实现pytorch版的mobileNetV1
2024-01-09 23:36:05
mobileNet具体细节,在前面已做了分析记录:轻量化网络-MobileNet系列-CSDN博客
这里是根据网络结构,搭建模型,用于图像分类任务。
1. 网络结构和基本组件
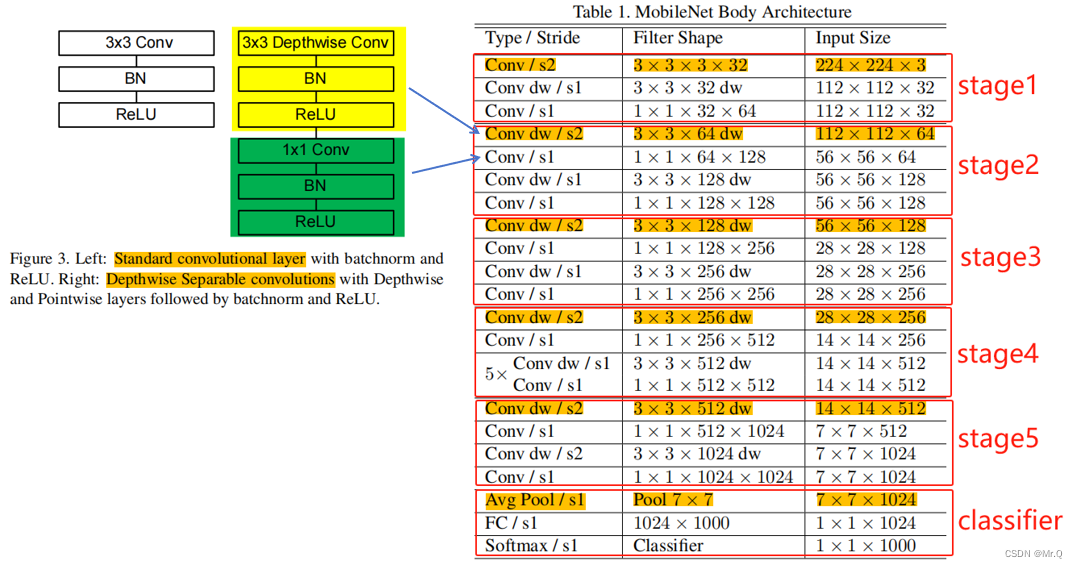
2. 搭建组件
(1)普通的卷积组件:CBL?= Conv2d + BN + ReLU6;
(2)深度可分离卷积:DwCBL? = Conv dw+ Conv dp;
Conv dw+ Conv dp = {Conv2d(3x3) + BN + ReLU6 }? + {Conv2d(1x1) + BN + ReLU6};
Conv dw是3x3的深度卷积,通过步长控制是否进行下采样;
Conv dp是1x1的逐点卷积,通过控制输出通道数,控制通道维度的变化;
# 普通卷积
class CBN(nn.Module):
def __init__(self, in_c, out_c, stride=1):
super(CBN, self).__init__()
self.conv = nn.Conv2d(in_c, out_c, 3, stride, padding=1, bias=False)
self.bn = nn.BatchNorm2d(out_c)
self.relu = nn.ReLU6(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x# 深度可分离卷积: 深度卷积(3x3x1) + 逐点卷积(1x1xc卷积)
class DwCBN(nn.Module):
def __init__(self, in_c, out_c, stride=1):
super(DwCBN, self).__init__()
# conv3x3x1, 深度卷积,通过步长,只控制是否缩小特征hw
self.conv3x3 = nn.Conv2d(in_c, in_c, 3, stride, padding=1, groups=in_c, bias=False)
self.bn1 = nn.BatchNorm2d(in_c)
self.relu1 = nn.ReLU6(inplace=True)
# conv1x1xc, 逐点卷积,通过控制输出通道数,控制通道维度的变化
self.conv1x1 = nn.Conv2d(in_c, out_c, 1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_c)
self.relu2 = nn.ReLU6(inplace=True)
def forward(self, x):
x = self.conv3x3(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv1x1(x)
x = self.bn2(x)
x = self.relu2(x)
return x3. 搭建网络
class MobileNetV1(nn.Module):
def __init__(self, class_num=1000):
super(MobileNetV1, self).__init__()
self.stage1 = torch.nn.Sequential(
CBN(3, 32, 2), # 下采样/2
DwCBN(32, 64, 1)
)
self.stage2 = torch.nn.Sequential(
DwCBN(64, 128, 2), # 下采样/4
DwCBN(128, 128, 1)
)
self.stage3 = torch.nn.Sequential(
DwCBN(128, 256, 2), # 下采样/8
DwCBN(256, 256, 1)
)
self.stage4 = torch.nn.Sequential(
DwCBN(256, 512, 2), # 下采样/16
DwCBN(512, 512, 1), # 5个
DwCBN(512, 512, 1),
DwCBN(512, 512, 1),
DwCBN(512, 512, 1),
DwCBN(512, 512, 1),
)
self.stage5 = torch.nn.Sequential(
DwCBN(512, 1024, 2), # 下采样/32
DwCBN(1024, 1024, 1)
)
# classifier
self.avg_pooling = torch.nn.AdaptiveAvgPool2d((1, 1))
self.fc = torch.nn.Linear(1024, class_num, bias=True)
# self.classifier = torch.nn.Softmax() # 原始的softmax值
# torch.log_softmax 首先计算 softmax 然后再取对数,因此在数值上更加稳定。
# 在分类网络在训练过程中,通常使用交叉熵损失函数(Cross-Entropy Loss)。
# torch.nn.CrossEntropyLoss 会在内部进行 softmax 操作,因此在网络的最后一层不需要手动加上 softmax 操作。
def forward(self, x):
scale1 = self.stage1(x) # /2
scale2 = self.stage2(scale1)
scale3 = self.stage3(scale2)
scale4 = self.stage4(scale3)
scale5 = self.stage5(scale4) # /32. 7x7
x = self.avg_pooling(scale5) # (b,1024,7,7)->(b,1024,1,1)
x = torch.flatten(x, 1) # (b,1024,1,1)->(b,1024,)
x = self.fc(x) # (b,1024,) -> (b,1000,)
return x
if __name__ == '__main__':
m1 = MobileNetV1(class_num=1000)
input_data = torch.randn(64, 3, 224, 224)
output = m1.forward(input_data)
print(output.shape)4. 训练验证
import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn, optim
from mobilenetv1 import MobileNetV1
def validate(model, val_loader, criterion, device):
model.eval() # Set the model to evaluation mode
total_correct = 0
total_samples = 0
with torch.no_grad():
for val_inputs, val_labels in val_loader:
val_inputs, val_labels = val_inputs.to(device), val_labels.to(device)
val_outputs = model(val_inputs)
_, predicted = torch.max(val_outputs, 1)
total_samples += val_labels.size(0)
total_correct += (predicted == val_labels).sum().item()
accuracy = total_correct / total_samples
model.train() # Set the model back to training mode
return accuracy
if __name__ == '__main__':
# 下载并准备数据集
# Define image transformations (adjust as needed)
transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize images to a consistent size
transforms.ToTensor(), # converts to PIL Image to a Pytorch Tensor and scales values to the range [0, 1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # Adjust normalization values. val = (val - mean) / std.
])
# Create ImageFolder dataset
data_folder = r"D:\zxq\data\car_or_dog"
dataset = torchvision.datasets.ImageFolder(root=data_folder, transform=transform)
# Optionally, split the dataset into training and validation sets
# Adjust the `split_ratio` as needed
split_ratio = 0.8
train_size = int(split_ratio * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
# Create DataLoader for training and validation
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=4)
# 初始化模型、损失函数和优化器
net = MobileNetV1(class_num=2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
# 训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
net.to(device)
for epoch in range(20): # 例如,训练 20 个周期
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将数据移动到GPU
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if i % 100 == 0:
print("epoch/step: {}/{}: loss: {}".format(epoch, i, loss.item()))
# Validation after each epoch
val_accuracy = validate(net, val_loader, criterion, device)
print("Epoch {} - Validation Accuracy: {:.2%}".format(epoch, val_accuracy))
print('Finished Training')待续。。。
文章来源:https://blog.csdn.net/jizhidexiaoming/article/details/135405902
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!