北京通用人工智能研究院提出了首个三维世界中的具身多任务多模态的通才智能体 LEO
想要迈向通用人工智能,必须要构建一个能够理解人类生活的真实世界,并掌握丰富技能的具身通用智能体。
今年以来,以 GPT-4 (V)[1]、LLaVA [2]、PALM-E [3] 等为代表的多模态大语言模型(Multi-modal Large Language Model)在自然语言处理、视觉理解、机器人等任务上取得了显著的成功,但这类模型都是基于二维图片文本数据训练得到,在理解三维世界和与三维世界交互方面能力欠缺。
为解决这一问题,北京通用人工智能研究院联合北京大学、卡耐基梅隆大学和清华大学的研究人员提出了首个三维世界中的具身多任务多模态的通才智能体 LEO。
论文链接:https://arxiv.org/abs/2311.12871
项目主页:https://embodied-generalist.github.io/
代码链接:https://github.com/embodied-generalist/embodied-generalist
通才智能体 LEO 以大语言模型为基础,可以完成感知(perception)、定位(grounding)、推理(reasoning)、规划(planning)和动作执行(acting)等任务。
LEO 的三维视觉语言理解、具身推理和动作执行能力在现实世界中有广泛的应用场景与巨大的应用价值。作为未来的家庭助理,LEO 可以与人交互,回答与场景相关的问题,例如根据用户喜好调整家居布局、帮助用户找到特定物品、为用户的各种问题提供建议。LEO 的导航能力可用于购物中心、办公楼中的智能引导,其操控能力可用于家居自动化任务,如打扫、整理或简单厨房任务,以及仓库和物流中心的物品整理和搬运。
研究概述
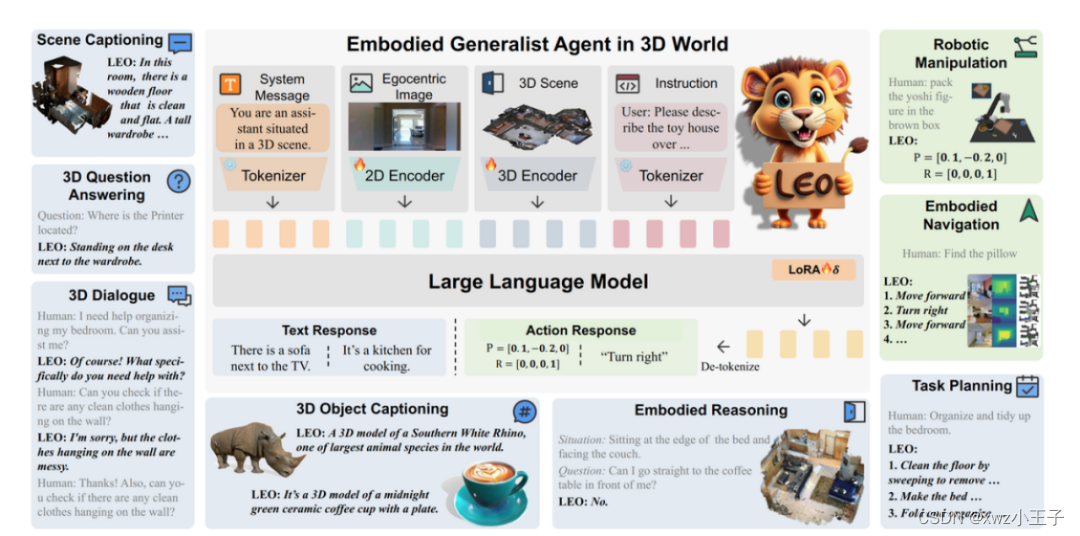
图 1. LEO 能力示意图
通才智能体 LEO 以 LLM 为基础,在不同任务之间采用共享的架构和权重,经由如下两个阶段训练得到:
1)三维视觉 - 语言对齐
2)视觉 - 语言 - 动作指令微调。
为完成上述两阶段的训练,作者收集并生成了包括物体级别(object-level)和场景级别(scene-level)的大规模数据集,并在问答(3D QA)、描述(3D captioning)、具身推理(embodied reasoning)、具身导航(embodied navigation)、机器人操作(robotic manipulation)多个任务上展示了 LEO 杰出的能力。
该工作的主要贡献可以总结如下:
1)构建了第一个能够在三维世界中进行感知、定位、推理、规划和动作执行的具身智能体 LEO。
2)提出了高效的学习策略,将以物体为中心(object-centric)的三维表征与 LLM 连接起来,同时加入具身动作任务,在三维世界中打通视觉 - 语言 - 动作(vision-language-action)。
3)提出了生成高质量三维视觉语言数据的方法,构建了视觉 - 语言 - 动作(vision-language-action)指令微调的大规模数据集。
模型介绍
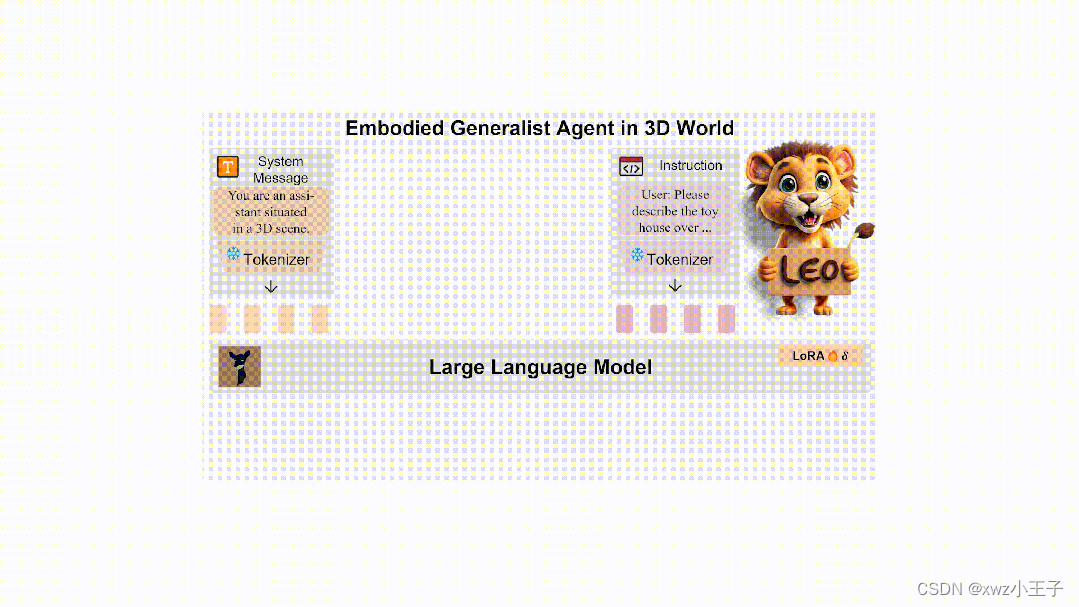
图 2. LEO 的通用任务序列和自回归式训练目标
LEO 模型的整体设计思想围绕两个核心点:
1)在统一的框架内处理第一视角的二维图片、三维场景信息和自然语言指令,并同时支持文本与动作的输出;
2)能够充分利用预训练语言模型的先验信息来促进下游任务。基于上述两个原则,作者设计了如图 2 所示的模型框架,将所有的多模态(2D、3D、text)输入都对齐到 LLM 的文本空间。
其中,作者利用 PointNet++ 提取出场景点云中物体级别的特征,随后用空间编码器(Spatial Transformer)对空间位置关系进行建模,从而得到三维场景级别(scene-level)的特征。输入中的二维图像则经过预训练模型 OpenCLIP ConvNext 处理得到第一视角的视觉特征。二维和三维的视觉特征最后分别经过 projector 映射到文本空间中。
具体过程如图 3 所示。
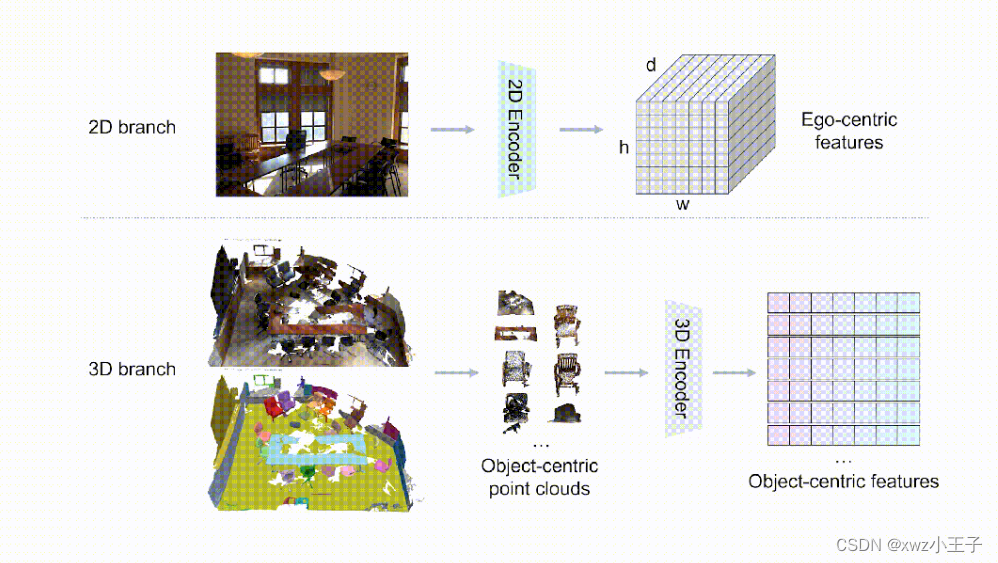
图 3. 图片和三维场景特征提取示意图
LLM 方面,作者采用 Vicuna-7B 作为预训练语言模型来处理 token 序列,训练中,利用 LoRA 方法来微调 LLM,训练目标如图 2 中所示。
数据集
数据集概况
根据两阶段的训练策略,作者分别收集了相应的数据,其整体概况如图 4 所示。数据集涵盖了大规模的三维物体数据,如 Objaverse,以及三维场景数据集,如 ScanNet、3RScan、Matterport3D 等,还包括了机器人操作相关的数据集 CLIPort,表 1 则给出了两阶段训练中所有数据的来源和数量统计。
图 4. LEO 数据集示意图

表 1. 数据集统计
LLM 辅助数据生成
为了解决当前三维场景视觉语言指令微调数据不足、现有的生成方法得到的数据质量不高的问题,作者提出了基于三维在场景图(scene graph)的数据生成方法,以及精炼过程(refinement procedures)来生成高质量的数据。具体过程如图 5 所示。
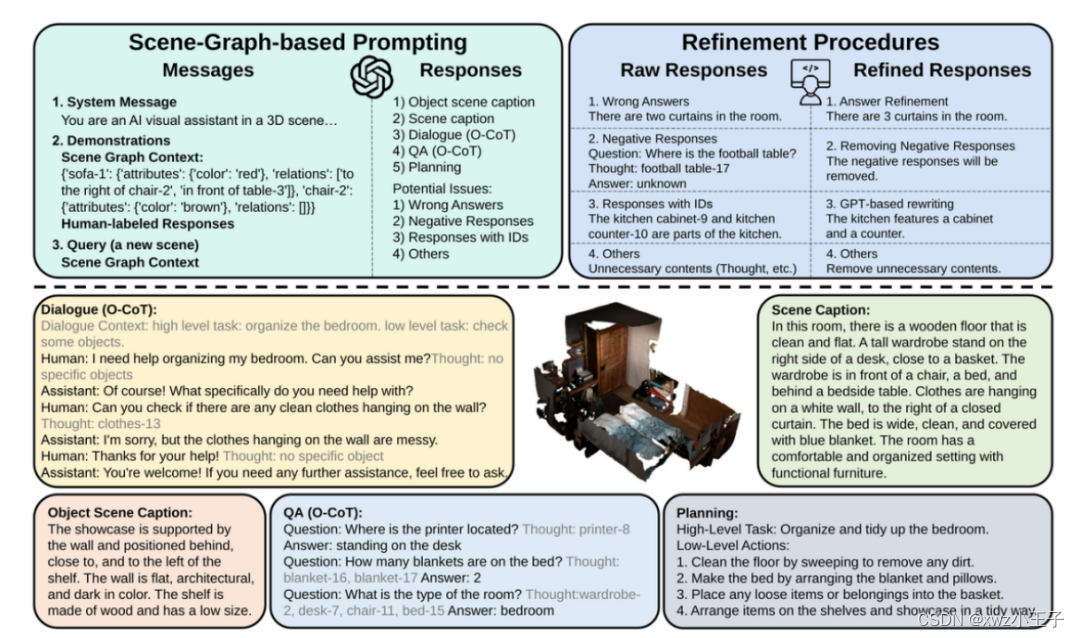
图 5. 基于 LLM 的三维视觉 - 语言指令微调数据生成
为了提高 LLM 生成数据的可靠性,作者提出了物体为中心的思维链(Object-centric Chain-Of-Thought)方法,提高生成回答和场景的关联,减少了输出中的幻觉(hallucination),并进一步通过精炼过程(Refinement Procedures)纠正生成数据中的错误。经过这一流程,最终得到了高质量的指令微调数据,更多关于数据集生成方法的细节和统计结果参见论文的附录部分。
模型能力
三维视觉语言理解和具身推理
视频 1. LEO 在 ScanQA, Scan2Cap, SQA 等任务上的表现
作者在三维场景问答数据集 ScanQA、三维物体描述数据集 Scan2Cap、三维场景具身推理数据集 SQA3D 上测试了模型的能力,这几类任务都以三维场景、自然语言指令为输入,其中 SQA3D 任务上还包括了提问时所处的位置和朝向,基于这些输入模型需要给出相应的回答,如上面的视频所示。
作者比较了之前各个数据集上的 SOTA 方法,如 3D-VisTA [4],3D-LLM [5],结果表 2 所示,实验结果表明 LEO 在三维视觉语言理解的任务上的多个指标明显优于之前的方法。
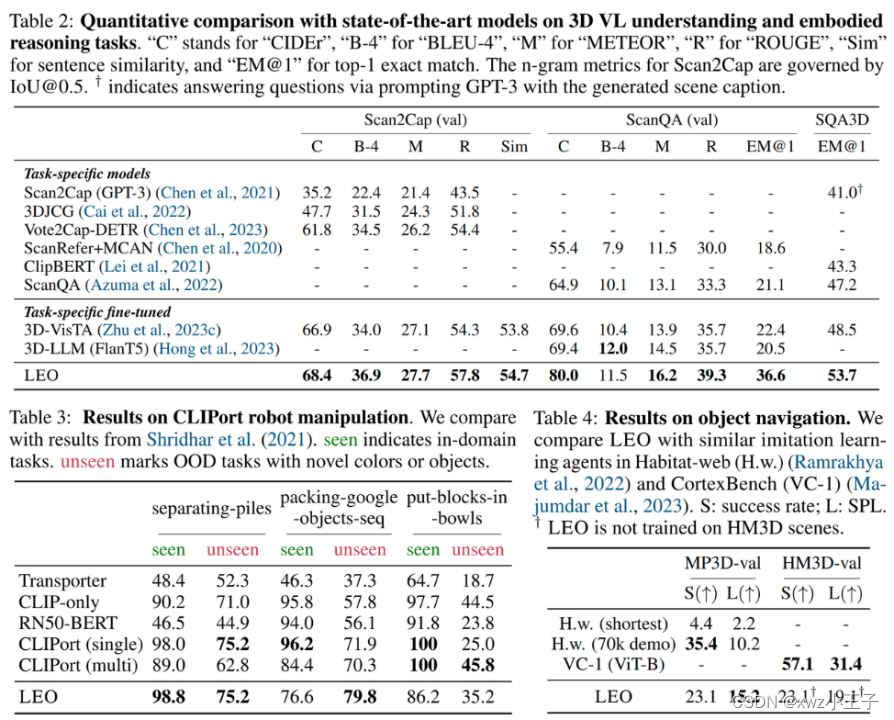
表 2 - 表 4. LEO 在三维视觉语言理解任务上的性能表现
三维世界中的具身动作执行
视频 2. LEO 在 manipulation 和 object navigation 任务上的表现
作者测试了 LEO 在机器人操作数据集 CLIPort 上的表现,该任务要求模型根据三维、二维感知结果和自然语言指令输出机械臂操作指令,如视频 2 所示。作者比较了 CLIPort 的基线方法 [6],结果如表 3 所示,证明了提出方法的优越性。另外,作者还测试了 LEO 在 MP3D(in domain)和 HM3D(out of distribution)这两个数据集上的表现,这一任务以三维场景、第一视角图片和自然语言指令作为输入,模型需要给出下一步的动作,如视频 3 所示。
论文与近期的相关工作 [7][8] 进行了比较,如表 4 所示。可以看出所提方法在学习最短路径数据下的表现可圈可点,在 SPL 指标上超越了先前的基准方法,而由于 LEO 的模型没有采用 recurrence 的结构,因此在学习 70k human demonstrations 的设定下表现出的能力有限。

图 6. LEO 的能力可视化
三维场景中的对话和规划
图 6 给出了 LEO 在多种任务中的可视化结果,可以看出,由于经过了指令微调训练的过程,LEO 可以进行多轮的场景对话,如按照用户需求在场景中寻找物体、按照不同的要求描述房间中的物体、给出建议等。还可以根据场景信息进行任务规划,如将房间整理为一个学习空间、打扫房间、重新装饰房间等,更多的例子可以在项目主页中进一步了解。
实验分析
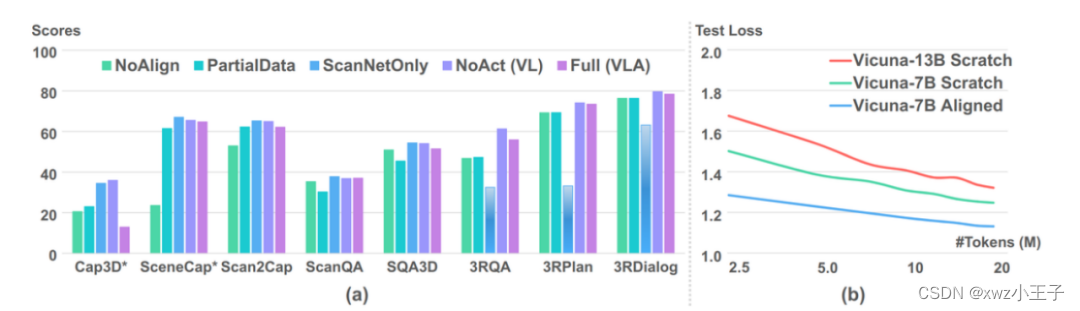
图 7. 消融实验结果
为了研究所提出的训练策略有效性,作者进行了不同数据集和训练阶段的多组对比实验。其中图 7-(a) 展示的是采用不同的训练数据得到的模型在多个任务上的表现,图 7-(b) 展示的是采用不同规模的 token 训练得到的模型对 test loss 的影响。
从实验可以得出如下结论:1)指令微调训练遵循 scaling law [9] 的规律。2)所提出的两阶段训练策略是重要的,对齐阶段的缺失会造成性能的明显下降。3)简单将模型参数规模从 7B 扩大至 13B 会造成性能的降低。
结论
本文提出的智能体 LEO 将当前的 LLM 模型能力拓展到了三维世界以及动作执行任务上,这一工作为构建通用具身智能体迈出了重要的一步。
基于这一工作,作者认为未来可以在如下方面进一步进行探索:
1)通过大规模的场景 - 文本数据对提升三维视觉 - 语言定位能力;
2)填补视觉 - 语言能力和动作执行能力之间的差距;
3)探索具身通用智能体的对齐和安全问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!