ARM架构—— Cortex-M3与Cortex-M4特点概述
2024-01-08 16:48:53
一、Cortex-M3与Cortex-M4异同点
相同点:
- 基于ARM-v7-M架构。
- 三级流水线设计。
- 哈佛总线架构,统一的存储器空间:指令和地址总线使用相同的地址空间。
- 32位寻址,支持4GB 存储空间。
- 基于ARM AMBA(高级微控制器总线架构)技术的片上接口,支持高吞吐量的流水线总线操作。
- NVIC(嵌套向量中断控制器),最多支持240个中断请求和8~256个中断优先级(理论上支持,实际需芯片厂商设计)
- 具有支持多种OS(操作系统)特性,例如:节拍定时器和影子栈指针等。
- 支持休眠模式和多种低功耗模式。
- 支持可选MPU(存储器保护单元),具有存储器保护特性:可编程存储器或访问权限控制等。
- 可通过位段特性支持两个特定存储器区域中的位数据访问。
- 可选择使用单个或多个处理器。
- 具有多种指令:
- 普通数据处理,包括硬件除法指令。
- 存储器访问指令(8位,16位,32位)
- 位域处理指令
- 乘累加(MAC)以及饱和指令
- 跳转,条件跳转以及函数调用指令
- 系统控制、支持OS指令
不同点:
- Cortex-M4在DSP方面应用具有更高的性能。
- Cortex-M4支持浮点运算(单精度)。
- Cortex-M4支持单指令多数据(SIMD)操作。
- Cortex-M4支持快速MAC和乘法指令。
- Cortex-M4支持饱和运算指令。
二、特殊关键字解释
(1)哈弗结构介绍
????????哈佛结构是一种将程序指令存储和数据存储分开的存储器结构。哈佛结构是一种并行体系结构,它的主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问。
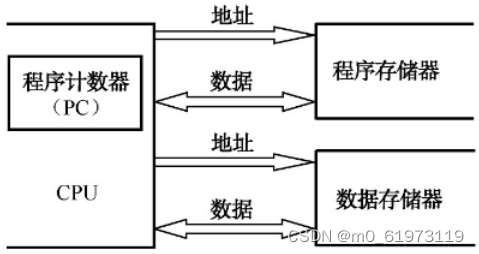
????????两个存储器相对应的是系统的4条总线,即程序的数据总线与地址总线、数据的数据总线与地址总线。这种分离的程序总线和数据总线可允许在一个机器周期内同时获得指令字(来自程序存储器)和操作数(来自数据存储器),从而提高了执行速度,进而提高了数据的吞吐率。
(2)浮点运算单元(FPU)
- Cortex-M4硬件支持单精度浮点运算,提供浮点运算指令集,单周期完成运算;
- Cortex-M4软件支持双精度浮点运算,使用C语言提供的Run-time Library函数,运算速度较慢,但是对于某些三角函数的运算又是必须的;
- Cortex-M4支持定点运算(不常用),数据的存储和运算与整型数类似(增加移位操作),运算速度较快,但是可表达的数值较少。
- Cortex-M4处理器具有硬件浮点单元(FPU),这意味着它可以直接执行浮点运算,包括加法、减法、乘法和除法等。这种硬件支持可以提高浮点运算的速度和效率,特别是对于需要大量浮点运算的应用程序而言。
- Cortex-M3处理器没有硬件浮点单元,因此无法直接执行浮点运算。不过,Cortex-M3处理器可以通过软件库来实现浮点数计算。软件库中包含了一系列的软件算法和函数,可以模拟浮点运算的过程,虽然这样的软件实现通常会比硬件支持的浮点运算慢一些。
(3)三级流水线
- MIPS——Million instruction Per Second 每秒多少百万条指令,比如0.9MIPS,每秒90万条指令。
- MIPS/MHz表示CPU在1MHz的运行速度下可以执行多少个MIPS,比如0.9MIPS/MHz表示如果CPU运行在1MHz的频率下,每秒可执行90万条指令.
- 这两个概念常用作描述ARM类的CPU执行速度,比如STM32F103ZET6的参数是1.25 DMips/MHZ,CPU的最高频率为72MHz,也就是说CPU满负荷运行时,速度为 72*1.25 = 90MIPS,也就是1秒可执行9000万条执行,非常非常快。

文章来源:https://blog.csdn.net/m0_61973119/article/details/135457269
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!