[论文笔记] chatgpt系列 SparseMOE—GPT4的MOE结构
2023-12-16 04:46:05
SparseMOE: 稀疏激活的MOE
Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。
显存增加。

Experts Choice:路由MOE:???????
由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。
由于FFN层的时间复杂度和attention层不同,FFN层的时间复杂度在O(N*d),N是输入长度,d是隐层纬度。attention层的时间复杂度在O(N^2*d)。
所以这样操作没能减小计算量。参数量也是多了几个Expert的参数量。
论文里的效果比SparseMOE更好。显存增加。
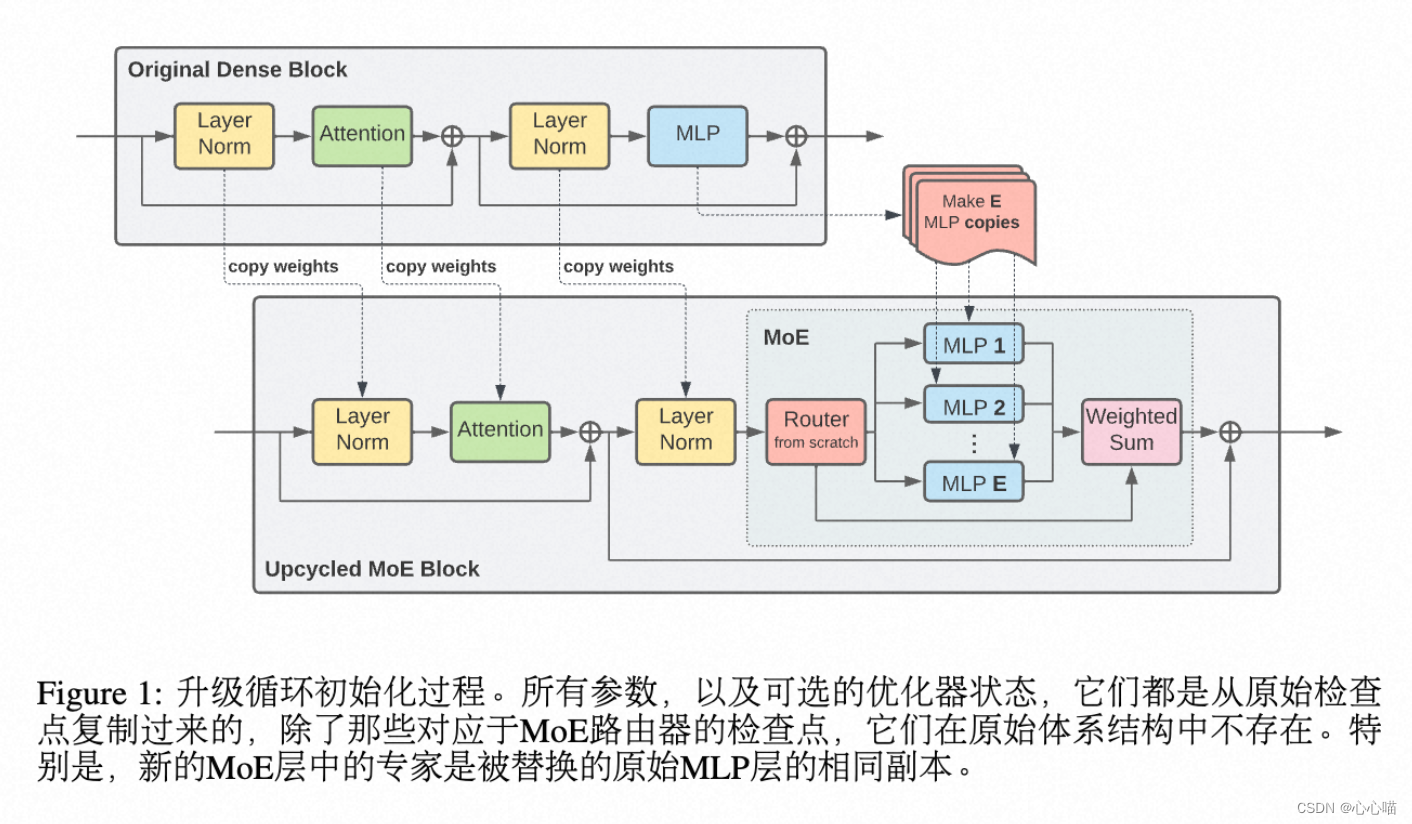
Tokens Choice:路由MOE:???????
由token选择专家。每个token只能进到一个专家里。没有t
文章来源:https://blog.csdn.net/Trance95/article/details/134998500
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!