14-高并发-异步并发
在做电商系统时,首页、活动页、商品详情页等系统承载了网站的大部分流量,而这些系统的主要职责包括聚合数据拼装模板、热点统计、缓存、下游功能降级开关、托底数据等。
其中聚合数据需要调用多个其他服务获取数据、拼装数据/模板,然后返回给前端,聚合数据来源主要有依赖系统/服务、缓存、数据库等。
而系统之间的调用可以通过如HTTP接口调用(如HtpClient)、SOA服务调用(如dubbo、thrift)等实现。
在Java中,如使用Tomcat,一个请求会分配一个线程进行请求处理,该线程负责获取数据、拼装数据或模板,然后返回给前端。
在同步调用获取数据接口的情况下(等待依赖系统返回数据),整个线程是一直被占用并阻塞的。
如果有大量的这种请求,则每个请求占用一个线程,但线程一直处于阻塞,降低了系统的吞吐量,这将导致应用的吞吐量下降。
我们希望,在调用依赖的服务响应比较慢时,应该让出线程和CPU来处理下一个请求,当依赖的服务返回后再分配相应的线程来继续处理。
而这应该有更好的解决方案:异步/协程。
而Java是不支持协程的(虽然有些Java框架号称支持,但还是高层API的封装),因此,在Java中我们可以使用异步来提升吞吐量。目前大部分Java开源框架(HttpAsyncClient、Dubbo、Thrift等)都支持。
另外,应用中一个服务可能会调用多个依赖服务来处理业务,而这些依赖服务是可以同时调用的。如果顺序调用的话需要耗时100ms,而并发调用只需要50ms,那么可以使用Java并发机制来并发调用依赖服务,从而降低该服务的响应时间。
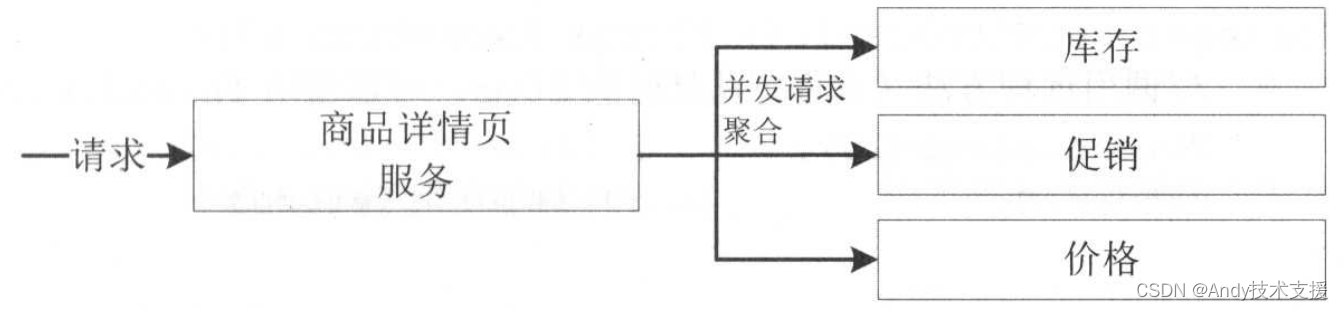
在开发应用系统过程中,通过异步并发并不能使响应变得更快,更多是为了提升吞吐量、对请求更细粒度控制,或是通过多依赖服务并发调用降低服务响应时间。
当一个线程在处理任务时,通过Fork多个线程来处理任务并等待这些线程的处理结果,这种应用并不是真正的异步。
异步是针对CPU和IO的,当IO没有就绪时要让出CPU来处理其他任务,这才是异步。
本文不会介绍异步并发实现原理,主要介绍在Java应用中如何运用这些技术,而且大多数场景并不是真正的异步化,在Java中真正实现异步化是非常困难的事情,如MySQL JDBC驱动等很多都是BIO设计,大多数情况下说的异步并发是通过线程池模拟实现。
同步阻塞调用
即串行调用,响应时间为所有依赖服务的响应时间总和。
异步Future
线程池配合Future实现,但是阻塞主请求线程,高并发时依然会造成线程数过多、CPU上下文切换。
通过Future可以并发发出N个请求,然后等待最慢的一个返回,总响应时间为最慢的一个请求返回的用时。如下请求如果并发访问,则响应可以在30ms后返回。

异步Callback
通过回调机制实现,即首先发出网络请求,当网络返回时回调相关方法,如HttpAsyncClien使用基于NIO的异步I/O模型实现,它实现了Reactor模式,摒弃阻塞I/O模型one thread per connection,采用线程池分发事件通知,从而有效支撑大量并发连接。这种机制并不能提升性能,而是为了支撑大量并发连接或者提升吞吐量。
异步编排CompletableFuture
JDK8 CompletableFuture提供了新的异步编程思路,可以对多个异步处理进行编排,实现更复杂的异步处理。
其内部使用ForkJoinPool实现异步处理。
使用CompletableFuture可以把回调方式的实现转变为同步调用实现。
CompletableFuture提供了50多个API,可以满足各种所需场景的异步处理编排,在此列举三个场景。
场景一是三个服务异步并发调用,然后对结果合并处理,不阻塞主线程。

异步Web服务实现
借助Servlet 3、CompletableFuture实现异步Web服务。如下是整个处理流程。
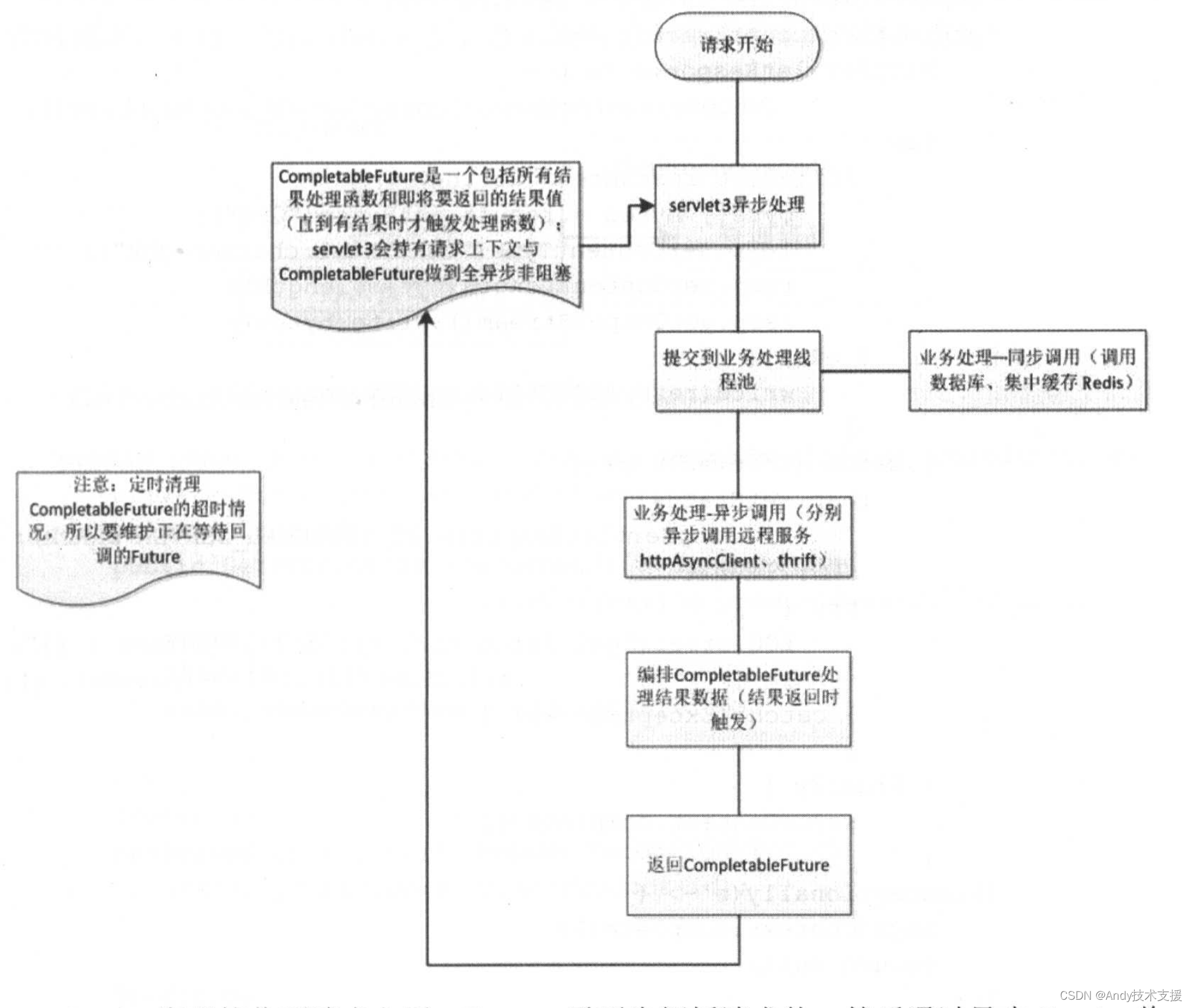
Servlet容器接收到请求之后,Tomcat需要先解析请求体,然后通过异步Servlet将请求交给异步线程池来完成业务处理,Tomcat线程释放回容器。通过异步机制可以提升Tomcat容器的吞吐量。
请求缓存
在一个查询库存的服务中,因为一些特殊原因对同一个商品查询了多次,即一次用户请求需要重复调用多次商品接口。
我们一般的做法是将GetProductService包装一层JVM缓存,不过,使用Hystrix后,我们还有另一种请求级别的缓存实现。
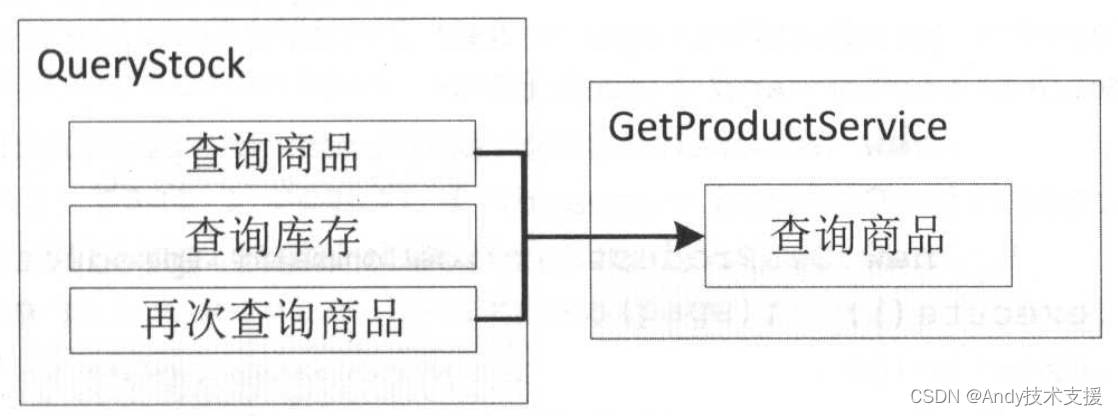
Hystrix使用了ThreadLocal HystrixRequestContext实现,并在异步线程执行之前注入ThreadLocal HystrixRequestContext实现多个线程共享,从而实现请求级别的响应缓存。
下面看一下如何用CompletableFuture实现批量查询。
我们有个服务需要多次查询价格,而价格服务提供了单个查询和批量查询接口。
一种方式是我们在客户端多线程查询,然后聚合。
另一种方式是调用批量查询接口(一些服务器端实现其实是串行的,这种情况建议使用客户端多线程查询,而不是服务器端提供的支持)。在调用批量接口时,我们需要限制每次批量的大小,从而减少阻塞时间。
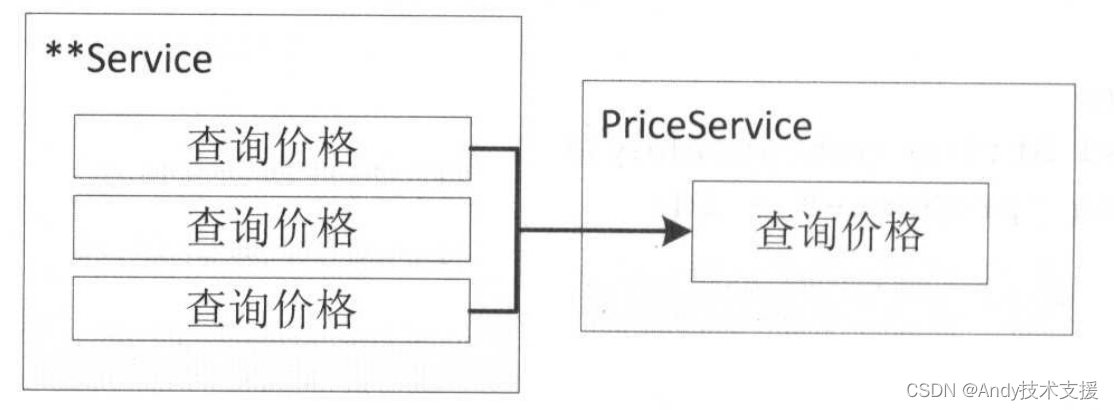
请求合并
CompletableFuture必须提前构造好批量查询,而Hystrix支持将多个单个请求转换为单个批量请求,即可以按照单个命令来请求。但是,实际是以批量请求模式执行。
Hystrix内部会将多个查询进行合并后批量查询,此处需要先使用queue而不能直接使用execute方法调用。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!