浅淡A100-4090-性价比
大模型的训练用 4090 是不行的,但推理(inference/serving)用 4090 不仅可行,在性价比上还能比 H100 稍高。4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
--------------------
- FP64(双精度浮点)性能: 这是区分游戏卡和计算卡的关键因素之一。在科学计算和某些高精度要求的AI应用中,FP64的性能非常重要。游戏显卡(如RTX 4090)通常在这一点上性能较弱,因为游戏通常不需要双精度计算。
- 关于A100/H100的不同版本: 您正确指出,这些GPU存在不同的版本,具有不同的内存容量(如96GB, 80GB, 40GB等)。这些不同的版本对于特定的应用场景(如大模型训练和推理)意味着不同的性能和适用性。
- BF16和FP16: BFloat16(BF16)是一种浮点格式,它在AI计算中越来越流行,因为它在精度和性能之间提供了一个良好的平衡。而FP16(半精度)则是另一种常见的低精度浮点格式。这两种格式在AI应用中都很重要,尤其是在模型训练中。
- FP32和FP16性能: 根据您提供的数据,RTX 4090在FP16和FP32上的性能相同,都是82.58 Tflops,而其FP64性能则显著较低。这表明它更适合于不需要高精度计算的应用。而H100在FP16上的性能为248.3 Tflops,在FP32上为62 Tflops,FP64性能为31.04 Tflops,这显示了它在更高精度计算上的优势。
- RTX 4090与A100的FP16性能比较:
- 根据之前的讨论,RTX 4090的FP16性能约为82.58 Tflops,而A100的FP16性能可达约312 Tflops。不过,您引用的评论者“王一”提到,实际使用中4090的FP16性能接近于A100。这可能是因为不同的测试条件和使用场景会影响性能测量,或者由于不同的硬件版本和配置。
- 从理论规格上看,A100确实在FP16上显示出更高的性能,但实际应用性能可能会有所不同,取决于具体任务和软件优化。
- 大型机房环境下的成本考虑:
- 评论者“Crear”提到的成本分析观点非常重要。在评估GPU在数据中心的总成本时,不能仅仅考虑硬件和电费。还需要考虑机房空间、冷却系统、维护成本、硬件的可靠性和寿命等因素。
- 例如,尽管A100/H100的硬件成本可能更高,但它们可能在机房空间利用效率、耗电效率、维护需求和稳定性方面具有优势。这些因素在大规模部署时尤其重要。
- 交换机和存储成本也是重要的考虑因素,特别是在涉及到高速网络通信和大数据量存储的AI应用中
以上这些信息对于理解不同GPU的性能特点和适用场景至关重要。再次感谢您提供这些详细且关键的技术数据。在讨论GPU性能时,确保数据的准确性非常重要,尤其是在为特定的计算任务选择合适的硬件时。
------------------------------
其实 GPT-3.5 Turbo 的 $0.002 / 1K tokens 真的挺良心的,有的卖 API 的,LLaMA-2 70B 都敢比 GPT-3.5 Turbo 卖得贵。
如果换成用 H100 做推理,重新算一下这笔账。一张 H100 至少要 3 万美金,一台 8 卡 H100 高配服务器加上配套的 IB 网络,起码要 30 万美金,同样按照 3 年摊销,每小时 11.4 美元。10 kW 功耗,电费每小时 1 美元。一个普通供电和散热的机架只能放 2 台 8 卡 H100,机柜租用成本(不含电费)还按 1500 美元算,合每小时 1 美元。一共 13.4 美元一小时。
论文 ["Reducing Activation Recomputation" ](2205.05198.pdf (arxiv.org))中,计算过程涉及的公式 "token 长度 \* batch size \* hidden layer 的神经元数量 \* 层数 \* (10 + 24/张量并行度)" 是用来估算正向传播过程中需要的内存空间。
这个公式的每部分代表的含义是:
- token 长度:这是输入序列中的token的数量。
- batch size:这是在单次训练/推理过程中同时处理的数据样本数量。
- hidden layer 的神经元数量:这是每个隐藏层中神经元的数量。
- 层数:这是神经网络中的层数。
- (10 + 24/张量并行度):这部分是公式中比较复杂的部分,它代表每个神经元为正向传播存储中间状态所需的字节数。
特别是,"(10 + 24/张量并行度)" 这部分可能是指:
- 10字节:可能是估算每个神经元基础内存需求的经验值。这可能包括神经元的激活值和其他必要的辅助信息。
- 24/张量并行度:这表明当使用张量并行时,每个神经元的内存需求会减少。张量并行会将模型的一部分分配到多个处理单元(如GPU)上,因此每个单元只需存储一部分模型的中间状态。这里的“24”可能是一个针对特定模型或层类型的估算值,表明在没有张量并行的情况下每个神经元需要额外的24字节。随着张量并行度的增加,每个处理单元需要的额外存储量会减少。
这个公式提供了一个估算正向传播中内存需求的方法,特别是在大型模型和复杂网络结构中非常有用。不过,具体的数字可能会根据模型的结构和实现方式有所不同。
公式 "token 长度 * batch size * hidden layer 的神经元数量 * 层数 * (10 + 24/张量并行度)" 用于估算深度学习模型在正向传播过程中对内存的需求。这个计算结果代表正向传播中需要为存储中间状态(activations)分配的总内存量。
让我们通过一个假设的示例来演示这个公式的计算结果。假设我们有以下参数:
- Token 长度: 512
- Batch size: 8
- Hidden layer 的神经元数量: 2048(这是一个典型的隐藏层大小)
- 层数: 12(例如,一个较小的Transformer模型)
- 张量并行度: 1(假设没有使用张量并行)
代入公式,计算过程如下:
内存需求 = token 长度 * batch size * hidden layer 的神经元数量 * 层数 * (10 + 24/张量并行度)
= 512 * 8 * 2048 * 12 * (10 + 24/1)
= 512 * 8 * 2048 * 12 * 34
= 1073741824 字节
= 1024 MB
= 1 GB
因此,根据这个公式和给定的假设参数,模型的正向传播过程大约需要1GB的内存来存储中间状态。这个计算结果可以帮助我们了解特定配置的深度学习模型在训练时对硬件资源的需求。实际应用中,这个数值可能会有所不同,具体取决于模型的具体结构和实现方式
当然 还有这些信息可以参考[URL](https://xba0xp0y90.feishu.cn/sheets/NMVls7iMGhfyDGt7zpecOzDdnSd?from=from_copylink):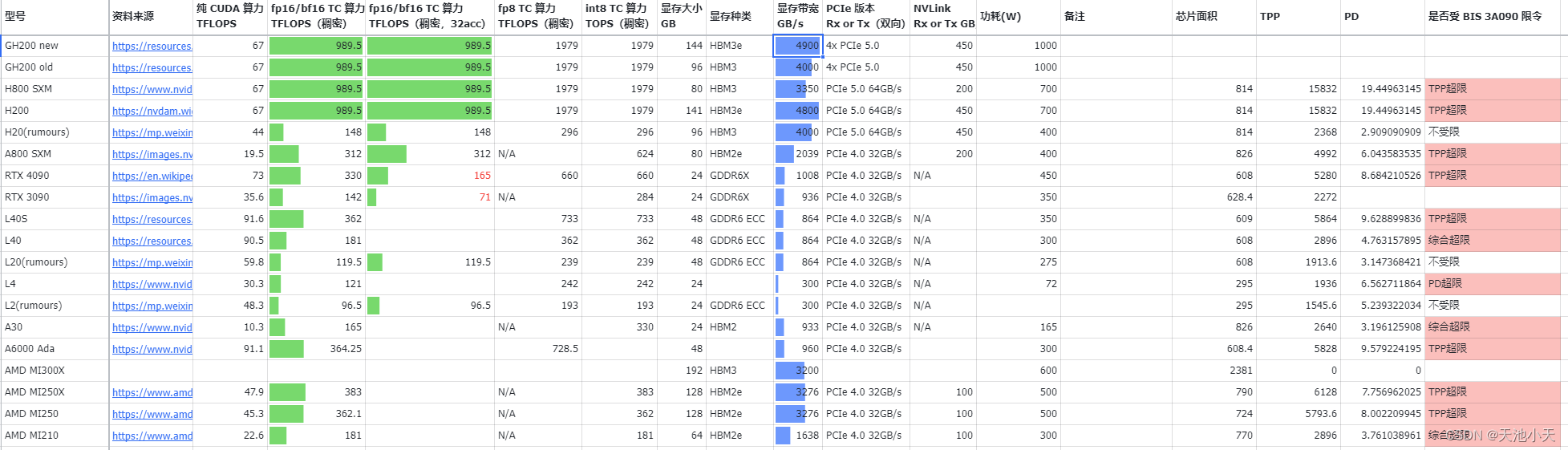
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!