MYSQL练题笔记-子查询-部门工资前三高的所有员工
这个系列的最后一个,也是所有的50题的第一个困难题,看着就有点吓人啧啧啧。
一、题目相关内容
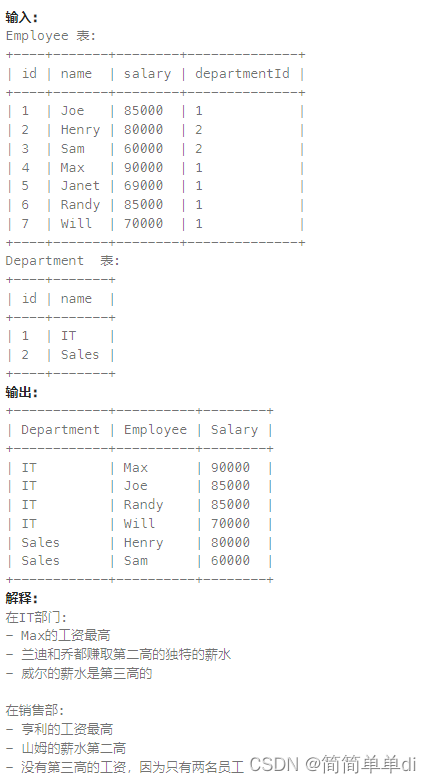
1)相关的表和题目

2)帮助理解题目的示例,提供返回结果的格式
二、自己初步的理解
将每个部门分组,然后用rank()over()窗口函数将每个分组的排名数字小于等于3的输出。但是窗口函数有一个点,他那个排序不用输出,那就用这个查询出来,然后作为父句的条件字段。
将两个表连接起来,如下语句。
Select name as department,employee,salary,rank()over(order by salary) from department d join employee e on d.id=e.departmentId group by e.departmentId
然后我觉得这里应该就不用group by 在窗口函数里面用partition by,就是如下的语句。
Select d.name as department,e.name as employee,salary,rank()over(partition by departmentId order by salary desc) as number from department d join employee e on d.id=e.departmentId;
然后这里显示的结果和最终预期结果很像,天哪然后太棒了
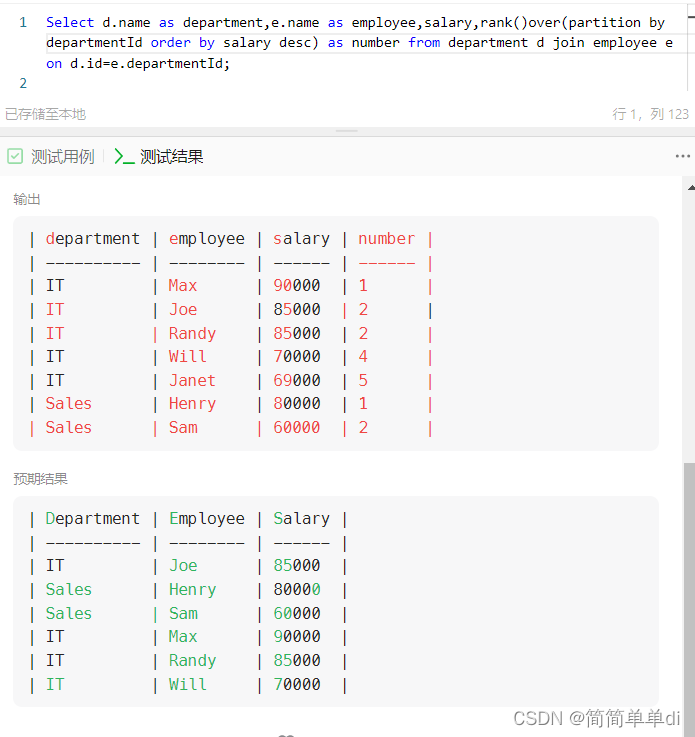
然后下一步就是上面的句子作为子查询,但是发现没什么p用,我排出来也没法根据他来用;但是我又想到一个用where in,然后分组里里面distinct,但是经过多番尝试还是失败了。
想着先去重但是去重的话,利用distinct没办法作为order by和输出的参数,然后我找之前的笔记,disctint可以用在count()里面,但是还是没有做出来。还是得看题解啊,我还以为这一题我能写出来,很有头绪啊。
三、题解展示和分析
题解如下
SELECT
Department.NAME AS Department,
e1.NAME AS Employee,
e1.Salary AS Salary
FROM
Employee AS e1,Department
WHERE
e1.DepartmentId = Department.Id
AND 3 > (SELECT? count( DISTINCT e2.Salary )
?FROM???????? Employee AS e2
?WHERE e1.Salary < e2.Salary AND e1.DepartmentId = e2.DepartmentId ????????) #这是重点
ORDER BY Department.NAME,Salary DESC;
这个题解里说先找出公司里前 3 高的薪水,意思是不超过三个值比这些值大;实在是高啊,然后用上连接,真的连接是个好东西,通常是解题的关键啊。这个题解里关于这个子查询的作者的解释如下
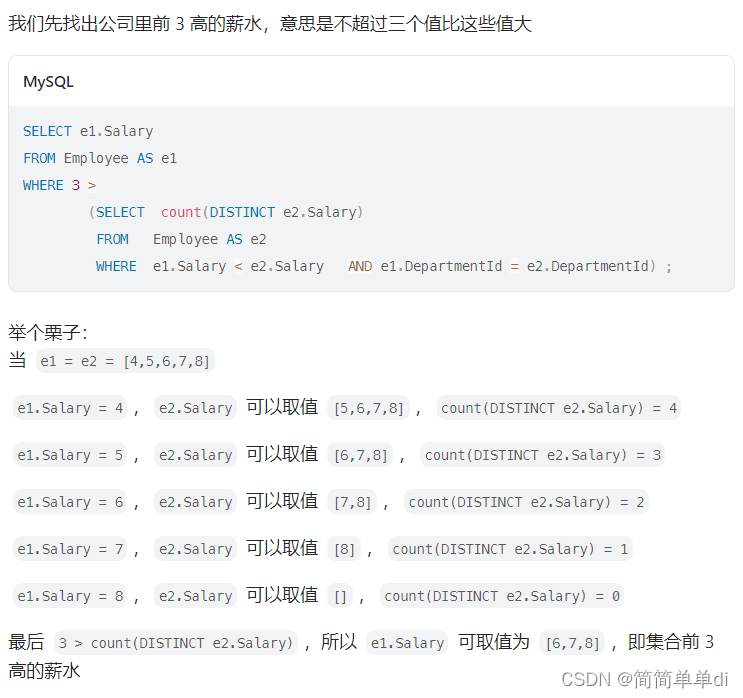
我的理解是先关注不要输出的e1.salary 定值
然后思考对应的条件下要输出的e2.salary的值,
然后最终想象输出的结果count()的数量,但是这几步其实很难想到的,因为太不直接了,要通过很多步的思考才能想出最终要达到的结果。
就是你想拿下前3的记录,两个相同的薪水对比,
如果他比你大的条数有4条,那你就是排第5,
如果他比你大的条数有3条,那你就是排第4,
如果他比你大的条数有2条,那你就是排第3,
当然最终的结果根据题目的要求是不同的薪水排名前三,所以还要利用distinct去下重
四、总结
这题太难了,我其实还没有思考透,还需要再复习。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!