DALL-E:Zero-Shot Text-to-Image Generation
2023-12-23 17:53:15
DALL-E
- 论文
- 是一个文本生成图片模型。
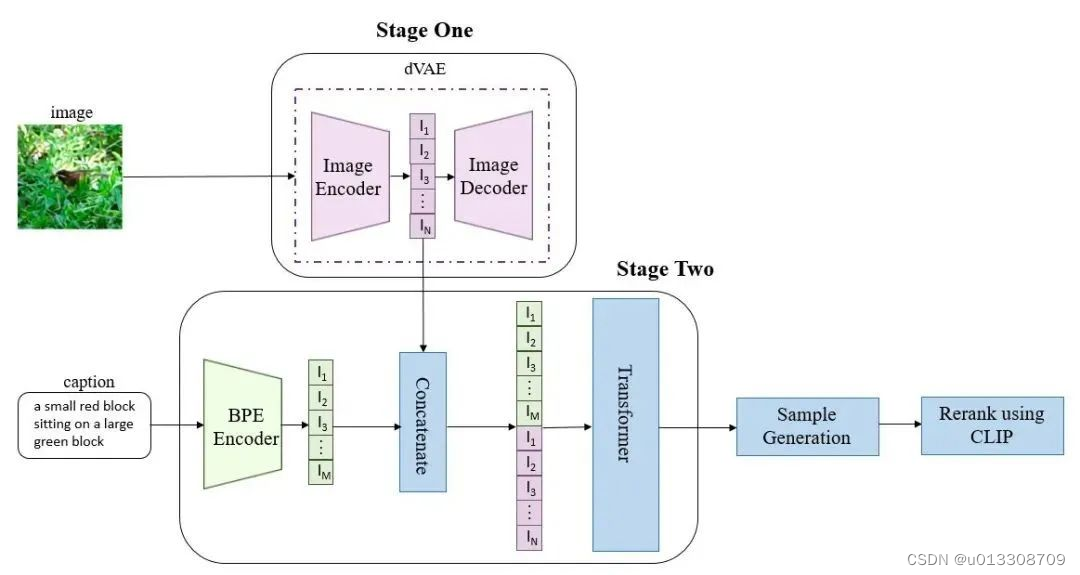
训练分为两个阶段
- 第一阶段,训练一个dVAE(discrete variational autoencoder离散变分自动编码器),其将256 x 256的RGB图片转换为32 x 32的图片token。目的:降低图片的分辨率。图片token的词汇量大小是8192个,即每个位置有8192种可能的取值(也就是说dVAE的encoder输出是维度为32x32x8192的logits,然后通过logits索引codebook的特征进行组合,codebook的embedding是可学习的)。第一阶段同时训练dVAE编码器和dVAE解码器。
- 第二阶段,用BPE Encoder对文本进行编码,得到最多256个文本token,token数不满256的话padding到256,然后将256个文本token与1024个图像token进行拼接,得到长度为1280的数据,用拼接的数据去训练一个自回归transformer来建模文本和图片token的联合分布。
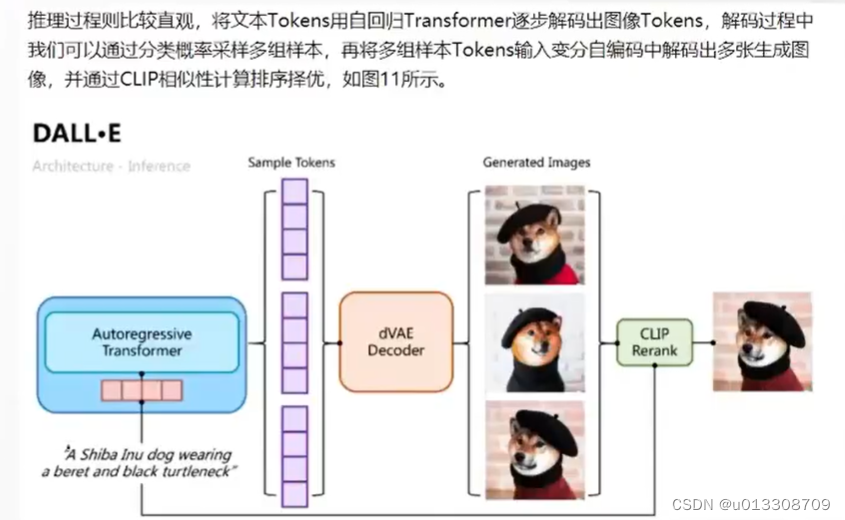
推理阶段
- 给定一张候选图片和一条文本,通过transformer可以得到融合后的token,然后用dVAE的decoder生成图片,最后通过预训练好的CLIP计算出文本和生成图片的匹配分数,采样越多数量的图片,就可以通过CLIP得到不同采样图片的分数排序,得到不同采样图片的分数排序,最终找到跟文本最匹配的图片。
- dVAE、Transformer和CLIP三个模型都是不同阶段独立训练的
参考:https://blog.csdn.net/weixin_57974242/article/details/134227455
文章来源:https://blog.csdn.net/u013308709/article/details/135162021
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!