10、神秘的“位移主题”
本章主题是:Kafka 中的内部主题(Internal Topic)__consumer_offsets。
__consumer_offsets 在 Kafka 源码中有个更为正式的名字,叫位移主题,即 Offsets Topic。这里将统一使用位移主题来指代__consumer_offsets。需要注意的是,它有两个下划线哦。
1、什么是位移主题
Consumer 的位移管理机制其实就是将 Consumer 的位移数据作为一条条普通的 Kafka 消息,提交到 __consumer_offsets 中。可以这么说,__consumer_offsets 的主要作用是保存 Kafka 消费者的位移信息。它要求这个提交过程不仅要实现高持久性,还要支持高频的写操作。显然,Kafka 的主题设计天然就满足这两个条件,因此,使用 Kafka 主题来保存位移这件事情,实际上就是一个水到渠成的想法了。
位移主题和普通的 Kafka 主题类似,我们可以手动地创建它、修改它,甚至是删除它。只不过,它同时也是一个内部主题,大部分情况下,其实并不需要 “搭理” 它,也不用花心思去管理它,把它丢给 Kafka 就完事了。
虽说位移主题是一个普通的 Kafka 主题,但它的消息格式却是 Kafka 自己定义的,用户不能修改,也就是说你不能随意地向这个主题写消息,因为一旦你写入的消息不满足 Kafka 规定的格式,那么 Kafka 内部无法成功解析,就会造成 Broker 的崩溃。事实上,Kafka Consumer 有 API 帮你提交位移,也就是向位移主题写消息,千万不要自己写个 Producer 随意向该主题发送消息。
2、位移主题的消息格式
那这个主题的消息格式是怎么的呢?里面的消息格式,可以简单地理解为是一个 KV 对。
key 的内容
1、key 保存了 Group ID。因为必须要有字段来标识这个位移数据是哪个 Consumer 的
2、Key 还保存了 Consumer 要提交位移的分区。因为 Consumer 提交位移是在分区层面上进行的,即它提交的是某个或某些分区的位移
结论就是,位移主题的 Key 中应该保存 3 部分内容:<Group ID,主题名,分区号>
value 的内容
1、保存一个位移值
2、保存位移提交的一些其他元数据,诸如时间戳和用户自定义的数据等。保存这些元数据是为了帮助 Kafka 执行各种各样后续的操作,比如删除过期位移消息等。
可以简单地认为消息体就是保存了位移值。
3、位移主题是怎么被创建的
当 Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。
其实位移主题就是普通的 Kafka 主题,那么它自然也有对应的分区数。但如果是 Kafka 自动创建的,分区数是怎么设置的呢?
这就要看 Broker 端参数 offsets.topic.num.partitions 的取值了。它的默认值是 50,因此 Kafka 会自动创建一个 50 分区的位移主题。
存储在 Kafka 日志路径下如 __consumer_offsets-xxx 这样的目录,这就是 Kafka 自动创建的位移主题。
那除分区数外,副本数或备份因子是怎么控制的呢?答案就是 Broker 端另一个参数 offsets.topic.replication.factor。它的默认值是 3。
总结一下,如果位移主题是 Kafka 自动创建的,那么该主题的分区数是 50,副本数是 3。
4、什么地方会用到位移主题
创建位移主题当然是为了用的,那么什么地方会用到位移主题呢?
Kafka Consumer 提交位移时会写入该主题,那 Consumer 是怎么提交位移的呢?
目前 Kafka Consumer 提交位移的方式有两种:自动提交位移和手动提交位移。
Consumer 端有个参数叫 enable.auto.commit,如果值是 true,则 Consumer 在后台默默地为你定期提交位移,提交间隔由一个专属的参数 auto.commit.interval.ms 来控制。自动提交位移有一个显著的优点,就是省事,你不用操心位移提交的事情,就能保证消息消费不会丢失。但这一点同时也是缺点。因为它太省事了,以至于丧失了很大的灵活性和可控性,你完全没法把控 Consumer 端的位移管理。
事实上,很多与 Kafka 集成的大数据框架都是禁用自动提交位移的,如 Spark、Flink 等。这就引出了另一种位移提交方式:手动提交位移,即设置 enable.auto.commit = false。一旦设置了 false,作为 Consumer 应用开发的你就要承担起位移提交的责任。Kafka Consumer API 为你提供了位移提交的方法,如 consumer.commitSync 等。当调用这些方法时,Kafka 会向位移主题写入相应的消息。
事实上,很多与 Kafka 集成的大数据框架都是禁用自动提交位移的,如 Spark、Flink 等。这就引出了另一种位移提交方式:手动提交位移,即设置 enable.auto.commit = false。一旦设置了 false,作为 Consumer 应用开发的你就要承担起位移提交的责任。Kafka Consumer API 为你提供了位移提交的方法,如 consumer.commitSync 等。当调用这些方法时,Kafka 会向位移主题写入相应的消息。
如果你选择的是自动提交位移,那么就可能存在一个问题:只要 Consumer 一直启动着,它就会无限期地向位移主题写入消息。
我们来举个极端一点的例子。假设 Consumer 当前消费到了某个主题的最新一条消息,位移是 100,之后该主题没有任何新消息产生,故 Consumer 无消息可消费了,所以位移永远保持在 100。由于是自动提交位移,位移主题中会不停地写入位移 = 100 的消息。显然 Kafka 只需要保留这类消息中的最新一条就可以了,之前的消息都是可以删除的。这就要求 Kafka 必须要有针对位移主题消息特点的消息删除策略,否则这种消息会越来越多,最终撑爆整个磁盘。
5、位移主题的删除机制
Kafka 是怎么删除位移主题中的过期消息的呢?答案就是 Compaction。可以理解为压实,或干脆采用 JVM 垃圾回收中的术语:整理。
不管怎么翻译,Kafka 使用 Compact 策略来删除位移主题中的过期消息,避免该主题无限期膨胀。那么应该如何定义 Compact 策略中的过期呢?对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。我在这里贴一张来自官网的图片,来说明 Compact 过程。
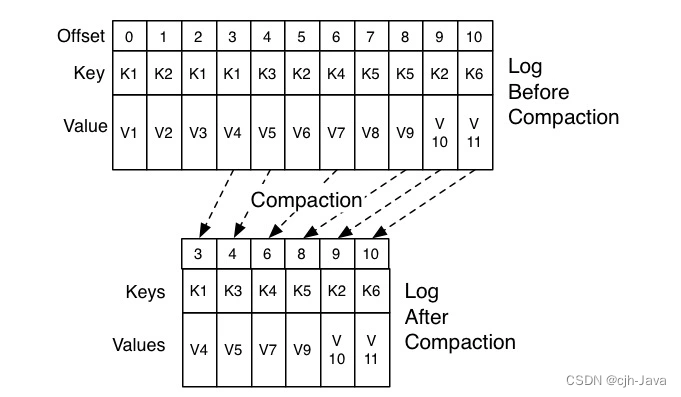
图中位移为 0、2 和 3 的消息的 Key 都是 K1。Compact 之后,分区只需要保存位移为 3 的消息,因为它是最新发送的。
Kafka 提供了专门的后台线程定期地巡检待 Compact 的主题,看看是否存在满足条件的可删除数据。这个后台线程叫 Log Cleaner。很多实际生产环境中都出现过位移主题无限膨胀占用过多磁盘空间的问题,如果你的环境中也有这个问题,我建议你去检查一下 Log Cleaner 线程的状态,通常都是这个线程挂掉了导致的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!