FCN(pytorch)
2023-12-17 04:54:26
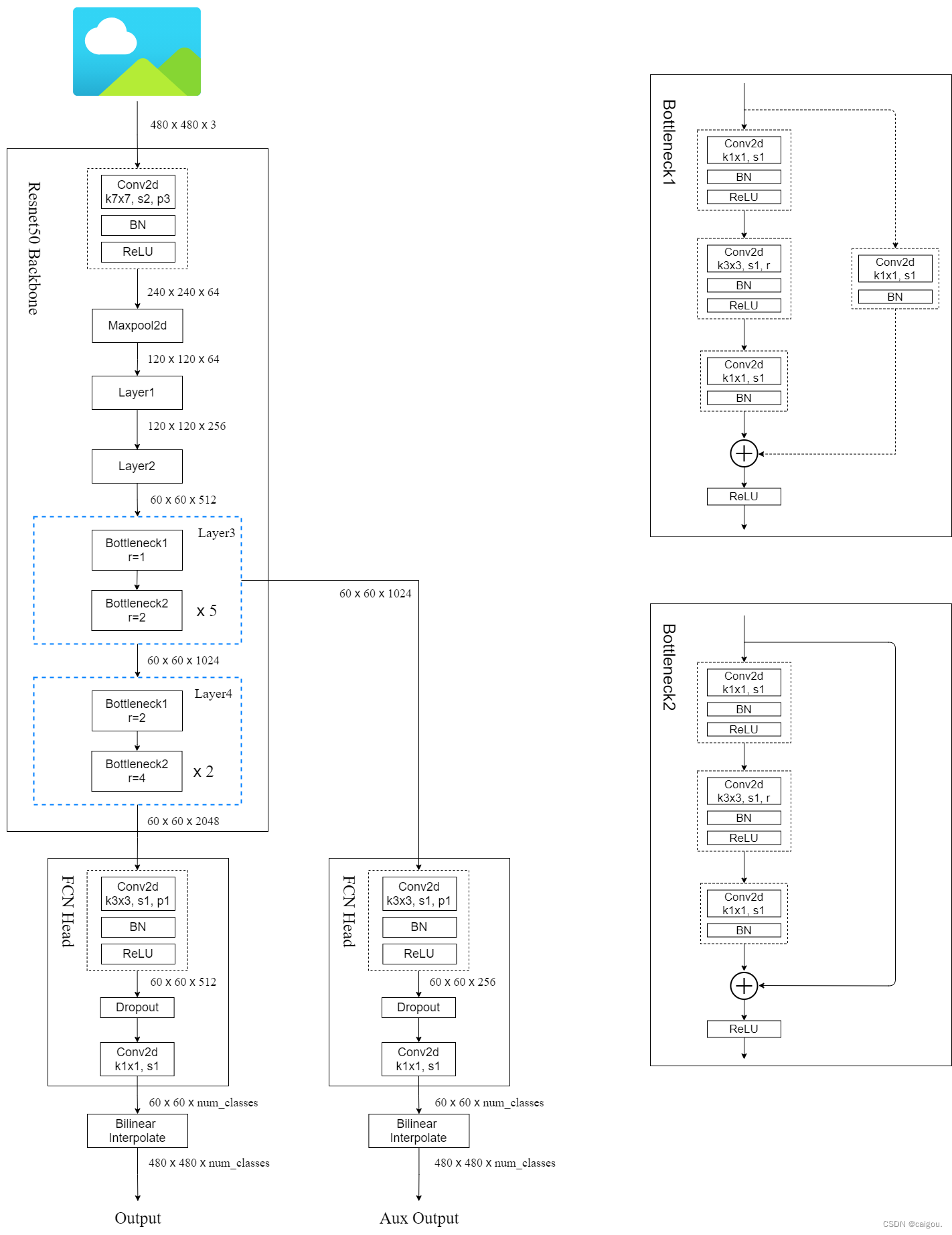
backbon.py
import torch
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
# 引入replace_stride_with_dilation参数,传入的含有replace_stride_with_dilation参数的列表会用膨胀卷积
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
# layer3,4不下采样,改stride为1
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(block, layers, **kwargs):
model = ResNet(block, layers, **kwargs)
return model
def resnet50(**kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 6, 3], **kwargs)
def resnet101(**kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet(Bottleneck, [3, 4, 23, 3], **kwargs)
fcn-model.py
from collections import OrderedDict
from typing import Dict
import torch
from torch import nn, Tensor
from torch.nn import functional as F
from .backbone import resnet50, resnet101
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model
It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work.
Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
}
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()}
# 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break
super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers
def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
class FCN(nn.Module):
"""
Implements a Fully-Convolutional Network for semantic segmentation.
Args:
backbone (nn.Module): the network used to compute the features for the model.
The backbone should return an OrderedDict[Tensor], with the key being
"out" for the last feature map used, and "aux" if an auxiliary classifier
is used.
classifier (nn.Module): module that takes the "out" element returned from
the backbone and returns a dense prediction.
aux_classifier (nn.Module, optional): auxiliary classifier used during training
"""
__constants__ = ['aux_classifier']
def __init__(self, backbone, classifier, aux_classifier=None):
super(FCN, self).__init__()
self.backbone = backbone
self.classifier = classifier
self.aux_classifier = aux_classifier
def forward(self, x: Tensor) -> Dict[str, Tensor]:
# 取高宽
input_shape = x.shape[-2:]
# contract: features is a dict of tensors
features = self.backbone(x)
result = OrderedDict()
# 提取出键为out的layer4的输出
x = features["out"]
# 输出到主分类器
x = self.classifier(x)
# 原论文中虽然使用的是ConvTranspose2d,但权重是冻结的,所以就是一个bilinear插值
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["out"] = x
if self.aux_classifier is not None:
x = features["aux"]
x = self.aux_classifier(x)
# 原论文中虽然使用的是ConvTranspose2d,但权重是冻结的,所以就是一个bilinear插值
x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)
result["aux"] = x
return result
class FCNHead(nn.Sequential):
def __init__(self, in_channels, channels):
inter_channels = in_channels // 4
layers = [
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(inter_channels),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(inter_channels, channels, 1)
]
super(FCNHead, self).__init__(*layers)
def fcn_resnet50(aux, num_classes=21, pretrain_backbone=False):
# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'
# 'fcn_resnet50_coco': 'https://download.pytorch.org/models/fcn_resnet50_coco-1167a1af.pth'
# 列表三个元素对应layer2,layer3,layer4
backbone = resnet50(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet50 backbone预训练权重
backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
# IntermediateLayerGetter 看是否有辅助分类器,重构backbone
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = FCNHead(out_inplanes, num_classes)
# 把backbone,主分类器,辅助分类器传入FCN,构建模型model
model = FCN(backbone, classifier, aux_classifier)
return model
def fcn_resnet101(aux, num_classes=21, pretrain_backbone=False):
# 'resnet101_imagenet': 'https://download.pytorch.org/models/resnet101-63fe2227.pth'
# 'fcn_resnet101_coco': 'https://download.pytorch.org/models/fcn_resnet101_coco-7ecb50ca.pth'
backbone = resnet101(replace_stride_with_dilation=[False, True, True])
if pretrain_backbone:
# 载入resnet101 backbone预训练权重
backbone.load_state_dict(torch.load("resnet101.pth", map_location='cpu'))
out_inplanes = 2048
aux_inplanes = 1024
return_layers = {'layer4': 'out'}
if aux:
return_layers['layer3'] = 'aux'
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
aux_classifier = None
# why using aux: https://github.com/pytorch/vision/issues/4292
if aux:
aux_classifier = FCNHead(aux_inplanes, num_classes)
classifier = FCNHead(out_inplanes, num_classes)
#
model = FCN(backbone, classifier, aux_classifier)
return model
distributed.py
from collections import defaultdict, deque
import datetime
import time
import torch
import torch.distributed as dist
import errno
import os
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{value:.4f} ({global_avg:.4f})"
# deque是一个双向队列,它支持线程安全、有效内存地以近似O(1)的性能在deque的两端插入和删除元素3。
# deque的最大长度可以通过maxlen参数进行设定。当新的元素加入并且这个队列已满的时候,最老的元素会自动被移除掉
self.deque = deque(maxlen=window_size)
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
# total记录一个总的记录,在这个代码中打印频率是10,队列长度应该是10,每记录十次就开始队列抛出元素
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self):
d = torch.tensor(list(self.deque))
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
class ConfusionMatrix(object):
def __init__(self, num_classes):
self.num_classes = num_classes
self.mat = None
def update(self, a, b):
n = self.num_classes
if self.mat is None:
# 创建混淆矩阵
self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)
with torch.no_grad():
# 寻找GT中为目标的像素索引
k = (a >= 0) & (a < n)
# 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)
inds = n * a[k].to(torch.int64) + b[k]
self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)
def reset(self):
if self.mat is not None:
self.mat.zero_()
def compute(self):
h = self.mat.float()
# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
acc_global = torch.diag(h).sum() / h.sum()
# 计算每个类别的准确率
acc = torch.diag(h) / h.sum(1)
# 计算每个类别预测与真实目标的iou
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
return acc_global, acc, iu
def reduce_from_all_processes(self):
if not torch.distributed.is_available():
return
if not torch.distributed.is_initialized():
return
torch.distributed.barrier()
torch.distributed.all_reduce(self.mat)
def __str__(self):
acc_global, acc, iu = self.compute()
return (
'global correct: {:.1f}\n'
'average row correct: {}\n'
'IoU: {}\n'
'mean IoU: {:.1f}').format(
acc_global.item() * 100,
['{:.1f}'.format(i) for i in (acc * 100).tolist()],
['{:.1f}'.format(i) for i in (iu * 100).tolist()],
iu.mean().item() * 100)
class MetricLogger(object):
def __init__(self, delimiter="\t"):
# metric是度量的意思,Logger是记录,日志的意思,delimiter是定界符的意思
# defaultdict是默认字典的意思
# 类的构造函数,用于初始化 MetricLogger 对象。
# delimiter 参数指定指标之间的分隔符,默认为制表符 \t。
# 这段代码的目的是在当前对象上创建一个名为meters的属性,该属性是一个defaultdict,其默认值是SmoothedValue类的一个实例,用于存储和处理数据
# 这个meters是一个字典,记录了一系列名称和损失,每个名称和对应的记录值是SmoothedValue类型
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
# 更新指标值的方法。接受关键字参数 kwargs,其中键是指标名称,值是对应的指标值。
# 指标值可以是整数或浮点数,也可以是 PyTorch 的张量(torch.Tensor)。
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
# 属性访问方法,用于动态获取指标值的属性。如果属性名存在于 meters 字典中,则返回对应的 SmoothedValue 对象;
# 如果属性名存在于类的字典中,则返回对应的属性值;否则引发 AttributeError。
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
# 将 MetricLogger 对象转换为字符串的方法。将每个指标的名称和对应的 SmoothedValue 对象转换为字符串,并使用分隔符连接起来。
loss_str = []
for name, meter in self.meters.items():
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
# synchronize 是同步的意思
# synchronize_between_processes(self):在多进程训练中进行指标同步的方法。
# 遍历所有指标的 SmoothedValue 对象,并调用其 synchronize_between_processes 方法。
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
# 添加自定义指标的方法。将指标名称和对应的 SmoothedValue 对象添加到 meters 字典中。
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None):
# iterable是传入的迭代器,这里是DataLoader,
# 在迭代过程中记录和打印指标信息的方法。
# 定义Metric类:Metric类负责计算训练或验证的某些重要指标值,如训练误差、验证误差、准确率等
# 定义训练或验证的循环过程:在每个epoch或batch结束时,记录指定的指标,并将结果打印出来
# log_every方法还可以通过设置log_freq参数来指定日志记录的间隔,比如log_freq=10表示每10步记录一次日志2。
#
# 这个方法的应用非常广泛,无论是在深度学习中的训练过程中,还是机器学习领域的各种实验中都可以使用log_every来记录一些重要的指标值。
i = 0
if not header:
header = ''
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
if torch.cuda.is_available():
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'
])
else:
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'
])
MB = 1024.0 * 1024.0
for obj in iterable:
# 遍历传入的迭代器
data_time.update(time.time() - end)
yield obj
iter_time.update(time.time() - end)
if i % print_freq == 0:
# 每print_freq打印一次
eta_seconds = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
if torch.cuda.is_available():
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('{} Total time: {}'.format(header, total_time_str))
def mkdir(path):
try:
os.makedirs(path)
except OSError as e:
if e.errno != errno.EEXIST:
raise
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()
def is_main_process():
return get_rank() == 0
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
elif hasattr(args, "rank"):
pass
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
setup_for_distributed(args.rank == 0)
文章来源:https://blog.csdn.net/m0_56294205/article/details/134988745
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!