电商数仓项目----笔记六(数仓ODS层)
ODS层的设计要点如下:
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
(2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
同样的,需要将用户行为数据表和业务数据表放到ODS层。
日志表
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id
:STRING,source_type :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',
`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id
:STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms
:BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/';创建一个外部表(防止误操作):
common、page、actions、displays、start、err、ts?是表的列名;STRUCT?是一种复合数据类型,用于表示多个字段的组合。例如,common?列使用?STRUCT?类型,其中包含了多个字段;ARRAY?是一种用于表示数组的数据类型。例如,actions?和?displays?列使用?ARRAY?类型,分别包含了多个结构化的元素。PARTITIONED BY?指定了表的分区列,这里使用?dt?列作为分区列。ROW FORMAT SERDE?指定了数据的序列化和反序列化方式,这里使用?JsonSerDe。LOCATION?指定了外部表的存储位置
但是为什么创建这几个类? 因为当初咱们的日志格式是这样的:
页面日志:
{
"common": { -- 环境信息
"ar": "15", -- 省份ID
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1", -- 是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"sid": "3981c171-558a-437c-be10-da6d2553c517" -- 会话id
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [{ -- 动作(事件)
"action_id": "favor_add", -- 动作id
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"ts": 1585744376605 -- 动作时间戳
}
],
"displays": [{ -- 曝光
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, -- 出现顺序
"pos_id": 2 -- 曝光位置
"pos_seq": 1 -- 曝光序列号(同一坑位多个对象的编号)
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
"pos_seq": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
"pos_seq": 1
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
"pos_seq": 1
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
"pos_seq": 1
}
],
"page": { -- 页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页ID
"page_id": "good_detail", -- 页面ID
"from_pos_id":999, -- 来源坑位ID
"from_pos_seq":999, -- 来源坑位序列号
"refer_id":"2", -- 外部营销渠道ID
"sourceType": "promotion" -- 来源类型
},
"err": { --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}?JSON格式,最外层JSON对象的属性作为表的字段。重点是属性是什么类型?
????????第一个common对象,用map或者struct都行,因为个数确定,用struct更好;
????????第二个action,有中括号,用数组array<struct>因为里面的数组元素类型不统一ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> ;
? ? ? ? ?同理,第三个action也大同小异....
?
启动日志:
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"sid":"a1068e7a-e25b-45dc-9b9a-5a55ae83fc81"
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}? ? ? ?这些这里面common,ts什么都是一样的,只有start不一样,start也是结构体。
数据装载
load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' into table ods_log_inc partition(dt='2020-06-14');每日数据装载脚本
(1)在hadoop102的/home/atguigu/bin目录下创建hdfs_to_ods_log.sh
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log_inc partition(dt='$do_date');
"
hive -e "$sql"? ? ? ?这个脚本我们需要传入一个日期参数。首先,定义APP一个外部变量gmall,if [ -n "$1" ]是判定传入的第一个参数是否为空,如果不为空,则将传入的参数赋给do_date,否则,do_date赋为今天的日期减一天;
? ? ? ? 随后拼接sql语句,load data数据装载语句,inpath 后面跟着的是数据存放的路径,into后面跟着我们新创建的ODS层的表名;
? ? ? ? 拼接完sql语句,hive -e "$sql"相当于执行sql语句。Bash脚本特有的执行sql语句的语法。
业务表
????????这里表较多,全量和增量各取一张表做个简单说明:
????????活动信息表(全量表):
DROP TABLE IF EXISTS ods_activity_info_full;
CREATE EXTERNAL TABLE ods_activity_info_full
(
`id` STRING COMMENT '活动id',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_activity_info_full/';????????我们当时全量表数据的同步是靠DataX同步过来的,传输过来的是Tsv格式,我们要尽量保持格式不变。
????????这是当时的活动信息表的样式:
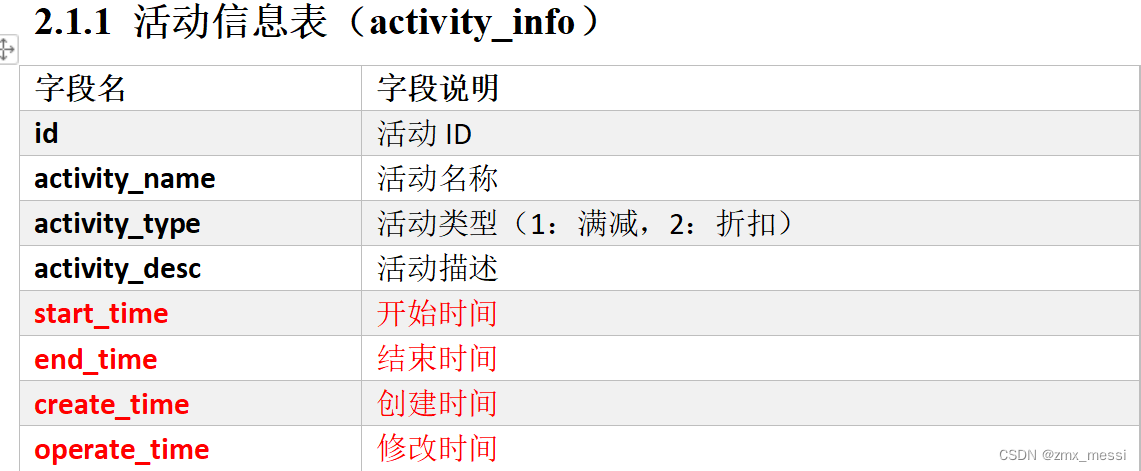
????????这段代码用于创建一个外部表?ods_activity_info_full。该表包含了多个列,其中每个列都有对应的数据类型和注释。
id、activity_name、activity_type、activity_desc、start_time、end_time、create_time?是表的列名。STRING?是表示字符串类型的数据类型。COMMENT?用于为列添加注释,描述列的含义。PARTITIONED BY?指定了表的分区列,这里使用?dt?列作为分区列。ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'?指定了行格式,数据以制表符分隔。NULL DEFINED AS ''?指定了空值的表示方式,这里将空值定义为空字符串。LOCATION?指定了外部表的存储位置。
?
?购物车表(增量表):
DROP TABLE IF EXISTS ods_cart_info_inc;
CREATE EXTERNAL TABLE ods_cart_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,user_id :STRING,sku_id :STRING,cart_price :DECIMAL(16, 2),sku_num :BIGINT,img_url :STRING,sku_name
:STRING,is_checked :STRING,create_time :STRING,operate_time :STRING,is_ordered :STRING,order_time
:STRING,source_type :STRING,source_id :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '购物车增量表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_cart_info_inc/';?????????我们当时全量表数据的同步是靠maxwell同步过来的,传输过来的是JSON格式。JSON:最外层JSON对象的属性作为表的字段。而且我们设计的表要考虑到下面三种不同的操作。但是里面的字段并不是全要的,比如database字段,对我们的统计分析没用,table也没用。Type有用,因为它可以帮我们区分三种不同的操作。xid和commit也用不上,因此我们分析比对只需要type,ts,date,old四个字段;
????????type:String,ts:timastamp,date:用结构体,old:map格式(不确定是几个)。

?这是当时的购物车表的样式:
在hadoop102的/home/atguigu/bin目录下创建hdfs_to_ods_db.sh
编写如下内容:
#!/bin/bash
APP=gmall
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
load_data(){
sql=""
for i in $*; do
#判断路径是否存在
hadoop fs -test -e /origin_data/$APP/db/${i:4}/$do_date
#路径存在方可装载数据
if [[ $? = 0 ]]; then
sql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"
fi
done
hive -e "$sql"
}
case $1 in
"ods_activity_info_full")
load_data "ods_activity_info_full"
;;
"ods_activity_rule_full")
load_data "ods_activity_rule_full"
;;
"ods_base_category1_full")
load_data "ods_base_category1_full"
;;
"ods_base_category2_full")
load_data "ods_base_category2_full"
;;
"ods_base_category3_full")
load_data "ods_base_category3_full"
;;
"ods_base_dic_full")
load_data "ods_base_dic_full"
;;
"ods_base_province_full")
load_data "ods_base_province_full"
;;
"ods_base_region_full")
load_data "ods_base_region_full"
;;
"ods_base_trademark_full")
load_data "ods_base_trademark_full"
;;
"ods_cart_info_full")
load_data "ods_cart_info_full"
;;
"ods_coupon_info_full")
load_data "ods_coupon_info_full"
;;
"ods_sku_attr_value_full")
load_data "ods_sku_attr_value_full"
;;
"ods_sku_info_full")
load_data "ods_sku_info_full"
;;
"ods_sku_sale_attr_value_full")
load_data "ods_sku_sale_attr_value_full"
;;
"ods_spu_info_full")
load_data "ods_spu_info_full"
;;
"ods_cart_info_inc")
load_data "ods_cart_info_inc"
;;
"ods_comment_info_inc")
load_data "ods_comment_info_inc"
;;
"ods_coupon_use_inc")
load_data "ods_coupon_use_inc"
;;
"ods_favor_info_inc")
load_data "ods_favor_info_inc"
;;
"ods_order_detail_inc")
load_data "ods_order_detail_inc"
;;
"ods_order_detail_activity_inc")
load_data "ods_order_detail_activity_inc"
;;
"ods_order_detail_coupon_inc")
load_data "ods_order_detail_coupon_inc"
;;
"ods_order_info_inc")
load_data "ods_order_info_inc"
;;
"ods_order_refund_info_inc")
load_data "ods_order_refund_info_inc"
;;
"ods_order_status_log_inc")
load_data "ods_order_status_log_inc"
;;
"ods_payment_info_inc")
load_data "ods_payment_info_inc"
;;
"ods_refund_payment_inc")
load_data "ods_refund_payment_inc"
;;
"ods_user_info_inc")
load_data "ods_user_info_inc"
;;
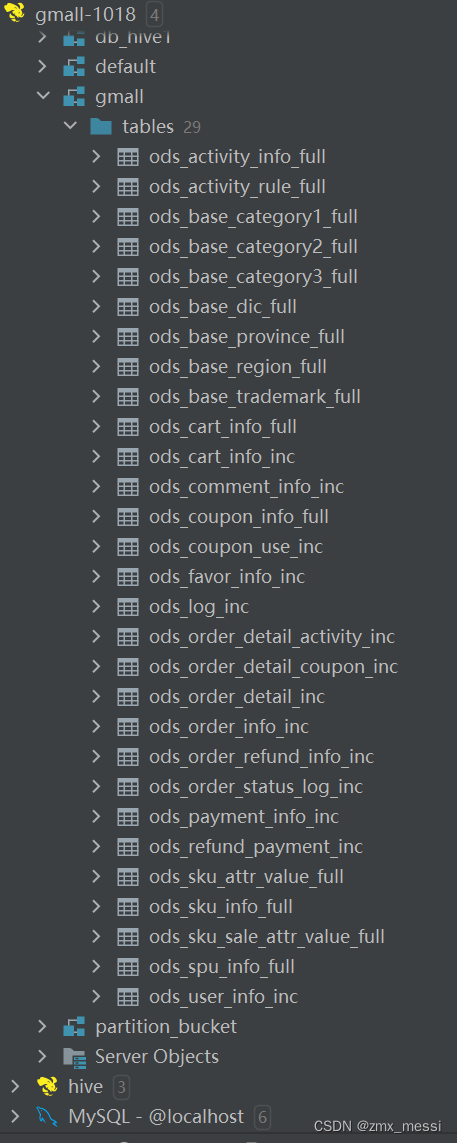
"all")
load_data "ods_activity_info_full" "ods_activity_rule_full" "ods_base_category1_full" "ods_base_category2_full" "ods_base_category3_full" "ods_base_dic_full" "ods_base_province_full" "ods_base_region_full" "ods_base_trademark_full" "ods_cart_info_full" "ods_coupon_info_full" "ods_sku_attr_value_full" "ods_sku_info_full" "ods_sku_sale_attr_value_full" "ods_spu_info_full" "ods_cart_info_inc" "ods_comment_info_inc" "ods_coupon_use_inc" "ods_favor_info_inc" "ods_order_detail_inc" "ods_order_detail_activity_inc" "ods_order_detail_coupon_inc" "ods_order_info_inc" "ods_order_refund_info_inc" "ods_order_status_log_inc" "ods_payment_info_inc" "ods_refund_payment_inc" "ods_user_info_inc"
;;
esac????????此脚本首先定义一个外部变量APP=gmall,随后再判断此脚本的第二个参数是否为空,如果是输入的日期就传入输入日期,如果没输入日期取当前日期的前一天。
? ? ? ? 后面定义了一个load_data函数,sql赋予一个空字符串,?for i in $*这行代码使用?for 循环遍历load_data函数的所有参数,其实就一个参数,也就是表名;
????????hadoop fs -test -e判断此路径是否存在,/origin_data/$APP/db/${i:4}/$do_date,${i:4}表示从传入的参数的第四个字符后开始读,比如这个"ods_activity_info_full",前面的ods跳过,后面的参数表示表名;
? ? ? ? 如果路径存在,? sql=$sql"load data inpath '/origin_data/$APP/db/${i:4}/$do_date' OVERWRITE into table ${APP}.$i partition(dt='$do_date');"数据装载;
? ? ? ? 数据装载之后如下所示:
????????
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!