base zhixi mode, redo example on local standyalone PC
?
ref url:
https://modelscope.cn/models/ZJUNLP/DeepKE-LLM/summary
Linux增大Swap分区,增加虚拟内存,以解决内存不足等问题_增大swapfile能缓解内存不足吗-CSDN博客
Add Local visual RAM 100G:
##增加虚拟内存
mkdir /data/VisualRAM
cd VisualRAM
dd if=/dev/zero of=swapfile bs=1G count=100
sudo chmod 600 swapfile
mkswap swapfile
sudo swapon swapfile?add to linux restart config for auto upload device:
sudo gedit /etc/fstab
/data/VisualRAM$/swapfile none swap defaults 0 0
sudo swapon --showDownload llama13b huggingface model:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('skyline2006/llama-13b',cache_dir='/YourModelCatchDir')Download zhixi diff 16pf:
python tools/download.py --download_path ./zhixi-diff-fp16 --only_base --fp16merge llama 13b base to zhixi diff 16pf:
first modify tools/weight_diff.py , goto line 107 nearly,? comment a few lines,like this:
if check_integrity_naively:
# This is not a rigorous, cryptographically strong integrity check :)
allsum = sum(state_dict_recovered[key].sum() for key in state_dict_recovered)
print("allsum={0}, code check number is 94052.2891 or 94046.1875".format(allsum))
# comment below codes::
# assert torch.allclose(
# allsum, torch.full_like(allsum, fill_value=94052.2891 if not is_fp16 else 94046.1875), atol=1e-2, rtol=0
# ), "Naive integrity check failed. This could imply that some of the checkpoint files are corrupted."
second: run code below
python tools/weight_diff.py recover --path_raw ./skyline2006/llama-13b --path_diff ./zhixi-diff-fp16 --path_tuned ./zhixi --is_fp16 TrueNow , all works is ready ,? begin run example:
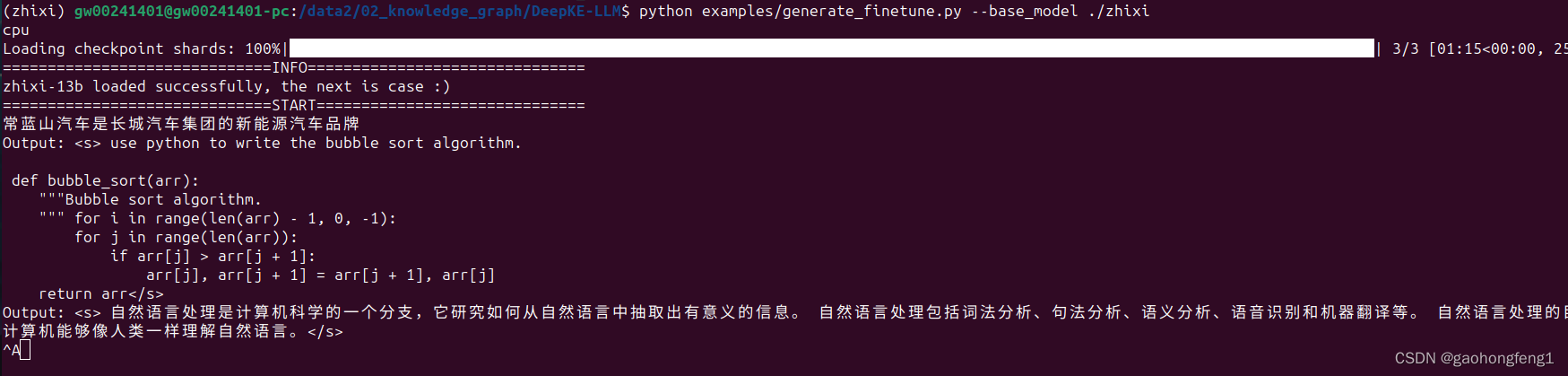
fix bug:
python examples/generate_finetune.py --base_model ./zhixi?error:
│????????????????????????????????????????????????????????????????????????????????????????????????? │
│ /home/gw00241401/anaconda3/envs/zhixi/lib/python3.9/site-packages/torch/nn/modules/linear.py:114 │
│ in forward?????????????????????????????????????????????????????????????????????????????????????? │
│????????????????????????????????????????????????????????????????????????????????????????????????? │
│?? 111 │?? │?? │?? init.uniform_(self.bias, -bound, bound)??????????????????????????????????????? │
│?? 112 │????????????????????????????????????????????????????????????????????????????????????????? │
│?? 113 │?? def forward(self, input: Tensor) -> Tensor:??????????????????????????????????????????? │
│ ? 114 │?? │?? return F.linear(input, self.weight, self.bias)???????????????????????????????????? │
│?? 115 │????????????????????????????????????????????????????????????????????????????????????????? │
│?? 116 │?? def extra_repr(self) -> str:?????????????????????????????????????????????????????????? │
│?? 117 │?? │?? return f'in_features={self.in_features}, out_features={self.out_features}, bias=?? │
╰──────────────────────────────────────────────────────────────────────────────────────────────────╯
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'
fix method:
1.modify? examples/generate_finetune.py
goto about 90 line,like this is ok
if not load_8bit:
if device == "cpu":
model.float()
else:
model.half() Error2:
OutOfMemoryError: CUDA out of memory. Tried to allocate 314.00 MiB. GPU 0 has a total capacty of 7.78 GiB of which 260.06 MiB is free. Including non-PyTorch memory, this process has
6.96 GiB memory in use. Of the allocated memory 6.49 GiB is allocated by PyTorch, and 360.60 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large
try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
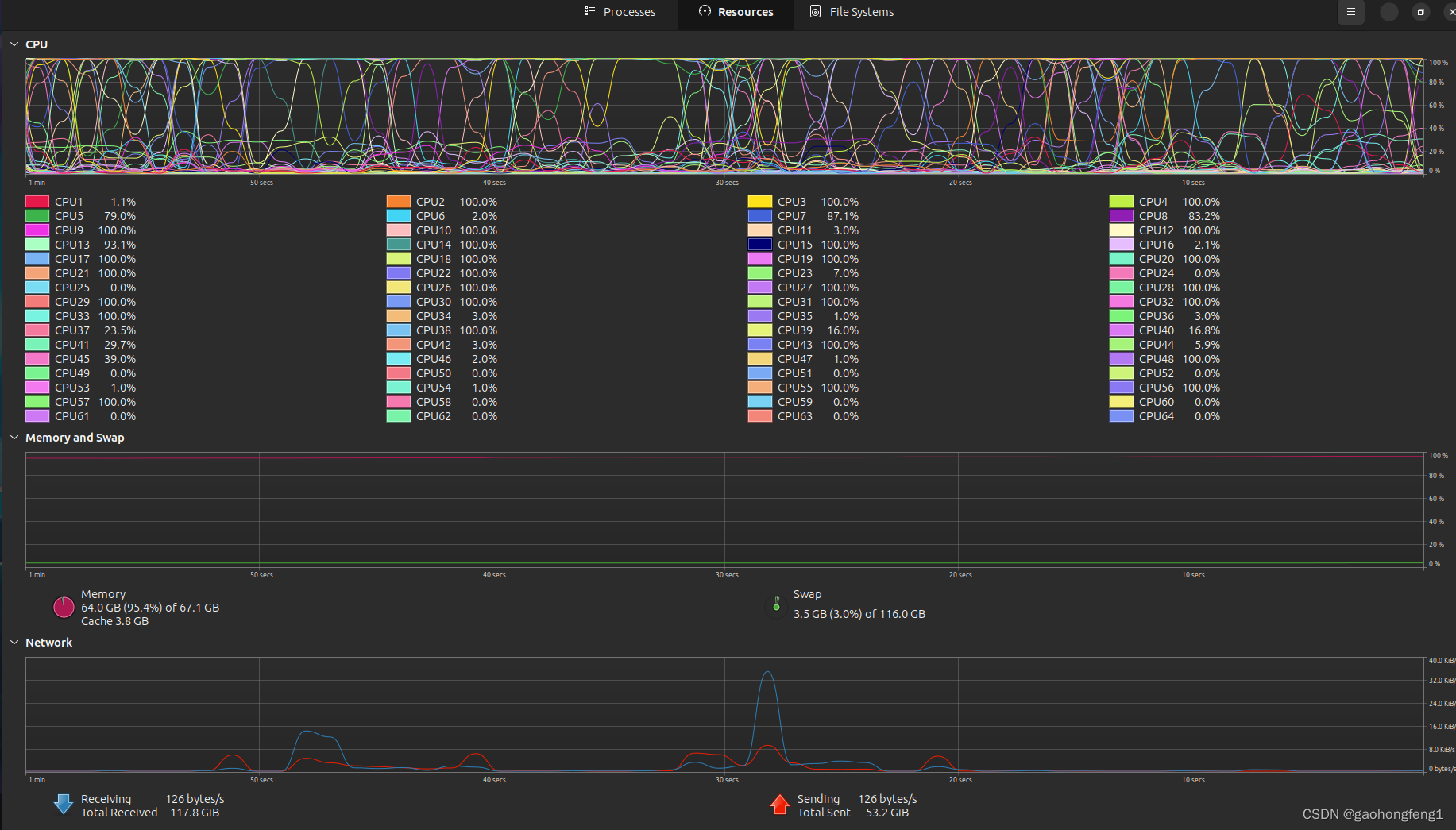
because your GPU is not enough!? go to set CPU run model
for me ,like to du? this:
modify examples/generate_fune.py, goto line 10 about, simply added code at last line
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
##added
device = "cpu"本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!