Hadoop集群环境下HDFS实践编程过滤出所有后缀名不为“.abc”的文件时运行报错:java.net.ConnectException: 拒绝连接;
一、问题描述
搭建完Hadoop集群后,在Hadoop集群环境下运行HDFS实践编程使用Eclipse开发调试HDFS Java程序(文末有源码):
假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
在执行上述任务时,运行代码后报错:
Exception in thread "main" java.net.ConnectException: Call From Master/192.168.52.136 to localhost:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: ?http://wiki.apache.org/hadoop/ConnectionRefused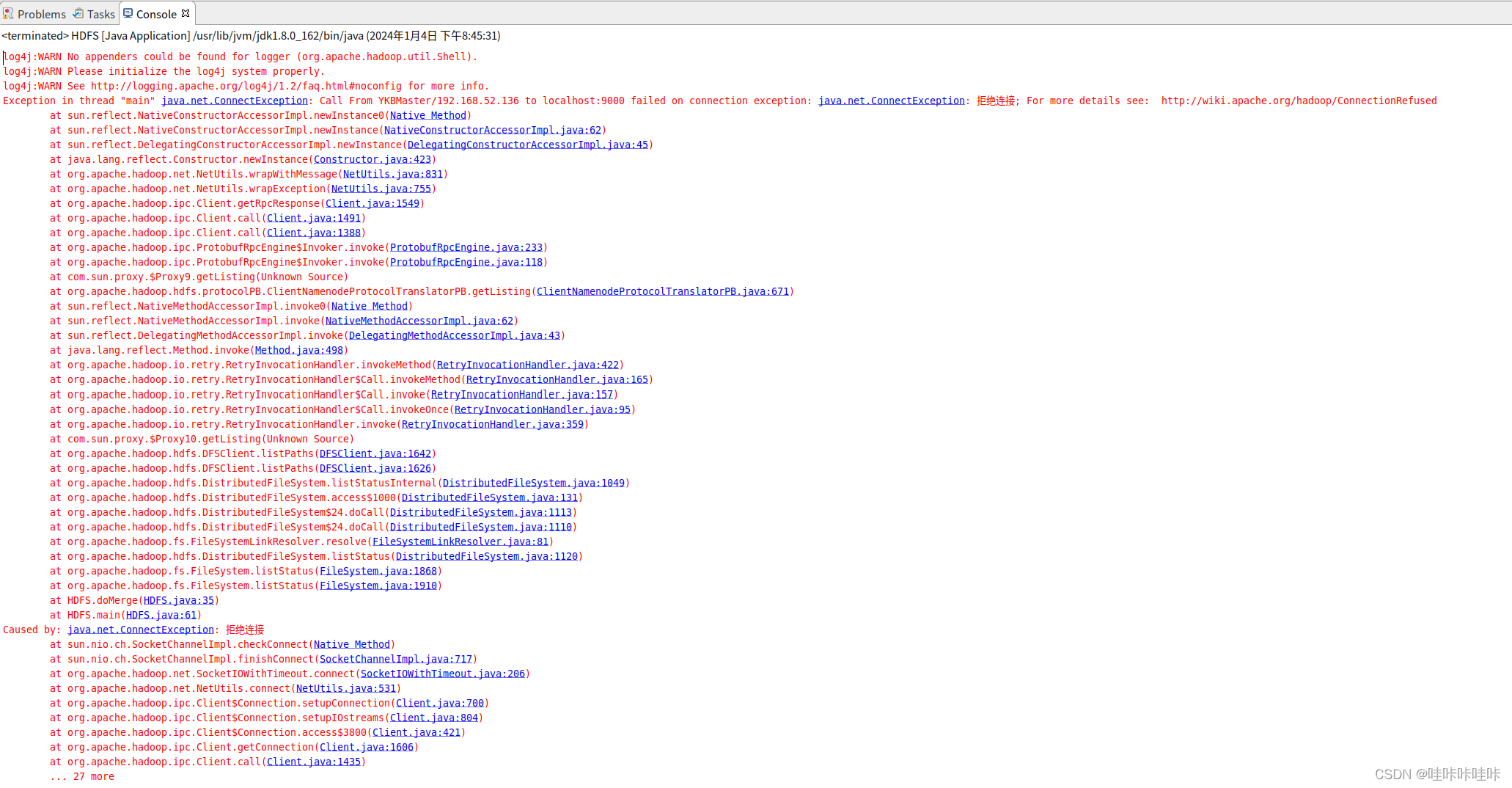
二、解决办法
将代码中“localhost”修改为自己的主节点的主机名
修改之前:
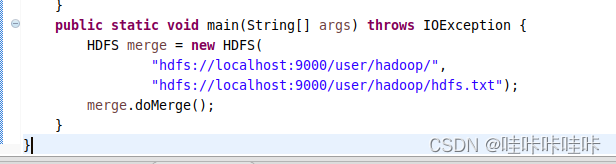
修改之后:

修改完成后再次运行即可成功:

查看HDFS家目录下的内容:

查看hdfs.txt中的内容:

如上,证明程序正常运行且运行成功。
至此,问题解决!!!
三、问题分析及可能出现的问题
1.问题分析
出现 "Exception in thread "main" java.net.ConnectException: Call From Master/192.168.52.136 to localhost:9000 failed on connection exception: java.net.ConnectException: 拒绝连接" 错误通常表示无法建立到Hadoop的NameNode(通常在localhost:9000)的连接。这可能是由以下原因导致的:
1. Hadoop服务未启动:请确保已经正确启动了Hadoop集群中的所有必要服务,包括NameNode。您可以通过运行`jps`命令来检查所需的Hadoop进程是否正在运行。
2. 网络连接问题:请确保主节点(Master/192.168.52.136)可以与NameNode服务器正常通信。可以尝试使用telnet命令验证是否能够连接到localhost的9000端口,例如:`telnet localhost 9000`。如果无法连接,请检查网络配置并确保端口未被防火墙阻止。
3. Hadoop配置错误:请检查Hadoop的核心配置文件(如`core-site.xml`和`hdfs-site.xml`)中的相关属性,特别是`fs.defaultFS`和`dfs.namenode.rpc-address`。确保它们正确的设置为NameNode的地址和端口。
4. 资源不足:如果系统资源不足,可能会导致Hadoop服务运行异常。请确保集群节点具有足够的内存和处理能力来支持Hadoop运行。
5.权限问题:请确保具有足够的权限来访问Hadoop集群。检查在运行Eclipse时使用的用户是否具有适当的权限。
此处是因为未访问到正确的地址端口导致无法与hdfs建立连接而导致的问题。
2.可能出现的问题
若出现“Exception in thread "main" java.io.FileNotFoundException: Path is not a file: /user/hadoop/input”的问题,可参考:
四、源码
执行的任务是:假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
现附上源码如下:
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
+ " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://localhost:9000/user/hadoop/",
"hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!