【Transformer】深入理解Transformer模型1——初步认识了解
前言
Transformer模型出自论文:《Attention is All You Need》 2017年
近年来,在自然语言处理领域和图像处理领域,Transformer模型都受到了极为广泛的关注,很多模型中都用到了Transformer或者是Transformer模型的变体,而且对于很多任务,使用加了Transformer的模型可以获得更好的效果,这也证明了Transformer模型的有效性。
由于Transformer模型内容较多,想要深入理解该模型并不容易,所以我分了大概4篇博客来介绍Transformer模型,第一篇(也就是本篇博客)主要介绍Transformer模型的整体架构,对模型有一个初步的认识和了解;第二篇是看了b站李宏毅老师的Transformer模型讲解之后,做的知识总结(内容比较多,会分成两篇博客);第三篇从代码的角度来理解Transformer模型。
目前我只完成了前两篇论文,地址如下,之后完成第三篇会进行更新。
第一篇:【Transformer】深入理解Transformer模型1——初步认识了解
第二篇:【Transformer】深入理解Transformer模型2——深入认识理解(上)-CSDN博客
第三篇:【Transformer】深入理解Transformer模型2——深入认识理解(下)-CSDN博客
第四篇:
初步认识
????????之前的RNN模型记忆长度有限且无法并行化,只有计算完ti时刻后的数据才能计算ti+1时刻的数据,但Transformer都可以做到。
????????本文提出了一个完全基于注意力机制的网络结构transformer来处理序列相关问题,跟以往不同,没有用到CNN和RNN的结构,将encoder-decoder中的循环层替换成了multi-head attention机制,且能够实现并行化操作提高模型效率,同时能够捕捉序列中各个位置之间的相对关系,进而更好地对序列进行建模。
????????具体来说,自注意力机制允许模型同时计算输入序列中所有位置之间的关系权重,进而加权得到每个位置的特征表示。在Transformer模型中,子注意力机制被运用在了Encoder和Decoder两个部分中,分别用于编码输入序列和生成输出序列。
注意:transformer的并行化主要体现在self-attention模块上,在encoder端其可以并行处理整个序列,而不像RNN、LSTM那样要一个token一个token的从前往后计算。
????????此外,本文还提出了一种新的训练方法,称为“无序列信息的训练(Training without sequence information)”,其基本思想是将输入序列中的每个位置看作独立的词向量,而不考虑它们在序列中的位置信息。通过这种方式,可以避免序列中的位置信息对模型训练的影响,提高模型的泛化性能。
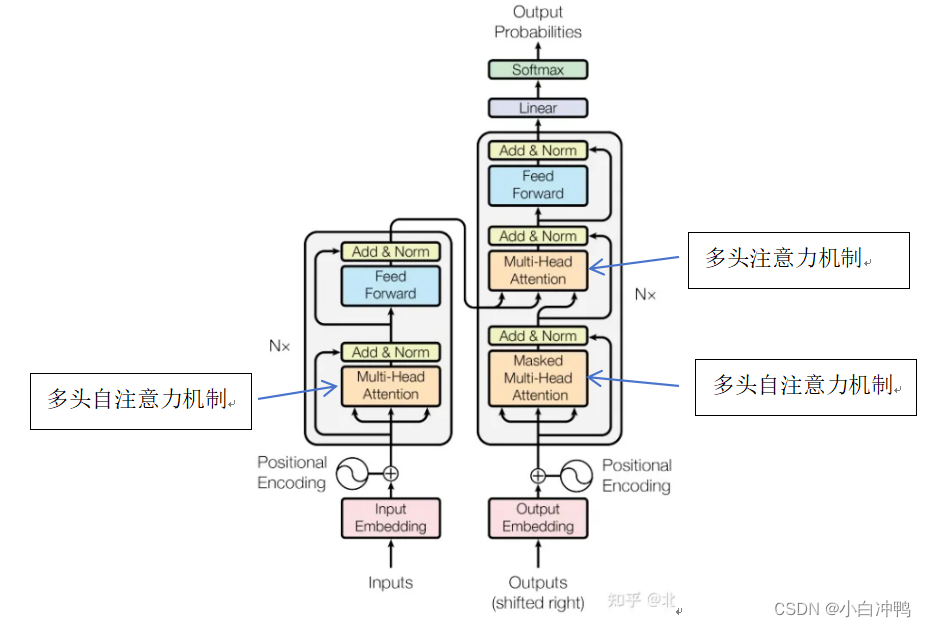
具体结构介绍:
Encoder:
????????Encoder的作用是将输入序列编码成一个高维向量表示,该向量表示将被输入到Decoder中用于生成输出序列。Encoder包括多个Encoder层,每个Encoder层由两个子层组成:多头自注意力机制和前馈网络。
(1)多头自注意力机制:
????????多头自注意力机制(multi-head self-attention)是transformer模型的核心部分,其作用是从输入序列中学习并计算每个位置与其他位置(包括自身)之间的相关度。具体来说,多头自注意力机制将输入序列中的每个位置看作一个向量,然后对这些向量进行相似度计算,得到每个位置与其它位置(包括自身)之间的相关度。
????????多头自注意力机制将输入序列分别映射成多个维度相同的向量,然后分别应用自注意力机制,得到多个输出向量,最后将这些输出向量拼接起来,得到最终的向量表示。这种分头处理的方法可以使模型更好地捕捉不同方面的特征,从而提高模型的表现。
(2)前馈网络:
????????前馈网络(feedforward network)是Encoder层的另一个子层,其作用是对多头自注意力机制的输出向量进行非线性变换。前馈网络由两个线性变换和一个激活函数组成,其中线性变换将输入向量映射到一个高维空间,激活函数将这个高维向量进行非线性变换,最后再将其映射回原始维度。
Decoder:
????????Decoder的作用是生成输出序列,它包括多个Decoder层,每个Decoder层由三个子层组成:多头自注意力机制、多头注意力机制和前馈网络。
(1)多头自注意力机制:
????????多头自注意力机制在Decoder中的作用与Encoder中类似,不同的是,它只关注当前时刻之前的位置。这种机制可以帮助模型更好地捕捉输入序列中的信息,并在生成输出序列时保留这些信息。
????????masked的作用就像是在进行解码的时候遮住了后面顺序的向量,只考虑前面已经出现的特征(因为解码的时候是一个一个输出的,在解前面特征的时候没有办法把后i按未解码的部分考虑进来,这和Encoder不一样)。
(2)多头注意力机制:
????????多头注意力机制(multi-head attention)是Decoder中的另一个子层,其作用是计算当前时刻的输入与输入序列之间的关系,并根据这些关系计算出当前时刻的上下文向量表示。
????????多头注意力机制将输入序列的向量表示与当前时刻的输入向量表示进行相似度计算,得到每个位置(输入序列中的)与当前时刻输入的相关度。然后,根据这些相关度计算当前时刻的上下文向量表示,用于生成输出序列。与多头自注意力机制类似,多头注意力机制也采用了分头处理的方式,从而更好地捕捉不同方面的特征。
(3)前馈网络:
????????前馈网络在Decoder中的作用与Encoder中类似,其作用是对多头自注意力机制和多头注意力机制的输出向量进行非线性变换。前馈网络同样由两个线性变换和一个激活函数组成,其中线性变换将输入向量映射到一个高维空间,激活函数将这个高维向量进行非线性变换,最后再将其映射回原始维度。
(4)损失函数:
????????Transformer模型使用了交叉熵损失函数(cross-entropy loss)作为优化目标,其目标是最小化模型生成的序列与目标序列之间的差异。具体来说,对于给定的输入序列和目标序列,Transformer模型通过最大化目标序列中每个位置的条件概率来生成输出序列。
总结:
????????Transformer模型通过引入自注意力机制和多头注意力机制来替代传统的RNN和CNN,从而提高了模型的表现。同时,Transformer模型还采用了分头处理和残差连接等技术,进一步提高了模型的效率和表现。该模型在机器翻译等任务中取得了极高的性能,成为自然语言处理领域的经典模型之一。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!