Apache Kyuubi 讲解与实战操作
文章目录
一、概述
Apache Kyuubi,一个分布式多租户网关,用于在 Lakehouse 上提供无服务器 SQL。Kyuubi 是一个基于 Apache Spark 的开源分布式 SQL 引擎,为用户提供了一个统一的 SQL 查询接口,使其能够以标准 SQL 语法查询和分析各种数据源。以下是对 Kyuubi 的详细解释:
- 背景和目的:
- Kyuubi 的目标是提供一个高度并发、可扩展且支持多租户的 SQL 引擎,以满足大数据分析的需求。
- 它构建在
Apache Spark之上,借助Spark的分布式计算能力,能够处理大规模数据集。
- 核心特性:
SQL兼容性: 支持标准SQL查询,使用户能够使用熟悉的 SQL 语法。- 分布式查询引擎: 利用 Apache Spark 实现分布式查询和计算。
- 连接池支持: 提供连接池机制,有效管理和重用连接,提高性能。
- 多租户支持: 允许多个用户或应用程序共享同一个 Kyuubi 服务器,确保隔离性。
- 身份验证和授权: 集成了身份验证和授权机制,保障数据访问的安全性。
- 可扩展的数据源支持: 可以连接多种数据源,包括 Hive、HBase 和其他兼容 Spark 的数据存储。
- 架构和工作原理:
Kyuubi架构上包含客户端、Kyuubi服务器和Spark集群。客户端通过JDBC或ODBC驱动连接到Kyuubi服务器,然后Kyuubi将查询分发到底层的Spark集群进行处理。 - 部署和配置:
Kyuubi可以通过配置文件进行各种参数的设置,包括连接池、身份验证方式、Spark应用程序的配置等。详细的配置信息可以参考Kyuubi的官方文档。
- 使用场景:
Kyuubi适用于需要进行大数据分析的场景,尤其是需要支持多用户并发查询的环境。- 通过
SQL查询接口,用户可以方便地从多种数据源中检索和分析数据。
- 社区和维护:
Kyuubi是一个活跃的开源项目,有一个不断发展的社区。用户可以通过GitHub等渠道参与讨论、报告问题和提供贡献。
总体而言,Kyuubi 是一个强大的分布式 SQL 引擎,通过整合 Apache Spark 的计算能力,提供了高性能、多租户支持的 SQL 查询服务。在大数据分析领域,Kyuubi 提供了一种灵活、可扩展的解决方案。
官方文档:
Kyuubi 软件跟 Livy 一样都是可以作为 Spark 代理网关,但是 livy 只支持 Spark2.x,如果对 Livy 感兴趣的小伙伴可以参考我以下几篇文章:
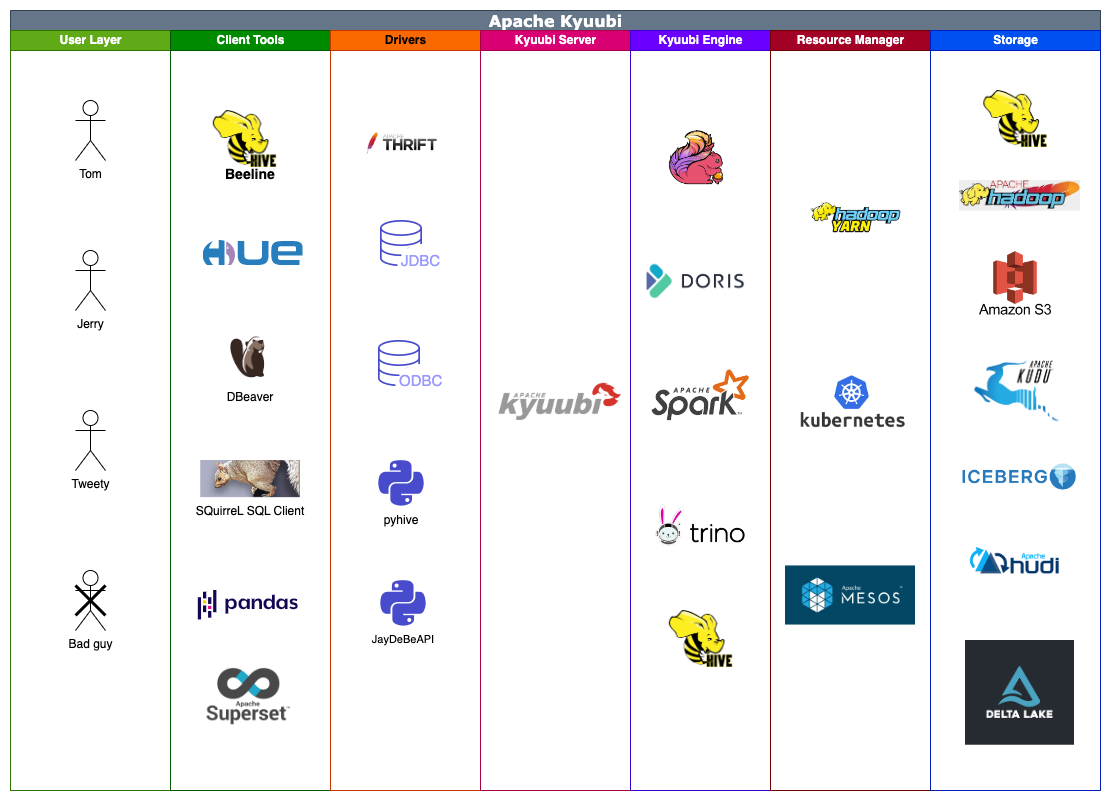
二、Spark Kyuubi 架构
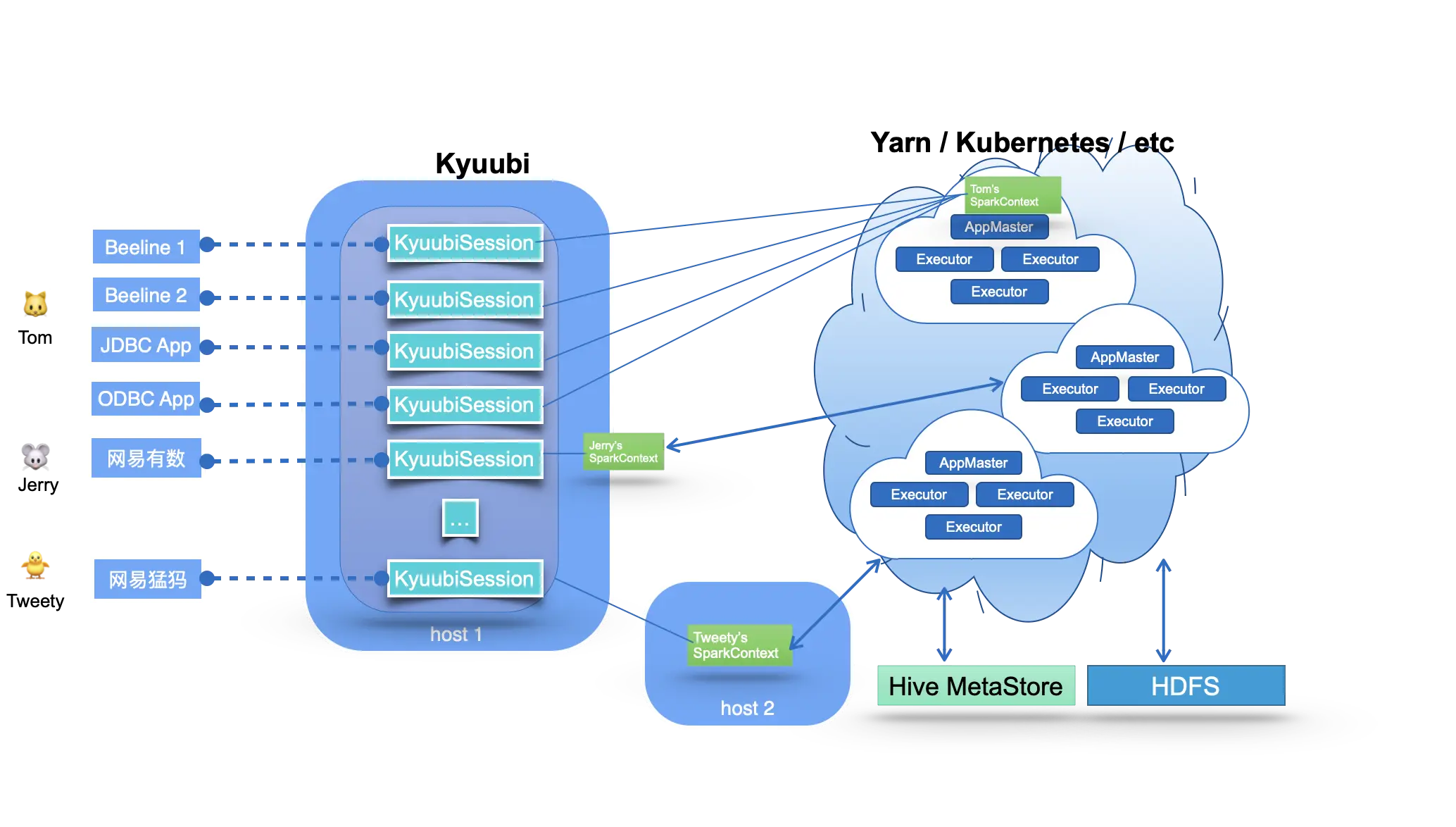
Kyuubi 系统的基本技术架构如下图所示:
-
图的中间部分是
Kyuubi服务端的主要部分,它处理来自图像左边所示的客户端的连接和执行请求。在Kyuubi中,这些连接请求被维护为Kyuubi Session,执行请求被维护为Kyuubi Operation,并与相应的session进行绑定。 -
Kyuubi Session的创建可以分为两种情况:轻量级和重量级。大多数 session 的创建都是轻量级的,用户无感知。唯一重量级的情况是在用户的共享域中没有实例化或缓存SparkContext,这种情况通常发生在用户第一次连接或长时间没有连接的时候。这种一次性成本的session维护模式可以满足大部分的 ad-hoc 快速响应需求。 -
Kyuubi以松耦合的方式维护与SparkConext的连接。这些SparkContexts可以是本服务实例在客户端部署模式下在本地创建的Spark程序,也可以是集群部署模式下在Yarn或Kubernetes集群中创建的。在高可用模式下,这些SparkConext也可以由其他机器上的Kyuubi实例创建,然后由这个实例共享。 -
这些
SparkConext实例本质上是由Kyuubi服务托管的远程查询执行引擎程序。这些程序在Spark SQL上实现,并对SQL语句进行端到端编译、优化和执行,以及与元数据(如Hive Metastore)和存储(如HDFS)服务进行必要的交互,最大限度地发挥Spark SQL的威力。它们可以自行管理自己的生命周期,自行缓存和回收,并且不受Kyuubi服务器上故障转移的影响。
三、Hadoop 基础环境安装
可以选择物理部署,如果只是测试的话,也可以选择容器部署,这里为了快速测试就选择容器部署了。物理部署和容器部署教程如下:
- 大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
- 大数据Hadoop之——数据仓库Hive
- 大数据Hadoop之——计算引擎Spark
- 通过 docker-compose 快速部署 Hive 详细教程
1)hadoop 下载部署包
# 下载部署包
git clone https://gitee.com/hadoop-bigdata/docker-compose-hadoop.git
2)创建网络
docker network create hadoop-network
3)部署MySQL
cd docker-compose-hadoop/mysql
docker-compose -f mysql-compose.yaml up -d
docker-compose -f mysql-compose.yaml ps
#root 密码:123456,以下是登录命令,注意一般在公司不能直接在命令行明文输入密码,要不然容易被安全抓,切记,切记!!!
docker exec -it mysql mysql -uroot -p123456
4)部署 Hadoop Hive
# 部署 Hadoop Hive
cd docker-compose-hadoop/hadoop_hive
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
# hive
docker exec -it hive-hiveserver2 hive -e "show databases";
# hiveserver2
docker exec -it hive-hiveserver2 beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop -e "show databases;"
四、Spark Kyuubi 安装
1)下载 Kyuubi
wget https://dlcdn.apache.org/kyuubi/kyuubi-1.8.0/apache-kyuubi-1.8.0-bin.tgz --no-check-certificate
tar zxf apache-kyuubi-1.8.0-bin.tgz
2)下载 Spark3
关于Spark的介绍,可以参考我之前的文章:大数据Hadoop之——计算引擎Spark
wget https://archive.apache.org/dist/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz --no-check-certificate
tar -xf spark-3.3.2-bin-hadoop3.tgz
修改配置文件:
# 进入spark配置目录
cd spark-3.3.2-bin-hadoop3/conf
# copy 一个模板配置
cp spark-env.sh.template spark-env.sh
在spark-env.sh下加入如下配置
# Hadoop 的配置文件目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# YARN 的配置文件目录
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# SPARK 的目录
export SPARK_HOME=/opt/apache/spark-3.3.2-bin-hadoop3
# SPARK 执行文件目录
export PATH=$SPARK_HOME/bin:$PATH
在/etc/profile文件中追加如下内容:
export SPARK_HOME=/opt/apache/spark-3.3.2-bin-hadoop3
export PATH=$SPARK_HOME/bin:$PATH
测试:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--num-executors 3 \
--executor-memory 1G \
--executor-cores 1 \
/opt/apache/spark-3.3.2-bin-hadoop3/examples/jars/spark-examples_2.12-3.3.2.jar 100

2)配置 Kyuubi (Spark3)
cp conf/kyuubi-env.sh.template conf/kyuubi-env.sh
echo 'export JAVA_HOME=/opt/apache/jdk1.8.0_212' >> conf/kyuubi-env.sh
echo 'export SPARK_HOME=/opt/apache/spark-3.3.2-bin-hadoop3' >> conf/kyuubi-env.sh
cp conf/kyuubi-defaults.conf.template conf/kyuubi-defaults.conf
# 将kyuubi地址设置为localhost,如果不打开该注释,那么使用localhost是无法连接的,需要填写主机的ip地址
vi conf/kyuubi-defaults.conf
kyuubi.frontend.bind.host localhost
3)启动 Kyuubi
bin/kyuubi start
4)测试使用
使用kyuubi自带的beeline客户端工具
bin/beeline -u 'jdbc:hive2://localhost:10009/' -n hadoop
Apache Kyuubi 不仅仅支持 Spark3 代理也支持 Presto、Flink 等组件的代理。
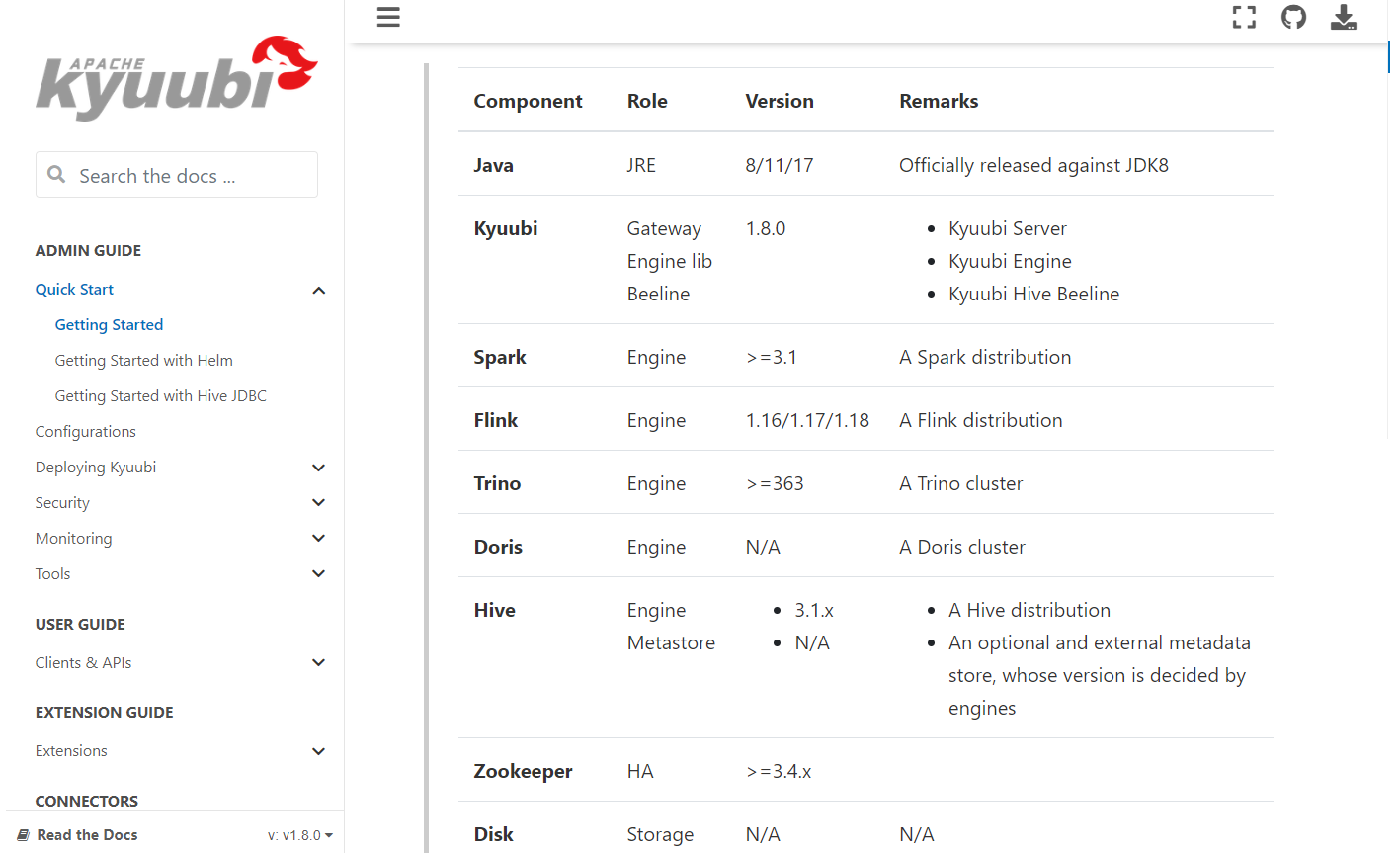
五、Apache Kyuubi HA 部署
目前Kyuubi支持负载均衡,使整个系统高可用。负载均衡旨在优化所有 Kyuubi 服务单元的使用,最大化吞吐量,最小化响应时间,并避免单个单元过载。使用具有负载平衡功能的多个 Kyuubi 服务单元而不是单个单元可以通过冗余来提高可靠性和可用性。
Kyuubi 通过使用Apache ZooKeeper来利用组中的冗余服务实例,在一个或多个组件发生故障时提供连续服务。
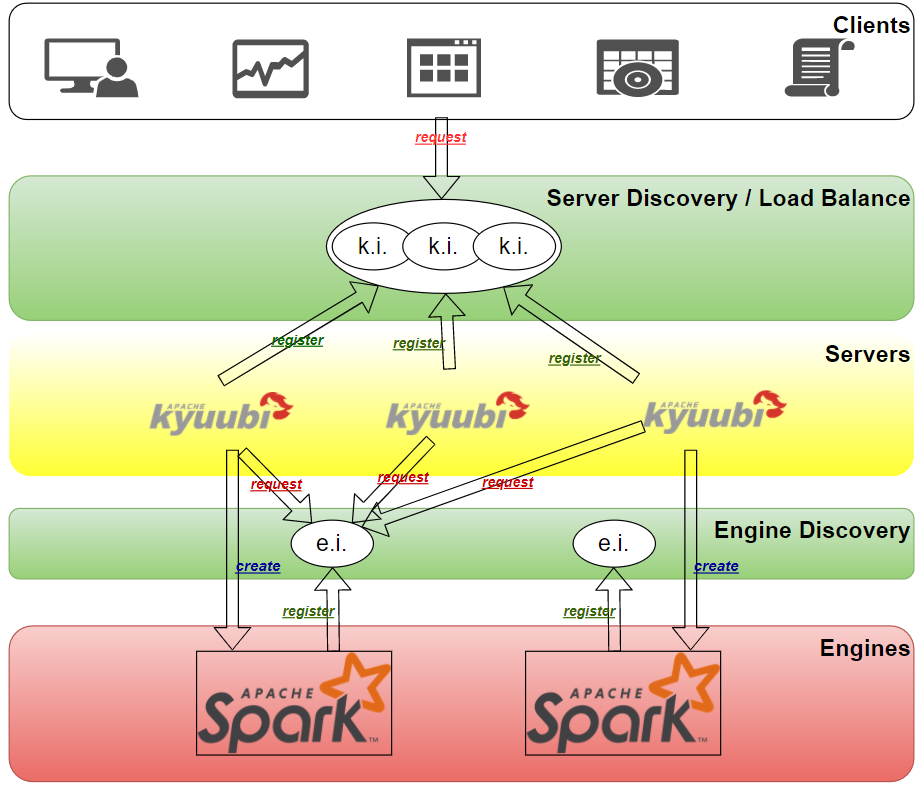
1)部署 Zookeeper
关于 Zookeeper 的介绍与部署可以参考我以下几篇文章:
这里为了快速测试就选择docker-compose部署Zookeeper了。
3)Kyuubi HA 配置
vim /opt/kyuubi/conf/kyuubi-defaults.conf
kyuubi.ha.addresses 192.168.182.110:31181,192.168.182.110:32181,192.168.182.110:33181
kyuubi.ha.namespace kyuubi
4)启动服务
bin/kyuubi restart
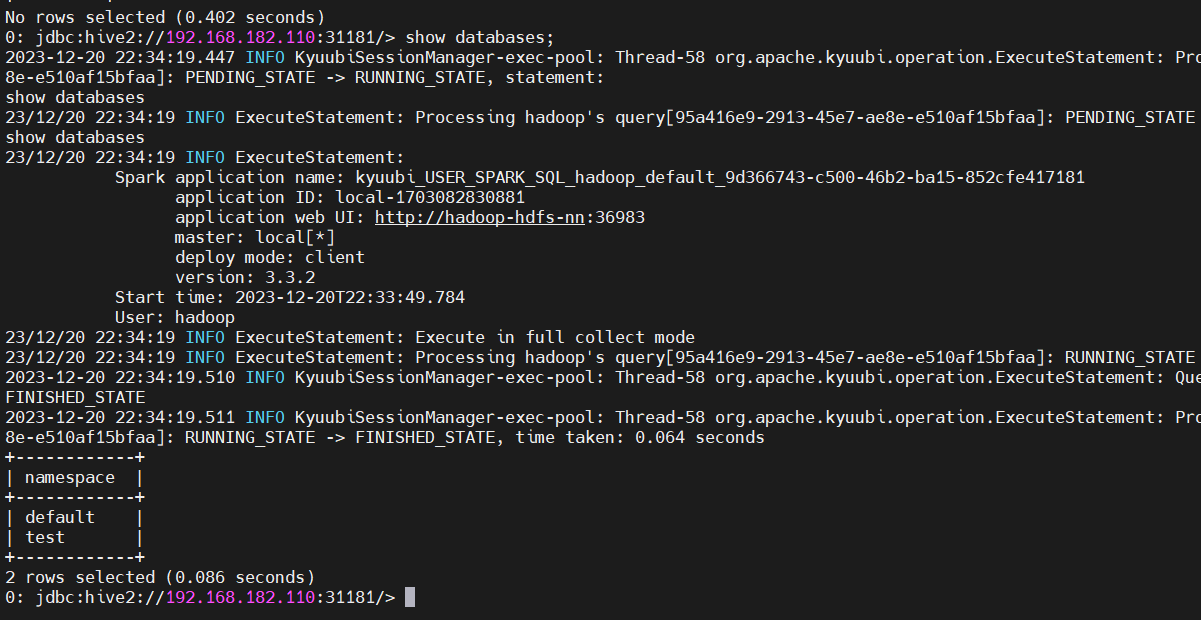
5)测试
bin/beeline -u 'jdbc:hive2://192.168.182.110:31181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi' -n hadoop
Apache Kyuubi 讲解与实战操作就先到这里了,更多API接口介绍与使用可以参考官方文档:https://kyuubi.readthedocs.io/en/master/client/index.html;有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!