探索数据的起点:Python中的statsmodels库简介
1 引言
在当今数据驱动的世界中,数据分析成为了解决问题和做出决策的关键步骤。为了更深入地了解和探索数据,我们需要强大而灵活的工具。其中,Statsmodels库是Python中一个不可或缺的工具,它为数据分析提供了丰富的统计模型和测试的功能。
1.1 数据分析基本概念
在开始探讨Statsmodels之前,让我们简要回顾一下数据分析的基本概念。数据分析是一项系统性的过程,旨在从大量数据中提取有意义的信息和洞察。这包括数据的收集、清理、转换和建模,以发现隐藏在数据背后的模式和规律。通过使用统计学、机器学习和可视化工具,数据分析师能够揭示数据之间的关系、趋势和变化,为决策制定提供支持。关键步骤包括描述性统计以总结数据特征,建立统计模型如线性回归进行预测,以及通过假设检验进行统计推断。
数据分析不仅适用于科学研究和学术领域,还在商业、医疗、社会科学等各个领域发挥关键作用,帮助人们更深刻地理解现象,做出明智的决策。这个过程不断演进,随着技术的进步和数据的不断增长,数据分析变得更加复杂和重要。
1.2 Statsmodels库的作用和重要性
Statsmodels库在Python中扮演着关键的角色,为数据分析提供了强大的统计建模和测试工具。其作用不仅限于描述性统计,还涵盖了多种统计模型,如线性回归和时间序列分析。
这个库的重要性体现在它能够帮助数据分析师更深入地理解数据背后的规律,通过生成详细的统计模型摘要和诊断图,使用户能够从数据中提取有意义的信息。Statsmodels的灵活性和丰富的功能,使其成为数据科学家和分析师们进行高级统计分析的不可或缺的工具,为数据驱动的决策提供了坚实的支持。
2 安装与导入Statsmodels
在开始使用Statsmodels之前,我们需要确保该库已成功安装,并将其导入到我们的Python环境中。
2.1 使用 pip 安装Statsmodels
要安装Statsmodels,您可以使用以下简单命令:
pip install statsmodels
2.2 导入Statsmodels模块
安装完成后,通过以下方式导入Statsmodels:
import statsmodels.api as sm
现在,我们已经准备好开始探索Statsmodels的功能了。
3 基础数据分析
Statsmodels提供了丰富的工具,可以进行基础的数据分析。
-
描述性统计分析:
describe():生成数据的描述性统计信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
-
方差分析(ANOVA):
anova_lm():进行方差分析,用于比较不同组之间的均值是否显著不同。
-
协方差分析(ANCOVA):
ols():进行协方差分析,用于比较组间均值是否显著不同,同时考虑一个或多个协变量。
-
统计检验:
ttest_ind():进行两组间的独立样本t检验。ttest_rel():进行两组相关样本t检验。
-
多元方差分析(MANOVA):
Manova():进行多元方差分析,适用于多个因变量。
-
卡方检验(Chi-squared Test):
contingency_tables():进行卡方检验,用于分析分类变量之间的关系。
-
独立性检验(Independence Test):
association_tests():用于执行独立性检验,例如卡方独立性检验。
-
正态性检验(Normality Test):
normaltest():用于检验数据是否服从正态分布。
-
相关性分析(Correlation Analysis):
pearsonr():计算Pearson相关系数,用于衡量两个变量之间的线性相关性。spearmanr():计算Spearman秩相关系数,用于衡量变量之间的单调相关性。
-
置信区间(Confidence Intervals):
DescrStatsW():用于计算均值的置信区间。
-
秩和检验(Rank Sum Test):
ranksums():用于比较两组独立样本的中位数是否相等。
这些功能覆盖了一系列基础性统计分析的需求,包括检验独立性、检验正态性、计算相关系数等。后续的文章中我会陆续介绍这些基础性分析的使用方法,这里只做一个简单的介绍,以描述性分析和绘制图表为例。
3.1 利用Statsmodels进行描述性统计分析
使用Statsmodels的describe()函数,我们可以轻松获取数据的描述性统计信息:
import pandas as pd
import numpy as np
import statsmodels.api as sm
# 构建模拟数据
np.random.seed(12)
data = {
'Height': np.random.normal(loc=170, scale=5, size=100),
'Weight': np.random.normal(loc=65, scale=8, size=100),
'Age': np.random.randint(20, 40, size=100)
}
df = pd.DataFrame(data)
# 使用Statsmodels进行描述性统计分析
summary = df.describe()
# 打印结果
print(summary)
运行上述代码后,结果如下:
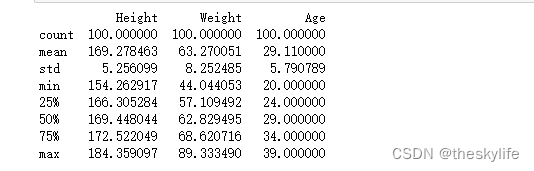
3.2 绘制基本的数据图表
Statsmodels结合了Matplotlib的功能,使得绘制数据图表变得非常简单。
3.2.1 绘制QQ图
例如,使用sm.qqplot()函数,采用3.1的数据,绘制QQ图:
import matplotlib.pyplot as plt
import statsmodels.api as sm
import statsmodels.graphics.api as smg
# 绘制图形
fig, ax = plt.subplots()
smg.qqplot(data['Weight'], fit=True, line='45', ax=ax)
plt.show()
运行上述结果后,截图如下:
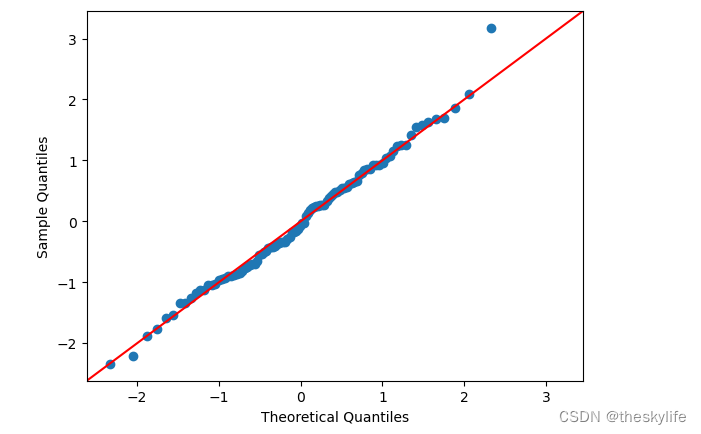
3.2.2 绘制散点矩阵图
这里继续采用3.1的数据进行绘制:
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 使用 pd.plotting.scatter_matrix 进行散点图矩阵
pd.plotting.scatter_matrix(df[['Height', 'Weight', 'Age']], figsize=(10, 8))
plt.show()
绘制图像后如下:
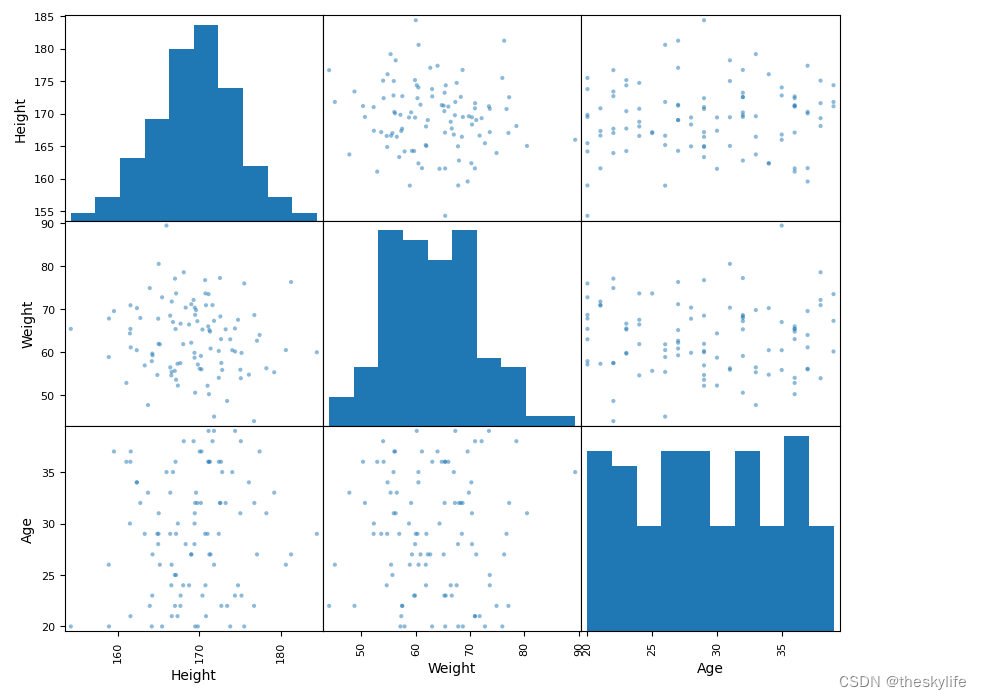
3.2.3 绘制残差和回归拟合图
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.graphics.regressionplots as smg
from statsmodels.graphics.regressionplots import plot_regress_exog
import matplotlib.pyplot as plt
# 假设你要拟合一个简单的线性回归模型
X = sm.add_constant(df['Height'])
y = df['Weight']
model = sm.OLS(y, X).fit()
# 绘制图像
fig, ax = plt.subplots(figsize=(10, 6))
plot_regress_exog(model, 'Height', fig=fig)
plt.show()
运行上述代码后,可以得到下面的图形:
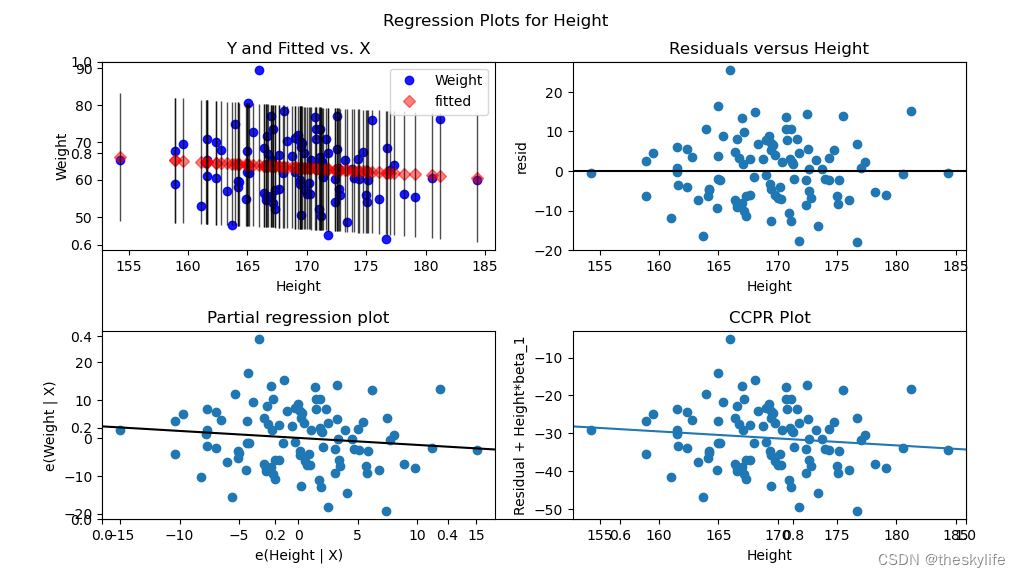
plot_regress_exog生成了包括四个子图的图形,分别是:
-
回归拟合图(Fitted values vs. Observed):
这个图显示了观测到的因变量值(实际体重)与模型预测的因变量值(拟合值)之间的关系。理想情况下,点应该沿着45度线分布,表示拟合值与实际值的一致性。 -
残差图(Residuals versus Height):
这个图显示了模型的残差(实际值与拟合值之差)与身高之间的关系。残差图用于检查模型的假设,理想情况下,残差应该随机分布在0附近。 -
Q-Q图(Quantile-Quantile Plot):
这个图用于检查残差是否符合正态分布。点在45度线上表示残差服从正态分布。 -
标准化残差图(Standardized Residuals vs. Fitted Values):
这个图显示了标准化残差(残差除以其标准差)与拟合值之间的关系。用于检查残差的异方差性(残差的方差是否与预测变量有关)。
通过观察这些图,可以评估回归模型的拟合效果、检查残差的分布和模型假设是否得到满足。
4 示例:线性回归分析
线性回归是数据分析中常用的一种方法,Statsmodels提供了简便而强大的工具进行线性回归分析。
假设我们有一组房屋数据,包括房屋的面积(SquareFeet)、卧室数量(Bedrooms)、以及售价(Price)。我们想要建立一个线性回归模型,通过房屋的面积和卧室数量来预测售价。以下是使用statsmodels库建立线性回归的例子:
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 生成模拟数据
np.random.seed(12)
square_feet = np.random.randint(800, 2500, 50)
price = 150000 + 300 * square_feet + np.random.normal(0, 50000, 50)
# 创建数据框
df = pd.DataFrame({'SquareFeet': square_feet, 'Price': price})
# 添加常数列
X = sm.add_constant(df['SquareFeet'])
# 拟合线性回归模型
model = sm.OLS(df['Price'], X).fit()
# 打印模型摘要
print(model.summary())
# 绘制拟合结果
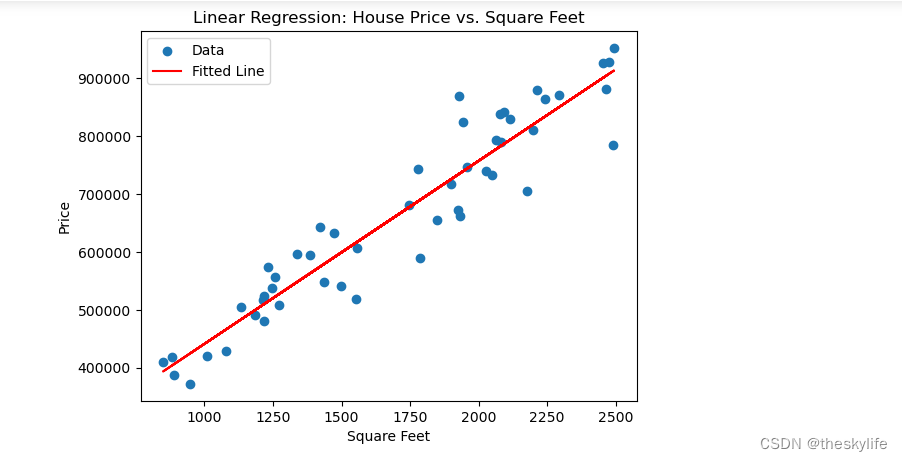
plt.scatter(df['SquareFeet'], df['Price'], label='Data')
plt.plot(df['SquareFeet'], model.predict(X), color='red', label='Fitted Line')
plt.xlabel('Square Feet')
plt.ylabel('Price')
plt.title('Linear Regression: House Price vs. Square Feet')
plt.legend()
plt.show()
运行上述代码后,输出结果如下:
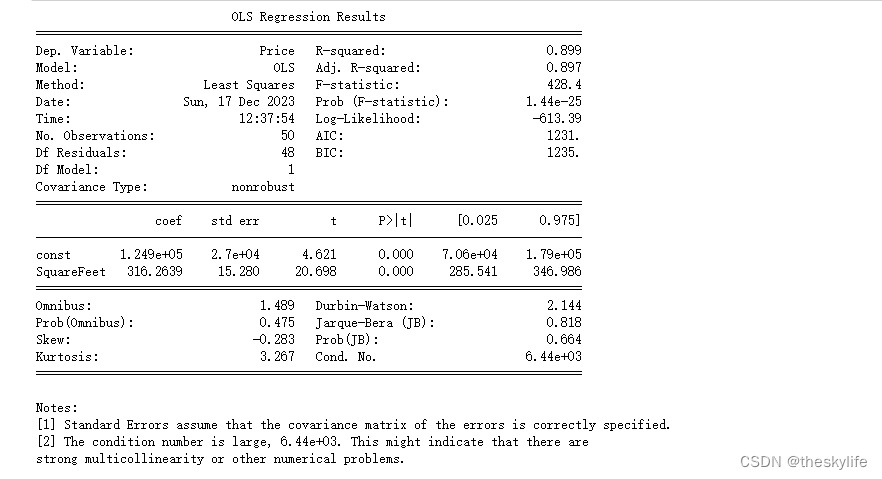
根据输出信息,让我们逐项评价这个简单线性回归模型的拟合效果:
-
R-squared 和 Adj. R-squared:
- R-squared为0.899,说明模型可以解释因变量(Price)89.9%的变异,这是一个相对较高的值,表明模型对数据的拟合效果较好。
- Adj. R-squared为0.897,考虑了模型中只有一个自变量,因此与R-squared值非常接近。
-
F-statistic 和 Prob (F-statistic):
- F-statistic为428.4,而Prob (F-statistic)非常接近零(1.44e-25),表示模型整体上是显著的,说明SquareFeet对Price的解释是显著的。
-
系数(coef)和其显著性(P>|t|):
- const(截距)的系数为1.249e+05,SquareFeet(房屋面积)的系数为316.2639。
- P>|t|的值都远小于通常的显著性水平(通常为0.05),表明这两个系数都是显著的。
-
残差统计和正态性检验:
- Omnibus和Jarque-Bera统计量的P值都相对较大,表明残差可能符合正态分布。
- Skew接近零,说明残差分布相对对称。
-
Durbin-Watson 统计量:
- Durbin-Watson为2.144,接近2,表明残差可能没有显著的自相关性。
-
条件数(Cond. No.):
- 条件数为6.44e+03,较大,可能表示自变量之间存在强烈的多重共线性。由于我们是单变量情况下进行建模的,因此此处不太相关,但如果是多元线性回归的话,要非常注意。
总体评价:
模型的R-squared、F-statistic以及系数的显著性均表明该模型在解释因变量方面效果较好。残差统计和正态性检验结果也表明残差相对符合正态分布。Durbin-Watson统计量表明残差可能没有显著的自相关性。
建议:
- 由于是单变量线性回归,无法通过变量选择来优化模型。然而,可以考虑添加更多自变量来提高模型的解释力,但需要注意多重共线性的问题。
- 尽管条件数较大,但在单变量情况下多重共线性通常不是主要问题,因此可能可以接受。然而,如果要添加更多自变量,就需要更仔细地考虑多重共线性的问题。
综合来看,这个简单线性回归模型已经相对有效,但如果希望提高解释力或者更深入地分析数据,可以考虑添加更多的自变量并进一步优化模型。
写在最后
通过本文的介绍,我们初步了解了Statsmodels库的使用方法和基本功能。从描述性统计分析到线性回归分析,Statsmodels为数据分析提供了强大的工具。这只是开始,掌握Statsmodels将为我们未来更深入的数据分析学习奠定坚实的基础。在实际应用中,不断探索和运用Statsmodels将使我们能够更深入地理解和利用数据,为各种问题找到切实可行的解决方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!