一文教会pandas
2023-12-20 01:41:46
今天的笔试题令我感触很深,回顾一下之前写的都是低代码想想都。。。
anareport[['reportid','anndt','stockid']].drop_duplicates().rolling(window=10,min_periods=1).sum().groupby(['anndt','stockid'])['reportid'].count()
df=anareport[['reportid','anndt','stockid']].drop_duplicates()
pd.crosstab(df['anndt'],df['stockid']).rolling(window=10,min_periods=1).sum().fillna(0)能看懂以上代码可自行跳过本文,哈哈哈
1、joining and merging
下面是三个数据框:
import pandas as pd
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])
用merge合并?
print(pd.merge(df1,df3, on='HPI'))
结果为:

merge 的时候, 会自动忽略索引列. 当然, 我们也可以使用多个列做基准如下:
print(pd.merge(df1,df2, on=['HPI','Int_rate']))
结果:

不共享公共列时, 所以两个列都会保留
可以将其设置成索引:
df4.set_index('HPI', inplace=True)
df4结果为:
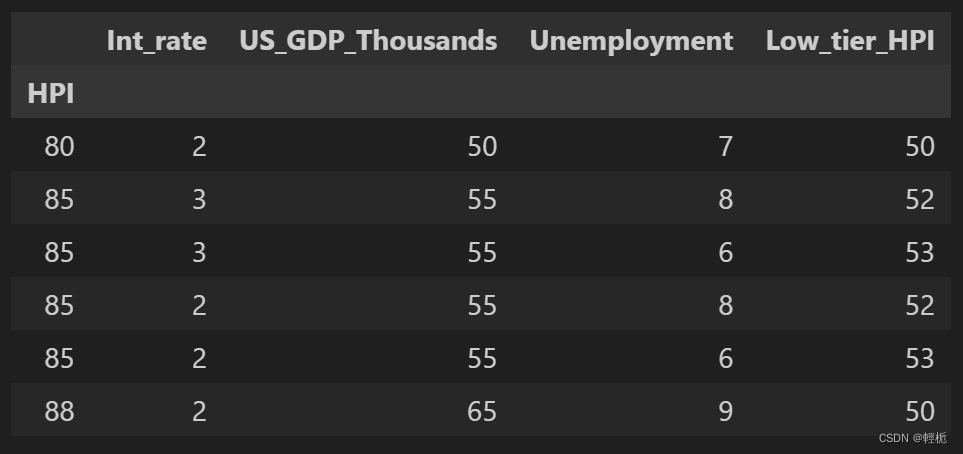
如果在合并之前,有相同的索引列就可以用join了:
df1.set_index('HPI', inplace=True)
df3.set_index('HPI', inplace=True)
joined = df1.join(df3)
print(joined)
结果为:

对上述数据稍加修改:
df1 = pd.DataFrame({
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55],
'Year':[2001, 2002, 2003, 2004]
})
df3 = pd.DataFrame({
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53],
'Year':[2001, 2003, 2004, 2005]})
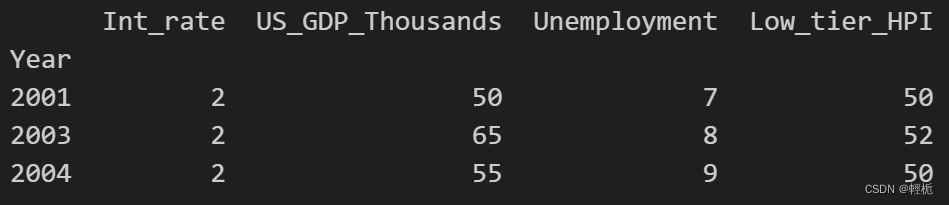
按照year合并得到:
merged = pd.merge(df1,df3, on='Year')
merged.set_index('Year', inplace=True)
print(merged)
结果为:?
?merge默认取的是交集,这就引出了另一个参数 "how", 通过对这个参数的定义, 可以选择以什么样的方式合并数据. 参数值有以下四种:
Left - 以左边的索引值为准.
Right - 以右边的索引值为准.
Outer - 取并集.
Inner - 取交集
这里展示outer效果:
merged = pd.merge(df1,df3, on='Year', how='outer')
merged.set_index('Year', inplace=True)
print(merged)
结果为:
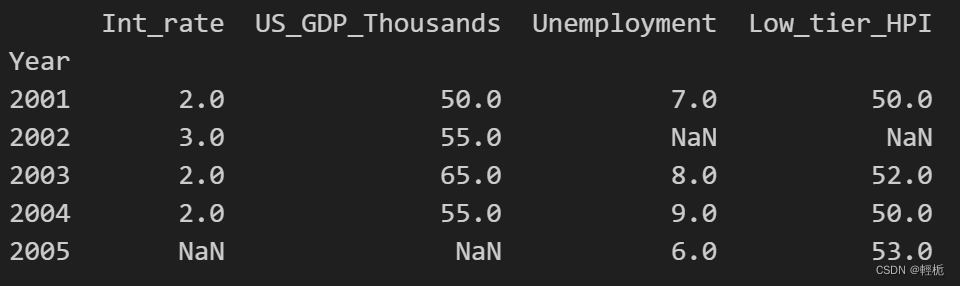
缺失值直接用NA填充。
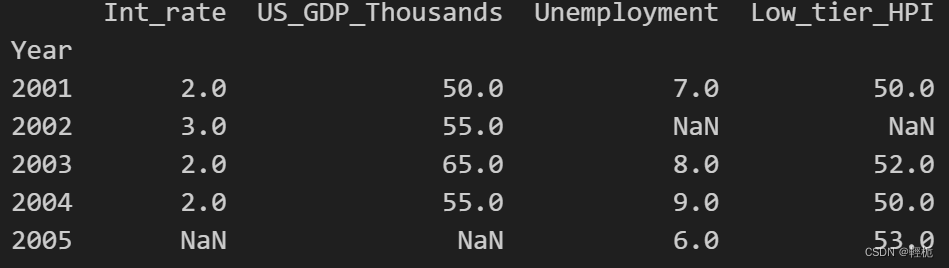
此时用join效果和merge一致:
df1.set_index('Year', inplace=True)
df3.set_index('Year', inplace=True)
joined = df1.join(df3, how="outer")
print(joined)
结果为:
 2、生成dataframe方式
2、生成dataframe方式
更多可参考:IO Tools (Text, CSV, HDF5, ...) — pandas 0.22.0 documentation
#读取csv文件:
df = pd.read_csv("/Users/rachel/Downloads/weather.csv")
#读取excel文件:,末尾为sheet参数
df = pd.read_excel("/Users/rachel/Downloads/weather.xlsx", "weather")
#字典转换:
weather_data = {
'day': ['1/1/2017','1/2/2017','1/3/2017'],
'temperature': [32,35,28],
'windspeed': [6,7,2],
'event': ['Rain', 'Sunny', 'Snow']
}
df = pd.DataFrame(weather_data)
#元组转换:
weather_data = [
('1/1/2017',32,6,'Rain'),
('1/2/2017',35,7,'Sunny'),
('1/3/2017',28,2,'Snow')
]
df = pd.DataFrame(data=weather_data, columns=['day','temperature','windspeed','event'])
#列表转换:
weather_data = [
{'day': '1/1/2017', 'temperature': 32, 'windspeed': 6, 'event': 'Rain'},
{'day': '1/2/2017', 'temperature': 35, 'windspeed': 7, 'event': 'Sunny'},
{'day': '1/3/2017', 'temperature': 28, 'windspeed': 2, 'event': 'Snow'},
]
df = pd.DataFrame(data=weather_data, columns=['day','temperature','windspeed','event'])
#自行指定列名生成数据框
df=pd.DataFrame(columns=['a','b'])3、缺失值处理
new_df = df.fillna(method='ffill')#参考上一行的值填充
new_df = df.fillna(method='bfill')#参考下一行的值填充
new_df = df.fillna(method='bfill', axis='columns')#横向从右向左填充
new_df = df.fillna(method='ffill', axis='columns')#横向从左向右填充
new_df = df.interpolate()#取空值前后的中间值
new_df = df.dropna()#舍弃所有NA的行
new_df = df.dropna(how='all')#舍弃所有列都为空值的行
new_df = df.dropna(thresh=1)#保留至少有一个列有值的行,thresh=1至少有两个列有值的行
df['value'] = df.groupby('group')['value'].transform(lambda x: x.fillna(x.mean()))# 分组后用组内均值填充NA
df['value'] = df.groupby('group')['value'].transform(lambda x: x.fillna(x.mode()[0]))#分组后用组内众数填充NA值
#补足所缺的日期
dt = pd.date_range('2024-01-01', '2024-11-11')#设置日期范围
idx = pd.DatetimeIndex(dt)#重新定义索引
df = df.reindex(idx)4、replace函数
new_df = df.replace([-99999, -88888], np.NaN)#用na替代列表中的异常值
new_df = df.replace({'temperature' : -99999,'windspeed':[-99999, -88888],'event': '0'}, np.NaN)#用字典处理每一列中异常值
new_df = df.replace({'temperature': '[A-Za-z]','windspeed': '[A-Za-z]'} ,'', regex=True)#正则表达式+字典处理每一列值格式
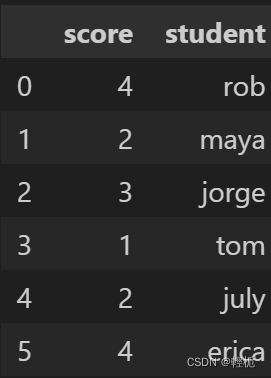
df = pd.DataFrame({'score': ['exceptional', 'average', 'good', 'poor', 'average', 'exceptional'],
'student': ['rob', 'maya', 'jorge', 'tom', 'july', 'erica']})
new_df = df.replace(['poor', 'average', 'good', 'exceptional'], [1, 2, 3, 4])#指代功能
5、用pivot table做格式转换
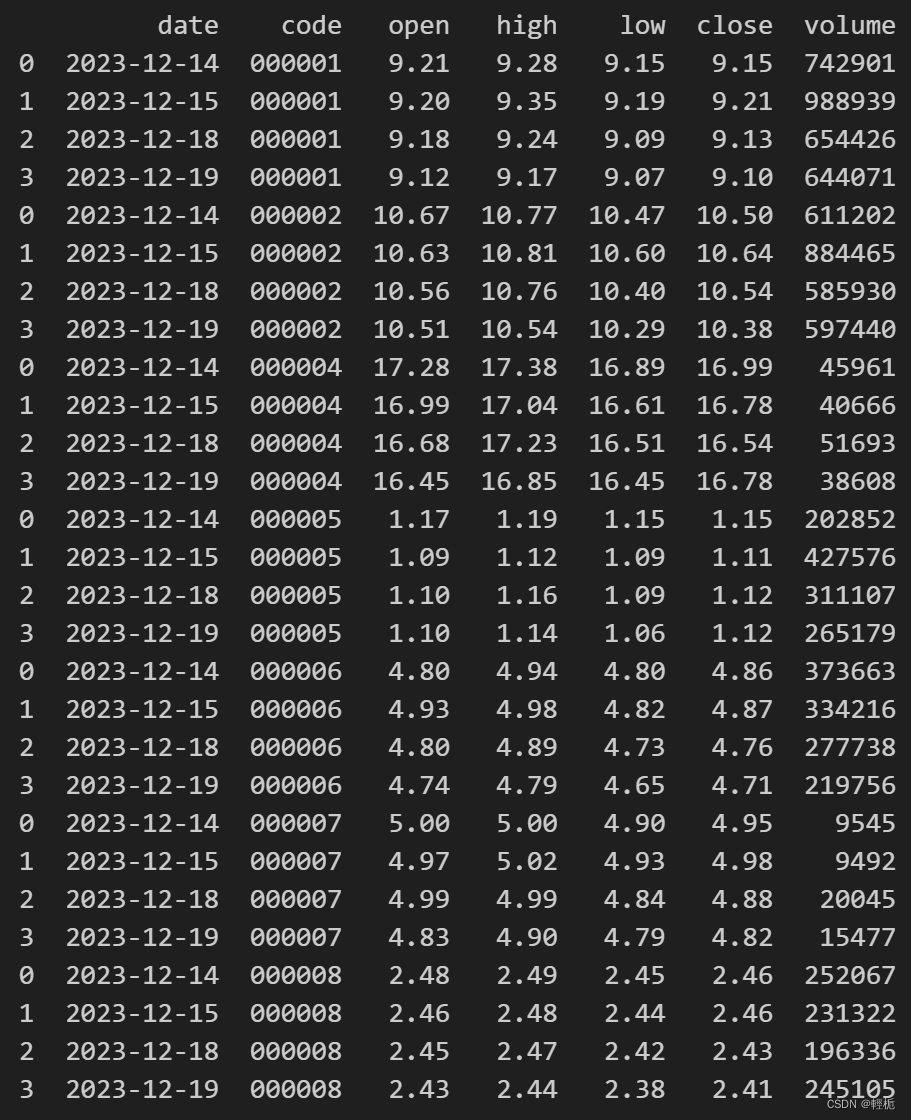
import akshare as ak
code_list = ['000001','000002','000004','000005','000006','000007','000008']
df = pd.DataFrame(columns = ['date','code','open','high','low','close','volume'])
for code in code_list:
data = ak.stock_zh_a_hist(code, period="daily", start_date = '20231214', end_date = '20231219', adjust="qfq")
data = data[['日期','开盘','最高','最低','收盘','成交量']]# 选取日期、高开低收价格、成交量数据
data = data.rename(columns={'日期': 'date','开盘': 'open','最高': 'high','最低': 'low','收盘': 'close','成交量':'volume'})
data['code'] = code
df = pd.concat([df,data])
print(df)
原来:
格式转换:#格式转换, 设置 'date' 为索引列, 也就让'date' 做每一行的输出依据, 然后设置'code' 为每一列输出的依据,输出值为close
df.pivot(index='date', columns='code', values='close')
不指定输出值:
df.pivot(index='date', columns='code')
用 pivot table 来做整合:
df.pivot_table(index='date', columns='code', values='close')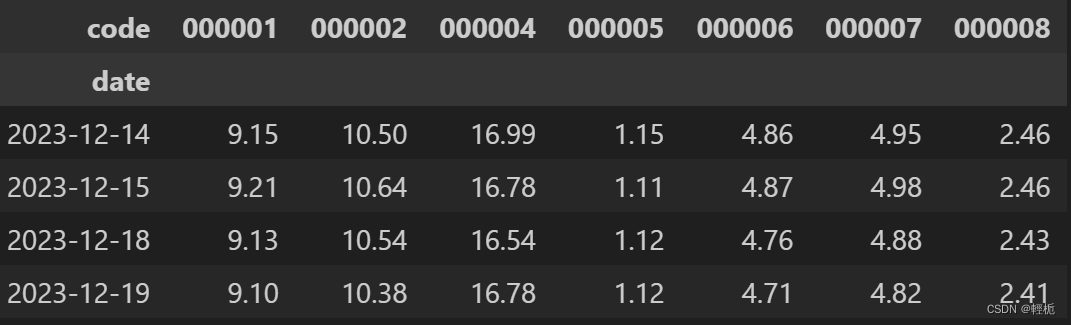
对于 pivot_table() 函数, 可以通过第三个参数 'aggfun' 来做很多的变化:
适用于:如果某个变量在同一时刻有多个值:(上海在同一天温度有多个值,我需要统计)
df.pivot_table(index='city', columns='date', aggfunc='sum')#取和
df.pivot_table(index='city', columns='date', aggfunc='count')#计数
df.pivot_table(index='city', columns='date', aggfunc='diff')#求差异
df.pivot_table(index='city', columns='date', aggfunc='mean')#求均值
df.pivot_table(index='city', columns='date', margins=True)#横向纵向分别求和的平均值6、group by 用法
文章来源:https://blog.csdn.net/mnwl12_0/article/details/135094759
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!