count(*)、count(1)、count(column)的区别
2023-12-22 06:15:40
count(*)、count(1)、count(column)的区别
count(*): 返回检索到的行数,无论是否含有NULL值,在InnoDB下,仅计算当前事务可见的行,通过遍历最小的可用二级索引来处理count(*),除非索引或优化器指示优化器使用不同的索引,如果二级索引不存在,则通过扫描聚集索引来处理。在MyISAM下,count(*)经过优化,存储引擎存储了精确的行计数。
count(1): InnoDB处理select count(*)和select count(1)操作方式相同,没有性能差异。在MyISAM下,仅第一列设置NOT NULL时,count(1)才和count(*)一样走优化,否则扫描所有行数(包含NULL值的行)。
count(column): 返回检索的行中非NULL值的数量,如果没有二级索引则扫描全表,然后排除NULL值。
以下是验证,先看InnoDB引擎:
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`username` varchar(16) DEFAULT NULL,
`phone` char(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1572835 DEFAULT CHARSET=utf8mb3;
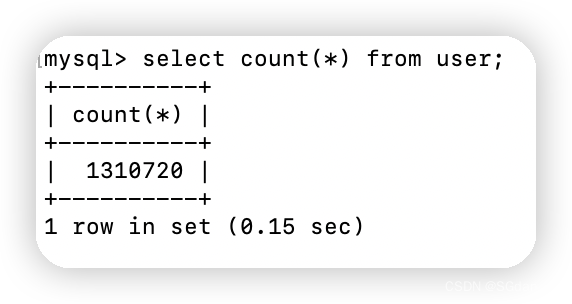
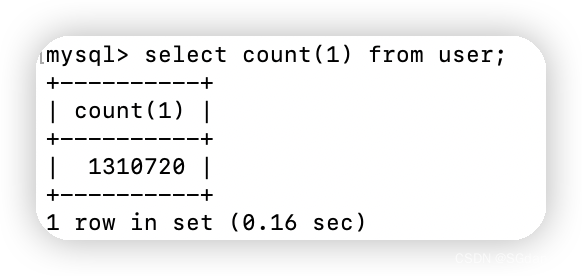
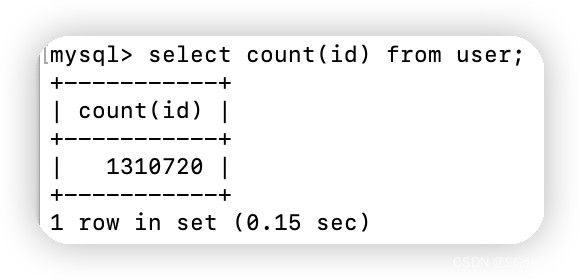
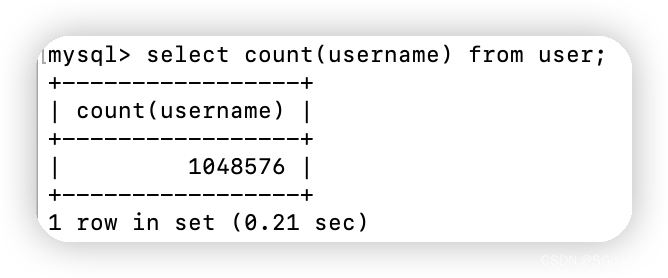




因为此处无多余索引,所以count()、count(1)、count(id)都是走的主键索引,耗时情况应该是count(column) >= count(id) >= count() = count(1) 。
接下来看MyISAM引擎的,
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb3;

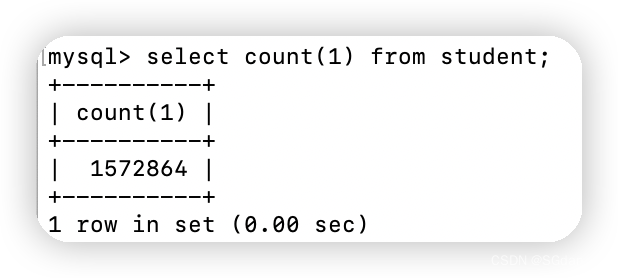
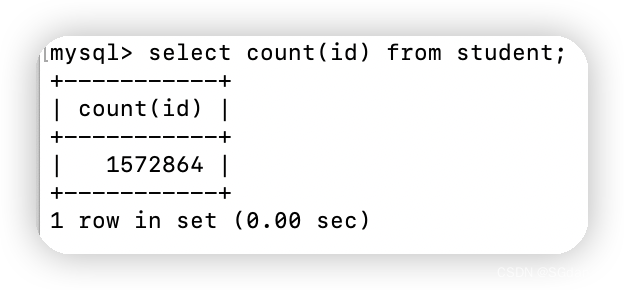
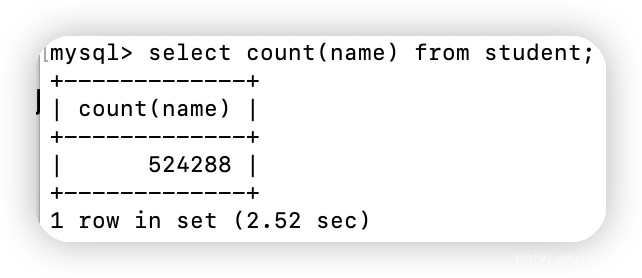




可以看到,count()、count(1)、count(id)耗时一致且没走索引,count(name)耗时较多且是全表扫描,所以耗时情况:count(column) >= count(id) = count(1) >= count()。
文章来源:https://blog.csdn.net/SGdan_qi/article/details/135143433
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!