捕捉左/右、上/下、中心的概念的最小尺寸)。在其中一种配置中,我们还使用1×1卷积滤波器,可以将其视为输入通道的线性变换(随后是非线性)。卷积步长固定为1像素;卷积的空间填充。层输入是这样的,即在卷积之后空间分辨率保持不变,即对于3×3卷积,填充是1个像素。层次感。空间池化是由五个最大池化层执行的,这些层紧跟在一些圆锥之后。层(不是所有的。层之后是最大池化)。最大合用是在2×2像素窗口上执行的,步长为2。 卷积层的堆栈(在不同的体系结构中具有不同的深度)后面是三个全连接(FC)层:前两个层各有4096个通道,第三个执行1000路ILSVRC分类,因此包含1000个通道(每个类别一个)。最后一层是softmax层。所有网络中的完全连接层的配置都是相同的。 所有隐藏层都配备了校正(RELU(Krizhevsky等人,2012))非线性。我们注意到,我们的所有网络(除了一个网络)都没有包含本地响应归一化(LRN)归一化(Krizhevsky等人,2012年):如第4节所示,这种归一化不会提高ILSVRC数据集的性能,而是导致内存消耗和计算时间增加。在适用的情况下,LRN层的参数是(Krizhevsky等人,2012年)的参数。
精读
深度是卷积神经网络架构的一个重要方面。为了使深度更深,作者将卷积层中卷积核尺寸都设为很小——3×3,将卷积层数量加大,使深度更深,事实证明是可行的。
方法
**1.输入:**一个固定大小的224*224RGB图像
**2.唯一预处理:**将输入的224×224×3通道的像素值,减去平均RGB值,然后进行训练
**3.卷积核:**①使用最小尺寸的卷积核3×3这个尺寸也是能捕捉上下左右和中间方位的最小尺寸
? ②有些卷积层中还使用了1×1大小的卷积核(FC层之间的),可看作是输入通道的线性变换
● 为什么3个3x3的卷积核可以代替7x7的卷积? **①得到更好的拟合效果。**3个3x3的卷积,使用了3个ReLU函数非线性校正,增加了非线性表达能力,比一个ReLU的单层Layer更具有识别能力,使得分割平面更具有可分性 **②减少网络参数个数。**对于C个通道的卷积核,7×7×C×C 比3×3×C×C的参数量大。 ● 1x1卷积核的作用? ①在不影响感受野的情况下,增加模型的非线性性 ②1x1卷积相当于线性变换,非线性激活函数起到非线性作用
**4.卷积步幅 :**卷积步幅固定为1像素,3×3卷积层的填充设置为1个像素。
**5.池化层:**池化层采用空间池化,空间池化有五个最大池化层,他们跟在一些卷积层之后,但是也不是所有的卷积层后都跟最大池化。最大池化层使用2×2像素,步幅为2。
**6.卷积层:**一个卷积层(在不同的体系结构中具有不同的深度)之后是三个完全连接的(FC)层:前两个层各有4096个通道,第三个层执行1000路ILSVRC分类,因此包含1000个通道(每类一个)(1000分类对应ImageNet-1K)。最后一层是softmax层,用来分类。在所有网络中,完全连接的层的配置都是相同的。
**7.隐藏层:**所有隐藏层都有ReLU非线性函数,网络除了第一个其他都不包含局部响应归一化(LRN)(原因:论文中,作者指出,虽然LRN在AlexNet对最终结果起到了作用,但在VGG网络中没有效果,并且该操作会增加内存和计算,从而作者在更深的网络结构中,没有使用该操作)
img
2.2Configurations—配置
翻译
该篇论文中卷积网络的设置在表格1中展示出来。在接下来的环节中我们将使用它们的代词(A-E)。所有通用的设置在2.1节中叙述完,唯一的不同点就在于网络的深度:从A中的11层(8层卷积+3层全连接层)到E中的19层(16层卷积+3层全连接层)。卷积层的宽度(即通道数)是相对小的,从第一层的64,每经过一层最大池化层就扩大2倍,直到达到512。
表一:ConvNet配置(以列展示)。配置的深度从左(A)向右(E)增加,添加了更多的层(添加的层以粗体表示)。卷积层参数表示成“conv<感受野大小>-<通道数量>”。为了简洁,未展示ReLU激活函数。

img
表二:在表2中,我们报告了每种配置的参数数量。尽管有很大的深度,但我们的网中的权重数并不比更浅、更大圆度的网中的权重数多。层宽度和感受野(144m重量(Sermanet等人,2014年))。
精读
1.这个表的对比是一个对照实验组。
2.我们可以看到第一个A组有11层(8卷积层+3全连接层,只算带权重的层 所以池化层不算)。另一个A组加上LRN。D,E组就是在上文中见到的VGG16和VGG19。C和D都是16层,他俩的区别是C组使用了1×1的卷积核,而D组都是3 × 3 卷积核。
3.图中加粗的就是增加的或者修改的层。
4.这里面是有Relu函数的,作者没有标明出来。
具体对比结果我们下一节详细讨论。
2.3Discussion—讨论
翻译
我们的ConvNet配置与ILSVRC-2012(Krizhevsky等人,2012)和ILSVRC-2013比赛(Zeiler&Fergus,2013;Sermanet等人,2014)表现最好的参赛作品中使用的配置有很大不同。而不是在第一层conv中使用相对较大的感受野。(例如,在(Krizhevsky等人,2012)中为11×11,步长为4,或在(Zeiler&Fergus,2013;Sermanet等人,2014)中为7×7,步长为2),我们在整个网络中使用非常小的3×3感受野,这些感受野在每个像素处与输入卷积(步长为1)。很容易看到两个3×3 conv堆叠。各层(中间无空间混合)的有效感受野为5×5,其中3层的有效感受野为7×7。那么,比方说,使用三个3×3卷积的堆叠,我们得到了什么呢?而不是单一的7×7层?首先,我们加入了三个非线性校正层而不是单个校正层,使得决策函数更具区分性。其次,我们减少了参数的数量:假设一个三层3×3卷积叠加的输入和输出都有C个通道,该叠加由3(32C2)=27C2权重参数化;同时,单个7×7卷积,层将需要72C2=49C2参数,即比27C2多81%。这可以看作是对7×7卷积施加了正规化过滤器,迫使它们通过3×3的过滤器进行分解(在其间注入非线性)。
精读
对比第一个卷积层感受野大小:
本文章中的网络配置与前面一些表现非常好的网络配置比较不一样(例如AlexNet和OverFeat),VGG在整个网络使用了非常小的感受野而不是在第一个卷积层使用相对来说比较大的卷积层(AlexNet中卷积核大小为11×11步长为4,OverFeat中卷积核大小为7×7步长为2)
感受野相关问题 **感受野(Receptive Field)**的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点跟原图上有关系的点的区域。
img
我们可以通过上图看出,在卷积神经网络 中,越深层的神经元看到的输入区域越大。上图中的卷积核大小均为3×3,步幅均为1,绿色标记的是Layer2每个神经元看到的区域,黄色标记的是Layer3看到的区域。这样我们就可以很明显的看出来,Layer2每个神经元可看到的Layer1上3×3大小的区域,Layer3每个神经元看到的是Layer2上3×3大小的区域,同时,该区域可以看到Layer1上5×5大小的区域。 动态效果可以看下图:
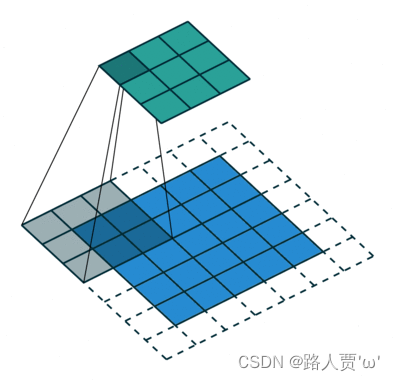
img
好处
通过对卷积层作用的评估,可以很容易看出来两个3 × 3的卷积层可以起到一个5 × 5 卷积层的作用,三个3×3的卷积层可以起到一个7 × 7卷积层的作用。
为什么有这样的作用?
1.合并了三个非线性ReLU层,不是只用一个,使得决策函数更具有判别性。
2.减少了参数数量。
三、Classification Framework—分类框架
3.1Training—训练
(1)步骤和参数
翻译
ConvNet训练过程一般遵循Krizhevsky等人的做法。(2012)(除了对来自多尺度训练图像的输入作物进行采样之外,如后面所解释的)。即,通过使用带动量的小批量梯度下降(基于反向传播(LeCun等人,1989))来优化多项式Logistic回归目标来执行训练。批量设置为256,动量为0.9。训练通过权重衰减(L2惩罚倍数设置为5·10?4)和前两个完全连接的层的dropout规则化(dropout率设置为0.5)来归一化。学习速率最初设置为10?2,当验证集精度停止提高时,学习率降低到原来的1/10。总共降低了3倍的学习速率,并在37万次迭代(74个epochs)后停止学习。我们猜测,尽管与(Krizhevsky等人,2012年)相比,我们的网络有更多的参数数量和更深的网络,网络收敛所需的epochs更少由于(a)更大深度和更小Conv过滤器大小施加的隐式正则化;(b)某些层的预初始化。
精读
卷积网络训练步骤大致跟随AlexNet,除了从多尺度训练图像中对输入进行采样,也就是说通过使用小批量梯度下降法优化多项式逻辑回归来进行训练。同时添加了L2正则项进行正则化,使用Dropout减少全连接层过拟合,并且应用了学习率退火,具体参数设置如下:
| 参数名 | 大小 |
|---|---|
| batch size(批量大小) | 256 |
| momentum(动量) | 0.9 |
| weight decay(权重衰减) | 0.0005 |
| dropout ratio(随机失活率) | 0.5 |
| learning rate(学习率) | 0.01 |
| 迭代步数 | 370K |
| epoches(轮数) | 75 |
● 学习率退火: 当验证集的准确率停止提升的时候除以10,学习率总共下降了三次,一共经过了74个Epochs
网络能更快收敛的原因?(与AlexNet相比,VGGnet有更多的参数和更大的深度)
①较大深度和较小的卷积核所施加的隐式正则化
②某些层的预初始化
正则化相关问题 ● 正则化 旨在更好实现模型泛化的补充技术,即在测试集上得到更好的表现。 ● L1和L2正则化 L1正则化会让特征变得稀疏,起到特征选择的作用; L2正则化会让模型变得更简单,防止过拟合,而不会起到特征选择的作用。 ● 隐式正则化 没有直接对模型进行正则化约束,但间接获取更好的泛化能力。 1、数据标准化,平滑优化目标函数曲面; 2、数据增强,扩大数据集规模; 3、随机梯度下降算法
(2)初始化权重
翻译
网络权值的初始化很重要,因为由于深层网络中梯度的不稳定性,错误的初始化可能会导致学习停滞。为了绕过这个问题,我们从训练配置A(表1)开始,它足够浅,可以通过随机初始化进行训练。然后,当训练更深的体系结构时,我们用Net A的层初始化前四个卷积层和最后三个全连通层(中间层是随机初始化的)。我们没有降低预初始层的学习速率,允许它们在学习过程中改变。对于随机初始化(如果适用),我们从具有零均值和10?2方差的正态分布中抽样权重。偏差被初始化为零。值得注意的是,在论文提交后,我们发现可以使用Glorot&Bengio(2010)的随机初始化过程来初始化权重,而不需要预先训练。
精读
原因
因为深度网络中梯度的不稳定性,错误的初始化会阻碍学习。
方法
开始训练配置A,通过随机初始化进行训练,然后对更深层次网络结构训练。将前四层卷积层和后三个FC层都按照A网络的初始化配置设置,中间层接着随机初始化。没有减少预初始化层的学习率,而是让它们随着学习的进程发生改变。
采样参数
对于随机初始化,我们从一个均值为0方差为0.01的正态分布中对权重进行采样,偏置初始化为0。
证明结论
即使随机初始化所有的层,模型也能训练的很好。
后期发现
使用随机初始化程序可以在不进行预训练的情况下初始化权重。
(3)数据增广
翻译
为了获得固定大小的224×224 ConvNet输入图像,从重新缩放的训练图像中随机裁剪它们(每次SGD迭代每个图像一个裁剪)。为了进一步增加训练集,这些作物经历了随机水平翻转和随机RGB颜色变换(Krizhevsky等人,2012年)。下面解释训练图像的重新缩放。 Training image size.设S是各向同性重新缩放的训练图像的最小边,从中裁剪ConvNet输入(我们也将S称为训练比例)。当裁剪大小固定为224×224时,原则上S可以采用不小于224时的任何值:对于S=224时,裁剪将捕获整个图像统计,完全覆盖训练图像的最小边;对于S?224,裁剪将对应于包含小对象或对象部分的图像的一小部分。 我们考虑了两种设置训练尺度S的方法。第一种是固定S,其对应于单尺度训练(请注意,采样作物内的图像内容仍然可以代表多尺度图像统计)。在我们的实验中,我们评估了在两个固定尺度上训练的模型:S=256(这在现有技术中已经被广泛使用(Krizhevsky等人,2012年;Zeiler&Fergus,2013;Sermanet等人,2014))和S=384。在给定ConvNet配置的情况下,我们首先使用S=256训练网络。为了加快S=384网络的训练速度,用S=256时预先训练的权值进行了初始化,并使用了较小的初始学习率10?3。 设置S的第二种方法是多尺度训练,其中每个训练图像通过从特定范围[Smin,Smax] (我们使用Smin=256和Smax=512)随机采样S来单独重新缩放。由于图像中的对象可以具有不同的大小,因此在训练期间考虑这一点是有益的。这也可以被看作是通过尺度抖动来扩大训练集,其中单个模型被训练来识别大范围尺度上的对象。出于速度的原因,我们通过微调具有相同配置的单尺度模型的所有层来训练多尺度模型,预先训练固定的S=384。
精读
方法
对图片进行缩放后裁剪出224 × 224大小的图片,然后进行随机水平翻转和随机的RGB通道切换。
训练尺度S
训练用到的224 × 224的图片是从缩放后的原始图片中裁剪出来的,而缩放不仅仅可以缩小也可以放大,记图片缩放后的最短边的长度为S,也称为训练尺度(training scale)。
**S的取值:**当裁剪尺寸固定为224*224时,原则上S可以取不小于224的任何值:对于S=224来说,裁剪将会捕获整个的图像统计数据,将会完整横跨训练图像的最小边。对于S ? 224,裁剪将会对应于图像的一小部分,包括一个小对象或者对象的一部分。
有两种设置训练尺度S的办法
1、使用固定的S(单尺度的训练),本文使用了两种大小:256(应用于AlexNet,ZFNet,Sermanet)和384。
2、使用变化的S(多尺度的训练),给定一个S变化的范围[ Smin , Smax ](https://zhuanlan.zhihu.com/文章中使用的范围是[ 256 , 512 ]),使其在这个范围中随机选值来缩放图片。
3.2Testing—测试
翻译
在测试时,给定一个训练好的ConvNet和一个输入图像,它按以下方式分类。首先,将其各向同性地重新缩放到预定义的最小图像侧,表示为Q(我们也将其称为测试比例)。我们注意到Q不一定等于训练尺度S(正如我们将在第4节中说明的那样,对每个S使用几个Q值可以提高性能)。然后,以类似于Sermanet等人的方式在重新缩放的测试图像上密集地应用网络(Sermanet等人,2014)。也就是说,首先将完全连通的层转换为卷积层(第一FC层转换为7×7卷积。层,最后两个FC层为1×1 Conv。层)。然后,将得到的完全卷积网络应用于整个(未裁剪)图像。结果是一个类分数图,其通道数等于类数,空间分辨率可变,具体取决于输入图像的大小。最后,为了获得图像的固定大小的班级分数向量,对班级分数地图进行空间平均(总和)。我们还通过水平翻转图像来扩充测试集;对原始图像和翻转图像的软最大类后验进行平均,以获得图像的最终分数。 由于全卷积网络应用于整个图像,因此不需要在测试时对多个作物进行采样(Krizhevsky等人,2012),这样效率较低,因为它需要为每个作物重新计算网络。同时,正如Szegedy等人所做的那样,使用了大量的作物。(2014),可以提高精度,因为与全卷积网络相比,它可以对输入图像进行更精细的采样。此外,由于不同的卷积边界条件,多作物评估与密集评估是互补的:当将卷积网络应用于作物时,卷积的特征地图用零填充,而在密集评估的情况下,相同作物的填充自然来自图像的相邻部分(由于卷积和空间汇集),这大大增加了整个网络接收区域,因此捕获了更多的上下文。虽然我们认为,在实践中,多作物计算时间的增加并不能证明在精度方面的潜在收益是合理的,但为了参考,我们也使用每尺度50种作物(5×5规则网格,2个翻转)来评估我们的网络,针对3个尺度上的150个作物,这与Szegedy等人使用的4个尺度上的144个作物相当。
精读
方法
将全连接层等效替换为卷积层进行测试
原因
卷积层和全连接层的唯一区别就是卷积层的神经元和输入是局部联系的,并且同一个通道(channel)内的不同神经元共享权值(weight)。卷积层和全连接层的计算实际上相同,因此可以将全连接层转换为卷积层。
**改造前:**假设网络是这样的 N个卷积 -> 全连接 -> 全连接。假如N个卷积之后的数据变成7x7x512 则此时展成向量变成 25088个元素的向量,通过一个4096神经元的全连接层 ,变成4096个元素的向量,再通过一个1000个神经元的全连接,最后输出1000个元素的向量。
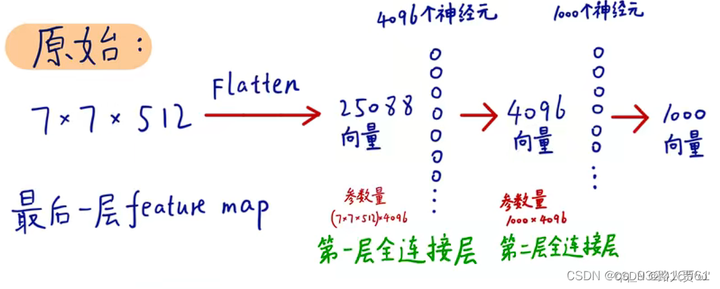
img
(图片来自b站up主:同济子豪兄。下同)
**改造后:**当得到前面的数据 7x7x512之后,不将其展开成向量,而是直接送去有 4096 个 7×7卷积核的卷积层,对比改造之前看,其实就是将改造之前的全连接层里的4096个单神经元变成了 7×7的卷积核,参数依旧是等量的。同理,后面就变成了1000个1×1卷积核的卷积层(实际上论文中是三层全连接层,改为一个7x7卷积层和两个 1×1卷积层,他这里少画了一层1×1的卷积层)
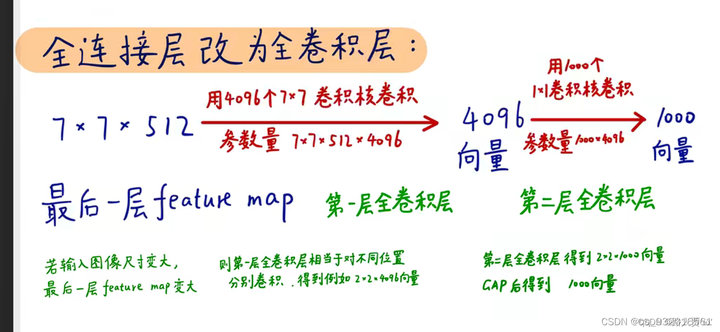
img
目的
1.输入图像的大小不再受限制,因此可以高效地对图像作滑动窗式预测。
2.而且全连接层的计算量比较大,等效卷积层的计算量减小了,这样既达到了目的又十分高效。
3.3Implementation Details—实现细节
翻译
我们的实现源自公开可用的C++ Caffe工具箱(Jia,2013)(2013年12月扩展),但包含许多重大修改,允许我们在单个系统中安装的多个GPU上执行训练和评估,以及在多个比例(如上所述)的全尺寸(未裁剪)图像上进行训练和评估。多GPU训练利用数据并行性,通过将每批训练图像分成几个GPU批次来执行,这些批次在每个GPU上并行处理。在计算GPU批次梯度之后,对它们进行平均,以获得整个批次的梯度。所有GPU之间的渐变计算是同步的,因此结果与在单个GPU上训练时完全相同。 虽然最近提出了更复杂的加速ConvNet训练的方法(Krizhevsky,2014),这些方法针对网络的不同层使用模型和数据并行,但我们发现,与使用单个GPU相比,我们在概念上简单得多的方案已经在现成的4-GPU系统上提供了3.75倍的加速比。在配备了四个NVIDIA Titan Black GPU的系统上,根据架构的不同,训练一个网络需要2-3周时间。
精读
**1.多个GPU上训练:**实现使用的是基于C++的Caffe toolbox,并且还做了一系列的优化,可以在单个系统中安装的多个GPU上执行训练和评估,以及训练和评估多尺度的全尺寸(未裁剪)图像。
**2.分为多个GPU批次:**通过将每批训练图像分成几个GPU批次,在每个GPU上并行处理来进行,计算GPU批次梯度后,对它们进行平均可以获得完整批次的梯度。因此结果与在单个GPU上训练的结果是一样是的,但是可以节约很多时间。
**3.花费的时间:**该模型在配备有4个NVIDIA Titan Black GPU的机器上训练一个架构需要花费2-3周的时间
四、Classification Experiments—分类实验
4.1数据集:ILSVRC-2012
翻译
数据集 在本节中,将展示我们提出的卷积网络架构在ILSVRC-2012数据集(用于ILSVRC2012-2014挑战)上获得的图像分类结果。数据集包括1000个类的图像,并分为三组:训练(130万张图像)、验证(50K张图像)和测试(100K个保留类标签的图像)。分类性能通过两个指标进行评估: the top-1 and top-5 error。前者是一种多类分类误差,即错误分类图像的比例;后者是ILSVRC中使用的主要评价标准,并且计算图像gt 不在top-5 predicted categories的比例。
对于大多数实验,我们使用验证集作为测试集。某些实验也在测试集上进行,并作为ILSVRC-2014竞赛的“VGG”团队参赛作品提交给官方。
精读
**分类:**这个数据集有1000个类,包含三个部分:训练集(1.3M),验证集(50K),测试集(100K),可以通过两个指标来评估准确率:top-1和 top-5误差。
top-1和 top-5误差 top-1误差:是一个多类分类误差,表示分类错误图片的比例(模型猜的最可能的结果就是正确答案的概率) top-5误差:是竞赛评估的主要指标,表示了真实的类别不在预测到的概率最大的五个类别中的错误率(模型猜的前五个结果里面包涵正确答案的概率)
4.2Single Scale Evaluation—单尺度评价(测试角度)
翻译
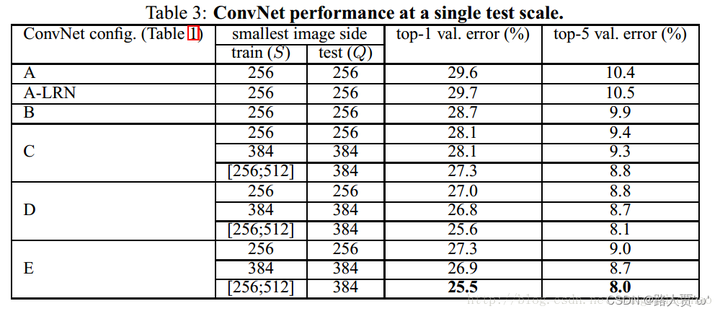
我们首先用章节2.2中描述的网络配置在单一尺度上评估单个ConvNet模型的性能。.测试图像大小设置如下:Q=S,固定的S,Q=0.5(Smin+Smax),S∈[Smin,Smax]。结果如表3所示。首先,我们注意到使用局部响应归一化(A-LRN网络)在没有任何归一化层的改进模型A。因此,我们不在更深层次的架构中使用标准化(B-E)。
img
其次,我们观察到分类误差随着ConvNet深度的增加而减小:从A的11层减少到E的19层。值得注意的是,尽管有相同的深度,配置C(它包含三个1×1conv层),性能比配置D差,后者使用3×3conv。贯穿整个网络的图层。这表明,虽然额外的非线性确实有帮助(C比B好),但是通过使用大的卷积核的来捕获空间上下文也很重要。(D优于C)。当深度达到19层时,我们的体系结构的错误率达到饱和,但更深的模型可能有利于更大的数据集。我们还比较了B结构,在浅层把每对3×3conv换成1个5×5conv层(它有相同的感受野。)浅层网的前1误差比B((on a center crop)高7%,这证实了具有小滤波器的深网优于大滤波器的浅层网。 最后,在训练时的尺度变化(S∈[256;512])明显比训练固定最小边的图像(S=256或S=384),即使在测试时使用单一的尺度。这证实了通过尺度变化增强训练集确实有助于捕获多尺度图像统计数据。
精读
采用的方法
训练尺度S:(1)一种方法是固定S的大小
? (2)另一种方法是从一定区间内随机取S(测试集记为Q)
**具体实现:**测试时所用的scale固定。这里把训练scale和测试的scale分别用S和Q表示。当S为固定值时,令Q=S固定;当S为[Smin,Smax]浮动时,Q固定为=0.5[Smin + Smax]。
结论
(对比表格放在翻译里了~)
1.测试发现A组和A-LRN组的top1和top5错误率几乎持平,LRN局部响应归一化并没有带来精度提升,故在A-LRN之后的B~E类VGG网络中,都没有使用。
2.变动的S比固定的S准确率高。在训练中,采用浮动尺度效果更好,因为这有助于学习分类目标在不同尺寸下的特征。
3.卷积网络越深,损失越小,效果越好。
4.C优于B,表明增加的非线性ReLU有效。
5.D优于C,表明卷积层3×3对于捕捉空间特征有帮助。
6.E深度达到19层后达到了损失的最低点,达到饱和,更深的层次对精度没有提升,但是对于其他更大型的数据集来说,可能更深的模型效果更好。
7.B和同类型卷积核为5×5的网络进行了对比,发现其top-1错误率比B高7%,表明小尺寸卷积核效果更好。
4.3Multi Scale Evaluation—多尺度评价(测试角度)
翻译
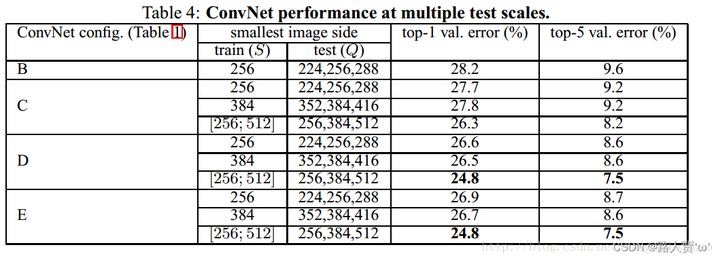
在单一尺度上评估了ConvNet模型之后,我们现在评估了测试时尺度抖动的影响。它包括在一个测试图像的几个重新缩放的版本(对应于不同的Q值)上运行一个模型,然后平均得到的类后验。考虑到训练量表和测试量表之间的很大差异会导致性能下降,用固定S训练的模型在三个测试图像大小上进行评估,接近训练一个:Q={S?32,S,S+32}。同时,训练时的尺度抖动允许网络在测试时应用于更广泛的尺度范围,因此使用变量S∈[Smin;Smax]训练的模型在更大的尺寸Q = Smin, 0.5(Smin+Smax) ,Smax范围内进行评估.
结果如表4所示,表明测试时的尺度抖动导致更好的性能(与在单一尺度上评价相同的模型相比,如表3所示)。与之前一样,最深的配置(D和E)表现最好,规模抖动比固定最小边训练更好。我们在验证集上的最佳单网络性能是24.8%/7.5%top1/top5错误(在表4中以粗体突出显示)。在测试集上,配置E达到了7.3%的前5名错误。
img
精读
方法
multi-scale表示测试时的scale不固定。这里当训练时的S固定时,Q取值是{S-32,S,S+32}这三个值,进行测试过后取平均结果。当S为[Smin,Smax]浮动时,Q取{Smin,0.5(Smin+Smax),Smax},测试后取平均。
结论
1.同single scale一样,模型越深,效果越好
2.同深度下,浮动scale效果好于固定scale
4.4Multi-Crop Evaluation—多剪裁评价(测试输入角度)
翻译
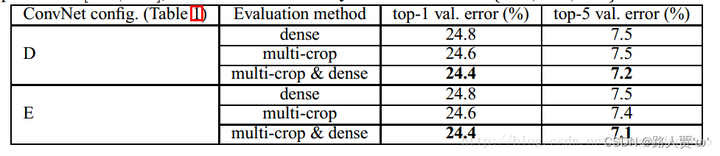
在表5中,我们比较了密集的ConvNet评价和Multi-Crop评价(见第二节。3.2的细节)。我们还通过平均它们的softmax输出来评估这两种评估技术的互补性。可以看出,使用Multi-Crop的性能略优于密集评估,而且这两种方法确实是互补的,因为它们的组合性能优于每一种方法。如上所述,我们假设这是由于对卷积边界条件的不同处理。
img
精读
dense evaluation 与multi-crop evaluation两种评估方法的区别
**①multi-crop:**即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均。GoogleNet中使用了很多multi-crop的技巧,可以显著提升精度,因为有更精细的采样。
**②dense :**就是在上章说的将全连接层都变成卷积网络的那种训练方式。
方法
在表5中我们比较了密集评估与多裁剪评估。我们还通过平均Softmax输出来评估两种评估技术的互补性。
结果
ConvNet评估技术对比。在所有的实验中训练尺度S是从[256; 512]中抽取的,3个测试尺度Q是从{256,384,512}中抽取的。
结论
1.使用multi-crop优于dense
2.这两种方法是互补的
3.multi-crop+dense方法结合的效果最好
4.5ConvNet Fusion—ConvNet融合
翻译
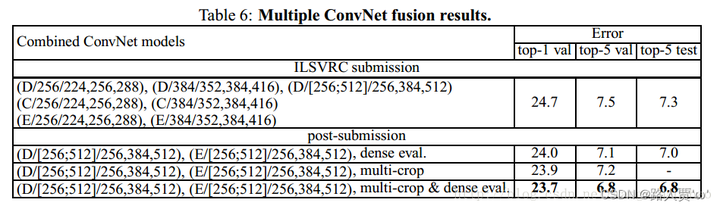
到目前为止,我们评估了各个ConvNet模型的性能。在这部分的实验中,我们通过平均它们的类后验来组合几个模型的输出。由于模型的互补性,这提高了性能,并在2012年(Krizhevsky et al., 2012) and 2013 (Zeiler & Fergus, 2013; Sermanet et al., 2014). 结果如表6所示。到ILSVRC提交时,我们只训练了单尺度网络,以及多尺度模型D(通过只微调全连接的层,而不是所有的层)。7个网络的集成有7.3%的ILSVRC测试误差。提交后,我们只考虑了两个表现最好的多尺度模型(配置D和E)的集合,使用密集评估将测试误差降低到7.0%,使用密集和多作物联合评估将测试误差降低到6.8%。作为参考,我们表现最好的单个模型达到了7.1%的误差(模型E,表5)
img
精读
方法
到目前为止,我们只计算了一个ConvNet模型的性能。在实验部分,我们通过平均几个模型的soft-max类的后验概率来结合输出。由于模型之间的互补,这种方法提高了性能。
结果
结果展示在表6中。到ILSVRC提交的时间,我们仅仅训练了一个单一尺度的网络,和一个多尺度的模型D(仅仅通过微调了全连接层而不是所有层)。
结论
1.结合多个模型,最后的结果通过softmax平均再结合判断,由于模型之间的互补性质,这会提高他们的性能。
2.融合之后网络的错误率要比单个网络的错误率低0.几个百分点。
3.使用multi-crop+dense结合的方法会使得效果更佳。
4.6Comparision With The State of The Art—与最新技术的比较
(State of the art(SOTA)——当前最佳性能/技术/算法,论文中会经常看到)
翻译
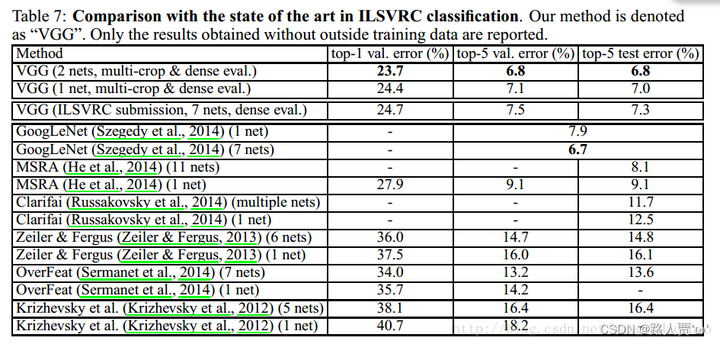
最后,我们将我们的结果与表7中的最新技术水平进行了比较。在ILSVRC-2014挑战的分类任务中,我们的“VGG”团队使用7个模型的集合,以7.3%的测试误差获得了第二名。提交后,我们将使用2个模型的集合错误率降低到 6.8%。
img
从表7可以看出,我们非常深的ConvNets的表现明显优于上一代的模型,在ILSVRC-2012和ILSVRC-2013的比赛中取得了最好的效果。我们的结果也与分类任务获胜者(GoogLeNet with 6.7% error))具有竞争力,大大优于ILSVRC-2013获奖提交的clarfai,在使用外部训练数据达到11.2%,在没有训练数据的情况下达到11.7%。这是值得注意的,因为我们的最佳结果是通过结合两个模型——明显少于在大多数ILSVRC提交中使用的模型。在单网性能方面,我们的架构获得了最佳的结果(7.0%的测试错误),比单个GoogLeNet高出0.9%。值得注意的是,我们并没有背离LeCun等人(1989)的经典ConvNet架构,而是通过大幅增加深度而改进了它。
精读
这部分不重要,作者就是想说我们的模型就是强,你们是弟弟,即使第一名的Googlenet,我们也只和他们差一点点,在雷式对比法中甚至还强些~
五、Conclusion—结论
翻译
在这项工作中,我们评估了非常深的卷积网络(多达19个层)的大尺度图像分类。结果表明,表示深度有利于分类精度,并且可以使用传统的ConvNet大幅增加深度 挑战数据集上实现最先进的性能。在附录中,我们还展示了我们的模型可以很好地推广到广泛的任务和数据集,匹配或优于围绕较不深的图像表示构建的更复杂的识别管道。我们的研究结果再次证实了深度在视觉表征中的重要性。
精读
1.在这次的工作中,我们评估了大尺度图像分类汇总非常深的卷积神经网络的作用,他展示了模型的深度对于分类准确率的重要性。
2.同时在附录中,我们也展示了我们的模型更广范围的任务以及数据集上得到一个很好的泛化效果。
3.最后,我们的结论再一次证明了深度在视觉表征中的重要性
论文十问
Q1:论文试图解决什么问题? 本文研究了在大规模图像识别中,卷积网络深度对其识别精度的影响。 Q2:这是否是一个新的问题? 不算,因为它是在Alex模型基础上增加了深度。 Q3:这篇文章要验证一个什么科学假设? 证明使用更小的卷积核并且增加卷积神经网络的深度,可以更有效地提升模型的性能。 Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员? AlexNet,都属于图像识别,提高精度的问题 Q5:论文中提到的解决方案之关键是什么? 1.用三个3×3的卷积核代替7×7的卷积核,有的FC层还用到了1×1的卷积核。以及2×2的池化层。 2.在更深的结构中没有用到LRN(推翻了Alex),避免了部分内存和计算的增加。 3.使用了密集型训练方法(全连接->卷积层),可适应各种尺寸的图片。 4.将图像分为多个GPU批次,在多个GPU上进行训练,节省了时间。 5.进行分类试验。 Q6:论文中的实验是如何设计的? 1.采用ImageNet2012数据集 2.Single Scale Evaluation—单尺度评价 3.Multi Scale Evaluation—多尺度评价 4.Multi Crop Evaluation—多剪裁评价 5.ConvNet Fusion—ConvNet融合 Q7:用于定量评估的数据集是什么?代码有没有开源? ImageNet2012,代码有开源 Q8:论文中的实验及结果有没有很好地支持需要验证的科学假设? 论文实验结果在ILSVRC-2014挑战赛的分类任务中,我们的“VGG”团队使用7个模型的融合用7.3%的测试错误率达得到了第2。提交之后,我们使用2个模型的融合将错误率减少到了6.8%。足以证明增加深度对精度识别很重要。 Q9:这篇论文到底有什么贡献? 我们的主要贡献是使用具有非常小(3 ×3)卷积核的架构对于增加了深度的网络的全面评估,这表明将通过将深度推到16和19个权重层可以实现对现有技术配置的显著改进。 Q10:下一步呢?有什么工作可以继续深入? 1.VGG在Alex基础上将卷积核都替换为了1×1及3×3的小卷积核以减少参数计算量,虽然 VGG减少了卷积层参数,但实际上其参数空间比 Alex大,其中绝大多数的参数都是来自于第一个FC,耗费更多计算资源。 2.VGG模型比较简单,可以以它为基础进行改进。
VGG在深度学习的历史上是很有意义的,它的结构简单易懂,在当时仅次于大名鼎鼎的GoogLeNet,证明了神经网络更深表现会更好,最重要的是 VGG 向世人证明了更小的卷积核尺寸的重要性。 本篇VGG论文解读就到此为止了,欢迎大家留言交流呀~
数据处理
前言
SSD代码详解数据篇,旨在全方位介绍数据从下载到数据增强,最后封装为pytorch的data_loader过程。
其中,涉及了目标检测领域绝大部分的数据增强方式,亮度、对比度、色调、裁剪、扩充等等方法。
目录
-
下载数据
-
数据dataset
-
数据增强
-
-
- 数据类型转换
-
- Transform Compose
-
- IOU计算
-
- bbox坐标变化
-
- 图片 Resize
-
- 图片色彩转换
-
- 色调Hue变化
-
- 饱和度变化
-
- 亮度变化
-
- 对比度变化
-
- 颜色通道变化
-
- 图片镜像
-
- 图片随机裁剪
-
- 图片扩充
- 汇总
-
下载数据
进入到自己的data文件夹,执行下面的脚本即可下载并解压好 VOC2017 & VOC2012 的数据。
脚本代码:
cd ./data
echo "Downloading VOC2007 trainval ..."
# 下载数据
curl -LO http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
echo "Downloading VOC2007 test data ..."
curl -LO http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
echo "Done downloading."
# 解压数据
echo "Extracting trainval ..."
tar -xvf VOCtrainval_06-Nov-2007.tar
echo "Extracting test ..."
tar -xvf VOCtest_06-Nov-2007.tar
echo "removing tars ..."
# 删除压缩包
rm VOCtrainval_06-Nov-2007.tar
rm VOCtest_06-Nov-2007.tar
然后稍微整理,把VOC2007, VOC2012放在同一个目录下,如下:
├── data
│ ├── VOC
│ ├── VOCdevkit
│ ├── VOC2017
│ ├── VOC2012
数据dataset
1. Annotation Tranform:
VOCAnnotationTransform() 需要把VOC的xml数据提取并且转化,提取bbox坐标进行归一化,并且把类别转化为字典格式,最后把数据组合为: [[xmin, ymin, xmax, ymax, label_ind],...]
- VOC数据类别和目录:
VOC_CLASSES = (
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
VOC_ROOT = "E:/TZ_WK/VOC/VOCdevkit"
VOCAnnotationTransform:
class VOCAnnotationTransform(object):
"""
把VOC的annotation中bbox的坐标转化为归一化的值;
将类别转化为用索引来表示的字典形式;
Args:
class_to_ind: (dict)类别的索引字典
keep_difficult: 是否保留difficult=1的物体
"""
def __init__(self, class_to_ind=None, keep_difficult=False):
self.class_to_ind = class_to_ind or dict(
zip(VOC_CLASSES, range(len(VOC_CLASSES))))
self.keep_difficult = keep_difficult
def __call__(self, target, width, height):
"""
Args:
target: xml被读取的一个ET.Element
width: 图片宽度
height: 图片高度
Return:
res: list, [bbox coords, class name]
-->eg: [[xmin, ymin, xmax, ymax, label_ind],...]
"""
res = []
for obj in target.iter('object'):
# 判断difficult
difficult = int(obj.find('difficult').text) == 1
if not self.keep_difficult and difficult:
continue
# 读取xml中所需的信息
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
# bbox的表示
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# 归一化,x/w, y/h
cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
# 提取类别名称对应的 index
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res += [bndbox]
return res
# 代码调试
if __name__ == "__main__":
vocan = VOCAnnotationTransform()
res = vocan(target, width, height)
print('The transform res:')
print(res)
输出:
The transform res:
[[0.13314447592067988, 0.478, 0.5495750708215298, 0.74, 11],
[0.019830028328611898, 0.022, 0.9943342776203966, 0.994, 14]]
2. VOC Detection Dataset:
根据Annotation Transform 和 VOC的数据结构,读取图片, bbox和label,构建VOC的数据集。
class VOCDetection(data.Dataset):
def __init__(self, root,
image_sets = [('2007', 'trainval'), ('2012', 'trainval')],
transform = None,
target_transform = VOCAnnotationTransform(),):
self.root = root
self.image_set = image_sets
self.transform = transform
self.target_transform = target_transform
# bbox和label
self._annopath = os.path.join('%s', 'Annotations', '%s.xml')
# 图片path
self._imgpath = os.path.join('%s', 'JPEGImages', '%s.jpg')
self.ids = list()
for (year, name) in image_sets:
rootpath = os.path.join(self.root, 'VOC' + year)
for line in open(os.path.join(rootpath, 'ImageSets', 'Main', name + '.txt')):
self.ids.append((rootpath, line.strip()))
def __getitem__(self, index):
img_id = self.ids[index]
# label 信息
target = ET.parse(self._annopath % img_id).getroot()
# 读取图片信息
img = cv2.imread(self._imgpath % img_id)
h, w, c = img.shape
# Annotation transform
if self.target_transform is not None:
target = self.target_transform(target, w, h)
# transform, 数据增强
if self.transform is not None:
target = np.array(target)
# transform
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
# 把图片转化为RGB
img = img[:, :,(2, 1, 0)]
# 把 bbox和label合并为 shape(N, 5)
target = np.hstack(boxes, np.expand_dims(labels, axis=1))
else:
target = np.array(target)
return torch.from_numpy(img).permute(2, 0, 1), target, h, w
def __len__(self):
return len(self.ids)
调试代码:
Data = VOCDetection(VOC_ROOT)
data_loader = data.DataLoader(Data, batch_size=1,
num_workers=0,
shuffle=True,
pin_memory=True)
print('the data length is:', len(data_loader))
# 类别 to index
class_to_ind = dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))
# index to class,转化为类别名称
ind_to_class = ind_to_class ={v:k for k, v in class_to_ind.items()}
# 加载数据
for datas in data_loader:
img, target,h, w = datas
img = img.squeeze(0).permute(1,2,0).numpy().astype(np.uint8)
target = target[0].float()
# 把bbox的坐标还原为原图的数值
target[:,0] *= w.float()
target[:,2] *= w.float()
target[:,1] *= h.float()
target[:,3] *= h.float()
# 取整
target = np.int0(target.numpy())
# 画出图中类别名称
for i in range(target.shape[0]):
# 画矩形框
img =cv2.rectangle(img, (target[i,0],target[i,1]),(target[i, 2], target[i, 3]), (0,0,255), 2)
# 标明类别名称
img =cv2.putText(img, ind_to_class[target[i,4]],(target[i,0], target[i,1]-25),
cv2.FONT_HERSHEY_SIMPLEX, .5, (255, 255, 0), 1)
# 显示
cv2.imshow('imgs', img)
cv2.waitKey(0);
cv2.destroyAllWindows()
break
输出
the data length is: 16551

image
数据增强
1. 数据类型转换
在针对图像进行变化的过程中,需要把图片的 uint8 格式转化为 np.float32,方便计算。
class ConvertFromInts(object):
"""
把图片的uint8转化为float型
"""
def __call__(self, image, boxes=None, labels=None):
return image.astype(np.float32), boxes, labels
2. Transform Compose
我们有很多图片增强的方式,比如对比度,亮度,色度等等,因此会有很多的transform, Compose()函数的作用是把这些transform合并在一起。
class Compose(object):
"""
把不同的数据增强方法组合在一起
Args:
transforms: (list[Transform]):transforms的列表
Example:
>>> augmentations.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),])
"""
def __init__(self, transform):
self.transform = transform
def __call__(self, img, boxes=None, labels=None):
for t in self.transform:
img, boxes, labels = t(img, boxes, labels)
return img, boxes, labels
3. IOU计算
在进行裁剪图片的时候,我们需要考虑裁剪框和图片bbox的iou,这样确保裁剪出的都是有效区域。
def iou_numpy(box_a, box_b):
'''
计算一个框和一些框之间的iou值;
Args:
box_a: 多个bounding boxes,shape[N,4]
box_b: 裁剪矩形,单个bounding box, shape[4]
Reture:
iou: shape[N]
'''
lt = np.maximum(box_a[:, :2], box_b[:2])
rb = np.minimum(box_a[:, 2:], box_b[2:])
wh = np.clip((rb - lt), a_min=0, a_max=np.inf)
inter = wh[:, 0]*wh[:, 1]
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1]))
area_b = ((box_b[2] - box_b[0]) *
(box_b[3] - box_b[1]))
iou = area_a + area_b - inter
return iou
4. bbox坐标变化
在图片增强的过程中,有时候需要原图的绝对坐标,确保bbox的变化,有时候需要归一化后的坐标,例如在resize时候。
- 归一化 --> 原图 size
class ToAbsoluteCoords(object):
"""
把归一化后的box变回原图
"""
def __call__(self, image, boxes=None, labels=None):
h, w, c = image.shape
boxes[:, 0] *= w
boxes[:, 2] *= w
boxes[:, 1] *= h
boxes[:, 3] *= h
return image, boxes, labels
- 原图 size --> 归一化
class ToPercentCoords(object):
"""
把原图的box进行归一化
"""
def __call__(self, image, boxes=None, labels=None):
h, w, c = image.shape
boxes[:, 0] = boxes[:, 0] / w
boxes[:, 2] = boxes[:, 2] / w
boxes[:, 1] = boxes[:, 1] / h
boxes[:, 3] = boxes[:, 3] / h
return image, boxes, labels
5. 图片 Resize
输入的图片大小各异,在输入网络前,需要进行统一的resize。
class Resize(object):
"""
图片 Resize
"""
def __init__(self, size=300):
self.size = size
def __call__(self, image, boxes=None, labels=None):
image = cv2.resize(image, (self.size, self.size))
return image, boxes, labels

Resize
6. 图片色彩转换
在进行亮度,饱和度等变化时,需要把色彩空间转换为HSV。
class ConvertColor(object):
"""
BGR 和 HSV 之间的转换
"""
def __init__(self, current='BGR', transform='HSV'):
self.current = current
self.transform = transform
def __call__(self, image, boxes=None, labels=None):
# BGR TO HSV
if self.current == 'BGR' and self.transform =='HSV':
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# HSV TO BGR
elif self.current == 'HSV' and self.transform == 'BGR':
image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
else:
raise NotImplementedError
return image, boxes, labels
7. 色调Hue变化
- Hue变化需要在 HSV 空间下,改变H的数值;
- 图像IPL_DEPTH_32F类型时,H取值范围是0-360
class RandomHue(object):
"""
随机变换色度(在np.float32 type 和 HSV 空间下, H的范围(0, 360));
需要输入图片格式为HSV;
"""
def __init__(self, delta=18.0):
assert delta >= 0.0 and delta <= 360.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
print('hue')
# 改变 h的值
image[:, :, 0] += random.uniform(-self.delta, self.delta)
# 已知 h 的范围是在 (0, 360)之间
image[:, :, 0][image[:, :, 0] > 360.0] -= 360.0
image[:, :, 0][image[:, :, 0] < 0.0] += 360.0
return image, boxes, labels

RandomHue
8. 饱和度变化
- 饱和度变化需要在 HSV 空间下,改变S的数值;
- 图像IPL_DEPTH_32F类型时,S取值范围是0-1
class RandomSaturation(object):
"""
随机饱和度变化,需要输入图片格式为HSV
"""
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
print('saturation')
image[:, :, 1] *= random.uniform(self.lower, self.upper)
# 已知 S 的范围是在 (0, 1)之间
image[:, :, 1] = np.clip(image[:, :, 1], 0., 1.0)
return image, boxes, labels

RandomSaturation
9. 亮度变化
- 图片的亮度变化,只需要在RGB空间下,加上一个delta值;
- 要设置变化后数值在0~255之间
class RandomBrightness(object):
"""
图片亮度的随机变化;
变化公式:img(x) = img(x)+b
"""
def __init__(self, delta=32):
assert delta >= 0.0
assert delta <= 255.0
self.delta = delta
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
delta = random.uniform(-self.delta, self.delta)
image += delta
# 限制image的范围[0, 255.0]
image = np.clip(image, 0, 255)
return image, boxes, labels

RandomBrightness
10. 对比度变化
- 图片的对比度变化,只需要在RGB空间下,乘上一个alpha值;
- 要设置变化后数值在0~255之间
class RandomContrast(object):
"""
图片对比度的随机变化;
变化公式:img(x) = a*img(x)
"""
def __init__(self, lower=0.5, upper=1.5):
self.lower = lower
self.upper = upper
assert self.upper >= self.lower, "contrast upper must be >= lower."
assert self.lower >= 0, "contrast lower must be non-negative."
# expects float image
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
alpha = random.uniform(self.lower, self.upper)
image *= alpha
# 限制image的范围[0, 255.0]
image = np.clip(image, 0, 255)
return image, boxes, labels

RandomContrast
11. 颜色通道变化
针对图片的RGB空间,随机调换各通道的位置,实现不同灯光效果
class SwapChannels(object):
"""
图片通道变换
Args:
swaps: (int triple),变化的通道元组
eg: (2, 1, 0)
"""
def __init__(self, swaps):
self.swaps = swaps
def __call__(self, image):
image = image[:, :, self.swaps]
return image
class RandomLightingNoise(object):
"""
图片更换通道,形成的颜色变化
"""
def __init__(self):
self.perms = ((0, 1, 2), (0, 2, 1),
(1, 0, 2), (1, 2, 0),
(2, 0, 1), (2, 1, 0))
def __call__(self, image, boxes=None, labels=None):
if random.randint(2):
print('RandomLightingNoise')
swap = self.perms[random.randint(len(self.perms))]
shuffle = SwapChannels(swap)
image = shuffle(image)
return image, boxes, labels

RandomLightingNoise
12. 图片镜像
图片镜像是指图片的左右翻转,实现图片增广。
class RandomMirror(object):
"""
随机镜像图片
"""
def __call__(self, image, boxes, labels):
w = image.shape[1]
if random.randint(2):
# 图片翻转
image = image[:, ::-1]
# boxes的坐标也需要相应改变
boxes = boxes.copy()
boxes[:, 0::2] = w - boxes[:, 2::-2]
return image, boxes, labels

原图

镜像图
13. 图片随机裁剪
图片的随机裁剪在图片增强有着很大的应用,在考虑图片裁剪的过程中,裁剪的过程为:
- 随机选取裁剪框的大小;
- 根据大小确定裁剪框的坐标;
- 分析裁剪框和图片内部bounding box的iou;
- 筛选掉iou不符合要求的裁剪框
- 裁剪图片,重新更新bounding box 的位置坐标
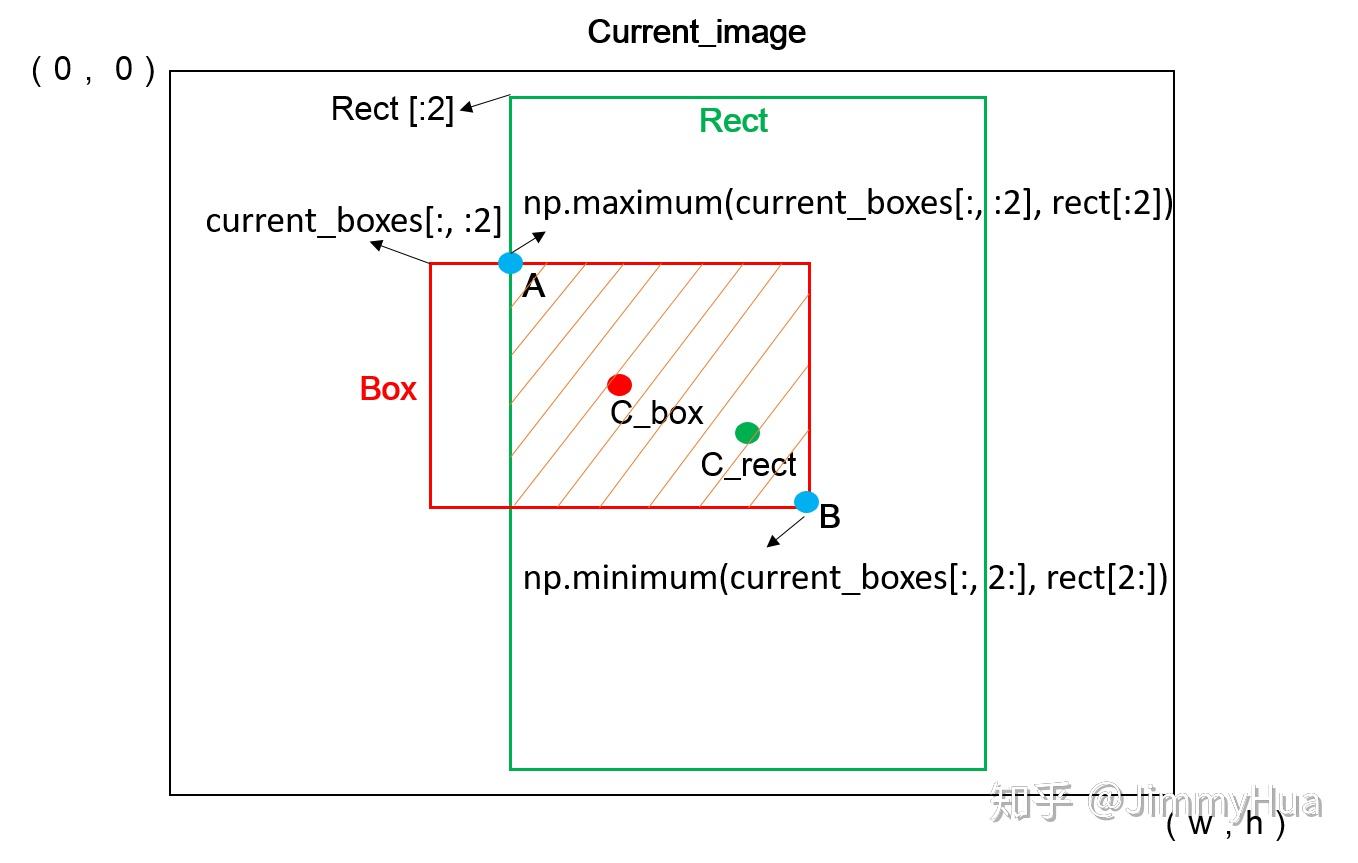
裁剪示意图
class RandomSampleCrop(object):
"""
随机切割图片
"""
def __init__(self):
self.sample_options = (
# 原图
None,
# min_iou 和 max_iou
(0.1, None),
(0.3, None),
(0.7, None),
(0.9, None),
# randomly sample a patch
(None, None),
)
def __call__(self, image, boxes=None, labels=None):
print('crop now...')
h, w, _ = image.shape
while True:
mode = random.choice(self.sample_options)
if mode is None:
return image, boxes, labels
min_iou, max_iou = mode
if min_iou is None:
min_iou = float('-inf')
if max_iou is None:
max_iou = float('inf')
# 迭代 n 次
for i in range(50):
current_image = image
ww = random.uniform(0.3 * w, w)
hh = random.uniform(0.3 * h, h)
# 判断长宽比在一定范围
if hh / ww < 0.5 or hh / ww > 2:
continue
left = random.uniform(w - ww)
top = random.uniform(h - hh)
# 切割的矩形大小
rect = np.array([int(left), int(top), int(left+ww), int(top+hh)])
# 计算切割的矩形和 gt 框的iou大小
overlap = iou_numpy(boxes, rect)
# 筛选掉不满足 overlap条件的
if overlap.min() < min_iou and max_iou < overlap.max():
continue
current_image = current_image[rect[1]:rect[3], rect[0]:rect[2]]
centers = (boxes[:, :2] + boxes[:, 2:]) / 2.0
# 切割矩形 在所有的 gt box的中心点的左上方
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
# 切割矩形 在所有的 gt box的中心点的右下方
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
mask = m1 * m2
if not mask.any():
continue
current_boxes = boxes[mask, :].copy()
current_labels = labels[mask]
# 获取box和切割矩形的交点(左上角) A点
current_boxes[:, :2] = np.maximum(current_boxes[:, :2],
rect[:2])
# 调节坐标系,让boxes的左上角坐标变为切割后的坐标
current_boxes[:, :2] -= rect[:2]
current_boxes[:, 2:] = np.minimum(current_boxes[:, 2:],
rect[2:])
# 调节坐标系,让boxes的左上角坐标变为切割后的坐标
current_boxes[:, 2:] -= rect[:2]
return current_image, current_boxes, current_labels

RandomSampleCrop
14. 图片扩充
设置一个大于原图Size的随机size,填充指定的像素值,然后把原图随机放入这个图片中,实现原图的扩充。
class Expand(object):
"""
随机扩充图片,expand
"""
def __init__(self, mean):
self.mean = mean
def __call__(self ,image, boxes, labels):
if random.randint(2):
return image, boxes, labels
h, w, c = image.shape
ratio = random.uniform(1, 4)
left = random.uniform(0, w*ratio - w)
top = random.uniform(0, h*ratio - h)
expand_image = np.zeros((int(h*ratio), int(w*ratio), c),
dtype=image.dtype)
# 填充 mean值
expand_image[:,:,:] = self.mean
# 放入原图
expand_image[int(top):int(top+h), int(left):int(left+w)] = image
image = expand_image
# 同样相应的变化boxes的坐标
boxes = boxes.copy()
boxes[:, :2] += (int(left), int(top))
boxes[:, 2:] += (int(left), int(top))
return image, boxes, labels

Expand
汇总
最后,根据上面所有的方法,合并为数据增强的一个python类。
class PhotometricDistort(object):
"""
图片亮度,对比度和色调变化的方式合并为一个类
"""
def __init__(self):
self.pd = [
RandomContrast(),
ConvertColor(transform='HSV'),
RandomSaturation(),
RandomHue(),
ConvertColor(current='HSV', transform='BGR'),
RandomContrast()
]
self.rand_brightness = RandomBrightness()
self.rand_light_noise = RandomLightingNoise()
def __call__(self, image, boxes, labels):
im = image.copy()
im, boxes, labels = self.rand_brightness(im, boxes, labels)
if random.randint(2):
distort = Compose(self.pd[:-1])
else:
distort = Compose(self.pd[1:])
im, boxes, labels = distort(im, boxes, labels)
return self.rand_light_noise(im, boxes, labels)
# 结合所有的图片增广方法形成的类
class SSDAugmentation(object):
def __init__(self, size=300, mean=(104, 117, 123)):
self.mean = mean
self.size = size
self.augment = Compose([
ConvertFromInts(), # 转化为float32
ToAbsoluteCoords(), # 转化为原图坐标
PhotometricDistort(), # 图片增强方式
Expand(self.mean), # 扩充
RandomSampleCrop(), # 裁剪
RandomMirror(), # 镜像
ToPercentCoords(), # 转化为归一化后的坐标
Resize(self.size), # Resize
ToAbsoluteCoords(), # 转为原图坐标
#SubtractMeans(self.mean), # 减去均值
])
def __call__(self, image, boxes, labels):
return self.augment(image, boxes, labels)
输出样图:

代码复现
前言
SSD Pytorch版本的代码来至于 Amdegroot 的 Pytorch 版本。
目录
-
网络模型
-
- VGG Backbone
- Extra Layers
- Multi-box Layers
- SSD 模型类
-
先验框生成
-
损失函数
-
L2 正则化
-
训练处理
-
- 位置坐标转换
- IOU计算
- 位置编码和解码
- 先验框匹配
- NMS抑制
-
Detection函数
网络模型
整个网络是由三大部分组成:
- VGG Backbone
- Extra Layers
- Multi-box Layers
VGG Backbone
根据SSD的论文描述,作者采用了vgg16的部分网络作为基础网络,在5层网络后,丢弃全连接,改为两个卷积网络,分别为:1024x3x3、1024x1x1。
值得注意:
- conv4-1前面一层的maxpooling的ceil_mode=True,使得输出为 38x38;
- Conv4-3网络是需要输出多尺度的网络层;
- Conv5-3后面的一层maxpooling参数为(kernel_size=3, stride=1, padding=1),不进行下采样。
网络层次图:
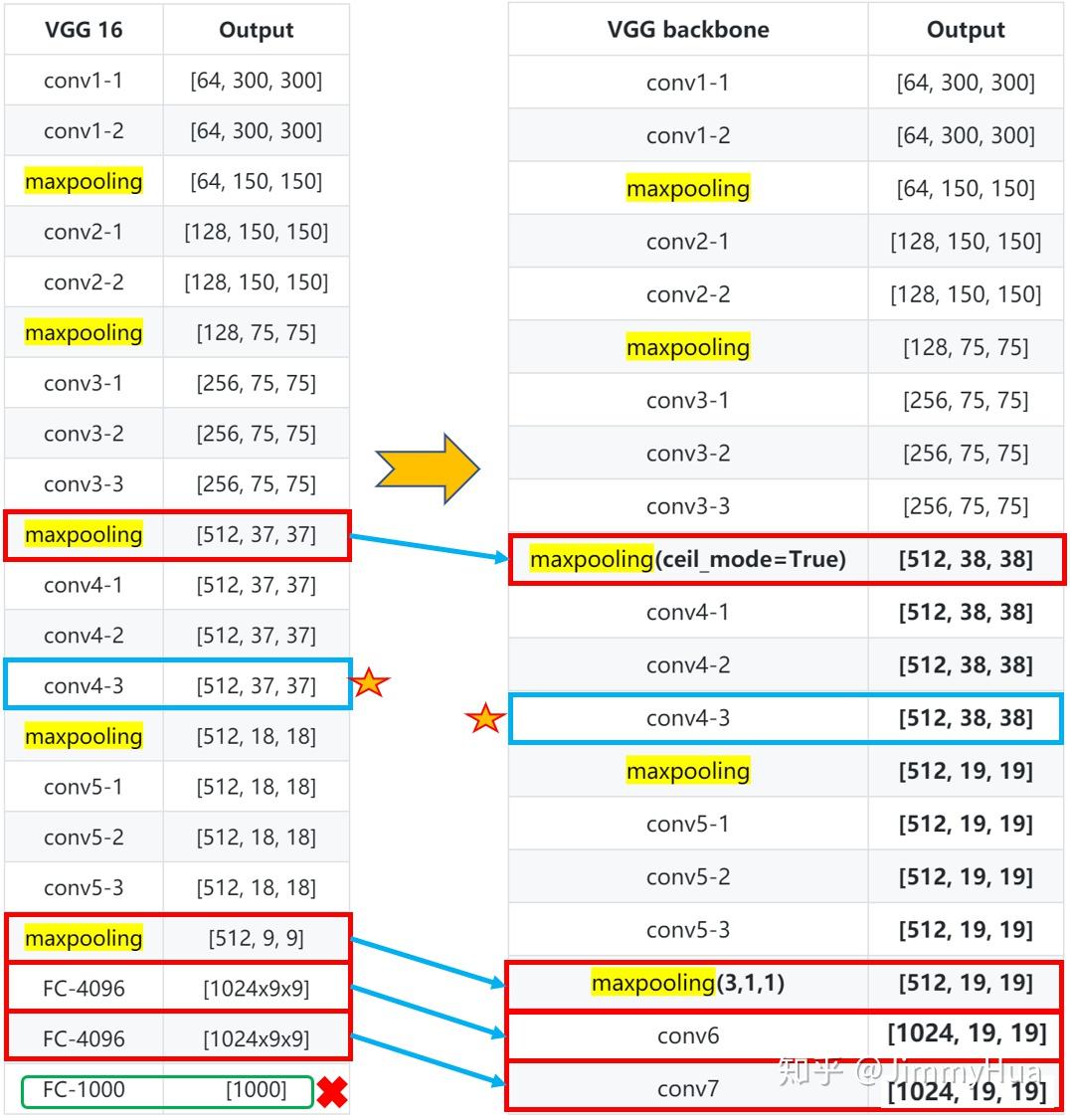
VGG Backbone
网络代码:
def vgg(cfg, i, batch_norm=False):
'''
该代码参考vgg官网的代码
'''
layers = []
in_channels = i
for v in cfg:
# 正常的 max_pooling
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# ceil_mode = True, 上采样使得 channel 75-->38
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
# update in_channels
in_channels = v
# max_pooling (3,3,1,1)
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
# 新添加的网络层 1024x3x3
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
# 新添加的网络层 1024x1x1
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
# 结合到整体网络中
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
# 代码测试
if __name__ == "__main__":
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
vgg = nn.Sequential(*vgg(base['300'], 3))
x = torch.randn(1,3,300,300)
print(vgg(x).shape) #(1, 1024, 19, 19)
不同的写法
def vggs():
'''
调用torchvision.models里面的vgg,
修改对应的网络层,同样可以得到目标的backbone。
'''
vgg16 = models.vgg16()
vggs = vgg16.features
vggs[16] = nn.MaxPool2d(2, 2, 0, 1, ceil_mode=True)
vggs[-1] = nn.MaxPool2d(3, 1, 1, 1, ceil_mode=False)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
'''
方法一:
'''
#vggs= nn.Sequential(feature, conv6, nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True))
'''
方法二:
'''
vggs.add_module('31',conv6)
vggs.add_module('32',nn.ReLU(inplace=True))
vggs.add_module('33',conv7)
vggs.add_module('34',nn.ReLU(inplace=True))
#print(vggs)
x = torch.randn(1,3,300,300)
print(vggs(x).shape)
return vgg
输出网络结构:
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace)
)
Extra Layers
作者为了后续的多尺度提取,在VGG Backbone后面添加了卷积网络。
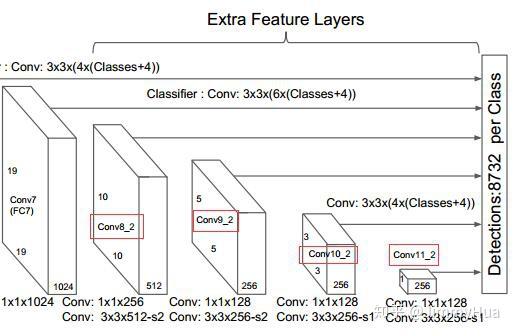
Extra layer
网络层次:

网络结构
PS: 红框的网络需要进行多尺度分析,输入到multi-box网络。
网络代码:
def add_extras(cfg, i, batch_norm=False):
'''
为后续多尺度提取,增加网络层
'''
layers = []
# 初始输入通道为 1024
in_channels = i
# flag 用来选择 kernel_size= 1 or 3
flag = False
for k,v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k+1],
kernel_size=(1,3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag # 反转flag
in_channels = v # 更新 in_channels
return layers
# 代码测试
if __name__ == "__main__":
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
layers = add_extras(extras['300'], 1024)
print(nn.Sequential(*layers))
输出:
Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
)
Multi-box Layers
SSD一共有6层多尺度提取的网络,每层分别对 loc 和 conf 进行卷积,得到相应的输出。
网络层次:
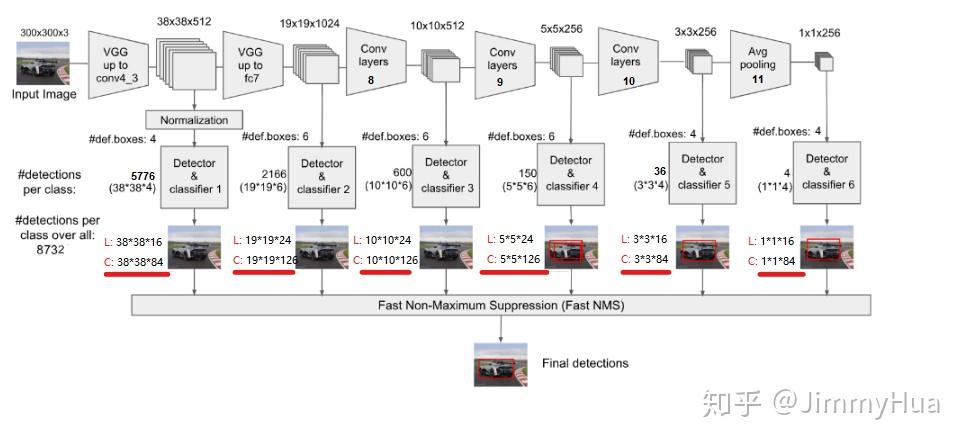
Multi-box Layers
网络代码:
def multibox(vgg, extra_layers, cfg, num_classes):
'''
Args:
vgg: 修改fc后的vgg网络
extra_layers: 加在vgg后面的4层网络
cfg: 网络参数,eg:[4, 6, 6, 6, 4, 4]
num_classes: 类别,VOC为 20+背景=21
Return:
vgg, extra_layers
loc_layers: 多尺度分支的回归网络
conf_layers: 多尺度分支的分类网络
'''
loc_layers = []
conf_layers = []
vgg_layer = [21, -2]
# 第一部分,vgg 网络的 Conv2d-4_3(21层), Conv2d-7_1(-2层)
for k, v in enumerate(vgg_layer):
# 回归 box*4(坐标)
loc_layers += [nn.Conv2d(vgg[v].out_channels, cfg[k]*4, kernel_size=3, padding=1)]
# 置信度 box*(num_classes)
conf_layers += [nn.Conv2d(vgg[v].out_channels, cfg[k]*num_classes, kernel_size=3, padding=1)]
# 第二部分,cfg从第三个开始作为box的个数,而且用于多尺度提取的网络分别为1,3,5,7层
for k, v in enumerate(extra_layers[1::2],2):
# 回归 box*4(坐标)
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]*4, kernel_size=3, padding=1)]
# 置信度 box*(num_classes)
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]*(num_classes), kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
if __name__ == "__main__":
vgg, extra_layers, (l, c) = multibox(vgg(base['300'], 3),
add_extras(extras['300'], 1024),
[4, 6, 6, 6, 4, 4], 21)
print(nn.Sequential(*l))
print('---------------------------')
print(nn.Sequential(*c))
输出:
'''
loc layers:
'''
Sequential(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
---------------------------
'''
conf layers:
'''
Sequential(
(0): Conv2d(512, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(1024, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(256, 126, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(256, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
SSD 模型类
根据上述的三个网络层结合,结合后面提到的 prior_box和detection方法可以,完整的写出SSD的类。
class SSD(nn.Module):
'''
Args:
phase: string, 可选"train" 和 "test"
size: 输入网络的图片大小
base: VGG16的网络层(修改fc后的)
extras: 用于多尺度增加的网络
head: 包含了各个分支的loc和conf
num_classes: 类别数
return:
output: List, 返回loc, conf 和 候选框
'''
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.size = size
self.num_classes = num_classes
# 配置config
self.cfg = (coco, voc)[num_classes == 21]
# 初始化先验框
self.priorbox = PriorBox(self.cfg)
self.priors = self.priorbox.forward()
# basebone 网络
self.vgg = nn.ModuleList(base)
# conv4_3后面的网络,L2 正则化
self.L2Norm = L2Norm(512, 20)
self.extras = nn.ModuleList(extras)
# 回归和分类网络
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
'''
# 预测使用
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 200, 0.01, 0.045)
'''
pass
def forward(self, x):
sources, loc ,conf = [], [], []
# vgg网络到conv4_3
for i in range(23):
x = self.vgg[i](x)
# l2 正则化
s = self.L2Norm(x)
sources.append(s)
# conv4_3 到 fc
for i in range(23, len(self.vgg)):
x = self.vgg[i](x)
sources.append(x)
# extras 网络
for k,v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
# 把需要进行多尺度的网络输出存入 sources
if k%2 == 1:
sources.append(x)
# 多尺度回归和分类网络
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == 'test':
'''
# 预测使用
output = self.detect(
# loc 预测
loc.view(loc.size(0), -1, 4),
# conf 预测
self.softmax(conf.view(conf.size(0), -1, self.num_classes)),
# default box
self.priors.type(type(x.data)),
)
'''
pass
else:
output = (
# loc的输出,size:(batch, 8732, 4)
loc.view(loc.size(0), -1 ,4),
# conf的输出,size:(batch, 8732, 21)
conf.view(conf.size(0), -1, self.num_classes),
# 生成所有的候选框 size([8732, 4])
self.priors,
)
# print(type(x.data))
# print((self.priors.type(type(x.data))).shape)
return output
# 加载模型参数
def load_weights(self, base_file):
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file))
print('Finished!')
使用build_ssd()封装函数,增加可读性:
def build_ssd(phase, size=300, num_classes=21):
# 判断phase是否为满足的条件
if phase != "test" and phase !="train":
print("Error: Phase:" + phase +" not recognized!\n")
return
# 判断size是否为满足的条件
if size != 300:
print("Error: currently only size=300 is supported!")
return
# 调用multibox,生成vgg,extras,head
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox['300'], num_classes,
)
return SSD(phase, size, base_, extras_, head_, num_classes)
# 调试函数
if __name__ == '__main__':
ssd = build_ssd('train')
x = torch.randn(1, 3, 300, 300)
y = ssd(x)
print("Loc shape: ", y[0].shape)
print("Conf shape: ", y[1].shape)
print("Priors shape: ", y[2].shape)
输出:
Loc shape: torch.Size([1, 8732, 4])
Conf shape: torch.Size([1, 8732, 21])
Priors shape: torch.Size([8732, 4])
先验框生成
SSD从Conv4_3开始,一共提取了6个特征图,其大小分别为 (38,38),(19,19),(10,10),(5,5),(3,3),(1,1),但是每个特征图上设置的先验框数量不同。
先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
s k = s m i n + s m a x ? s m i n m ? 1 ( k ? 1 ) , k ∈ [ 1 , m ] s_{k}=s_{m i n}+\frac{s_{m a x}-s_{m i n}}{m-1}(k-1), k \in[1, m] sk?=smin?+m?1smax??smin??(k?1),k∈[1,m]
其中:
- M 指特征图个数,但是为5,因为第一层(Conv4_3)是单独设置的;
- s_k 表示先验框大小相对于图片的比例;
- s_{min} 和 s_{max} 表示比例的最小值与最大值,paper里面取 0.2 和 0.9。
1、对于第一个特征图,它的先验框尺度比例设置为 s_{min}/2=0.1 ,则其尺度为 300 \times 0.1=30 ;
2、对于后面的特征图,先验框尺度按照上面公式线性增加,但是为了方便计算,先将尺度比例先扩大100倍,此时增长步长为:
δ = ? ? s m a x × 100 ? ? ? s m i n × 100 ? m ? 1 ? = 17 \delta = \left\lfloor\frac{\left\lfloor s_{m a x} \times 100\right\rfloor-\left\lfloor s_{m i n} \times 100\right\rfloor}{m-1}\right\rfloor= 17 δ=?m?1?smax?×100???smin?×100???=17
3、根据上面的公式,则有:
s k = s m i n × 100 + δ s_k = s_{min} \times 100 + \delta sk?=smin?×100+δ
s k ∈ { 20 , 37 , 54 , 71 , 88 } s_k \in\left\{20, 37, 54, 71, 88\right\} sk?∈{20,37,54,71,88}
4、将上面的值除以100,然后再乘回原图的大小300,再综合第一个特征图的先验框尺寸,则可得各个特征图的先验框尺寸为:
s k ∈ { 30 , 60 , 111 , 162 , 213 , 264 } s_k \in\left\{30, 60, 111, 162, 213, 264\right\} sk?∈{30,60,111,162,213,264}
5、先验框的长宽比一般设置为:
a r ∈ { 1 , 2 , 3 , 1 2 , 1 3 } a_{r} \in\left\{1,2,3, \frac{1}{2}, \frac{1}{3}\right\} ar?∈{1,2,3,21?,31?}
6、根据面积和长宽比可得先验框的宽度和高度:
w k a = s k a r , ? h k a = s k / a r w_{k}^{a}=s_{k} \sqrt{a_{r}}, \space h_{k}^{a}=s_{k} / \sqrt{a_{r}} wka?=sk?ar??,?hka?=sk?/ar??
7、默认情况下,每个特征图会有一个 a_{r}=1 且尺度为 s_{k} 的先验框,除此之外,还会设置一个尺度为 s_{k}^{\prime}=\sqrt{s_{k} s_{k+1}} 且 a_{r}=1 的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框;
8、最后一个特征图需要参考一个虚拟 $s_{m+1}=300 \times (88+17) / 100=315 $来计算 s m s_{m} sm?
9、因此,每个特征图一共有 6 个先验框 $\left{1,2,3, \frac{1}{2}, \frac{1}{3}, 1^{\prime}\right} $,但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为 3, \frac{1}{3} 的先验框;
10、每个单元的先验框的中心点分布在各个单元的中心,即:
( i + 0.5 ∣ f k ∣ , j + 0.5 ∣ f k ∣ ) , i , j ∈ [ 0 , ∣ f k ∣ ) \left(\frac{i+0.5}{\left|f_{k}\right|}, \frac{j+0.5}{\left|f_{k}\right|}\right), i, j \in\left[0,\left|f_{k}\right|\right) (∣fk?∣i+0.5?,∣fk?∣j+0.5?),i,j∈[0,∣fk?∣)
其中 ∣ f k ∣ \left|f_{k}\right| ∣fk?∣ 为特征图的大小。
因此,SSD 先验框共个数:
num_priors = 38x38x4+19x19x6+10x10x6+5x5x6+3x3x4+1x1x4=8732
代码:
class PriorBox(object):
"""
1、计算先验框,根据feature map的每个像素生成box;
2、框的中个数为: 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
3、 cfg: SSD的参数配置,字典类型
"""
def __init__(self, cfg):
super(PriorBox, self).__init__()
self.img_size = cfg['img_size']
self.feature_maps = cfg['feature_maps']
self.min_sizes = cfg['min_sizes']
self.max_sizes = cfg['max_sizes']
self.steps = cfg['steps']
self.aspect_ratios = cfg['aspect_ratios']
self.clip = cfg['clip']
self.version = cfg['name']
self.variance = cfg['variance']
def forward(self):
mean = [] #用来存放 box的参数
# 遍多尺度的 map: [38, 19, 10, 5, 3, 1]
for k, f in enumerate(self.feature_maps):
# 遍历每个像素
for i, j in product(range(f), repeat=2):
# k-th 层的feature map 大小
f_k = self.img_size/self.steps[k]
# 每个框的中心坐标
cx = (i+0.5)/f_k
cy = (j+0.5)/f_k
'''
当 ratio==1的时候,会产生两个 box
'''
# r==1, size = s_k, 正方形
s_k = self.min_sizes[k]/self.img_size
mean += [cx, cy, s_k, s_k]
# r==1, size = sqrt(s_k * s_(k+1)), 正方形
s_k_plus = self.max_sizes[k]/self.img_size
s_k_prime = sqrt(s_k * s_k_plus)
mean += [cx, cy, s_k_prime, s_k_prime]
'''
当 ratio != 1 的时候,产生的box为矩形
'''
for r in self.aspect_ratios[k]:
mean += [cx, cy, s_k * sqrt(r), s_k / sqrt(r)]
mean += [cx, cy, s_k / sqrt(r), s_k * sqrt(r)]
# 转化为 torch
boxes = torch.tensor(mean).view(-1, 4)
# 归一化,把输出设置在 [0,1]
if self.clip:
boxes.clamp_(max=1, min=0)
return boxes
# 调试代码
if __name__ == "__main__":
# SSD300 CONFIGS
voc = {
'num_classes': 21,
'lr_steps': (80000, 100000, 120000),
'max_iter': 120000,
'feature_maps': [38, 19, 10, 5, 3, 1],
'img_size': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'VOC',
}
box = PriorBox(voc)
print('Priors box shape:', box.forward().shape)
print('Priors box:\n',box.forward())
输出:
Priors box shape: torch.Size([8732, 4])
Priors box:
tensor([[0.0133, 0.0133, 0.1000, 0.1000],
[0.0133, 0.0133, 0.1414, 0.1414],
[0.0133, 0.0133, 0.1414, 0.0707],
...,
[0.5000, 0.5000, 0.9612, 0.9612],
[0.5000, 0.5000, 1.0000, 0.6223],
[0.5000, 0.5000, 0.6223, 1.0000]])
损失函数
SSD的损失函数包括两部分的加权:
- 位置损失函数 L l o c L_{loc} Lloc?
- 置信度损失函数 L c o n f L_{conf} Lconf?
整个损失函数为:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x, c, l, g)=\frac{1}{N}\left(L_{c o n f}(x, c)+\alpha L_{l o c}(x, l, g)\right) L(x,c,l,g)=N1?(Lconf?(x,c)+αLloc?(x,l,g))
其中:
- N 是先验框的正样本数量;
- c 为类别置信度预测值;
- l 为先验框的所对应边界框的位置预测值;
- g 为ground truth的位置参数。
1. 对于位置损失函数:
针对所有的正样本,采用 Smooth L1 Loss, 位置信息都是 encode 之后的位置信息。
smooth ? L 1 ( x ) = { 0.5 x 2 ?if? ∣ x ∣ < 1 ∣ x ∣ ? 0.5 ?otherwise? \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll}{0.5 x^{2}} & {\text { if }|x|<1} \\ {|x|-0.5} & {\text { otherwise }}\end{array}\right. smoothL1??(x)={0.5x2∣x∣?0.5??if?∣x∣<1?otherwise??
2. 对于置信度损失函数:
首先需要使用 hard negative mining 将正负样本按照 1:3 的比例把负样本抽样出来,抽样的方法是:
思想: 针对所有batch的confidence,按照置信度误差进行降序排列,取出前top_k个负样本。
编程:
- Reshape所有batch中的conf
batch_conf = conf_data.view(-1, self.num_classes)
- 置信度误差越大,实际上就是预测背景的置信度越小。
- 把所有conf进行logsoftmax处理(均为负值),预测的置信度越小,则logsoftmax越小,取绝对值,则
|logsoftmax|越大,降序排列-logsoftmax,取前top_k的负样本。
详细分析:
这里借用logsoftmax的思想:
log ? ( e x j ∑ i = 1 n e x i ) = log ? ( e x j ) ? log ? ( ∑ i = 1 n e x i ) = x j ? log ? ( ∑ i = 1 n e x i ) \begin{aligned} \log \left(\frac{e^{x_{j}}}{\sum_{i=1}^{n} e^{x_{i}}}\right) &=\log \left(e^{x_{j}}\right)-\log \left(\sum_{i=1}^{n} e^{x_{i}}\right) \\ &=x_{j}-\log \left(\sum_{i=1}^{n} e^{x_{i}}\right) \end{aligned} log(∑i=1n?exi?exj??)?=log(exj?)?log(i=1∑n?exi?)=xj??log(i=1∑n?exi?)?
为了防止数值溢出,可以把问题转化为:
log ? Sum ? Exp ? ( x 1 … x n ) = log ? ( ∑ i = 1 n e x i ) = log ? ( ∑ i = 1 n e x i ? c e c ) = log ? ( e c ∑ i = 1 n e x i ? c ) = log ? ( ∑ i = 1 n e x i ? c ) + log ? ( e c ) = log ? ( ∑ i = 1 n e x i ? c ) + c \begin{aligned} \log \operatorname{Sum} \operatorname{Exp}\left(x_{1} \ldots x_{n}\right) &=\log \left(\sum_{i=1}^{n} e^{x_{i}}\right) \\ &=\log \left(\sum_{i=1}^{n} e^{x_{i}-c} e^{c}\right) \\ &=\log \left(e^{c} \sum_{i=1}^{n} e^{x_{i}-c}\right) \\ &=\log \left(\sum_{i=1}^{n} e^{x_{i}-c}\right)+\log \left(e^{c}\right) \\ &=\log \left(\sum_{i=1}^{n} e^{x_{i}-c}\right)+c \end{aligned} logSumExp(x1?…xn?)?=log(i=1∑n?exi?)=log(i=1∑n?exi??cec)=log(eci=1∑n?exi??c)=log(i=1∑n?exi??c)+log(ec)=log(i=1∑n?exi??c)+c?
上述变换的关键在于,我们引入了一个不牵涉log或exp函数的常数项c。
现在我们只需为 c 选择一个在所有情形下有效的良好的值,结果发现,$max(x_1…x_n)$很不错。
由此我们可以构建对数softmax的新表达式:
log ? ( Softmax ? ( x j , x 1 … x n ) ) = x j ? log ? Sum ? Exp ? ( x 1 … x n ) = x j ? log ? ( ∑ i = 1 n e x i ? c ) ? c \begin{aligned} \log \left(\operatorname{Softmax}\left(x_{j}, x_{1} \ldots x_{n}\right)\right) &=x_{j}-\log \operatorname{Sum} \operatorname{Exp}\left(x_{1} \ldots x_{n}\right) \\ &=x_{j}-\log \left(\sum_{i=1}^{n} e^{x_{i}-c}\right)-c \end{aligned} log(Softmax(xj?,x1?…xn?))?=xj??logSumExp(x1?…xn?)=xj??log(i=1∑n?exi??c)?c?
因此,可以把排序的函数定义为:
c o n f l o g P = Softmax ? ( x j , x 1 … x n ) ? x j conflogP = \operatorname{Softmax}\left(x_{j}, x_{1} \ldots x_{n}\right) - x_j conflogP=Softmax(xj?,x1?…xn?)?xj?
python代码:
logSumExp的表示为:
def log_sum_exp(x):
x_max = x.detach().max()
return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True))+x_max
conf_logP 表示为:
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
排除正样本
conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
两次sort,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
可以参考如下表:
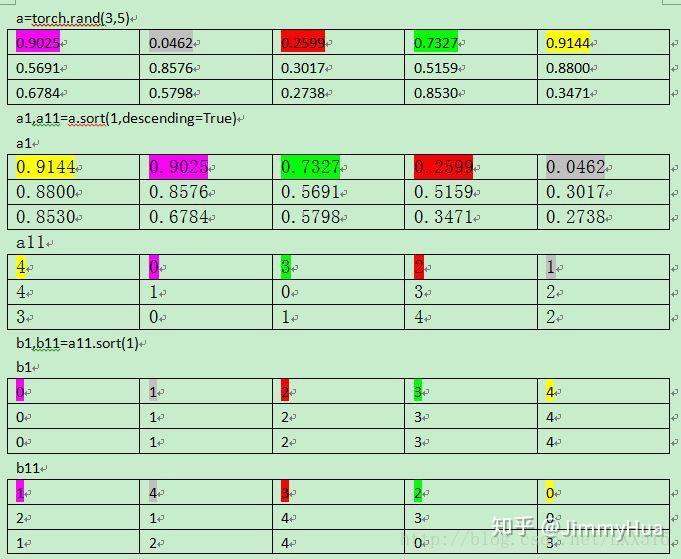
两次sort
后续,就可以筛选出所需的负样本,配合正样本求出conf的cross entropy。
完整loss代码
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 13 10:52:36 2019
@author: Jimmy Hua
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from vgg_backbone import voc
from box_utils import match, log_sum_exp
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, neg_pos, use_gpu=False):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.negpos_ratio = neg_pos
self.variance = voc['variance']
def forward(self, pred, targets):
'''
Args:
pred: A tuple, 包含 loc(编码钱的位置信息), conf(类别), priors(先验框);
loc_data: shape[b,M,4];
conf_data: shape[b,M,num_classes];
priors: shape[M,4];
targets: 真实的boxes和labels,shape[b,num_objs,5];
'''
loc_data, conf_data, priors = pred
batch = loc_data.size(0) #batch
num_priors = priors[:loc_data.size(1), :].size(0) # 先验框个数
# 获取匹配每个prior box的 ground truth
# 创建 loc_t 和 conf_t 保存真实box的位置和类别
loc_t = torch.Tensor(batch, num_priors, 4)
conf_t = torch.LongTensor(batch, num_priors)
for idx in range(batch):
truths = targets[idx][:, :-1].detach() # ground truth box信息
labels = targets[idx][:, -1].detach() # ground truth conf信息
defaults = priors.detach() # priors的 box 信息
# 匹配 ground truth
match(self.threshold, truths, defaults,
self.variance, labels, loc_t, conf_t, idx)
# use gpu
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
pos = conf_t > 0 # 匹配中所有的正样本mask,shape[b,M]
# Localization Loss,使用 Smooth L1
# shape[b,M]-->shape[b,M,4]
pos_idx = pos.unsqueeze(2).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1,4) # 预测的正样本box信息
loc_t = loc_t[pos_idx].view(-1,4) # 真实的正样本box信息
loss_l = F.smooth_l1_loss(loc_p, loc_t) # Smooth L1 损失
'''
Target;
下面进行hard negative mining
过程:
1、 针对所有batch的conf,按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列;
2、 负样本的label全是背景,那么利用log softmax 计算出logP,
logP越大,则背景概率越低,误差越大;
3、 选取误差交大的top_k作为负样本,保证正负样本比例接近1:3;
'''
# shape[b*M,num_classes]
batch_conf = conf_data.view(-1, self.num_classes)
# 使用logsoftmax,计算置信度,shape[b*M, 1]
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# hard Negative Mining
conf_logP = conf_logP.view(batch, -1) # shape[b, M]
conf_logP[pos] = 0 # 把正样本排除,剩下的就全是负样本,可以进行抽样
# 两次sort排序,能够得到每个元素在降序排列中的位置idx_rank
_, index = conf_logP.sort(1, descending=True)
_, idx_rank = index.sort(1)
# 抽取负样本
# 每个batch中正样本的数目,shape[b,1]
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max= pos.size(1)-1)
neg = idx_rank < num_neg # 抽取前top_k个负样本,shape[b, M]
# shape[b,M] --> shape[b,M,num_classes]
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 提取出所有筛选好的正负样本(预测的和真实的)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
conf_target = conf_t[(pos+neg).gt(0)]
# 计算conf交叉熵
loss_c = F.cross_entropy(conf_p, conf_target)
# 正样本个数
N = num_pos.detach().sum().float()
loss_l /= N
loss_c /= N
return loss_l, loss_c
# 调试代码使用
if __name__ == "__main__":
loss = MultiBoxLoss(21, 0.5, 3)
p = (torch.randn(1,100,4), torch.randn(1,100,21), torch.randn(100,4))
t = torch.randn(1, 10, 4)
tt = torch.randint(20, (1,10,1))
t = torch.cat((t,tt.float()), dim=2)
l, c = loss(p, t)
# 随机randn,会导致g_wh出现负数,此时结果会变成 nan
print('loc loss:', l)
print('conf loss:', c)
输出:
loc loss: tensor(11.9424)
conf loss: tensor(2.0487)
L2 正则化
VGG网络的conv4_3特征图大小38x38,网络层靠前,norm较大,需要加一个L2 Normalization,以保证和后面的检测层差异不是很大。
L2 norm 的公式如下:
x ^ = x ∥ x ∥ 2 ??? ? (1) \hat{\mathbf{x}}=\frac{\mathbf{x}}{\|\mathbf{x}\|_{2}} \space\space\space\cdots\text{(1)} x^=∥x∥2?x?????(1)
其中:
x = ( x 1 ? x d ) ∥ x ∥ 2 = ( ∑ i = 1 d ∣ x i ∣ 2 ) 1 / 2 ??? ? (2) \mathbf{x}=\left(x_{1} \cdots x_{d}\right) \|\mathbf{x}\|_{2}=\left(\sum_{i=1}^{d}\left|x_{i}\right|^{2}\right)^{1 / 2}\space\space\space\cdots\text{(2)} x=(x1??xd?)∥x∥2?=(i=1∑d?∣xi?∣2)1/2????(2)
注意,如果我们不按比例缩小学习范围,简单地对一个层的每个输入进行标准化就会改变该层的规模,并且会减慢速度学习,因此需要引入一个scaling paraneter \gamma_{i} ,对于每一个通道,l2 norm 变为:
y i = γ i x ^ i ??? ? (3) y_{i}=\gamma_{i} \hat{x}_{i}\space\space\space\cdots\text{(3)} yi?=γi?x^i?????(3)
通常,scale 值设为10或20,效果比较好。
代码:
class L2Norm(nn.Module):
'''
conv4_3特征图大小38x38,网络层靠前,norm较大,需要加一个L2 Normalization,
以保证和后面的检测层差异不是很大,具体可以参考: ParseNet。
'''
def __init__(self, n_channels, scale):
super(L2Norm, self).__init__()
self.n_channels = n_channels
self.gamma = scale or None
self.eps = 1e-10
# 将一个不可训练的类型Tensor转换成可以训练的类型 parameter
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
self.reset_parameters()
# 初始化参数
def reset_parameters(self):
nn.init.constant_(self.weight, self.gamma)
def forward(self, x):
# 计算 x 的2范数,参考公式 (2)
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() # shape[b,1,38,38]
# 参考公式 (1)
x = x / norm # shape[b,512,38,38]
# 扩展self.weight的维度为shape[1,512,1,1],然后参考公式
out = self.weight[None,...,None,None] * x
return out
# 测试代码
if __name__ == "__main__":
x = torch.randn(1, 512, 38, 38)
l2norm = L2Norm(512, 20)
out = l2norm(x)
print('L2 norm :', out.shape)
输出:
L2 norm : torch.Size([1, 512, 38, 38])
训练处理
位置坐标转换
Bounding Box的位置表示方式有两种:
A: (x_{min}, \space y_{min}, \space x_{max}, \space y_{max})
B: (x_{c}, \space y_{c}, \space w, \space h)
代码:
# B --> A
def point_form(boxes):
'''
把 prior_box (cx, cy, w, h)转化为(xmin, ymin, xmax, ymax)
'''
return torch.cat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
boxes[:, :2] + boxes[:, 2:]/2,), 1) # xmax, ymax
# A --> B
def center_size(boxes):
'''
把 prior_box (xmin, ymin, xmax, ymax) 转化为 (cx, cy, w, h)
'''
return torch.cat((boxes[:, :2] + boxes[:, 2:])/2, # cx, cy
(boxes[:, 2:] - boxes[:, :2],), 1) # w, h
IOU计算
IOU的原称为Intersection over Union,也就是两个box区域的交集比上并集,下面的示意图就很好理解,用于确定两个框的位置像素距离。
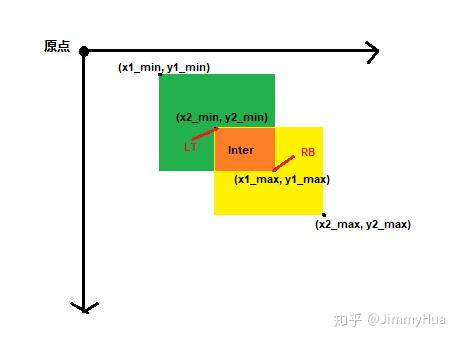
IOU示意图
思路:(注意维度一致)
- 首先计算两个box左上角点坐标的最大值和右下角坐标的最小值
- 然后计算交集面积
- 最后把交集面积除以对应的并集面积
代码:
def iou(box_a, box_b):
'''
IOU = A∩B/A∪B
Args:
box_a: Ground truth bounding box: shape[N, 4]
box_b: Priors bounding box: shape[M, 4]
'''
N = box_a.size(0)
M = box_b.size(0)
# 左上角,选出最大值
LT = torch.max(
box_a[:, :2].unsqueeze(1).expand(N, M, 2), #(N,2)-->(N,1,2)-->(N,M,2)
box_b[:, :2].unsqueeze(0).expand(N, M, 2), #(M,2)-->(M,1,2)-->(N,M,2)
)
# 右上角
RB = torch.min(
box_a[:, 2:].unsqueeze(1).expand(N, M, 2), #(N,2)-->(N,1,2)-->(N,M,2)
box_b[:, 2:].unsqueeze(0).expand(N, M, 2), #(M,2)-->(M,1,2)-->(N,M,2)
)
wh = RB - LT
wh[wh < 0] = 0 # 两个box没有重叠区域
inter = wh[:, :, 0] * wh[:, :, 1] # A∩B
# box_a和box_b的面积
area_a = (box_a[:, 2]-box_a[:, 0]) * (box_a[:, 3]-box_a[:, 1]) #(N,)
area_b = (box_b[:, 2]-box_b[:, 0]) * (box_b[:, 3]-box_b[:, 1]) #(M,)
# 把面积的shape扩展为inter一样的(N,M)
area_a = area_a.unsqueeze(1).expand_as(inter)
area_b = area_b.unsqueeze(0).expand_as(inter)
# iou
iou = inter / (area_a + area_b - inter)
return iou
# 测试代码
if __name__ == "__main__":
box_a = torch.Tensor([[2,1,4,3]])
box_b = torch.Tensor([[3,2,5,4]])
print('IOU = ',iou(box_a, box_b))
输出:
IOU = tensor([[0.1429]])
位置编码和解码
根据论文的描述,预测和真实的边界框是有一个转换关系的,具体如下:
- 先验框位置 d=(d^{cx},\space d^{cy}, \space d^{w}, \space d^{h})
- 真实框位置 g=(g^{cx},\space g^{cy}, \space g^{w}, \space g^{h})
- variance 用于调整检测值
编码: 得到预测框相对于default box的偏移量 l 。
g ^ j c x = ( g j c x ? d i c x ) / d i w / v a r i a n c e [ 0 ] \hat{g}_{j}^{cx}=(g_{j}^{cx}-d_{i}^{cx})/d_{i}^{w}/variance[0] g^?jcx?=(gjcx??dicx?)/diw?/variance[0]
g ^ j c y = ( g j c y ? d i c y ) / d i h / v a r i a n c e [ 1 ] \hat{g}_{j}^{cy}=(g_{j}^{cy}-d_{i}^{cy})/d_{i}^{h}/variance[1] g^?jcy?=(gjcy??dicy?)/dih?/variance[1]
g ^ j w = l o g ( g j w d i w ) / v a r i a n c e [ 2 ] \hat{g}_{j}^{w}=log(\frac{g_{j}^{w}}{d_{i}^{w}})/variance[2] g^?jw?=log(diw?gjw??)/variance[2]
g ^ j h = l o g ( g j h d i h ) / v a r i a n c e [ 3 ] \hat{g}_{j}^{h}=log(\frac{g_{j}^{h}}{d_{i}^{h}})/variance[3] g^?jh?=log(dih?gjh??)/variance[3]
代码:
def encode(matched, priors, variances):
'''
将来至于priorbox的差异编码到ground truth box中
Args:
matched: 每个prior box 所匹配的ground truth,
Shape[M,4],坐标(xmin,ymin,xmax,ymax)
priors: 先验框box, shape[M,4],坐标(cx, cy, w, h)
variances: 方差,list(float)
'''
# 编码中心坐标cx, cy
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 -priors[:, :2]
g_cxcy /= (priors[:, 2:] * variances[0]) #shape[M,2]
# 防止出现log出现负数,从而使loss为 nan
eps = 1e-5
# 编码宽高w, h
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
g_wh = torch.log(g_wh + eps) / variances[1] #shape[M,2]
return torch.cat([g_cxcy, g_wh], 1) #shape[M,4]
解码: 从预测值 l 中得到边界框的真实值。
g ?predict? c x = d w ? ( ?variance? [ 0 ] ? l c x ) + d c x {g_{\text { predict }}^{c x}=d^{w} *\left(\text { variance }[0] * l^{c x}\right)+d^{c x}} g?predict?cx?=dw?(?variance?[0]?lcx)+dcx
g ?predict? c y = d h ? ( ?variance? [ 1 ] ? l c y ) + d c y {g_{\text { predict }}^{c y}=d^{h} *\left(\text { variance }[1] * l^{c y}\right)+d^{c y}} g?predict?cy?=dh?(?variance?[1]?lcy)+dcy
g ?predict? w = d w exp ? ( ?variance? [ 2 ] ? l w ) {g_{\text { predict }}^{w}=d^{w} \exp \left(\text { variance }[2] * l^{w}\right)} g?predict?w?=dwexp(?variance?[2]?lw)
g ?predict? h = d h exp ? ( ?variance? [ 3 ] ? l h ) {g_{\text { predict }}^{h}=d^{h} \exp \left(\text { variance }[3] * l^{h}\right)} g?predict?h?=dhexp(?variance?[3]?lh)
代码:
def decode(loc, priors, variances):
'''
对应encode,解码预测的位置信息
'''
boxes = torch.cat((priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])),1)
# 转化坐标为 (xmin, ymin, xmax, ymax)类型
boxes = point_form(boxes)
return boxes
先验框匹配
在训练过程中,首先需要确定训练图片中的 ground truth 与哪一个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
SSD的先验框和ground truth匹配原则主要两点: 1. 对于图片中的每个gt,找到与其IOU最大的先验框,该先验框与其匹配,这样可以保证每个gt一定与某个prior匹配。 2. 对于剩余未匹配的priors,若某个gt的IOU大于某个阈值(一般0.5),那么该prior与这个gt匹配。
注意点:
- 通常称与gt匹配的prior为正样本,反之,若某一个prior没有与任何一个gt匹配,则为负样本。
- 某个gt可以和多个prior匹配,而每个prior只能和一个gt进行匹配。
- 如果多个gt和某一个prior的IOU均大于阈值,那么prior只与IOU最大的那个进行匹配。
代码:
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
'''
Target:
把和每个prior box 有最大的IOU的ground truth box进行匹配,
同时,编码包围框,返回匹配的索引,对应的置信度和位置
Args:
threshold: IOU阈值,小于阈值设为bg
truths: ground truth boxes, shape[N,4]
priors: 先验框, shape[M,4]
variances: prior的方差, list(float)
labels: 图片的所有类别,shape[num_obj]
loc_t: 用于填充encoded loc 目标张量
conf_t: 用于填充encoded conf 目标张量
idx: 现在的batch index
'''
overlaps = iou(truths, point_form(priors))
# [1,num_objects] 和每个ground truth box 交集最大的 prior box
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# [1,num_priors] 和每个prior box 交集最大的 ground truth box
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
# squeeze shape
best_prior_idx.squeeze_(1) #(N)
best_prior_overlap.squeeze_(1) #(N)
best_truth_idx.squeeze_(0) #(M)
best_truth_overlap.squeeze_(0) #(M)
# 保证每个ground truth box 与某一个prior box 匹配,固定值为 2 > threshold
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# 保证每一个ground truth 匹配它的都是具有最大IOU的prior
# 根据 best_prior_dix 锁定 best_truth_idx里面的最大IOU prior
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# 提取出所有匹配的ground truth box, Shape: [M,4]
matches = truths[best_truth_idx]
# 提取出所有GT框的类别, Shape:[M]
conf = labels[best_truth_idx] + 1
# 把 iou < threshold 的框类别设置为 bg,即为0
conf[best_truth_overlap < threshold] = 0
# 编码包围框
loc = encode(matches, priors, variances)
# 保存匹配好的loc和conf到loc_t和conf_t中
loc_t[idx] = loc # [M,4] encoded offsets to learn
conf_t[idx] = conf # [M] top class label for each prior
NMS抑制
非极大值抑制(Non-maximum suppression,NMS)是一种去除非极大值的算法,常用于计算机视觉中的边缘检测、物体识别等。
算法流程:
给出一张图片和上面许多物体检测的候选框(即每个框可能都代表某种物体),但是这些框很可能有互相重叠的部分,我们要做的就是只保留最优的框。假设有N个框,每个框被分类器计算得到的分数为 $S_i , 1\leqslant i \leqslant N $。
- 建造一个存放待处理候选框的集合H,初始化为包含全部N个框;建造一个存放最优框的集合M,初始化为空集。
- 将所有集合 H 中的框进行排序,选出分数最高的框 m,从集合 H 移到集合 M;
- 遍历集合 H 中的框,分别与框 m 计算交并比(Interection-over-union,IoU),如果高于某个阈值(一般为0~0.5),则认为此框与 m 重叠,将此框从集合 H 中去除。
- 回到第2步进行迭代,直到集合 H 为空。集合 M 中的框为我们所需。
示例:
比如人脸识别的一个例子
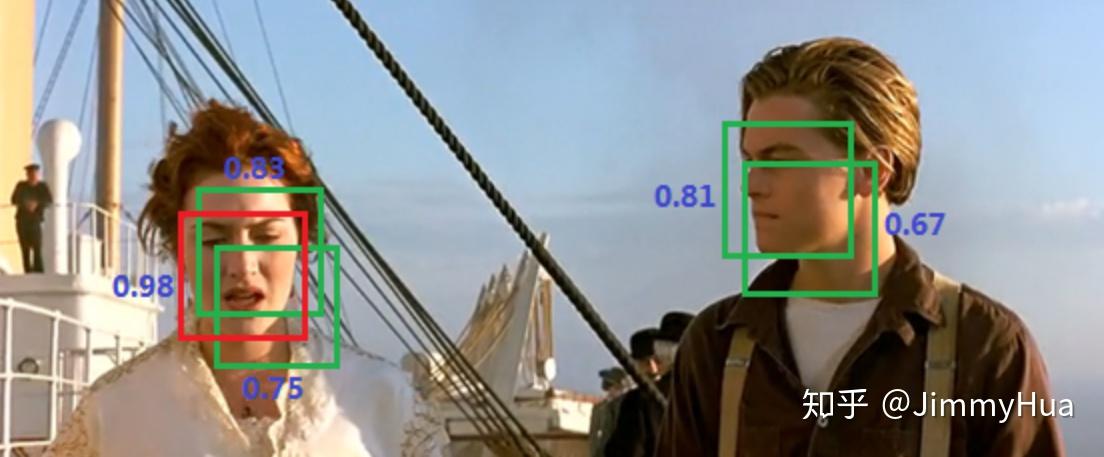
示例
已经识别出了5个候选框,但是我们只需要最后保留两个人脸。
首先选出分数最大的框(0.98),然后遍历剩余框,计算 IoU,会发现露丝脸上的两个绿框都和 0.98 的框重叠率很大,都要去除。
然后只剩下杰克脸上两个框,选出最大框(0.81),然后遍历剩余框(只剩下0.67这一个了),发现0.67这个框与 0.81 的 IoU 也很大,去除。
至此所有框处理完毕,算法结果:

NMS后
代码:
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:
- 选取这类box中scores最大的哪一个,它的index记为 i ,并保留它;
- 计算
boxes[i]与其余的boxes的IOU值; - 如果其
IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个) - 从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
def nms(boxes, scores, threshold=0.5, top_k=200):
'''
Args:
boxes: 预测出的box, shape[M,4]
scores: 预测出的置信度,shape[M]
threshold: 阈值
top_k: 要考虑的box的最大个数
Return:
keep: nms筛选后的box的新的index数组
count: 保留下来box的个数
'''
keep = scores.new(scores.size(0)).zero_().long()
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = (x2-x1)*(y2-y1) # 面积,shape[M]
_, idx = scores.sort(0, descending=True) # 降序排列scores的值大小
# 取前top_k个进行nms
idx = idx[:top_k]
count = 0
while idx.numel():
# 记录最大score值的index
i = idx[0]
# 保存到keep中
keep[count] = i
# keep 的序号
count += 1
if idx.size(0) == 1: # 保留框只剩一个
break
idx = idx[1:] # 移除已经保存的index
# 计算boxes[i]和其他boxes之间的iou
xx1 = x1[idx].clamp(min=x1[i])
yy1 = y1[idx].clamp(min=y1[i])
xx2 = x2[idx].clamp(max=x2[i])
yy2 = y2[idx].clamp(max=y2[i])
w = (xx2 - xx1).clamp(min=0)
h = (yy2 - yy1).clamp(min=0)
# 交集的面积
inter = w * h # shape[M-1]
iou = inter / (area[i] + area[idx] - inter)
# iou满足条件的idx
idx = idx[iou.le(threshold)] # Shape[M-1]
return keep, count
其中:
- torch.numel(): 表示一个张量总元素的个数
- torch.clamp(min, max): 设置上下限
- tensor.le(x): 返回tensor<=x的判断
Detection函数
模型进行测试的时候,需要把预测出的loc和conf输入到detect函数进行nms,最后给出相应的结果。
代码:
class Detect(Function):
def __init__(self, num_classes, top_k, conf_thresh, nms_thresh):
self.num_classes = num_classes
self.top_k = top_k
self.conf_thresh = conf_thresh
self.nms_thresh = nms_thresh
self.variance = cfg['variance']
def forward(self, loc_data, conf_data, prior_data):
'''
Args:
loc_data: 预测出的loc张量,shape[b,M,4], eg:[b, 8732, 4]
conf_data: 预测出的置信度,shape[b,M,num_classes], eg:[b, 8732, 21]
prior_data: 先验框,shape[M,4], eg:[8732, 4]
'''
batch = loc_data.size(0) # batch size
output = torch.zeros(batch, self.num_classes, self.top_k, 5) # 初始化输出
conf_preds = conf_data.transpose(2,1)
# 解码loc的信息,变为正常的bboxes
for i in range(batch):
# 解码loc
decode_boxes = decode(loc_data[i], prior_data, self.variance)
# 拷贝每个batch内的conf,用于nms
conf_scores = conf_preds[i].clone()
# 遍历每一个类别
for num in range(1, self.num_classes):
# 筛选掉 conf < conf_thresh 的conf
c_mask = conf_scores[num].gt(self.conf_thresh)
scores = conf_scores[num][c_mask]
# 如果都被筛掉了,则跳入下一类
if scores.size(0) == 0:
continue
# 筛选掉 conf < conf_thresh 的框
l_mask = c_mask.unsqueeze(1).expand_as(decode_boxes)
boxes = decode_boxes[l_mask].view(-1, 4)
# nms
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
# nms 后得到的输出拼接
output[i, num, :count] = torch.cat((
scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1)
return output
# 代码测试
if __name__ == "__main__":
detect = Detect(21, 200, 0.01, 0.5)
loc_data = torch.randn(1,8732,4)
conf_data = torch.randn(1,8732,21)
prior_data = torch.randn(8732, 4)
out = detect(loc_data, conf_data, prior_data)
print('Detect output shape:', out.shape)
输出:
Detect output shape: torch.Size([1, 21, 200, 5])
w = (xx2 - xx1).clamp(min=0)
h = (yy2 - yy1).clamp(min=0)
# 交集的面积
inter = w * h # shape[M-1]
iou = inter / (area[i] + area[idx] - inter)
# iou满足条件的idx
idx = idx[iou.le(threshold)] # Shape[M-1]
return keep, count
其中:
- torch.numel(): 表示一个张量总元素的个数
- torch.clamp(min, max): 设置上下限
- tensor.le(x): 返回tensor<=x的判断
## Detection函数
模型进行测试的时候,需要把预测出的loc和conf输入到detect函数进行nms,最后给出相应的结果。
**代码:**
```python
class Detect(Function):
def __init__(self, num_classes, top_k, conf_thresh, nms_thresh):
self.num_classes = num_classes
self.top_k = top_k
self.conf_thresh = conf_thresh
self.nms_thresh = nms_thresh
self.variance = cfg['variance']
def forward(self, loc_data, conf_data, prior_data):
'''
Args:
loc_data: 预测出的loc张量,shape[b,M,4], eg:[b, 8732, 4]
conf_data: 预测出的置信度,shape[b,M,num_classes], eg:[b, 8732, 21]
prior_data: 先验框,shape[M,4], eg:[8732, 4]
'''
batch = loc_data.size(0) # batch size
output = torch.zeros(batch, self.num_classes, self.top_k, 5) # 初始化输出
conf_preds = conf_data.transpose(2,1)
# 解码loc的信息,变为正常的bboxes
for i in range(batch):
# 解码loc
decode_boxes = decode(loc_data[i], prior_data, self.variance)
# 拷贝每个batch内的conf,用于nms
conf_scores = conf_preds[i].clone()
# 遍历每一个类别
for num in range(1, self.num_classes):
# 筛选掉 conf < conf_thresh 的conf
c_mask = conf_scores[num].gt(self.conf_thresh)
scores = conf_scores[num][c_mask]
# 如果都被筛掉了,则跳入下一类
if scores.size(0) == 0:
continue
# 筛选掉 conf < conf_thresh 的框
l_mask = c_mask.unsqueeze(1).expand_as(decode_boxes)
boxes = decode_boxes[l_mask].view(-1, 4)
# nms
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
# nms 后得到的输出拼接
output[i, num, :count] = torch.cat((
scores[ids[:count]].unsqueeze(1),
boxes[ids[:count]]), 1)
return output
# 代码测试
if __name__ == "__main__":
detect = Detect(21, 200, 0.01, 0.5)
loc_data = torch.randn(1,8732,4)
conf_data = torch.randn(1,8732,21)
prior_data = torch.randn(8732, 4)
out = detect(loc_data, conf_data, prior_data)
print('Detect output shape:', out.shape)
输出:
Detect output shape: torch.Size([1, 21, 200, 5])
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!