R语言——数据操作(四)
目录
一、数据转换
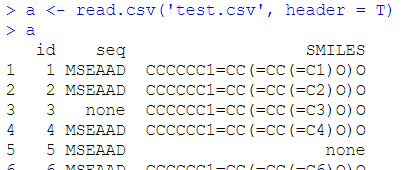
读取文件
a <- read.csv('test.csv', header = T)
判断读取的类型
class(a)
is.data.frame(a)
强制格式转换数据框格式
as.data.frame(a)
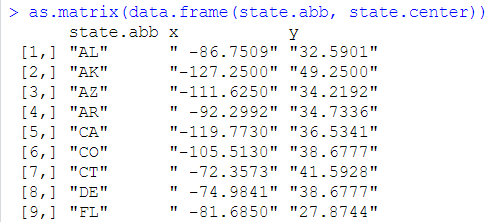
强制转换为矩阵格式,每个元素都为一个字符串
as.matrix(data.frame(a))


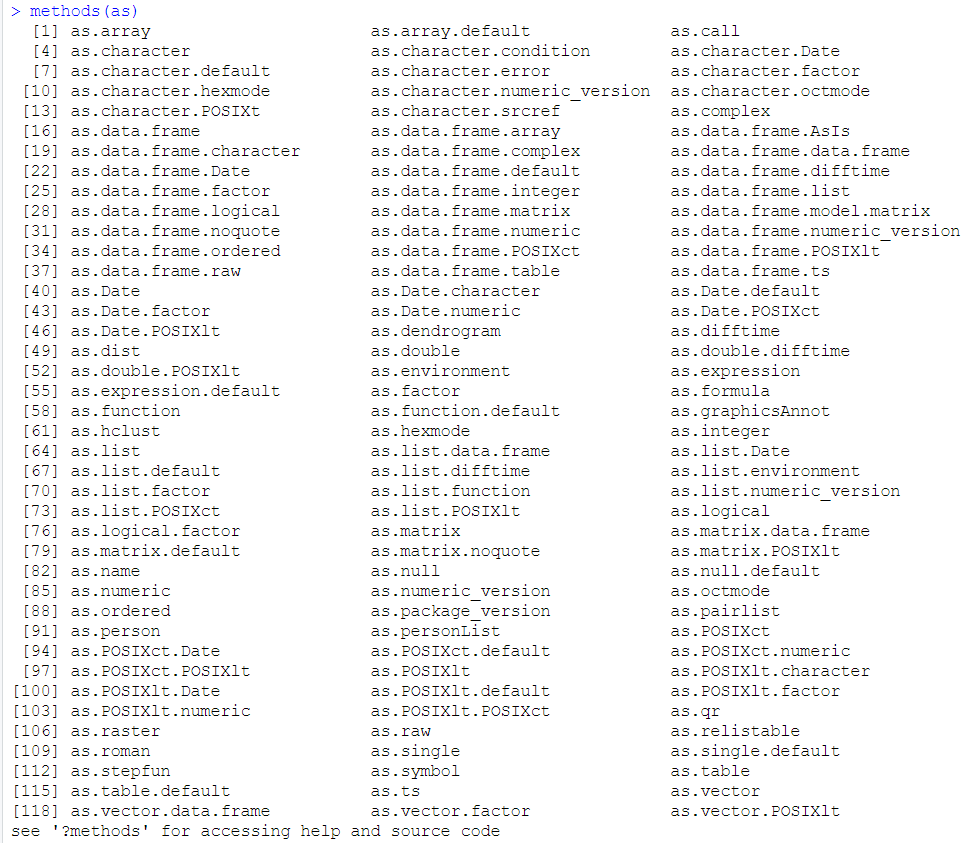
查看判断数据类型及格式转换方法
methods(is) 和 methods(as)

给向量添加一个维度就会变成矩阵或者数组

二、取子集
如何对数据框取子集
View(b)可以查看数据框
使用切片取连续子集
取不连续子集
使用 which 进行逻辑筛选
这里的? “? ,”是取行
subset() 可以对向量、矩阵、数据框取子集





sample(x, n) :无放回抽样, 每个元素只能抽取一次
设置replace = T,则是有放回抽样
对数据框进行抽样


数据框的合并
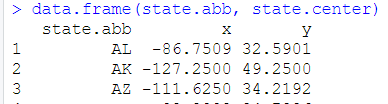
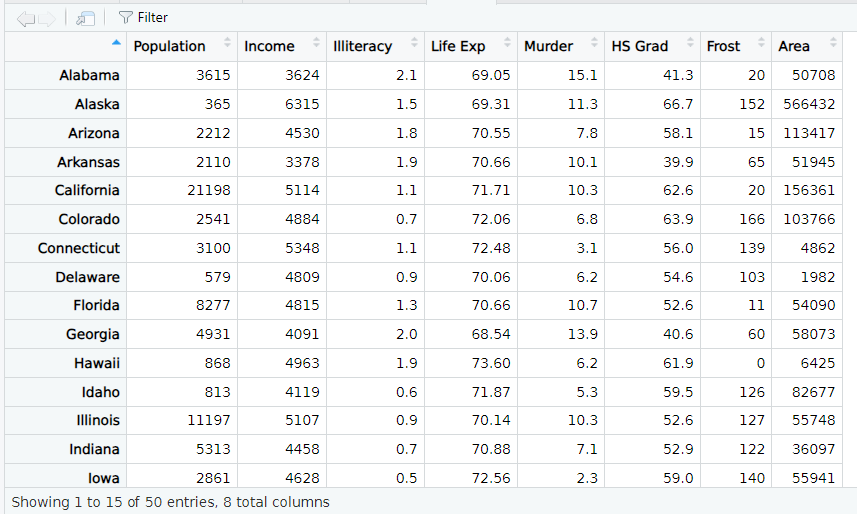
data.frame(state.abb, state.area)
cbind(state.abb,state.area):合并列
rbind(state.abb,state.area):合并行要求新数据与原数据具有相同的列名

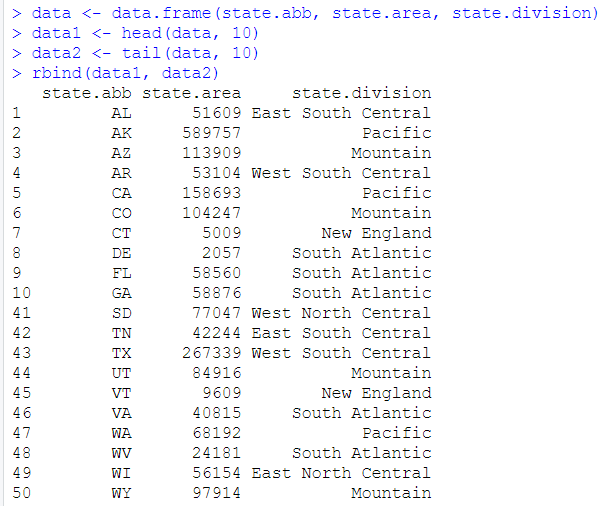
cbind,rbind也可以用于矩阵
要求是必须具有相同的行数或列数
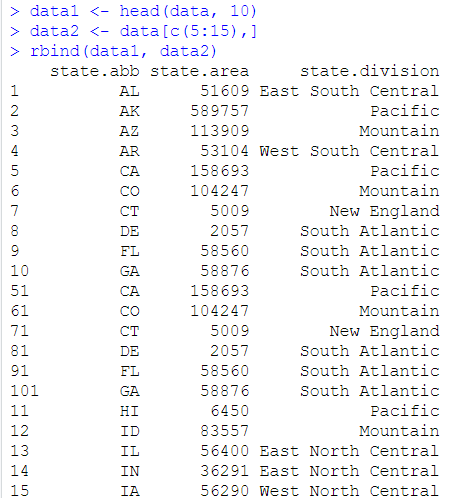
如果合并的数据有重复项应该怎么处理呢
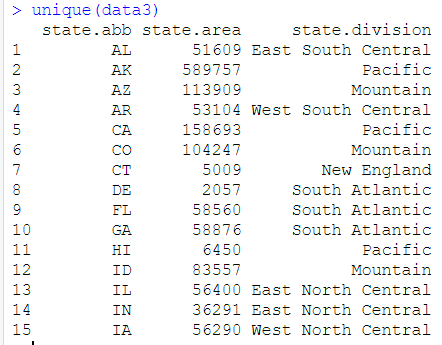
下图可以看到,51-101是重复项
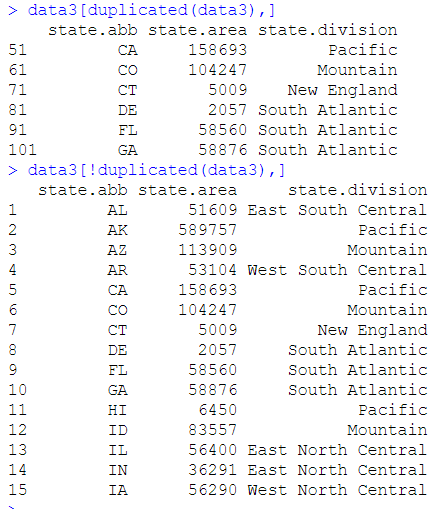
duplicated(data3):判断是否为重复项
可以取出重复项,加 “? !”可以取反
使用 unique() 可直接完成去重操作
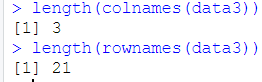
使用 length(rownames()) 和 length(colnames()) 可以查看行数和列数

三、数据框的翻转
t():数据框翻转
> data4<- t(data)
rev():反向


修改数据框中的值
transform(data, colname)
colname命名新的名字,则会生成新的一列


数据框排序
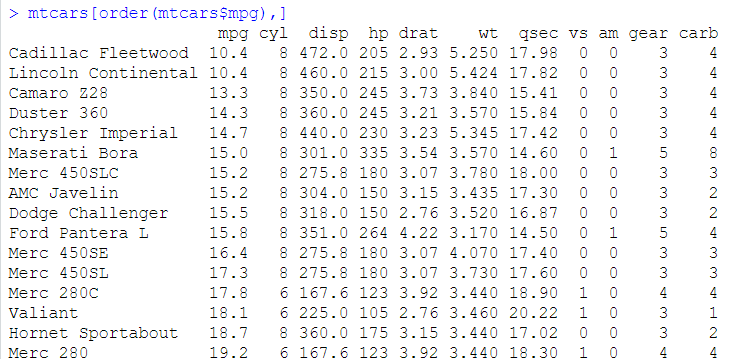
sort是对向量进行排序,返回排序后的结果

order也可以对向量进行排序,返回的是对应值所在的位置,而不是结果?
order可以根据索引对数据框进行排序
取与 order 默认相反的顺序
在变量前加一个 “ - ”


rank是求秩的函数
返回向量对应元素的排名
四、对数据框进行计算
将矩阵转为数据框
rowSums 计算行和
colMeans 计算列均值
将计算的行和 和 列均值添加到 原数据框 中
可以看到,cm 行 Total 列被第一列的值替代



五、apply的用法?

apply(x,MARGIN,FUN)
x是数组、矩阵或数据框;MARGIN等于1代表行,等于2代表列;FUN代表要应用的函数。
如:
apply(WorldPhones,MARGIN=1,FUN = sum)
apply(WorldPhones,MARGIN=2,FUN = mean)
apply(WorldPhones,MARGIN=2,FUN = Var)
apply(WorldPhones,MARGIN=2,FUN = log)

其他apply系列函数
lapply(x,FUN):l 代表list,x是列表,返回值是列表。
sapply(x,FUN):s代表simplify,x是列表,返回值是向量或者矩阵。
tapply(x,INDEX,FUN):x是向量或其他,INDEX是一组因子,利用这个因子,可以对第一个参数的数据进行分组。

六、数据的中心化与标准化?
数据中心化:是指数据集中的各项数据减去数据集的均值。
数据标准化:是指在中心化之后再除以数据集的标准差,即数据集中的各项数据减去数据集的均值再除以数据集的标准差。
简单来看:?
x <- c(1,2,3,6,3)
中心化:x-mean(x)
标准化:(x-mean(x))/sd(x)R中实现数据中心化和标准化可以使用scale函数:
scale(x,center,scale):center为TRUE就是做中心化处理,scale为TRUE就是做标准化处理。

七、参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!