【MySQL】表的增删查改
文章目录
表的增删查改
CRUD是数据库中常用的术语,表示对数据进行增、删、查、改的操作,下面看一下所谓的 'C'、'R'、'U'、'D' 所表示的意思:
-
C: Create(创建),当然数据库的表插入是insert,创建是Create
-
R: Retrieve(查询),就是select
-
U: Update(更新),就是Update
-
D: Delete(删除),就是Delete
Create
Create表示新增数据
💕 语法
insert [into] table_name
[(column [, column] ...)]
values (value_list) [, (value_list)] ...
value_list: value, [, value] ...

单行数据 + 全列插入
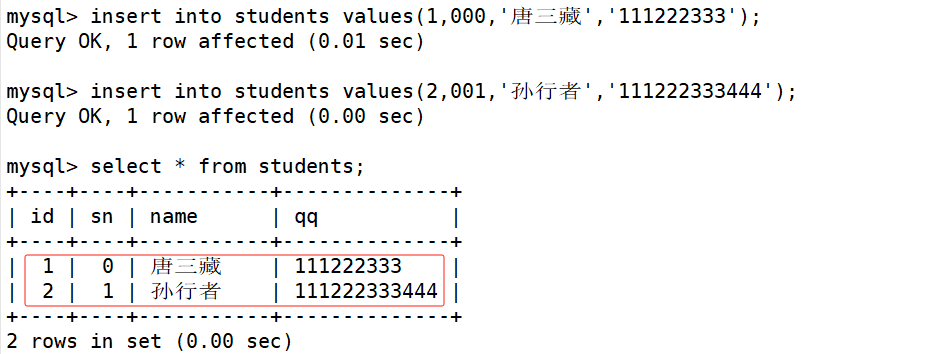
按照表中默认的列顺序进行 全列插入,因此插入的每条记录中的列值需要按表列顺序依次列出。如下
mysql> insert into students values(1,000,'唐三藏','111222333');
Query OK, 1 row affected (0.01 sec)
mysql> insert into students values(2,001,'孙行者','111222333444');
Query OK, 1 row affected (0.00 sec)
这里我们需要注意的是:
- 插入数据时,value_list 数量必须和定义表的列的数量及顺序一致。
- 再插入数据记录时,也可以不用指定id(当然,那时候就需要明确插入数据到哪些列了)那么MySQL会使用默认的值进行自增。
多行数据+指定列插入
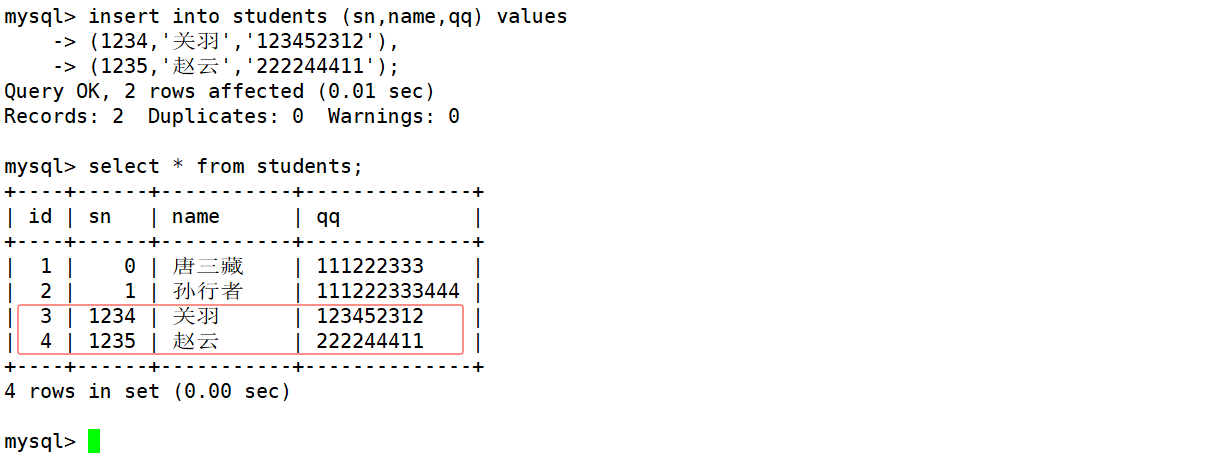
使用insert语句也可以 一次向表中插入多条记录,插入的多条记录之间使用逗号隔开,并且插入记录时可以只指定某些列进行插入。
mysql> insert into students (sn,name,qq) values
-> (1234,'关羽','123452312'),
-> (1235,'赵云','222244411');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
插入否则更新
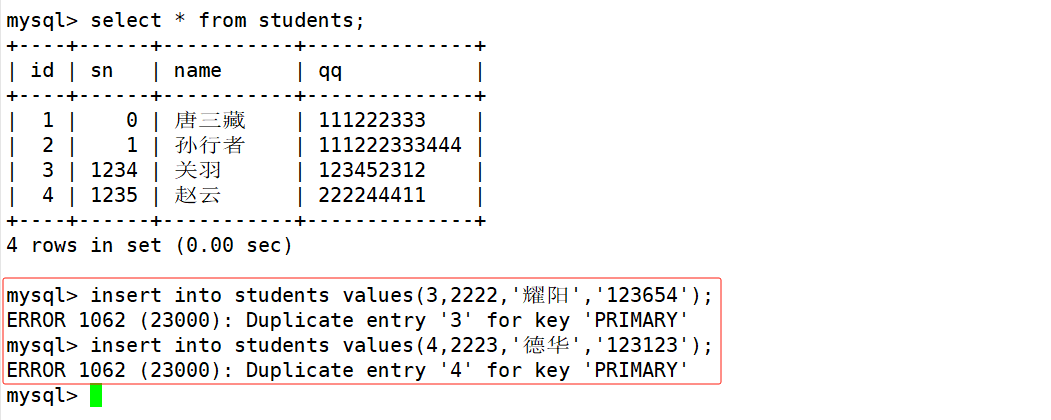
向表中插入记录时,如果待插入记录中的主键或唯一键已经存在,那么就会因为主键冲突或唯一键冲突导致插入失败。如下:
这时可以 选择性的进行同步更新 操作:
- 如果表中没有冲突数据,则直接插入数据。
- 如果表中有冲突数据,则将表中的数据进行更新。
插入否则更新的SQL如下:
insert... on duplicate key update
column = value [, column = value] ..
-- on duplicate key 当发生重复key的时候,进行更新
mysql> insert into students values(4,2223,'德华','123123')
-> on duplicate key update sn=2223,name='德华';
Query OK, 2 rows affected (0.00 sec)
mysql> insert into students values(3,2222,'耀阳','123654')
-> on duplicate key update sn=2222,name='耀阳';
Query OK, 2 rows affected (0.00 sec)
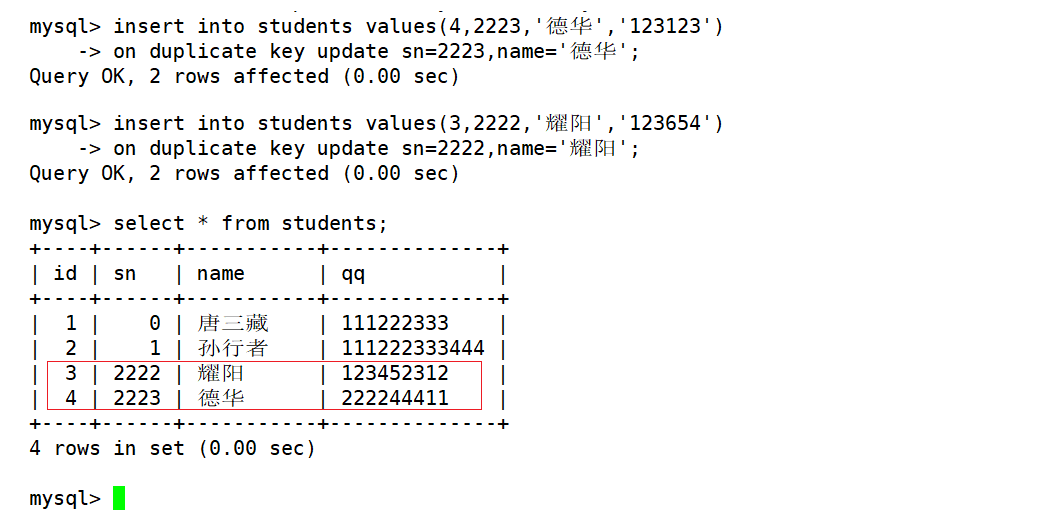
执行插入否则更新的SQL后,可以通过受影响的数据行数来判断本次数据的插入情况:
0rows affected:表中有冲突数据,但冲突数据的值和指定更新的值相同。1row affected:表中没有冲突数据,数据直接被插入。2rows affected:表中有冲突数据,并且数据已经被更新。
替换数据
替换数据: 如果表中没有冲突数据,则直接插入数据。如果表中有冲突数据,则先将表中的冲突数据删除,然后再插入数据。
要达到上述效果,只需要在插入数据时将SQL语句中的 insert 改为 replace 即可。比如:
mysql> replace into students (sn,name) values(0,'穆桂英');
Query OK, 2 rows affected (0.01 sec)

执行替换数据的SQL后,也可以通过受影响的数据行数来判断本次数据的插入情况:
1row affected:表中没有冲突数据,数据直接被插入。2rows affected:表中有冲突数据,冲突数据被删除后重新插入。
Retrieve
查找数据
select
[distinct] {* | {column [, column] ...} #去重
[from table_name]
[where ...] #查询条件
[order by column [asc | desc], ...] #升序/降序
limit ...#显式几行数据记录
说明一下:
- SQL中大写的表示关键字,
[ ]中代表的是可选项。 { }中的 | 代表的是选择左侧的语句或右侧的语句。
下面我们创建一个成绩表,表当中包含自增长的主键id、姓名以及该同学的语文成绩、数学成绩和英语成绩。如下:
create table exam_result(
id int unsigned primary key auto_increment comment '主键',
name varchar(20) not null comment '同学姓名',
chinese float default 0.0 comment '语文成绩',
math float default 0.0 comment '数学成绩',
english float default 0.0 comment '英语成绩'
);
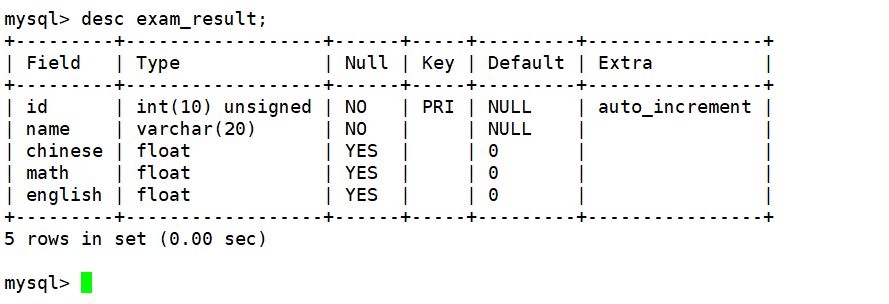
下面向表中插入几条测试记录,以供我们进行查找。如下:
mysql> insert into exam_result (name,chinese,math,english) values
-> ('唐三藏',67,98,56),
-> ('孙悟空',87,78,77),
-> ('曹孟德',82,84,67),
-> ('刘玄德',55,85,45),
-> ('孙权',70,73,78),
-> ('宋公明',75,65,30),
-> ('猪悟能',88,98,90);
SELECT列
全列查询
当我们在查询时直接用 * 代替column列表,表示进行全列查询,这时将会显示被筛选出来的记录的所有列信息。通常情况下不建议使用 * 进行全列查询,因为被查询到的数据需要通过网络从MySQL服务器传输到本主机,查询的列越多也就意味着需要传输的数据量越大,此外,进行全列查询还可能会影响到索引的使用。
💕 指定列查询
指定列查询
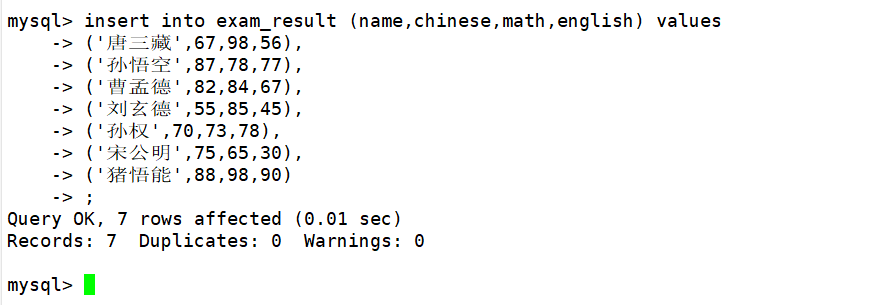
在查询数据时可以只对指定列进行查询,这时将需要查询的列在column列表列出即可。如下:
mysql> select name,math from exam_result;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 孙权 | 73 |
| 宋公明 | 65 |
| 猪悟能 | 98 |
+-----------+------+
7 rows in set (0.00 sec)
💕 查询字段为表达式
查询数据时,column列表中除了能罗列出表中存在的列明外,我们也可以将表达式罗列到column列表中。如下:
mysql> select id,name, 1+1 from exam_result;
+----+-----------+-----+
| id | name | 1+1 |
+----+-----------+-----+
| 1 | 唐三藏 | 2 |
| 2 | 孙悟空 | 2 |
| 3 | 曹孟德 | 2 |
| 4 | 刘玄德 | 2 |
| 5 | 孙权 | 2 |
| 6 | 宋公明 | 2 |
| 7 | 猪悟能 | 2 |
+----+-----------+-----+
7 rows in set (0.00 sec)

因为select不仅可以用来查询数据,而且也可以用来计算某些表达式或执行某些函数。如下:

如果我们将表达式罗列到column列表,那么每一条记录被筛选出来时就会执行这个表达式,然后将表达式的计算结果作为这条记录的一个列值进行显示。
column列表中的表达式可以包含表中已有的字段,这是每一条记录被筛选出来时,就会记录中对应的列值提供给表达式进行计算,如下:
mysql> select id,name,math+10 from exam_result;
+----+-----------+---------+
| id | name | math+10 |
+----+-----------+---------+
| 1 | 唐三藏 | 108 |
| 2 | 孙悟空 | 88 |
| 3 | 曹孟德 | 94 |
| 4 | 刘玄德 | 95 |
| 5 | 孙权 | 83 |
| 6 | 宋公明 | 75 |
| 7 | 猪悟能 | 108 |
+----+-----------+---------+
7 rows in set (0.00 sec)

💕 为查询结果指定别名
SELECT column [AS] alias_name [...] FROM table_name;
说明一下:SQL中大写的表示关键字,[ ]中代表的是可选项。
比如查询表中的数据时,将每一条记录中的三科成绩相加,然后将相加结果对应的列指定别名为“总分”,如下:
mysql> select id,name,chinese+math+english 总分 from exam_result;
+----+-----------+--------+
| id | name | 总分 |
+----+-----------+--------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 曹孟德 | 233 |
| 4 | 刘玄德 | 185 |
| 5 | 孙权 | 221 |
| 6 | 宋公明 | 170 |
| 7 | 猪悟能 | 276 |
+----+-----------+--------+
7 rows in set (0.00 sec)

💕 结果去重
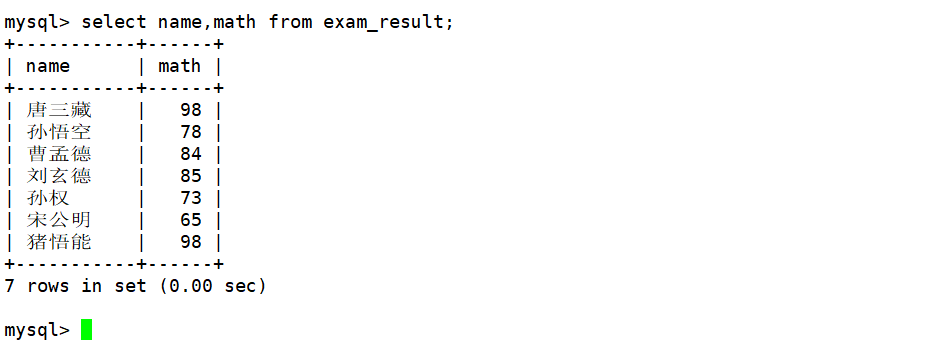
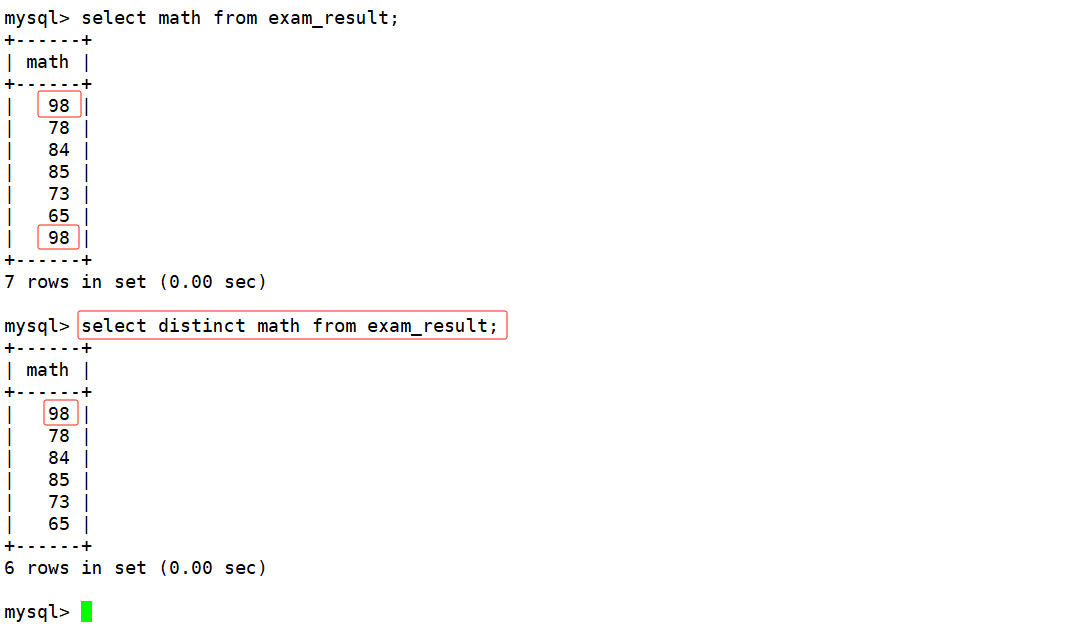
查询到成绩时指定查询数学成绩对应的列,可以看到数学成绩中有重复的分数。如果想要对查询结果进行去重操作,可以在SQL中的select后面带上distinct。如下:
mysql> select distinct math from exam_result;
WHERE条件
添加where子句的区别:
- 如果在查询数据时没有指定where子句,那么会直接将表中所有的记录作为数据源来依次执行select语句。
- 如果在查询数据时指定了where子句,那么在查询数据时会先根据where子句筛选出符合条件的记录,然后将符合条件的记录作为数据源来依次执行select语句。
where子句中可以指明一个或多个筛选条件,各个筛选条件之间用逻辑运算符AND或OR进行关联,下面给出了where子句中常用的比较运算符和逻辑运算符。
比较运算符:
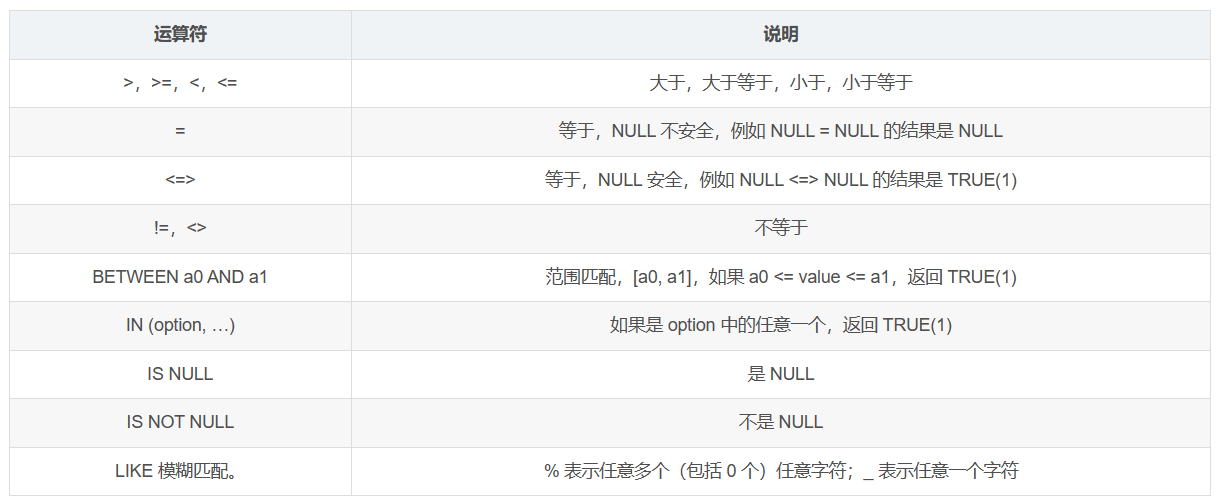
逻辑运算符:

查询英语不及格的同学及其英语成绩
select name, english from exam_result where english<60;

查询语文成绩在80到90分的同学及其语文成绩
select name,chinese from exam_result where chinese>=80 and chinese<=90;

当然,这里也可以使用 between a0 and a1 来指明语文成绩的所在区间。如下:
select name,chinese from exam_result where chinese between 80 and 90;

查询数学成绩是58或59或98或99分的同学及其数学成绩
select name,math from exam_result where math=58 or math=59 or math=98 or math=99;
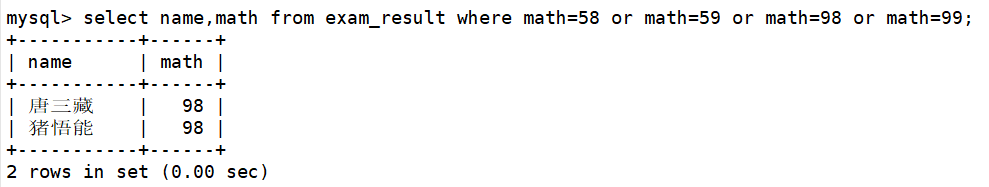
同样,这里也可以用IN(58,59,98,99)的方式来判断数学成绩是否符合筛选要求。如下:
select name,math from exam_result where math in(58,59,98,99);

分别查询性孙的同学和孙某同学
查询姓孙的同学
在where子句中通过模糊匹配来判断当前同学是否性孙(需要用到%来匹配多个字符),在select的column列表中指明要查询的列为姓名。如下:
select name from exam_result where name like '孙%';

查询孙某同学
在where子句中通过模糊匹配来判断当前同学是否性孙(需要用到_来匹配多个字符),在select的column列表中指明要查询的列为姓名。如下:
select name from exam_result where name like '孙_';

查询语文成绩好于英语成绩的同学
select name,chinese,english from exam_result where chinese>english;

查询总成绩在120分以下的同学
select name,chinese+math+english 总分 from exam_result where chinese+math+english<200;

需要注意的是,在where子句中不能使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录。
- 然后再将符合条件的记录作为数据源来依次执行select语句。
也就是说,where子句的执行是先于select语句的,所以在where子句中不能使用别名,如果在where子句中使用别名,那么在查询数据时就会产生报错。如下:

查询语文成绩大于80分并且不姓孙的同学
select name,chinese from exam_result where chinese>80 and name not like '孙%';

查询孙某同学,否则要求总成绩大于200分并且语文成绩小于数学成绩并且英语成绩大于80分。
mysql> select name,chinese,math,english, chinese+math+english 总分 from exam_result
-> where (name like '孙_') or (chinese+math+english>200 and chinese<math and english>80);

💕 NULL的查询
这里用之前的学成表来演示NULL查询,学生表中的内容如下:

查询QQ号已知的同学
select name,qq from students where qq is not null;

查询QQ号未知的同学
select name,qq from students where qq<=>null;

需要注意的是,在与NULL值作比较的时候应该使用<==>运算符,使用=运算符无法得到正确的查询结果。

因为=运算符是NULL不安全的,使用=运算符将任何值与NULL作比较,得到的结果都是NULL。如下:
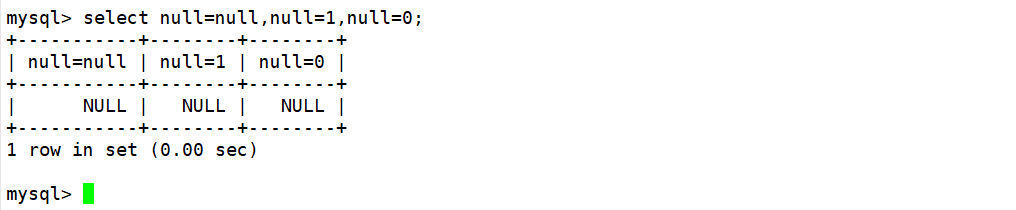
但是<=>运算符是NULL安全的,使用<=>运算符将NULL和NULL作比较得到的结果为TRUE(1),将非NULL值与NULL作比较得到的结果为FALSE(0)。如下:

结果排序
结果排序的SQL语句如下:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
说明一下:
- SQL中大写的表示关键字,[ ] 中代表的是可选项。
ASC和DESC分别代表的是排升序和排降序,默认为ASC。
注意: 如果查询SQL中没有order by子句,那么返回值的顺序是非定义的。
查询同学及其数学成绩,按数学成绩升序显示
select name,math from exam_result order by math asc;

查询同学及其QQ号,按QQ号排序显示
在select 的 column列表中指明要查询的列为姓名和QQ号,在order by子句中指明按照QQ号进行升序排序。如下:
select name,qq from students order by qq asc;

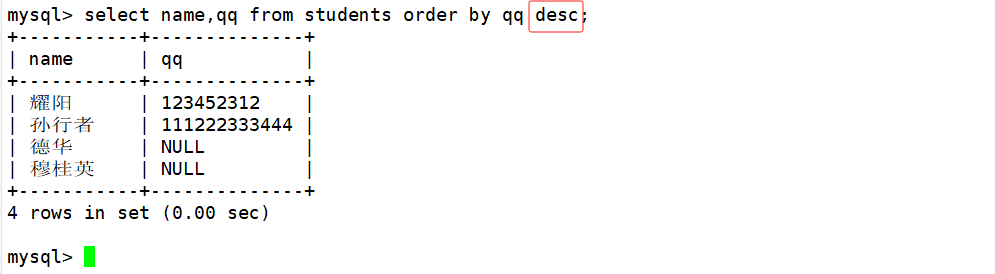
这里我们需要注意一下:NULL的值视为比任何值都小,因此拍升序时出现在最上面。
查询同学及其QQ号,按QQ号降序显示
select name,qq from students order by qq desc;
查询同学的各门成绩,依次按数学降序、英语升序、语文升序显示
select name,math,english,chinese from exam_result order by math desc,english asc,chinese asc;

最后我们可以看到显示结果是按照数学成绩进行降序排序的,而相同的数学成绩之间则是按照英语成绩进行升序排序的。
- order by子句中可以指明按照多个字段进行排序,每个字段都可以指明按照升序或降序进行排序,各个字段之间使用逗号隔开,排序优先级与书写顺序相同。
- 比如上述SQL中,当两条记录的数学成绩相同时就会按照英语成绩进行排序,如果这两条记录的英语成绩也相同就会继续按照语文成绩进行排序,以此类推。
查询同学及其总分,按总分降序显示
select name,chinese+math+english 总分 from exam_result order by chinese+math+english desc;

在order by子句中可以使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录。
- 然后再将符合条件的记录作为数据源来依次执行select语句。
- 最后再通过order by子句对select语句的执行结果进行排序。
也就是说,order by子句的执行是在select语句之后的,所以在order by子句中可以使用别名。如下:
select name,chinese+math+english 总分 from exam_result order by 总分 desc;
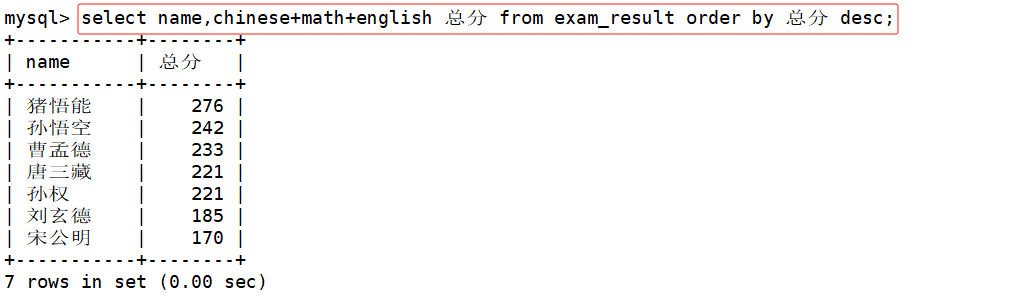
姓孙的同学或姓曹的同学及其数学成绩,按数学成绩降序显示
对于这种题目比较长的题目,我们可以先对题目进行分析。
- 题目的前半句描述的是查询,后半句描述的是排序。
- 在排序的时候必须要有数据,因此可以先完成前面的查询动作,然后再根据题目要求进行排序。
select name,math from exam_result where name like '孙%' or name like '曹%';
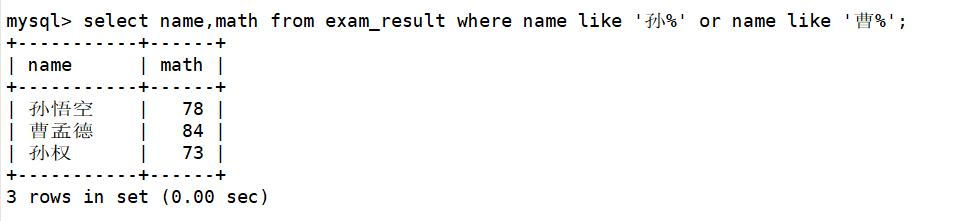
当查询到目标数据后再在查询SQL后添加order by 子句,在order by 子句中指明按照数学成绩进行降序排序。如下:
mysql> select name,math from exam_result where name like '孙%' or name like '曹%'
-> order by math desc;
筛选分页结果
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- 查询SQL中各语句的执行顺序为:
where、select、order by、limit。 - limit子句在筛选记录时,记录的下标从0开始。
建议: 对未知表进行查询时最好在查询SQL后加上 limit 1,避免在查询全表数据时因为表中数据过大而导致数据库卡死。
按id进行分页,每页3条记录,分别显示第1、2、3页
这里使用成绩表中的数据来演示分页查询,成绩表中的内容如下:

查询第1页记录时在查询全表数据的SQL后,加上limit子句指明从第0条记录开始,向后筛选出3条记录。如下:
select * from exam_result limit 3 offset 0;

查询第2页记录时在查询全表数据的SQL后,加上limit子句指明从第3条记录开始,向后筛选3条记录。如下:
select * from exam_result limit 3 offset 3;

查询第3页记录时在查询全表数据的SQL后,加上limit子句指明从第6条记录开始,向后筛选3条记录。如下:
select * from exam_result limit 3 offset 6;

这里我们需要注意的是,如果表中筛选出来的数据不足n个,则筛选出来几个就显示几个。
Update
修改数据的SQL如下:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
说明一下:
- SQL中的column=expr,表示将记录中列名为column的值修改为expr。
- 在修改数据之前需要先找到待修改的记录,update语句中的where、order by和limit就是用来定位数据的。
将孙悟空同学的成绩修改为80分
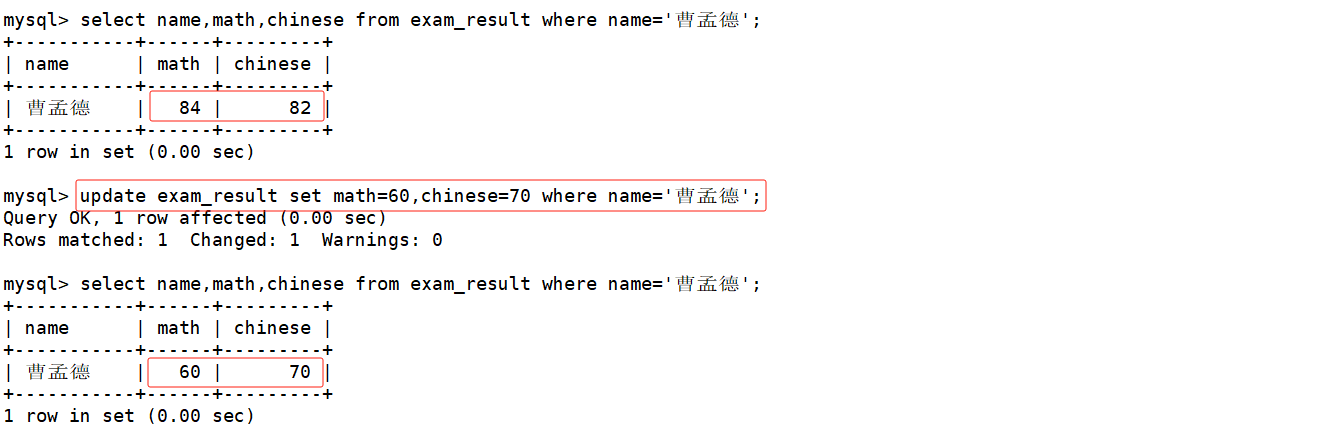
在修改数据之前,我们可以先查看一下孙悟空同学的成绩。如下:

在update语句之后指明要将筛选出来的记录的数学成绩改为80分,并在修改后再次查看数据确保数据成功被修改。如下:
update exam_result set math=80 where name='孙悟空';

将曹孟德同学的数学成绩修改为60分,语文成绩修改为70分
将总成绩倒数前三的3位同学的数学成绩加上30分
update exam_result set math=math+30 order by chinese+math+english asc limit 3;
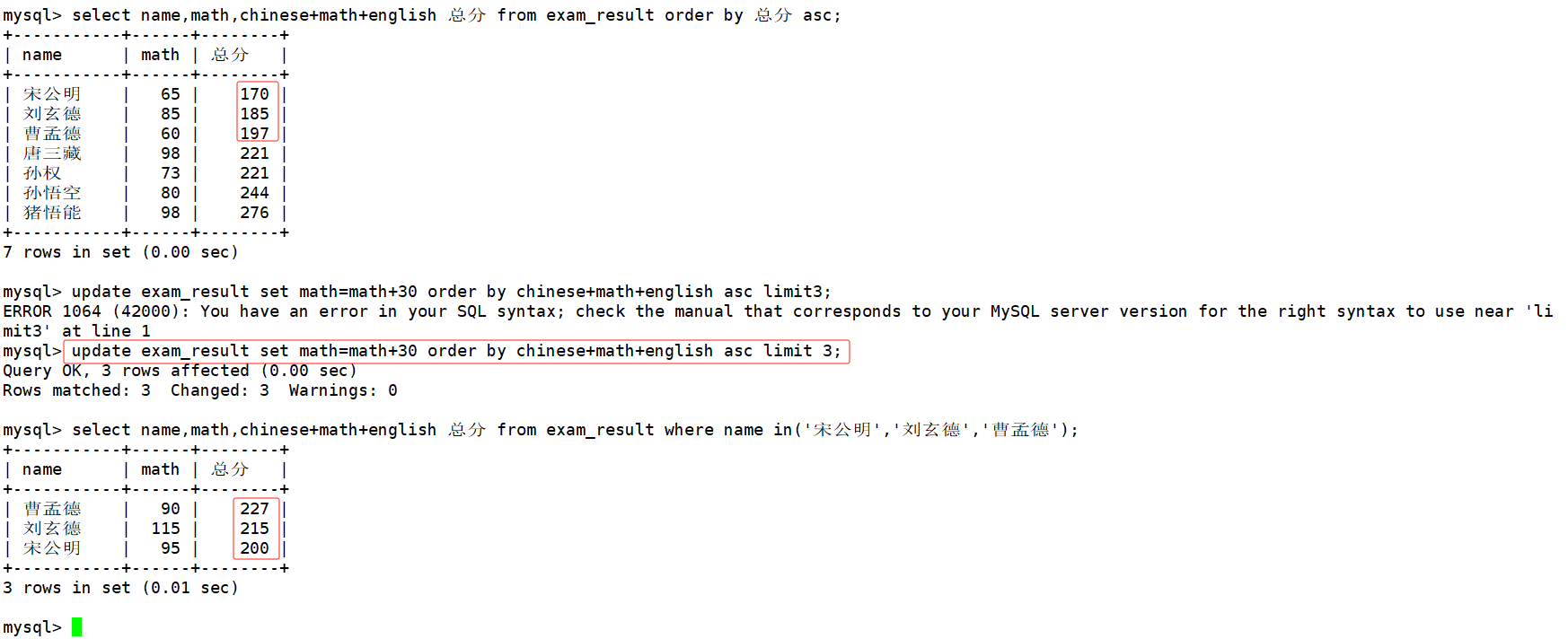
这里我们需要注意的是,MySQL中不支持 += 这种复合赋值运算符。
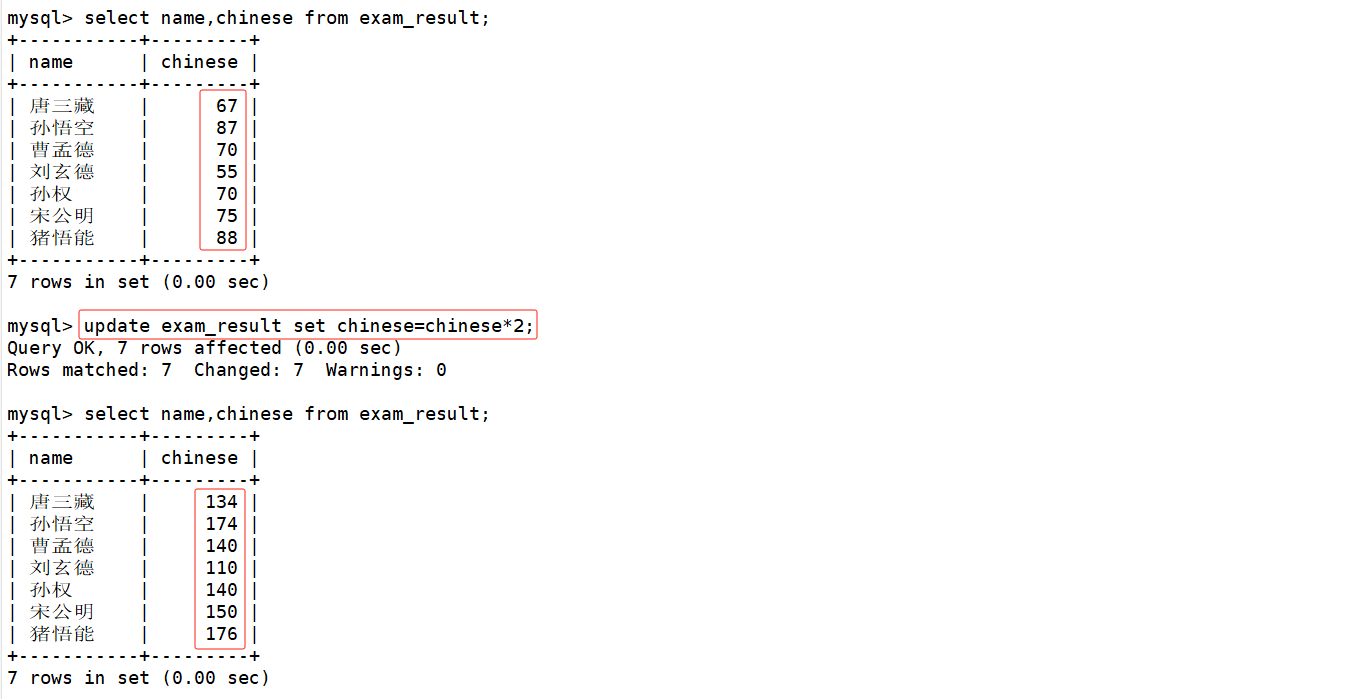
将所有同学的语文成绩修改为原来的2倍
update exam_result set chinese=chinese*2;
Delete
删除数据
删除数据的SQL如下:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
这里我们需要注意的是:在删除数据之前需要先找到待删除的记录,delete语句中的where、order by 和 limit 就是用来定位数据的。
删除孙悟空同学的考试成绩
delete from exam_result where name='孙悟空';

删除整张表数据
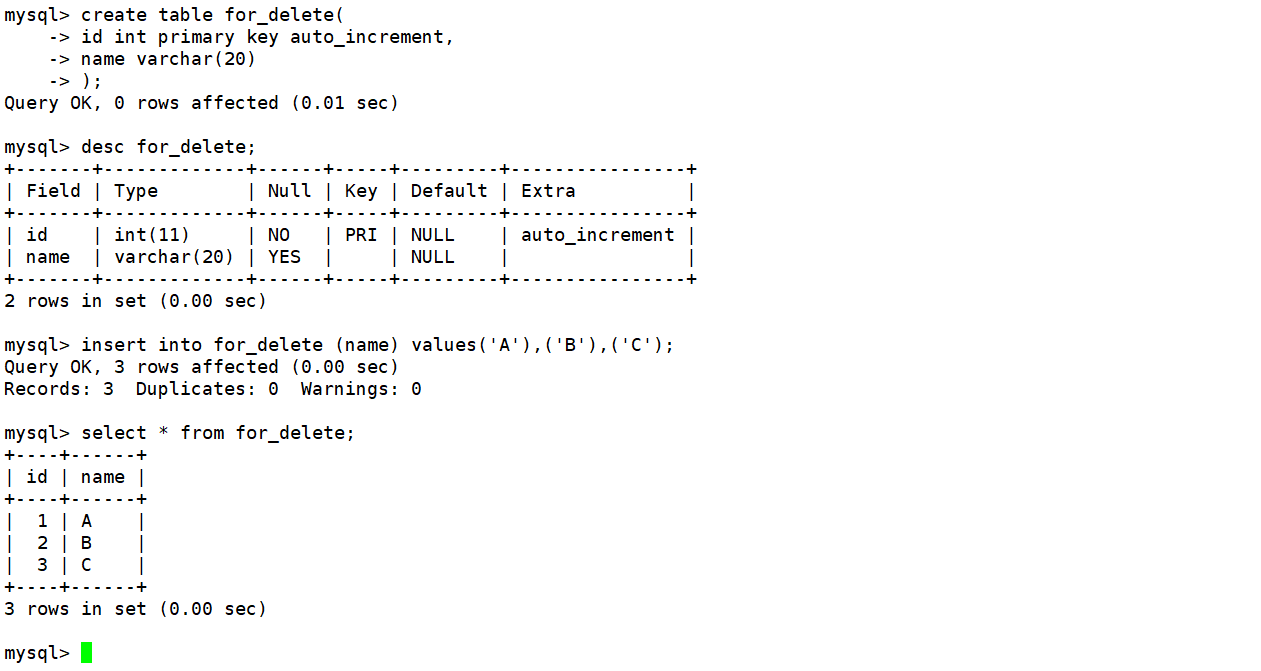
delete from for_delete;

当我们向表中再插入一些数据时,在插入数据时不指明自增长字段的值,这时你会发现插入数据对应的自增长id值是在之前的基础上继续增长的。如下:
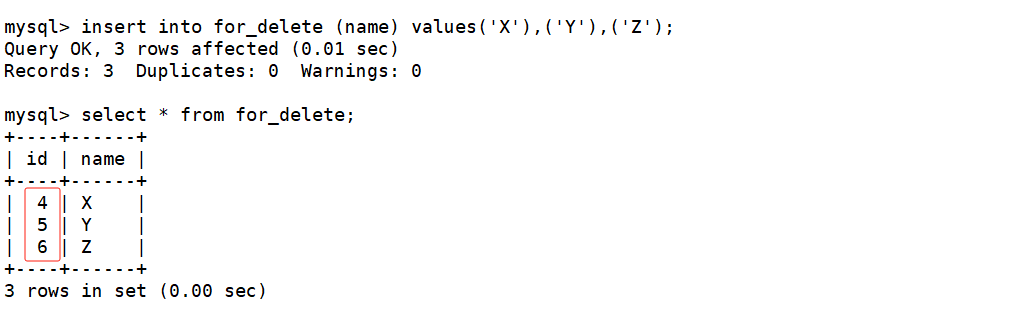
因此,当通过delete语句删除整张表数据时,不会重置AUTO_INCREMENT=n字段,因此删除整张表数据后插入数据对应的自增长id值会在原来的基础上继续增长。
截断表
截断表的SQL如下:
TRUNCATE [TABLE] table_name
- truncate只能对整表操作,不能像delete一样针对部分数据操作。
- truncate实际上不对数据操作,所以比delete更快。
- truncate在删除数据时不经过真正的事务,所以无法回滚。
- truncate会重置AUTO_INCREMENT=n字段。

insert into for_truncate (name) values('A'),('B'),('C');

truncate for_truncate;
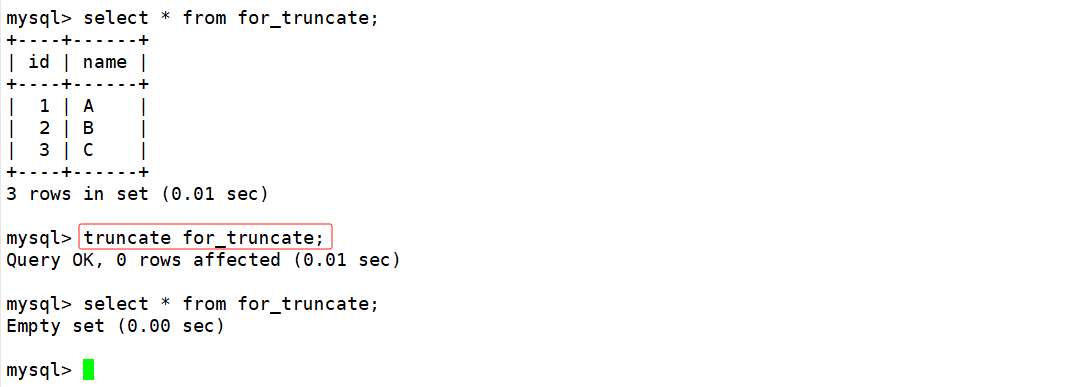
在truncate语句中只指明要删除数据的表名,这时便会删除整张表的数据,但由于truncate实际不对数据操作,因此执行truncate语句后看到影响行数为0。
再向表中插入一些数据,在插入数据时不指明自增长字段的值,这时会发现插入数据对应的自增长id值是重新从1开始增长的。
因此当通过truncate语句删除整张表数据时,会重置 AUTO_INCREMENT 字段, 因此截断表后插入数据对应的自增长id值会重新从1开始增长。
插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
- SQL的作用是将筛选出来的记录插入到指定的表当中。
- SQL中的column表示将筛选出的记录的各个列插入到表中的哪一列。
创建一张测试表并向其中插入一些重复数据。如下:
mysql> create table duplicate_table(
-> id int,
-> name varchar(20)
-> );
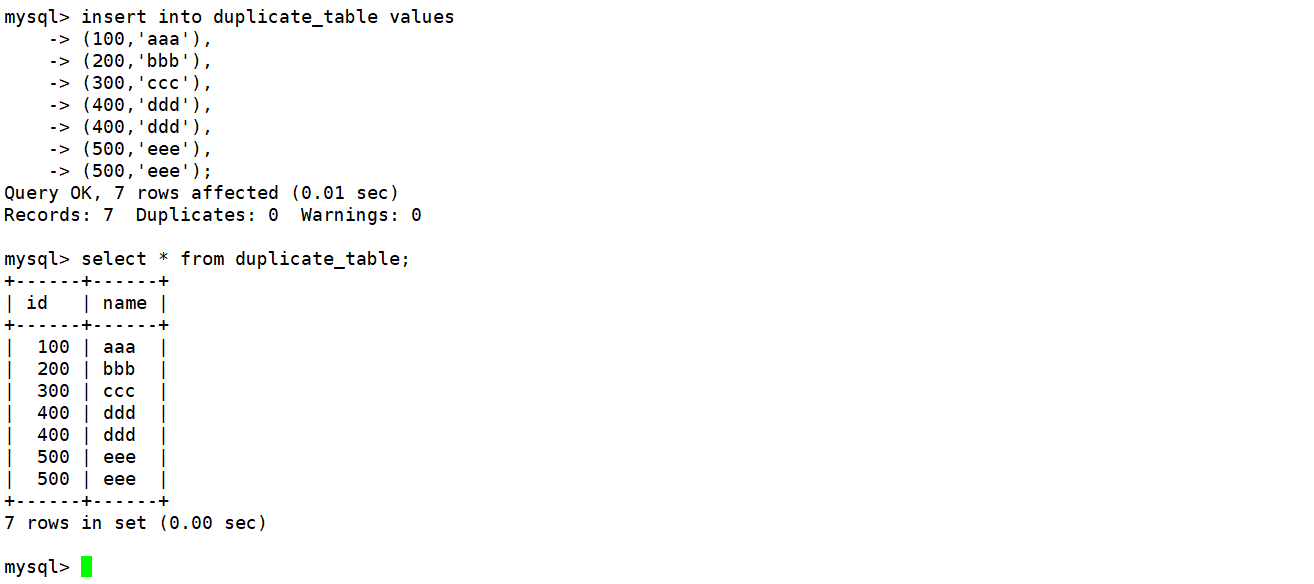
现在要求删除测试表中的重复数据,思路如下:
- 创建一张临时表,该表的结构与测试表的结构相同。
- 以去重的方式查询测试表中的数据,并将查询结果插入到临时表中。
- 将测试表重命名为其他名字,再将临时表重命名为测试表的名字,实现原子去重操作。
由于临时表与的结构与测试表相同,因此在创建临时表的时候可以借助like进行创建。如下:
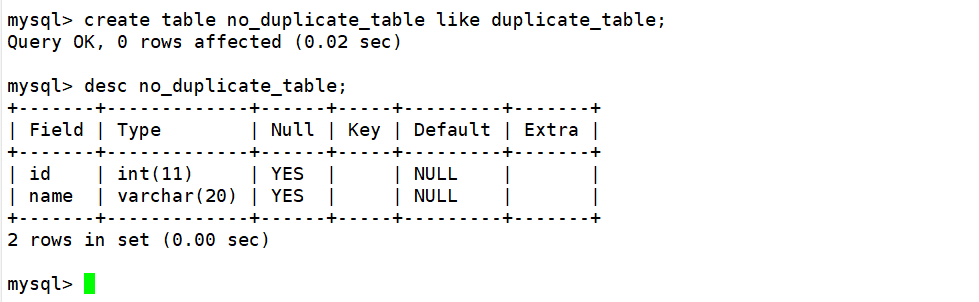
通过查询语句将去重查询后的结果插入到临时表中,由于临时表和测试表结构相同,并且select进行的是全列查询,因此在插入时不用再表明后指明column列表。如下:
insert into no_duplicate_table select distinct * from duplicate_table;

将测试表重命名为其他名字(相当于对去重前的数据进行备份,如果不需要可以直接删除),临时表重命名为测试表的名字,这是便完成了表中数据的去重操作。如下:
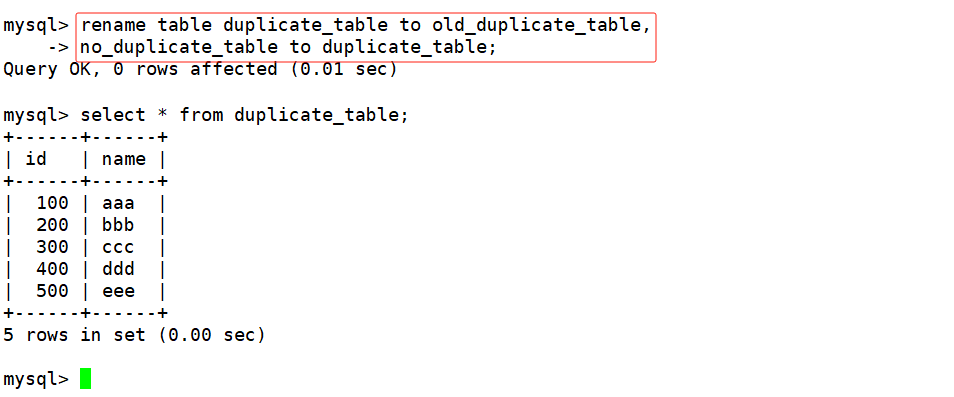
聚合函数
聚合函数是对一组值执行计算并返回单一的值,常用的聚合函数如下:
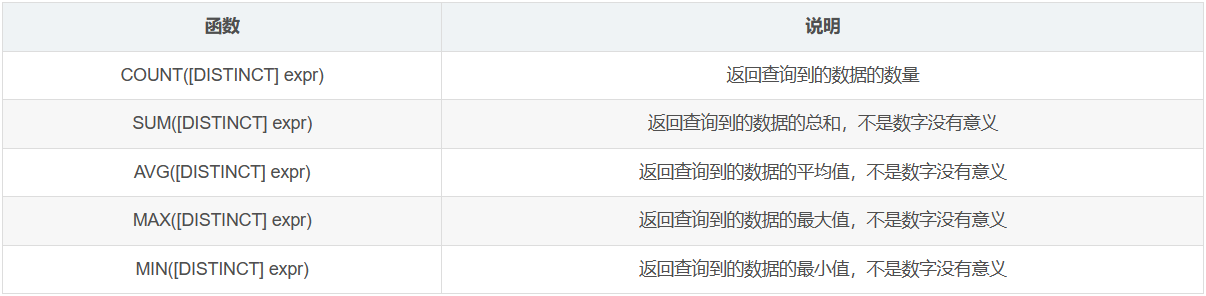
聚合函数可以在select语句中使用,此时select每处理一条记录时都会将对应的参数传递给这些聚合函数。
统计班级共有多少同学
在select语句中使用count函数,并将 * 作为参数传递给count函数,这时便能统计出表中的记录条数。如下:

当然,我们也可以使用表达式做统计,将表达式作为参数传递给count函数,这时也可以统计出表中的记录条数,如下:

统计班级收集的QQ号有多少个
mysql> select count(qq) from students;
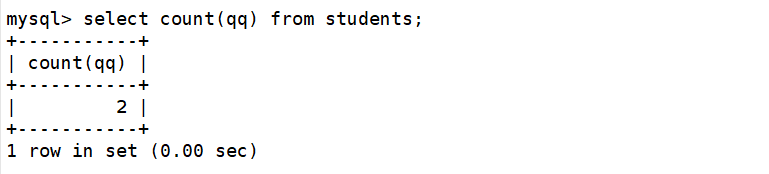
这里我们需要注意的是,如果count函数的参数是一个确定的列名,那么count函数将会忽略该列中的NULL值。
统计本次考试数学成绩的分数个数
select count(math) from exam_result;

统计本次考试数学成绩的分数个数(去重)
再使用count函数时(包括其他聚合函数),在传递的参数之前加上distinct,这时便能统计出表中数学成绩去重后的个数。如下:
select count(distinct math) from exam_result;

统计数学成绩总分
在select语句中使用sum函数统计math列中数据的总和,这时便能统计出表中数学成绩的总和。如下:
select sum(math) from exam_result;

统计不及格的数学成绩总分
在where子句中指明筛选条件为数学成绩小于60分,在select语句中使用sum函数统计math列中数据的总和。如下:
select sum(math) from exam_result where math<60;

统计平均总分
在select语句中使用avg函数计算总分的平均值。如下:
select avg(chinese+math+english) 平均总分 from exam_result;

返回英语最高分
在select语句中使用max函数来查询英语成绩最高分。如下:
select max(english) from exam_result;

返回70分以上的英语最低分
select min(english) from exam_result where english>70;

分组查询
SELECT column1 [, column2], ... FROM table_name [WHERE ...] GROUP BY column [, ...] [order by ...] [LIMIT ...];
说明一下:
- 查询SQL中各语句的执行顺序为:where、group by、select、order by、limit。
- group by后面的列名,表示按照指定列进行分组查询。
分组查询测试表 —— 雇员信息表
雇员信息表内容
雇员信息表中包含三张表,分别是员工表(emp)、部门表(dept)和工资等级表(salgrade)。
员工表(emp) 中包含如下字段:
- 雇员编号(empno)。
- 雇员姓名(ename)。
- 雇员职位(job)。
- 雇员领导编号(mgr)。
- 雇佣时间(hiredate)。
- 工资月薪(sal)。
- 奖金(comm)。
- 部门编号(deptno)。
部门表(dept) 中包含如下字段:
- 部门编号(deptno)。
- 部门名称(dname)。
- 部门所在地点(loc)。
工资等级表(salgrade) 中包含如下字段:
- 等级(grade)。
- 此等级最低工资(losal)。
- 此等级最高工资(hisal)。
雇员信息表SQL如下
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
进入该数据库,在该数据库中就可以看到雇员信息表中的三张表,如下:

部门表(dept) 的表结构和表中的内容如下:

员工表(emp) 的表结构和表中内容如下:
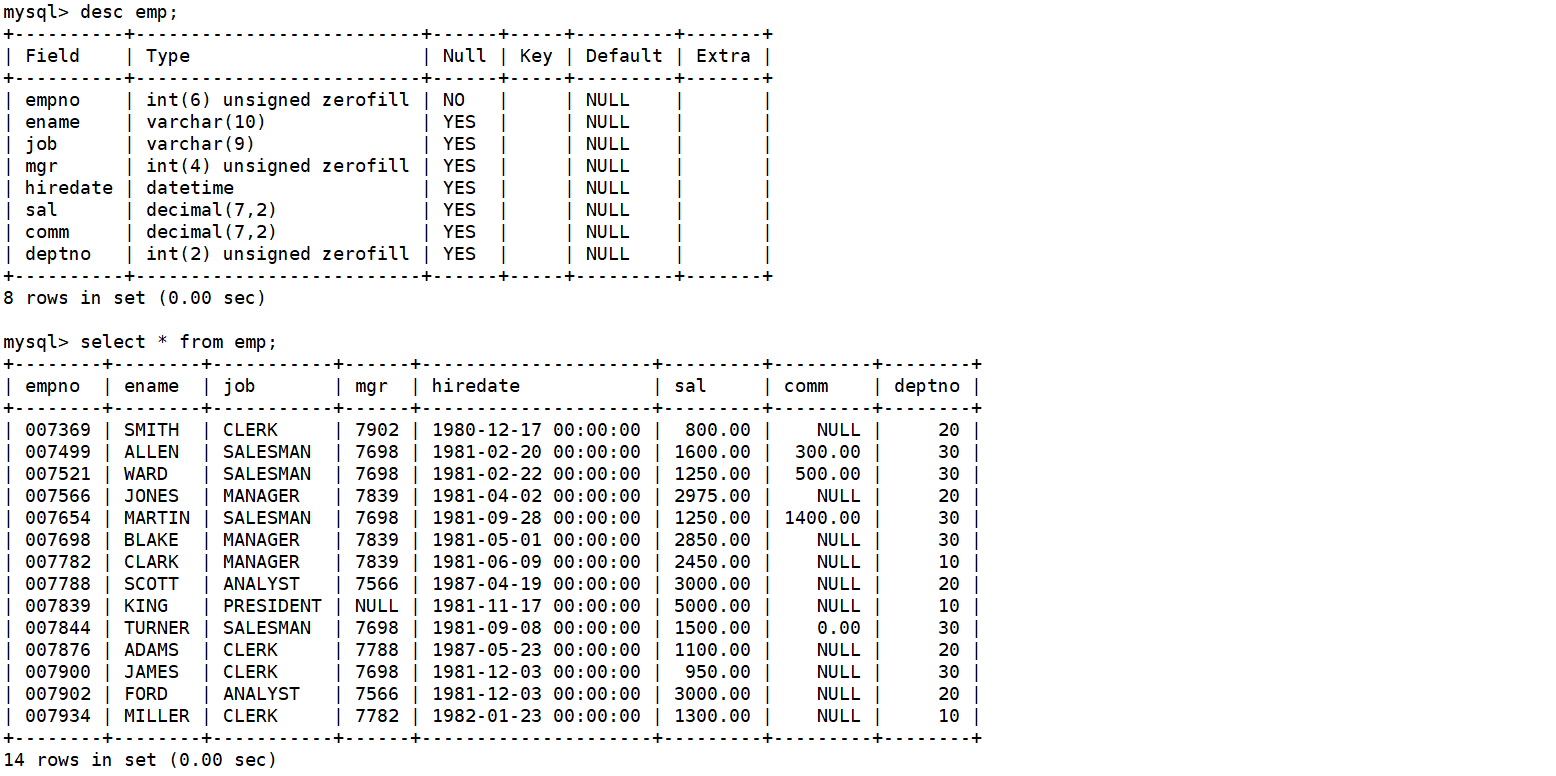
工资等级表(salgrade) 的表结构和表中的内容如下:

显示每个部门的平均工资和最高工资
group by 子句中指明按照部门号进行分组,在select语句中使用avg函数和max函数,分别查询每个部门的平均工资和最高工资。如下:
select deptno,avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno;

说明一下,上述SQL会将表中的数据按照部门号进行分组,然后各自在组内做聚合查询得到每个组的平均工资和最高工资。
显示每个部门的每种岗位的平均工资和最低工资
在group by子句中指明依次按照部门号和岗位进行分组,在select语句中使用avg函数和min函数,分别查询每个部门的每种岗位的平均工资和最低工资。如下:
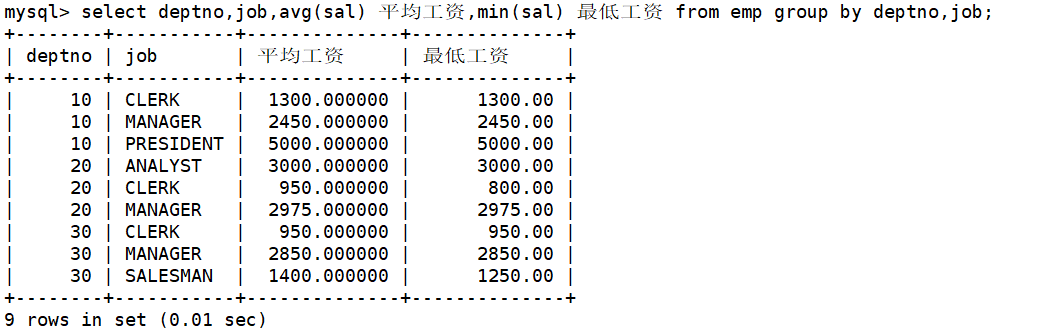
说明一下:
- group by子句中可以指明按照多个字段进行分组,各个字段之间使用逗号隔开,分组优先级与书写顺序相同。
- 比如上述SQL中,当两条记录的部门号相同时,将会继续按照岗位进行分组。
HAVING 条件
SELECT ... FROM table_name [WHERE ...] [GROUP BY ...] [HAVING ...] [order by ...] [LIMIT ...];
having子句中可以指明一个或多个筛选条件。
having和where子句的区别
- where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面。
- where子句是对整表的数据进行筛选,having子句是对分组后的数据进行筛选。
- where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名
SQL中各语句的执行顺序
查询数据时,SQL中各语句的执行顺序如下:
- 根据where子句筛选出符合条件的记录。
- 根据group by子句对数据进行分组。
- 将分组后的数据依次执行select语句。
- 根据having子句对分组后的数据进行进一步筛选。
- 根据order by子句对数据进行排序。
- 根据limit子句筛选若干条记录进行显示。
显示平均工资低于2000的部门和它的平均工资
先统计每个部门的平均工资。然后通过having子句筛选出平均工资低于2000的部门。
统计每个部门的平均工资
在group by子句中指明按照部门进行分组,在select语句中使用avg函数查询每个部门的平均工资。如下:
select deptno,avg(sal) 平均工资 from emp group by deptno;

显示平均工资低于2000的部门和它的平均工资
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!