Flink 本地单机/Standalone集群/YARN模式集群搭建
准备工作
本文简述Flink在Linux中安装步骤,和示例程序的运行。需要安装JDK1.8及以上版本。
下载地址:下载Flink的二进制包
点进去后,选择如下链接:

解压flink-1.10.1-bin-scala_2.12.tgz,我这里解压到soft目录
[root@hadoop1 softpackage]# tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C ../soft/
单节点安装
解压后进入Flink的bin目录执行如下脚本即可
[root@hadoop1 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop1.
Starting taskexecutor daemon on host hadoop1.
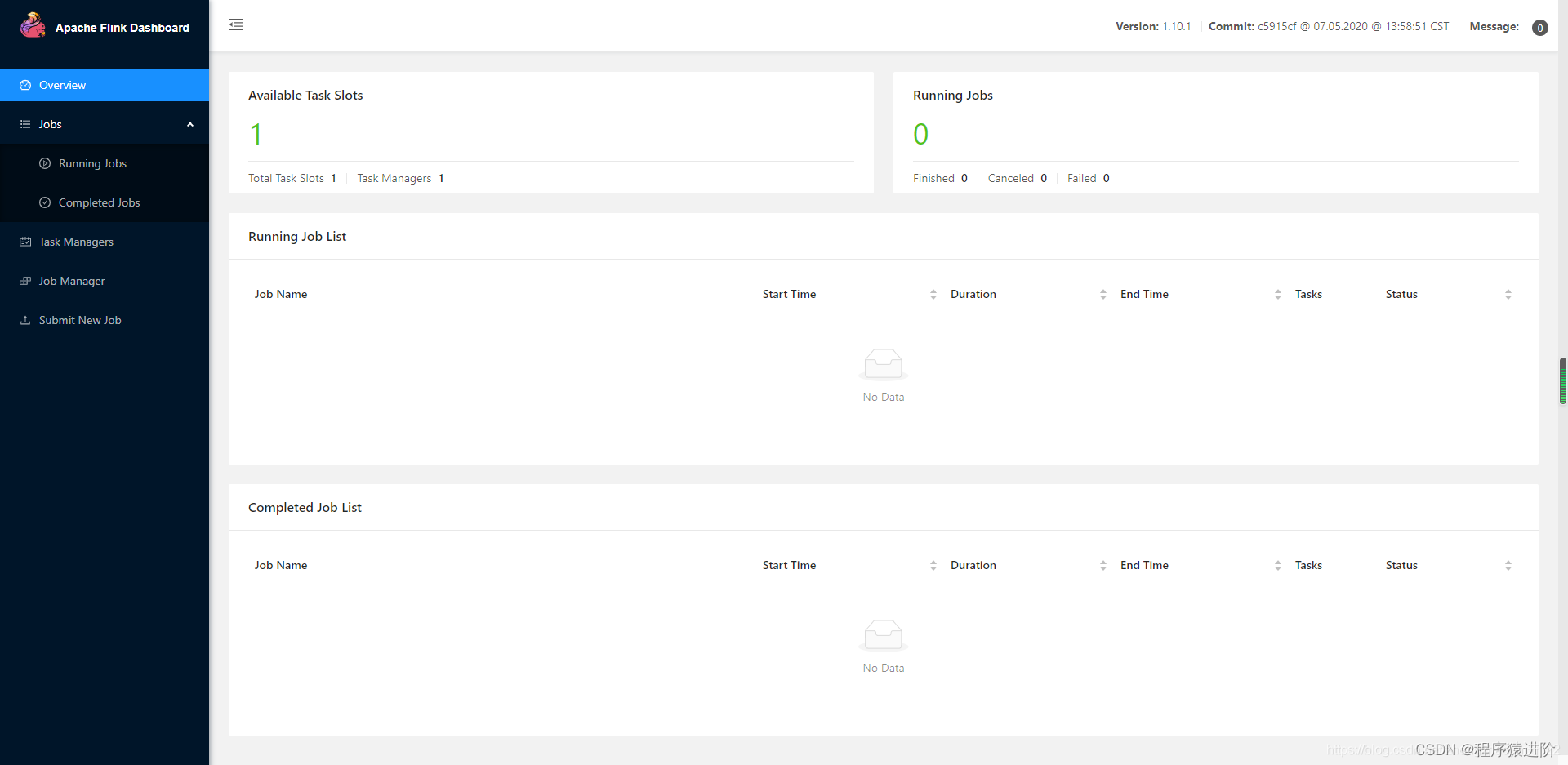
进入Flink页面看看,如果没有修改配置中的端口,默认是8081
 ## 集群安装
## 集群安装
集群安装分为以下几步:(注意:hadoopx都是我配置了/etc/hosts域名的)bin
【1】将hadoop1中解压的Flink分发到其他机器上,同时我也配置了免密登录SSH(也可以手动复制low)。
[root@hadoop1 soft]# xsync flink-1.10.1
执行完后,我们就可以在hadoop2和hadoop3中看到flink

【2】选择hadoop1作为master节点,然后修改所有机器conf/flink-conf.yaml(修改hadoop1分发即可)jobmanager.rpc.address密钥以指向您的主节点。您还应该通过设置jobmanager.heap.size和taskmanager.memory.process.size键来定义允许Flink在每个节点上分配的最大主内存量。这些值以MB为单位。如果某些工作节点有更多的主内存要分配给Flink系统,则可以通过在这些特定节点上设置 taskmanager.memory.process.size或taskmanager.memory.flink.size在conf / flink-conf.yaml中覆盖默认值。
jobmanager.rpc.address = master主机名
【3】修改master的conf/slaves提供集群中所有节点的列表,这些列表将用作工作节点。我的是hadoop2和hadoop3。类似于HDFS配置,编辑文件conf / slaves并输入每个辅助节点的IP /主机名。每个工作节点稍后都将运行TaskManager。
hadoop2
hadoop3
以上示例说明了具有三个节点(主机名hadoop1作为master,hadoop2和hadoop3作为worker)的设置,并显示了配置文件的内容。Flink目录必须在同一路径下的每个工作线程上都可用。您可以使用共享的NFS(网络文件系统)目录,也可以将整个Flink目录复制到每个工作节点。特别是:
1、每个JobManager的可用内存量jobmanager.heap.size;
2、每个TaskManager的可用内存量(taskmanager.memory.process.size并查看内存设置指南);
3、每台计算机可用的CPU数(taskmanager.numberOfTaskSlots);
4、集群中的CPU总数(parallelism.default);
5、临时目录(io.tmp.dirs);
【4】在master上启动集群(第一行)以及执行结果。下面的脚本在本地节点上启动JobManager,并通过SSH连接到slaves文件中列出的所有辅助节点,以在每个节点上启动TaskManager。现在,您的 Flink系统已启动并正在运行。现在,在本地节点上运行的JobManager将在配置的RPC端口上接受作业。要停止Flink,还有一个stop-cluster.sh脚本。
[root@hadoop1 flink-1.10.1]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop1.
Starting taskexecutor daemon on host hadoop2.
Starting taskexecutor daemon on host hadoop3.
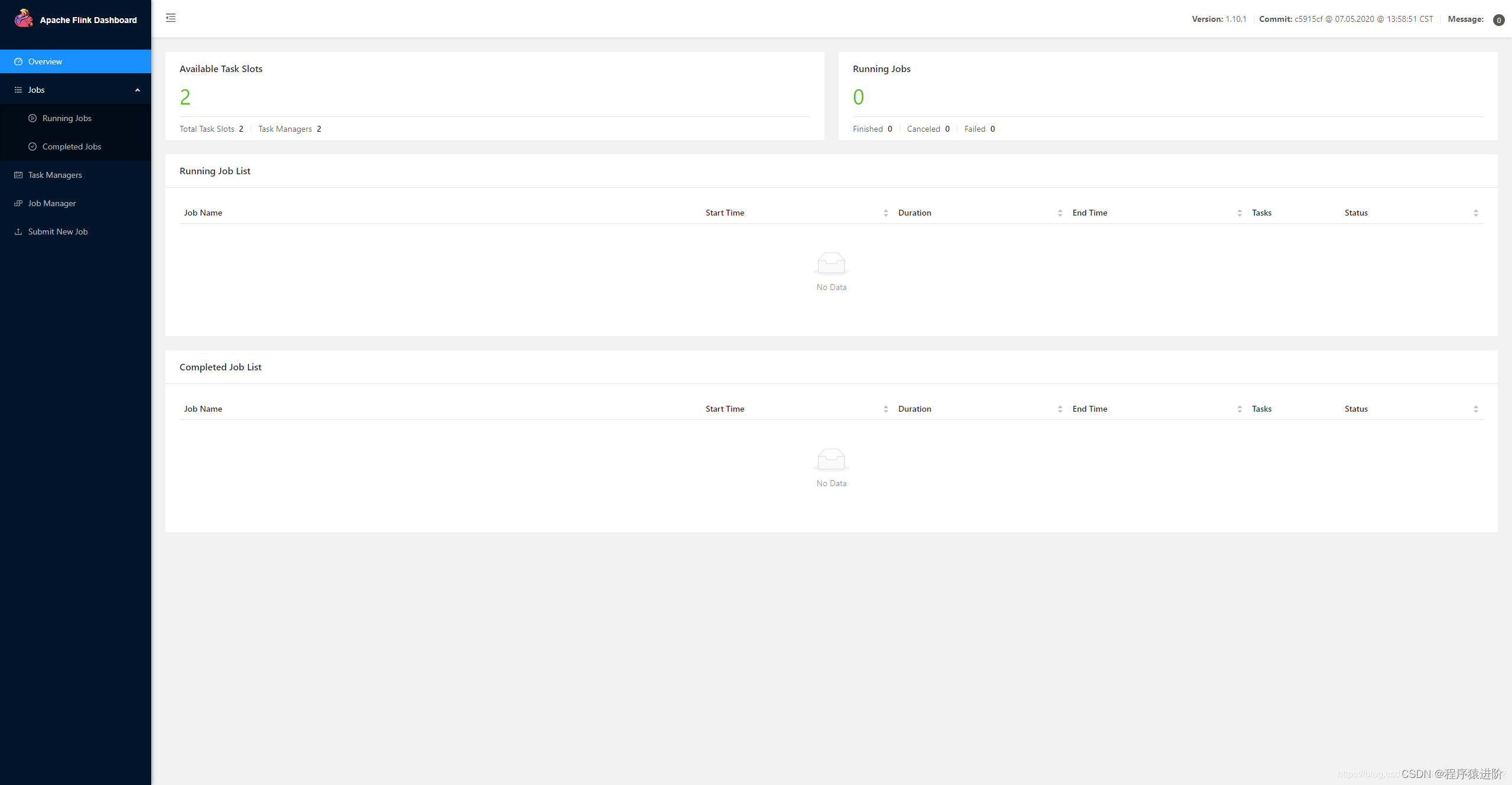
【5】Flink界面展示 :进入8081端口,例如:http://hadoop1:8081/ 或者通过jps命令查看服务也可行。
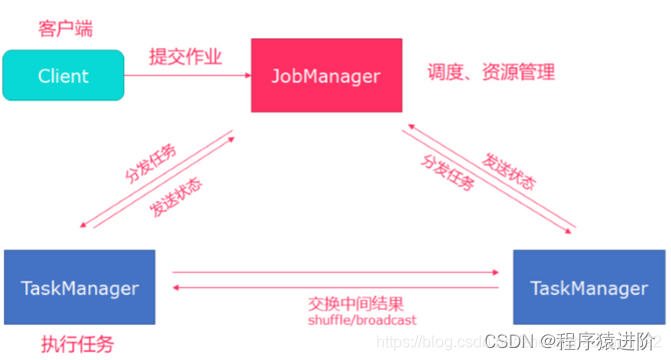
Standalone集群架构展示:client客户端提交任务给JobManager,JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行,TaskManager定期向JobManager汇报状态。
运行 flink示例程序
批处理示例:提交Flink的批处理examples程序:也可以在页面中进行提交,但是作为一名NB的程序员就使用命令
[root@hadoop1 flink-1.10.1]# bin/flink run examples/batch/WordCount.jar
执行上面的命令后,就会显示如下信息,这是Flink提供的examples下的批处理例子程序,统计单词个数。
[root@hadoop1 flink-1.10.1]# bin/flink run examples/batch/WordCount.jar
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 99f4c579947a66884ec269ddf5f5b0ed
Program execution finished
Job with JobID 99f4c579947a66884ec269ddf5f5b0ed has finished.
Job Runtime: 795 ms
Accumulator Results:
- b70332353f355cf0464b0eba21f61075 (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
(bare,1)
(be,4)
(bear,3)
(bodkin,1)
(bourn,1)
(but,1)
(by,2)
(calamity,1)
(cast,1)
(coil,1)
(come,1)
(conscience,1)
(consummation,1)
(contumely,1)
(country,1)
(cowards,1)
(currents,1)
......
得到结果,这里统计的是默认的数据集,可以通过--input --output指定输入输出。我们可以在页面中查看运行的情况:
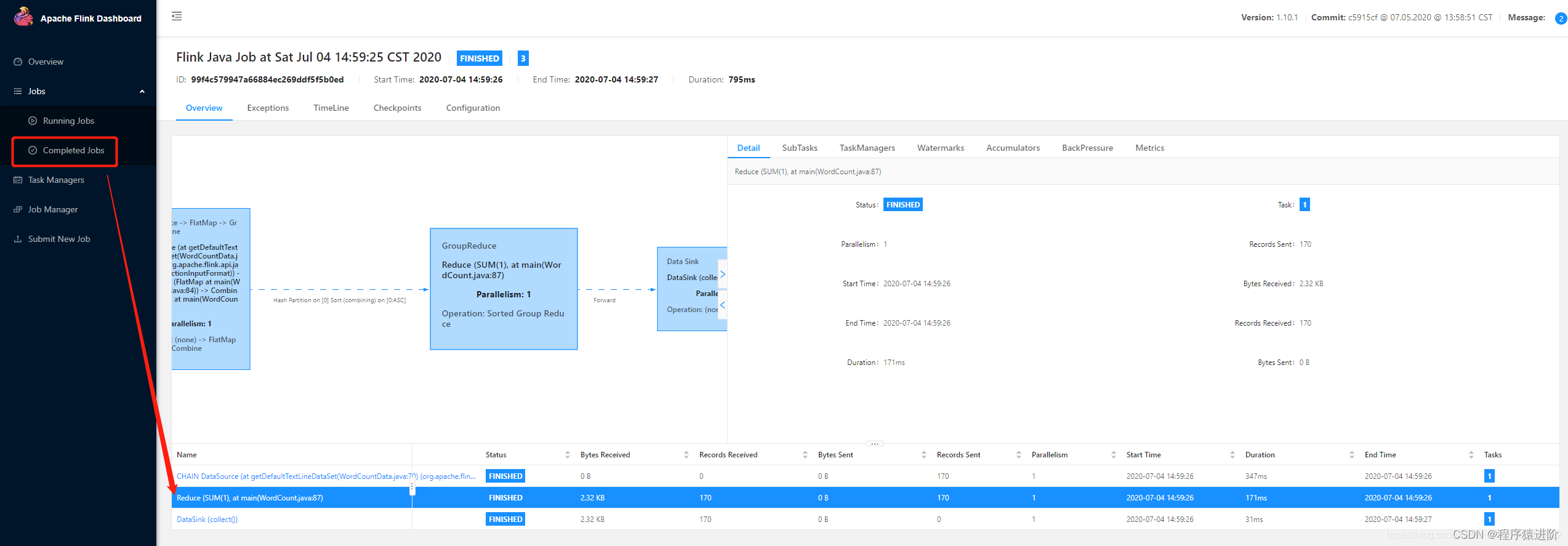 流处理示例:启动
流处理示例:启动nc服务器:
[root@hadoop1 flink-1.10.1]# nc -lk 9000
提交Flink的批处理examples程序:
[root@hadoop1 flink-1.10.1]# bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname hadoop1 --port 9000
这是Flink提供的examples下的流处理例子程序,接收socket数据传入,统计单词个数。在nc端随意写入单词
[root@hadoop1 flink-1.10.1]# nc -lk 9000
g
s
进入slave节点(hadoop2,hadoop3),进入Flink安装目录输入如下命令,查看实时数据变化
[root@hadoop2 flink-1.10.1]# tail -f log/flink-*-taskexecutor-*.out
s : 1
: 2
w : 1
d : 1
g : 1
d : 1
停止Flink
[root@hadoop1 flink-1.10.1]# bin/stop-cluster.sh
在Flink的web中查看运行的job

将 JobManager / TaskManager 实例添加到集群(扩展)
您可以使用bin/jobmanager.sh和bin/taskmanager.sh脚本将JobManager和TaskManager实例添加到正在运行的集群中。添加JobManager(确保在要启动/停止相应实例的主机上调用这些脚本)
[root@hadoop1 flink-1.10.1]# bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-all
添加任务管理器
[root@hadoop1 flink-1.10.1]# bin/taskmanager.sh start|start-foreground|stop|stop-all
YARN模式
在企业中,经常需要将Flink集群部署到YARN,因为可以使用YARN来管理所有计算资源。而且Spark程序也可以部署到YARN上。CliFrontend是所有job的入口类,通过解析传递的参数(jar包,mainClass等),读取flink的环境,配置信息等,封装成PackagedProgram,最终通过ClusterClient提交给Flink集群。Flink运行在YARN上,提供了两种方式:
第一种使用yarn-session模式来快速提交作业到YARN集群。如下,在Yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交,这个flink集群会常驻在Yarn集群中,除非手动停止。共享Dispatcher与ResourceManager,共享资源。有大量的小作业,适合使用这种方式;
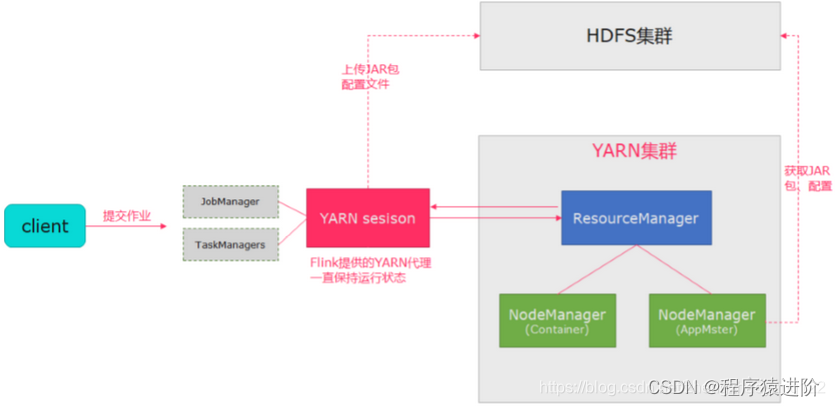
YarnSessionClusterEntrypoint是Flink在Yarn上的线程。ApplicationMaster是JobManager。YarnTaskExecutorRunner负责接收subTask并运行,是TaskManager。
【1】修改Hadoop的etc/hadoop/yarn-site.xml,添加该配置表示内存超过分配值,是否将任务杀掉。默认为true。运行Flink程序,很容易超过分配的内存。
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
【2】 添加环境变量
//查看是否配置HADOOP_CONF_DIR,我这里没有配置输出为空
[root@hadoop1 hadoop-2.7.2]# echo $HADOOP_CONF_DIR
//在系统变量中添加 HADOOP_CONF_DIR
[root@hadoop1 hadoop-2.7.2]# vim /etc/profile
//添加如下内容,wq保存退出
export HADOOP_CONF_DIR=$HADOOP_HOME/conf/
//刷新 /etc/profile
[root@hadoop1 hadoop-2.7.2]# source /etc/profile
//重新查看是否配置HADOOP_CONF_DIR
[root@hadoop1 hadoop-2.7.2]# echo $HADOOP_CONF_DIR
/opt/module/hadoop-2.7.2/conf/
【3】启动HDFS、YARN集群。通过jps查看启动状况。关闭flink的其他集群。
[root@hadoop1 hadoop-2.7.2]# sbin/start-all.sh
[root@hadoop2 hadoop-2.7.2]# jps
10642 NodeManager
11093 Jps
10838 ResourceManager
10535 DataNode
10168 TaskManagerRunner
【4】将官方指定Pre-bundled Hadoop 2.7.5包放到flink的lib目录下。使用yarn-session模式提交作业

使用Flink中的yarn-session(yarn客户端),会启动两个必要服务JobManager和TaskManagers;
客户端通过yarn-session提交作业;
yarn-session会一直启动,不停地接收客户端提交的作用。
-n 表示申请2个容器
-s 表示每个容器启动多少个slot
-tm 表示每个TaskManager申请800M内存
-nm yarn 的 appName,
-d detached表示以后台程序方式运行
如下表示启动一个yarn session集群,每个JM为1G,TM的内存是1G。
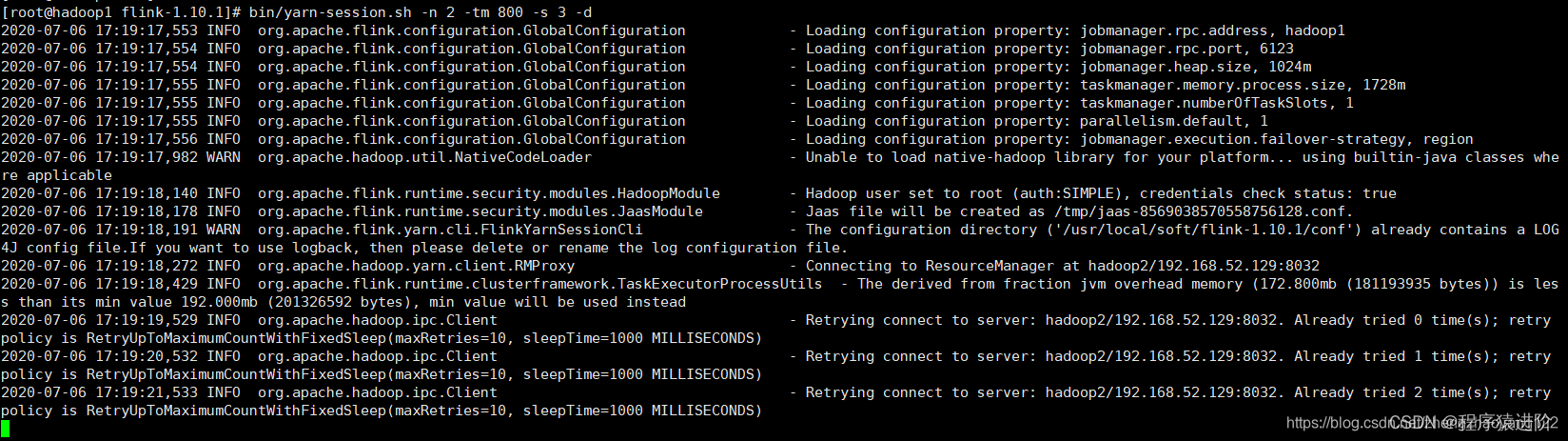
[root@hadoop1 flink-1.10.1]# bin/yarn-session.sh -n 2 -jm 1024m -tm 1024m -d
客户端默认是attach模式,不会退出 。可以ctrl+c退出,然后再通过如下命令连上来。或者启动的时候用-d则为detached模式
./bin/yarn-session.sh -id application_1594027553009_0001(这个id来自下面hadoop集群)
Yarn上显示为Flink session cluster,一致处于运行状态。
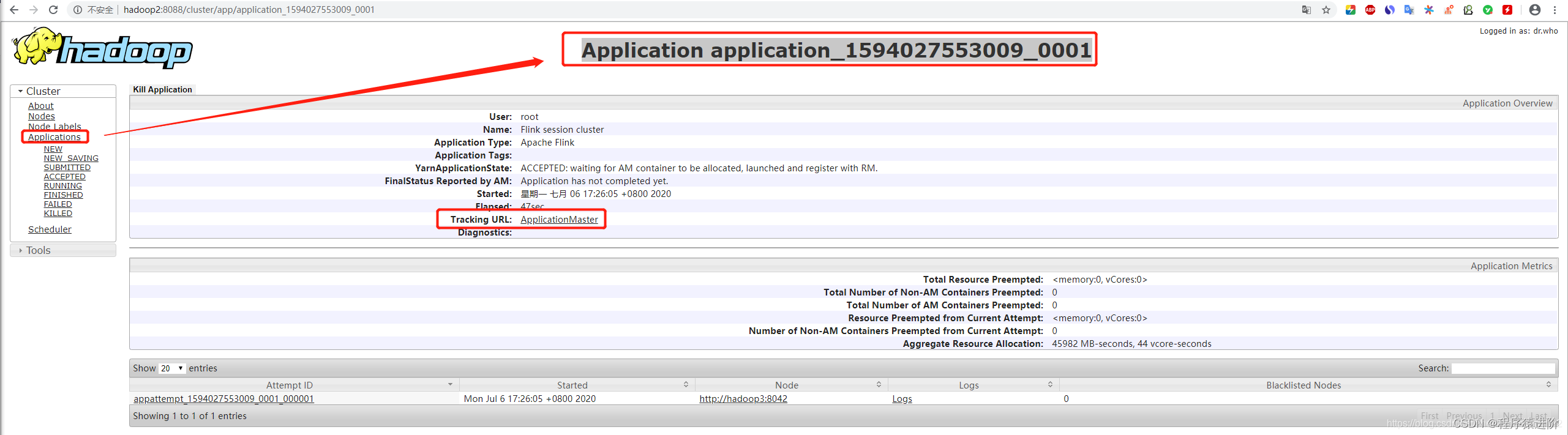 点击
点击ApplicationMaster就会进入Flink集群
 启动命令行中也会显示如下的
启动命令行中也会显示如下的JobManager启动的Web界面
JobManager Web Interface: http://hadoop1:34431
然后我们可以通过jps来看下当前的进程,其中YarnSessionClusterEntrypoint就是我们Yarn Session的分布式集群。
[root@hadoop1 flink-1.10.1]# jps
69923 NodeManager
81267 Jps
69394 NameNode
69531 DataNode
80571 FlinkYarnSessionCli
80765 YarnSessionClusterEntrypoint
/tmp下生成了一个文件
将Flink应用部署到Flink On Yarn 之 session方式中。
[root@hadoop1 flink-1.10.1]# bin/flink run -d examples/streaming/WordCount.jar
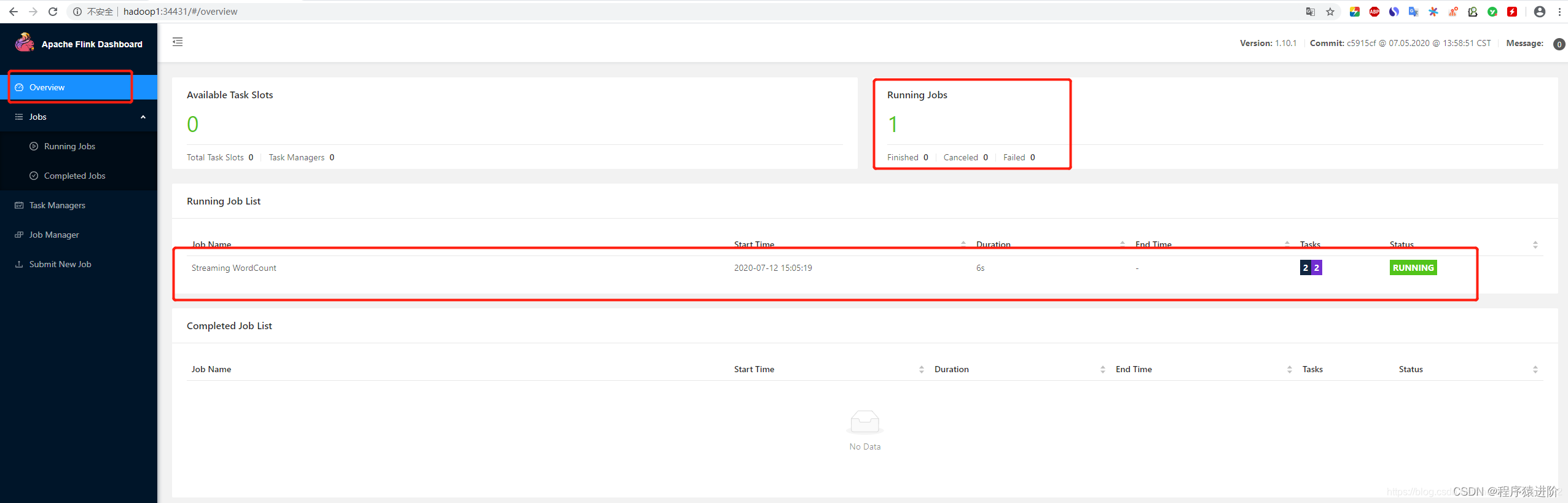
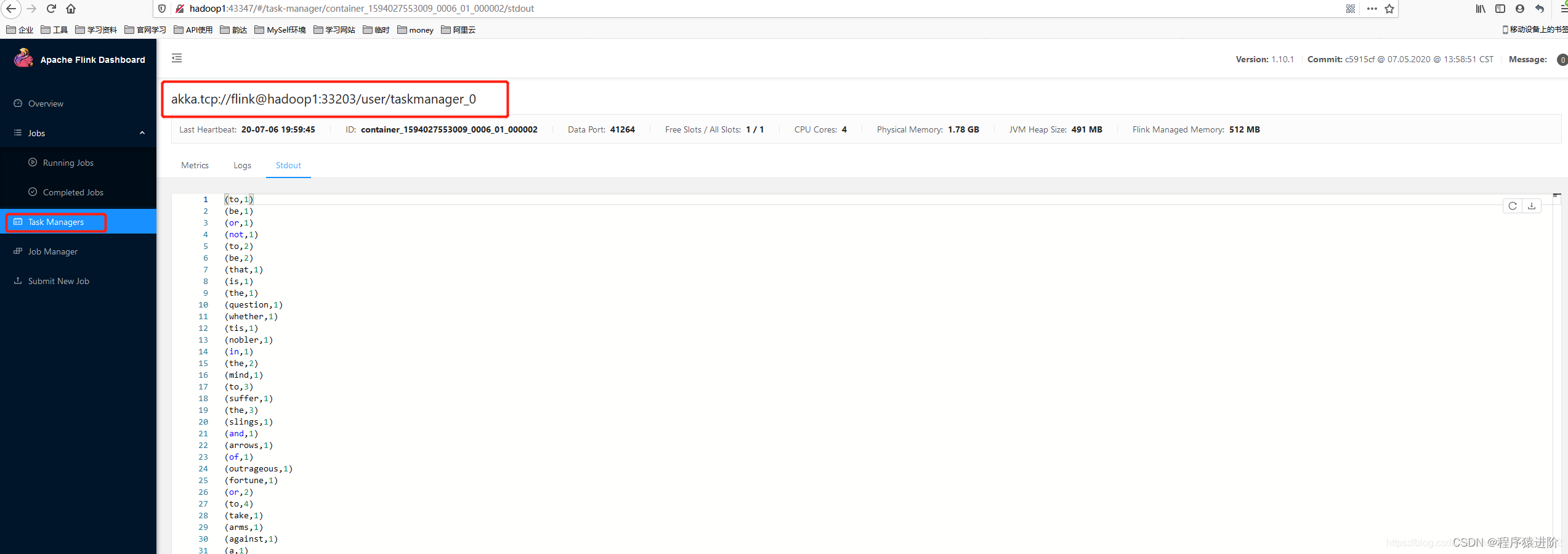
查看运行结果:
Flink On Yarn之session部署方式集群停止:关闭Yarn就会关闭Flink集群。。。
第二种模式:使用Per-JOBYarn分离模式(与当前客户端无关,当客户端提交完任务就结束,不用等到Flink应用执行完毕)提交作业:每次提交都会创建一个新的flink集群,任务之间相互独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。 直接提交任务给YARN,独享Dispatcher与ResourceManager。按需要申请资源。适合执行时间较长的大作业。
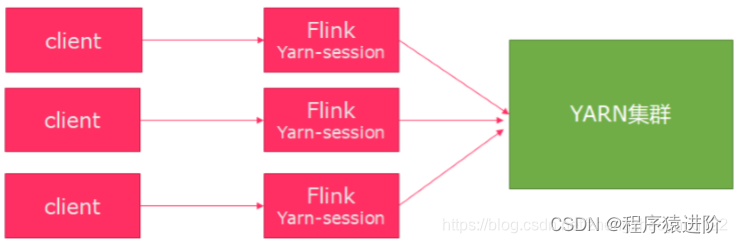
AM启动类是YarnJobClusterEntrypoint。YarnTaskExecutorRunner负责接收subTask,就是TaskManager。需要打开hadoop和yarn分布式集群。不需要启动flink分布式集群,它会自动启动flink分布式集群。
[root@hadoop1 flink-1.10.1]# bin/flink run -m yarn-cluster -d ./examples/streaming/WordCount.jar
2020-07-13 03:21:50,479 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/usr/local/soft/flink-1.10.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2020-07-13 03:21:50,479 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/usr/local/soft/flink-1.10.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
2020-07-13 03:21:50,707 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at hadoop2/192.168.52.129:8032
2020-07-13 03:21:50,791 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-07-13 03:21:50,928 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-07-13 03:21:51,001 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2020-07-13 03:21:53,906 INFO org.apache.flink.yarn.YarnClusterDescriptor
-yn:yarncontainer表示TaskManager的个数;
-yqu:yarnqueue指定yarn的队列;
-ys:yarnslots每一个TaskManager对应的slot个数;
上传成功之后,我们可以在Hadoop的图形化界面:http://hadoop2:8088/cluster/apps 中看到当前任务的信息;

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!