ARTrack 阅读记录
目录
环境配置与脚本编写
按照官网执行并没有顺利完成,将yaml文件中的 pip 项 手动安装的
conda create -n artrack python=3.9
# 启动该环境,并跳转到项目主目录路径下
astor==0.8.1 configparser==5.2.0
data==0.4 docker-pycreds==0.4.0 easydict==1.9 einops==0.4.1 formulaic==0.5.2 funcsigs==1.0.2 future==0.18.2
gitdb==4.0.9 gitpython==3.1.27 interface-meta==1.3.0 iopath==0.1.9 jpeg4py==0.1.4 jsonpatch==1.32 jsonpointer==2.3 latex==0.7.0
libarchive-c==2.9 linearmodels==4.29 lmdb==1.3.0 loguru==0.6.0 mat73==0.59 memory-profiler==0.60.0 msgpack==1.0.2 ninja==1.11.1
opencv-python==4.5.5.64 pathtools==0.1.2 promise==2.3 property-cached==1.6.4 protobuf==3.20.0 pycocotools==2.0.4 pyhdfe==0.1.2
ruamel-yaml-conda==0.15.100 sentry-sdk==1.5.8 setproctitle==1.2.2 setuptools-scm==7.1.0 shapely==1.8.1.post1 shortuuid==1.0.8
shutilwhich==1.1.0 smmap==5.0.0 tables==3.6.1 tempdir==0.7.1 tensorboardx==2.5.1 thop==0.1.0.post2207010342 tikzplotlib==0.10.1
timm==0.5.4 tomli==2.0.1 torch==1.11.0 torchfile==0.1.0 visdom==0.1.8.9 wandb==0.12.11 webcolors==1.12 yaspin==2.1.0里面的默认路径需要改写
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir ./outpu官网下载训练好的模型,创建路径,将模型放在该路径下
ARTrack-main/output/checkpoints/train/artrack_seq/artrack_seq_256_full/ARTrackSeq_ep0060.pth.tar创建encoder的预训练模型路径,并把预训练模型放入这里,在yaml文件中进行更改,并且源脚本文件 artrack_seq.py中也需要更改
mkdir pretrained_model
#
mae_pretrain_vit_base.pth 文件名
# artrack_seq_256_full.yaml 中用绝对路径改写
PRETRAIN_PTH: "/root/data/zjx/Code-subject/ARTrack/ARTrack-main/pretrained_models"
# 同时将artrack_seq.py --100 中的
load_from = cfg.MODEL.PRETRAIN_PTH
# 改为
load_from = cfg.MODEL.PRETRAIN_PTH +'/' + cfg.MODEL.PRETRAIN_FILE
#同时将 artrack_seq.py -- 103 中的
missing_keys, unexpected_keys = model.load_state_dict(checkpoint["net"], strict=False)
# 改为
missing_keys, unexpected_keys = model.load_state_dict(checkpoint["model"], strict=False)代码中没有实现 run video 的脚本,这里需要自定义一个脚本实现
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
import os
import random
import argparse
import multiprocessing
import cv2
import torch
import torch.nn as nn
import numpy as np
from glob import glob
from lib.test.evaluation.tracker import Tracker
import sys
prj_path = os.path.join(os.path.dirname(__file__), '..')
if prj_path not in sys.path:
sys.path.append(prj_path)
torch.set_num_threads(1)
parser = argparse.ArgumentParser(description='Run tracker on sequence or dataset.')
parser.add_argument('tracker_name', type=str, help='Name of tracking method.')
parser.add_argument('tracker_param', type=str, help='Name of config file.')
parser.add_argument('--runid', type=int, default=None, help='The run id.')
parser.add_argument('--video_path', type=str, default='None', help='Name of dataset (otb, nfs, uav, tpl, vot, tn, gott, gotv, lasot).')
parser.add_argument('--sequence', type=str, default=None, help='Sequence number or name.')
parser.add_argument('--debug', type=int, default=0, help='Debug level.')
parser.add_argument('--threads', type=int, default=0, help='Number of threads.')
parser.add_argument('--num_gpus', type=int, default=8)
args = parser.parse_args()
def main(): # 这里已经是图片了
colors = [random.randint(0, 255) for _ in range(3)]
print('[INFO] Loading the model')
# load config
trackers = Tracker(args.tracker_name, args.tracker_param, None, args.runid)
try:
worker_name = multiprocessing.current_process().name
worker_id = int(worker_name[worker_name.find('-') + 1:]) - 1
gpu_id = worker_id % args.num_gpus
torch.cuda.set_device(gpu_id)
except:
pass
trackers.run_video(args.video_path, None, None, None, False)
if __name__=='__main__':
main()
执行
python tracking/run_video.py artrack_seq artrack_seq_256_full --video_path /root/data/zjx/Code-subject/OSTrack-main/experiments/video/soccer1.avi 前向传播过程
裁剪模板区域和OSTrack代码一样,初始化的时候,为需要保留的N帧的bbox的坐标信息创建了一个buffer--self.store_result,初始化时全为 init bbox,N的值此时设置为7
for i in range(self.save_all - 1):
self.store_result.append(info['init_bbox'].copy())搜索区域的裁剪和OSTrack的一样。将之前帧的坐标进行变换,? 以前一帧预测的坐标为参考点计算相对坐标,因为当前帧的裁剪的搜索区域的就是以上一帧预测的bbox为中心进行裁剪的,所以搜索区域的中心实则是前一帧预测的bbox的中心。只不过前一帧预测的bbox为原img的尺度,而搜索区域为crop size上的尺度,因此,只需要将计算原img尺度上的也就是之前帧的预测的坐标与前一帧预测的坐标的相对坐标,再乘以resize factor就可以将相对坐标转换到crop size 的尺度下。并且,前一帧的预测的bbox转换实则移到了搜索区域的中心点,也就是 (crop_size/2, crop_ size/2)。?
转换后除以 crop size 进行了归一化,不过这里有可能会 小于0 或者 大于 1,因为坐标变换可能会超出边界。接下来将xywh转换成 xyxy 形式,并筛选只保留(-0.5,1.5)区间的。然后对坐标进行量化。加上0.5 为了防止 出现负数,最终将bbox量化到 2*(bins-1)之间。最终,包含时空上下文信息的坐标输入为
seqs_out = seqs_out.unsqueeze(0) # (1,28)将 模板 和 搜索区域送入 ViT backbone中进行特征提取,这个过程中一共 16倍 下采样。然后将 提取的 sequence patch、以及位置编码、外加之前转换后的之前帧的bbox的信息 送入 接下来的Transformer中。
首先进入一个 encoder,在FeatureFusionEncoder类中进行一些预处理,主要的基本模块是 FeatureFusion 模块。这个encoder的主要过程如下所示,最终返回 z 和 x 一样shape的特征 patch。
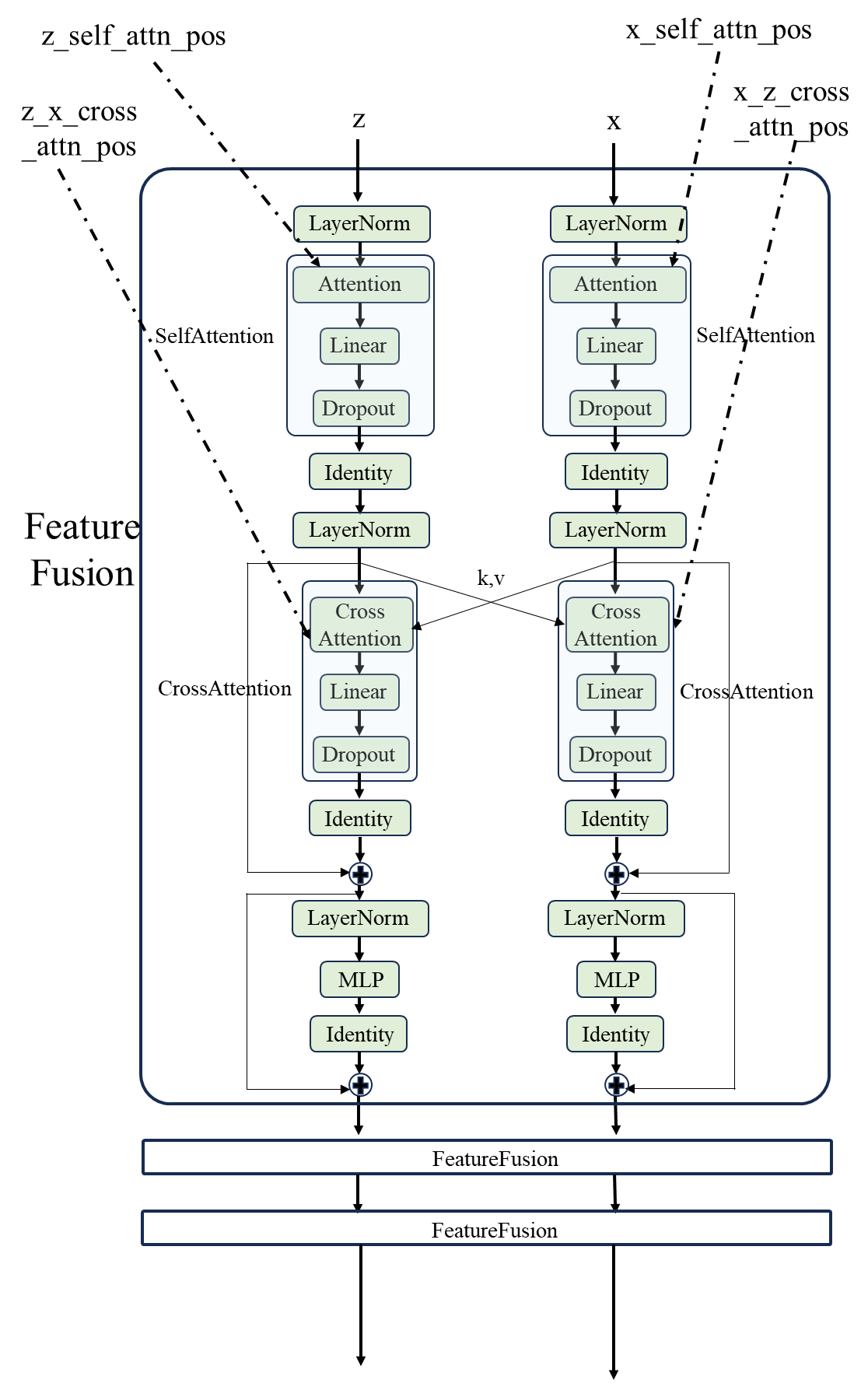
接下来?,将 之前帧的 bbox 坐标序列以及开始标志拼接在一起,作为decoder的输入 sequence。因为只需要预测bbox的坐标,所以不需要额外的结束标志,输出的序列长度直接为4即可。
1、 将输入的sequence 进行词汇嵌入,词向量的长度是crop img 下采样得到的特征patch的分辨率
2、 将初始输入tgt、模板特征、搜索特征、patch z的位置编码、 x patch的位置编码、identity高斯截断分布、高斯截断分布、查询嵌入、输入序列的掩码 送入decoder?decoder主要由TargetQueryDecoderLayer层组成。该模块的前向过程如下所示,一共有6层
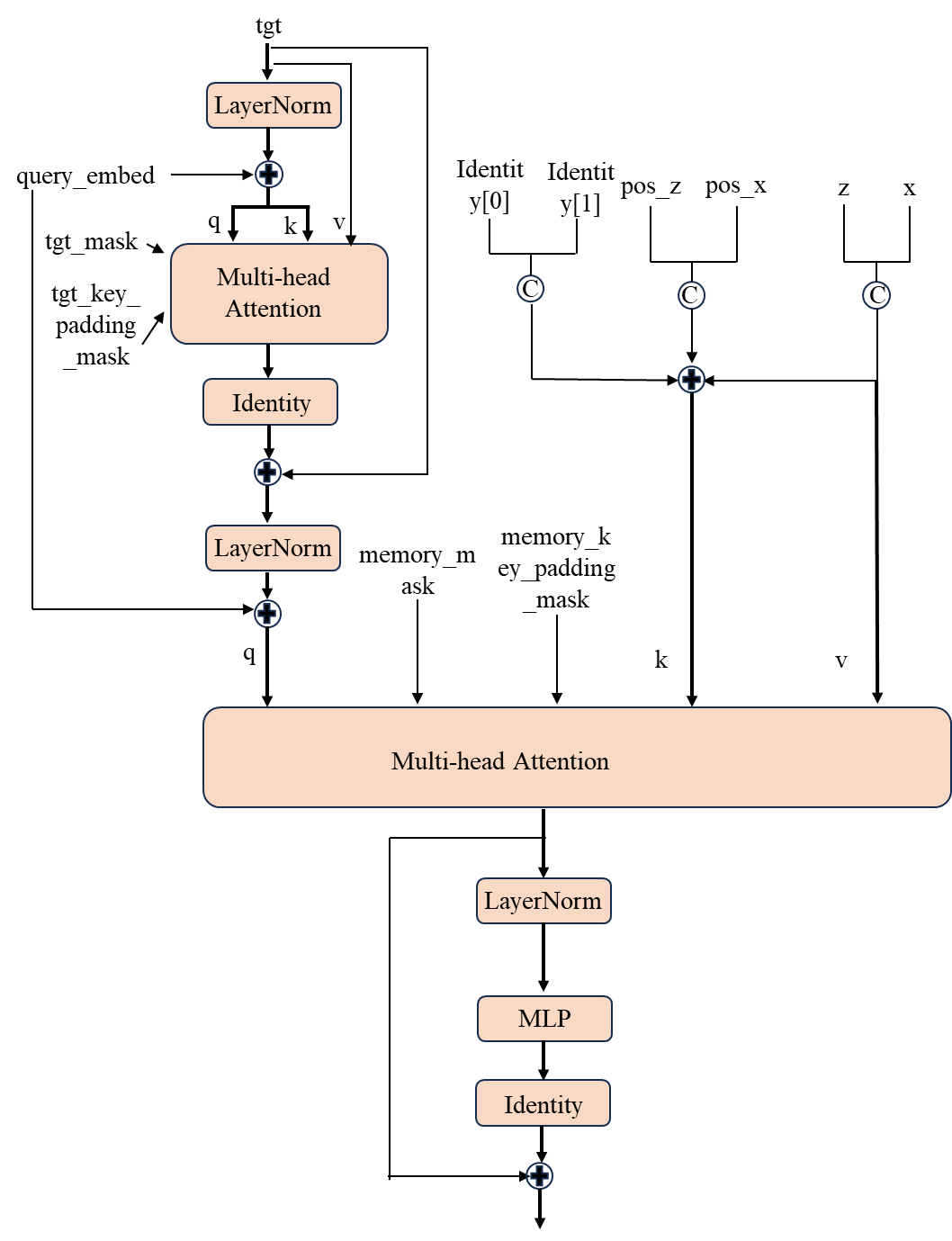
最终输出和 tgt shape一样的token sequence。得到的输出的shape为(1,length,768),这个length为tgt的长度,随sequence的预测而逐渐增加。接下来,
1、 拿出得到的 query的 最后一个单词嵌入,并与词向量的权重矩阵进行矩阵乘法,得到与每个位置量化后的相关联的预测值。
2、 取softmax,得到关于量化后的坐标的概率分布。
3、 采用argmax sampleing,也就是看最大概率的位置。
4、 将当前预测的量化后的坐标加入到 tgt当中,执行循环。
5、 最终得到预测的bbox的量化坐标。
得到网络的输出预测后,
1、 bbox坐标反量化
2、 xyxy 转为 xywh 中心点加长宽
3、 尺度返回到原img, 转成 xywh, 左顶点加长宽
4、 平滑处理,去掉bbox超出图片的部分
5、 对于之前保存的坐标信息,将最靠前的弹出去,在最靠后的也就是前一帧的坐标加入当前预测的。好比出栈入栈操作。?
网络结构
ARTrackSeq(
(backbone): VisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(blocks): Sequential(
(0): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): Identity()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(3): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(4): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(5): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(6): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(7): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(8): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(9): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(10): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(11): Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(drop1): Dropout(p=0.0, inplace=False)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
)
(norm): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)
(pix_head): Pix2Track(
(word_embeddings): Embedding(802, 768, padding_idx=800, max_norm=1)
(position_embeddings): Embedding(5, 768)
(prev_position_embeddings): Embedding(28, 768)
(encoder): FeatureFusionEncoder(
(layers): ModuleList(
(0): FeatureFusion(
(z_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_x_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_z_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(x_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(1): FeatureFusion(
(z_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_x_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_z_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(x_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(2): FeatureFusion(
(z_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_self_attn): SelfAttention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm2_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_x_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(x_z_cross_attention): CrossAttention(
(q): Linear(in_features=768, out_features=768, bias=True)
(kv): Linear(in_features=768, out_features=1536, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.1, inplace=False)
)
(z_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(x_norm3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(z_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(x_mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
)
(z_pos_enc): Untied2DPositionalEncoder(
(pos): Learned2DPositionalEncoder()
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(pos_q_linear): Linear(in_features=768, out_features=768, bias=True)
(pos_k_linear): Linear(in_features=768, out_features=768, bias=True)
)
(x_pos_enc): Untied2DPositionalEncoder(
(pos): Learned2DPositionalEncoder()
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(pos_q_linear): Linear(in_features=768, out_features=768, bias=True)
(pos_k_linear): Linear(in_features=768, out_features=768, bias=True)
)
(z_rel_pos_bias_table): RelativePosition2DEncoder()
(x_rel_pos_bias_table): RelativePosition2DEncoder()
(z_x_rel_pos_bias_table): RelativePosition2DEncoder()
(x_z_rel_pos_bias_table): RelativePosition2DEncoder()
)
(decoder): TargetQueryDecoderBlock(
(layers): ModuleList(
(0): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(1): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(2): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(3): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(4): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
(5): TargetQueryDecoderLayer(
(norm_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attn1): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_2_query): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(norm_2_memory): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(norm_3): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlpz): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(drop_path): Identity()
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!